Pytorch(3)Autograd 与逻辑回归 |
您所在的位置:网站首页 › 网络信息安全学院排名 › Pytorch(3)Autograd 与逻辑回归 |
Pytorch(3)Autograd 与逻辑回归
|
[PyTorch 学习笔记]
Autograd 与逻辑回归
自动求导 (autograd)
在深度学习中,权值的更新是依赖于梯度的计算,因此梯度的计算是至关重要的。在 PyTorch 中,只需要搭建好前向计算图,然后利用torch.autograd自动求导得到所有张量的梯度。 torch.autograd.backward():自动求取梯度 1torch.autograd.backward(tensors, grad_tensors=None, retain_graph=None, create_graph=False, grad_variables=None) tensors: 用于求导的张量,如 loss retain_graph: 保存计算图。PyTorch 采用动态图机制,默认每次反向传播之后都会释放计算图。这里设置为 True 可以不释放计算图。 create_graph: 创建导数计算图,用于高阶求导 grad_tensors: 多梯度权重。当有多个 loss 混合需要计算梯度时,设置每个 loss 的权重。 ==逻辑回归 (Logistic Regression)==逻辑回归是线性的二分类模型。模型表达式
分类原则如下:class 其中 逻辑回归也被称为对数几率回归
PyTorch 构建模型需要 5 大步骤: 数据:包括数据读取,数据清洗,进行数据划分和数据预处理,比如读取图片如何预处理及数据增强。 模型:包括构建模型模块,组织复杂网络,初始化网络参数,定义网络层。 损失函数:包括创建损失函数,设置损失函数超参数,根据不同任务选择合适的损失函数。 优化器:包括根据梯度使用某种优化器更新参数,管理模型参数,管理多个参数组实现不同学习率,调整学习率。 迭代训练:组织上面 4 个模块进行反复训练。包括观察训练效果,绘制 Loss/ Accuracy 曲线,用 TensorBoard 进行可视化分析。 123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384import torchimport torch.nn as nnimport matplotlib.pyplot as pltimport numpy as nptorch.manual_seed(10)# ============================ step 1/5 生成数据 ============================sample_nums = 100mean_value = 1.7bias = 1n_data = torch.ones(sample_nums, 2)# 使用正态分布随机生成样本,均值为张量,方差为标量x0 = torch.normal(mean_value * n_data, 1) + bias # 类别0 数据 shape=(100, 2)# 生成对应标签y0 = torch.zeros(sample_nums) # 类别0 标签 shape=(100, 1)# 使用正态分布随机生成样本,均值为张量,方差为标量x1 = torch.normal(-mean_value * n_data, 1) + bias # 类别1 数据 shape=(100, 2)# 生成对应标签y1 = torch.ones(sample_nums) # 类别1 标签 shape=(100, 1)train_x = torch.cat((x0, x1), 0)train_y = torch.cat((y0, y1), 0)# ============================ step 2/5 选择模型 ============================class LR(nn.Module): def __init__(self): super(LR, self).__init__() self.features = nn.Linear(2, 1) self.sigmoid = nn.Sigmoid() def forward(self, x): x = self.features(x) x = self.sigmoid(x) return xlr_net = LR() # 实例化逻辑回归模型# ============================ step 3/5 选择损失函数 ============================loss_fn = nn.BCELoss()# ============================ step 4/5 选择优化器 ============================lr = 0.01 # 学习率optimizer = torch.optim.SGD(lr_net.parameters(), lr=lr, momentum=0.9)# ============================ step 5/5 模型训练 ============================for iteration in range(1000): # 前向传播 y_pred = lr_net(train_x) # 计算 loss loss = loss_fn(y_pred.squeeze(), train_y) # 反向传播 loss.backward() # 更新参数 optimizer.step() # 清空梯度 optimizer.zero_grad() # 绘图 if iteration % 20 == 0: mask = y_pred.ge(0.5).float().squeeze() # 以0.5为阈值进行分类 correct = (mask == train_y).sum() # 计算正确预测的样本个数 acc = correct.item() / train_y.size(0) # 计算分类准确率 plt.scatter(x0.data.numpy()[:, 0], x0.data.numpy()[:, 1], c='r', label='class 0') plt.scatter(x1.data.numpy()[:, 0], x1.data.numpy()[:, 1], c='b', label='class 1') w0, w1 = lr_net.features.weight[0] w0, w1 = float(w0.item()), float(w1.item()) plot_b = float(lr_net.features.bias[0].item()) plot_x = np.arange(-6, 6, 0.1) plot_y = (-w0 * plot_x - plot_b) / w1 plt.xlim(-5, 7) plt.ylim(-7, 7) plt.plot(plot_x, plot_y) plt.text(-5, 5, 'Loss=%.4f' % loss.data.numpy(), fontdict={'size': 20, 'color': 'red'}) plt.title("Iteration: {}\nw0:{:.2f} w1:{:.2f} b: {:.2f} accuracy:{:.2%}".format(iteration, w0, w1, plot_b, acc)) plt.legend() # plt.savefig(str(iteration / 20)+".png") plt.show() plt.pause(0.5) # 如果准确率大于 99%,则停止训练 if acc > 0.99: break训练的分类直线的可视化如下: 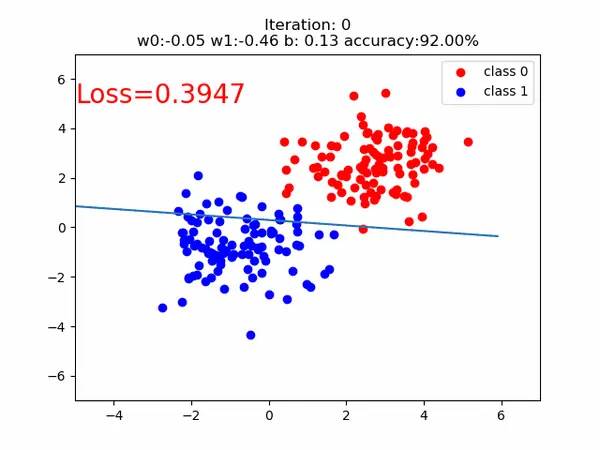 img
img
|

【本文地址】
今日新闻 |
推荐新闻 |