【LSS: Lift, Splat, Shoot】代码的复现与详细解读 |
您所在的位置:网站首页 › 缩小ego怎么理解 › 【LSS: Lift, Splat, Shoot】代码的复现与详细解读 |
【LSS: Lift, Splat, Shoot】代码的复现与详细解读
|
文章目录
一、代码复现1.1 环境搭建1.2 数据集下载1.3 Evaluate a model1.4 Visualize Predictions1.5 Visualize Input/Output Data1.6 Train a model
二、代码理解main.pyexplore.pydata.pymodels.pytools.pytrain.py
原论文:https://arxiv.org/pdf/2008.05711v1.pdf 论文解读:论文精读《LSS: Lift, Splat, Shoot: Encoding Images from Arbitrary Camera Rigs by Implicitly Unprojecting》 代码: https://github.com/nv-tlabs/lift-splat-shoot 一、代码复现 1.1 环境搭建使用ubuntu从零配置环境参考:此文 使用anaconda创建虚拟环境 conda create -n lssEnv python=3.8 conda activate lssEnv 安装torch 先从官网上下载轮子,然后直接安装 pip install torch-1.9.0+cu102-cp38-cp38-linux_x86_64.whl pip install torchvision-0.10.0+cu102-cp38-cp38-linux_x86_64.whl 安装工具 pip install nuscenes-devkit tensorboardX efficientnet_pytorch==0.7.0 安装tensorflow (方便在训练过程中使用TensorBoard) pip install tensorflow-gpu==2.2.0 1.2 数据集下载NuSences 数据集解析以及 nuScenes devkit 的使用 在官网上下载mini版本的数据集(Nuscenes的官网下载链接 )
 下载最新的Map expansion 下载最新的Map expansion  解压到maps文件下 解压到maps文件下  1.3 Evaluate a model
下载项目文件
git clone https://github.com/nv-tlabs/lift-splat-shoot.git
下载权重文件
wget https://github.com/lukemelas/EfficientNet-PyTorch/releases/download/1.0/efficientnet-b0-355c32eb.pth
运行 main.py 文件中的eval_model_iou 对模型进行评估。 其中,因为我们采用的是mini 版本的 nuScenes,所以 采用mini参数。反之,如果我们采用的是Trianval 版本的 nuScenes,则采用Trianval参数。 modelf 选择刚才下载的权重文件放置的路径 dataroot 选择我们下载mini数据集的路径 gpuid 如果是默认一块则为0
python main.py eval_model_iou mini --modelf=./efficientnet-b0-355c32eb.pth --dataroot=../dataset/nuScenes --gpuid=0
这时会报错 :
1.3 Evaluate a model
下载项目文件
git clone https://github.com/nv-tlabs/lift-splat-shoot.git
下载权重文件
wget https://github.com/lukemelas/EfficientNet-PyTorch/releases/download/1.0/efficientnet-b0-355c32eb.pth
运行 main.py 文件中的eval_model_iou 对模型进行评估。 其中,因为我们采用的是mini 版本的 nuScenes,所以 采用mini参数。反之,如果我们采用的是Trianval 版本的 nuScenes,则采用Trianval参数。 modelf 选择刚才下载的权重文件放置的路径 dataroot 选择我们下载mini数据集的路径 gpuid 如果是默认一块则为0
python main.py eval_model_iou mini --modelf=./efficientnet-b0-355c32eb.pth --dataroot=../dataset/nuScenes --gpuid=0
这时会报错 : 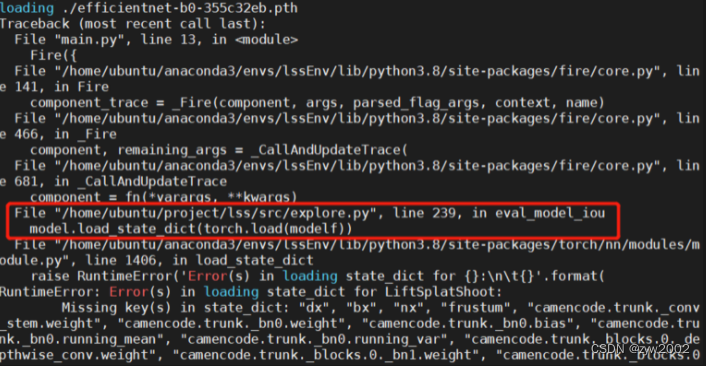 解决方案 把explore.py文件下的第239行中,选择不加载模型状态
model.load_state_dict(torch.load(modelf), False)
然后,运行成功 解决方案 把explore.py文件下的第239行中,选择不加载模型状态
model.load_state_dict(torch.load(modelf), False)
然后,运行成功 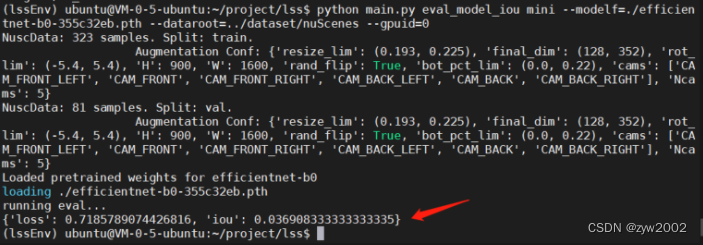 1.4 Visualize Predictions
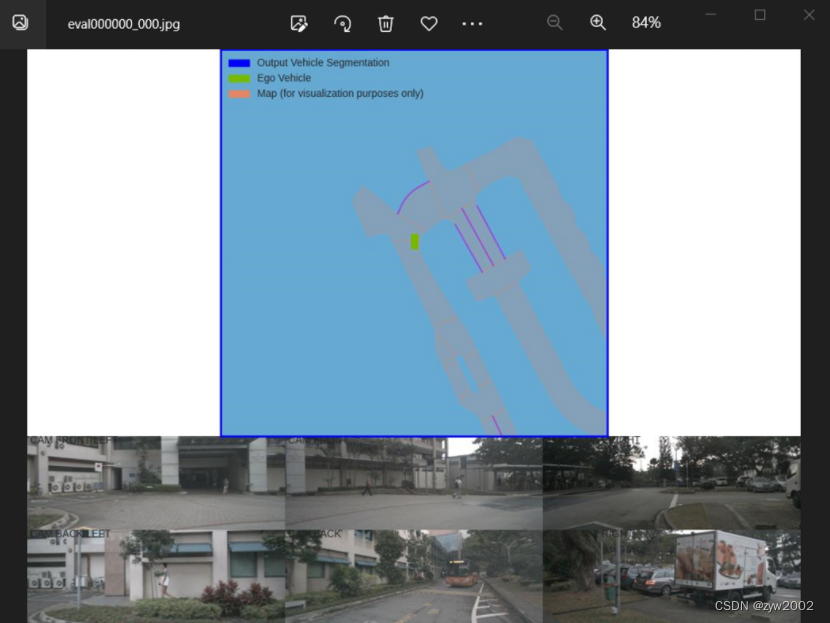
运行 main.py 文件中的viz_model_preds 对预测结果进行可视化。
python main.py viz_model_preds mini --modelf=./efficientnet-b0-355c32eb.pth --dataroot=../dataset/nuScenes --map_folder=../dataset/nuScenes/mini --gpuid=0
1.4 Visualize Predictions
运行 main.py 文件中的viz_model_preds 对预测结果进行可视化。
python main.py viz_model_preds mini --modelf=./efficientnet-b0-355c32eb.pth --dataroot=../dataset/nuScenes --map_folder=../dataset/nuScenes/mini --gpuid=0
 1.5 Visualize Input/Output Data
运行lidar_check, 检查以确保正确地解析了extrinsics/intrinsics
python main.py lidar_check mini --dataroot=../dataset/nuScenes --viz_train=False
1.5 Visualize Input/Output Data
运行lidar_check, 检查以确保正确地解析了extrinsics/intrinsics
python main.py lidar_check mini --dataroot=../dataset/nuScenes --viz_train=False
 1.6 Train a model
1.6 Train a model
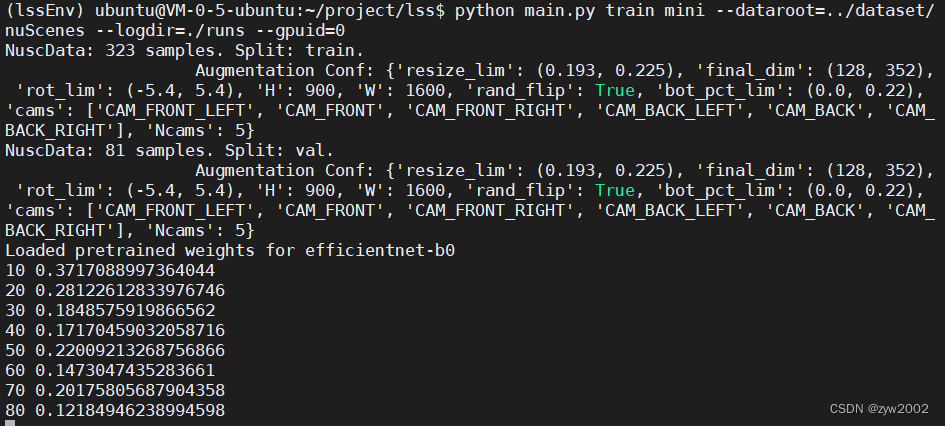
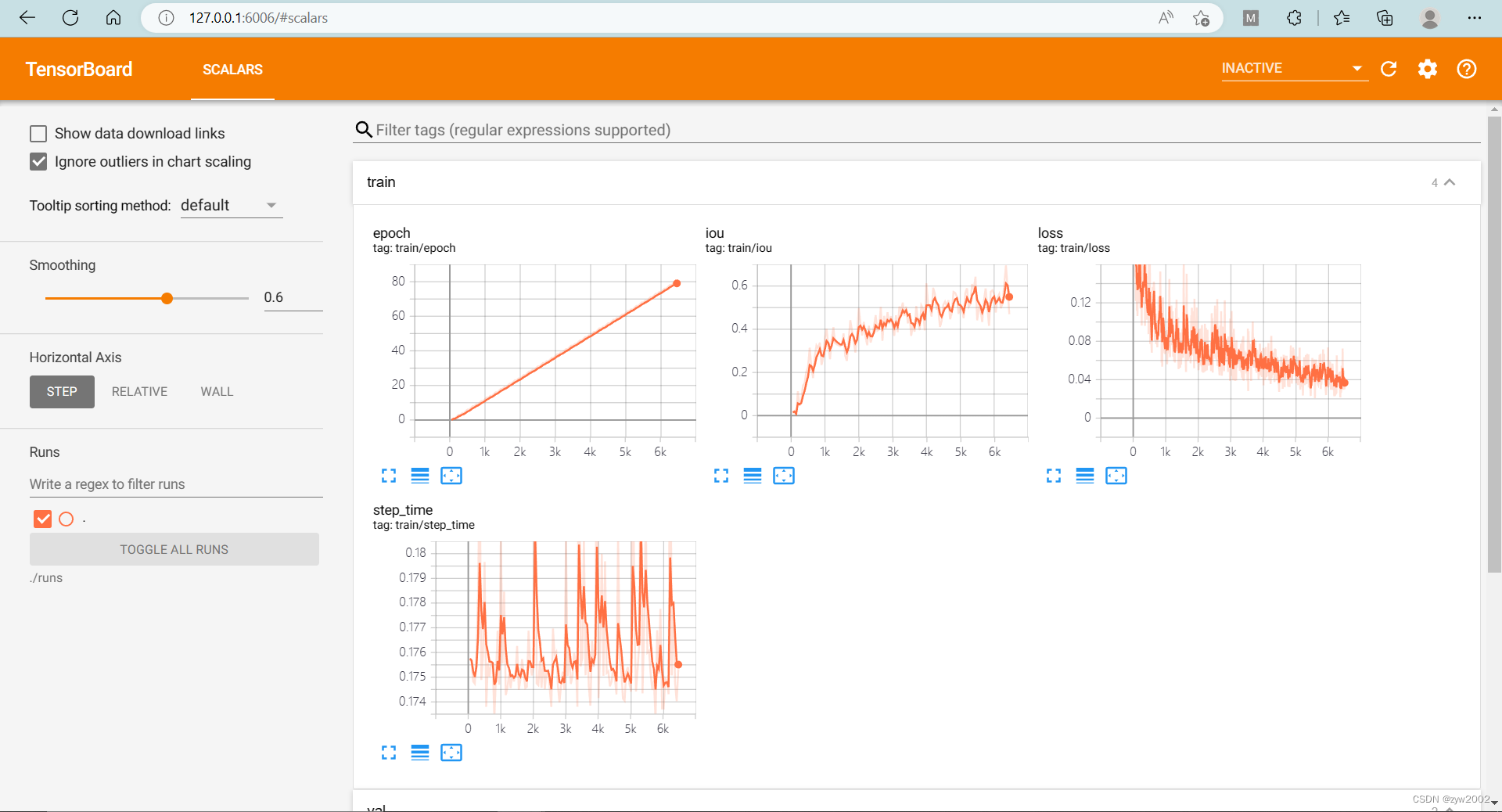
在项目文件夹下新建一个runs的目录,用来存放训练时的日志信息。 执行下面的命令开始训练 python main.py train mini --dataroot=../dataset/nuScenes --logdir=./runs --gpuid=0 tensorboard --logdir=./runs --bind_all
利用MobaXterm配置隧道 在本地浏览器上输入127.0.0.1:6006, 可以看到tensorboard面板 我们按照代码的执行逻辑来拆开理解。 main.pymain.py文件是函数的执行入口。 Fire (python Fire 的使用指南)通过使用字典格式,选择函数暴露给命令行。 当命令行参数传入eval_model_iou ,程序就开始执行src/explore.py文件下的eval_model_iou 函数。 if __name__ == '__main__': Fire({ 'lidar_check': src.explore.lidar_check, 'cumsum_check': src.explore.cumsum_check, 'train': src.train.train, 'eval_model_iou': src.explore.eval_model_iou, 'viz_model_preds': src.explore.viz_model_preds, }) explore.py我们来看看explore.py中的eval_model_iou函数。 函数参数: 先来看看这个函数需要传入哪些参数~ version, # 数据集版本: mini/trival modelf, # 模型文件路径 dataroot='/data/nuscenes',# 数据集路径 gpuid=1,# gpu的序号 H=900, W=1600, # 图片的宽和高 resize_lim=(0.193, 0.225), # resize 的范围 final_dim=(128, 352), # 数据预处理后最终的图片大小 bot_pct_lim=(0.0, 0.22), # 裁剪图片时,图像底部裁掉部分所占的比例范围 rot_lim=(-5.4, 5.4), # 训练时旋转图片的角度范围 rand_flip=True, # 是否随机翻转然后定义了两个字典grid_conf 和 data_aug_con grid_conf = { # 网格配置 'xbound': xbound, 'ybound': ybound, 'zbound': zbound, 'dbound': dbound, } data_aug_conf = { # 数据增强配置 'resize_lim': resize_lim, 'final_dim': final_dim, 'rot_lim': rot_lim, 'H': H, 'W': W, 'rand_flip': rand_flip, 'bot_pct_lim': bot_pct_lim, 'cams': ['CAM_FRONT_LEFT', 'CAM_FRONT', 'CAM_FRONT_RIGHT', 'CAM_BACK_LEFT', 'CAM_BACK', 'CAM_BACK_RIGHT'], 'Ncams': 5, # 读取数据时读取的摄像机的数目-1 }数据的加载、训练和评估: 调用data.py文件中的compile_data 生成训练集和验证集的数据加载器trainloader和valloader。 trainloader, valloader = compile_data(version, dataroot, data_aug_conf=data_aug_conf, grid_conf=grid_conf, bsz=bsz, nworkers=nworkers, parser_name='segmentationdata') # 测试集和验证集集的数据加载器 调用model.py文件中的compile_model 构造LSS模型 model = compile_model(grid_conf, data_aug_conf, outC=1) # 获取模型 把模型迁移到GPU上 device = torch.device('cpu') if gpuid |

 然后新建一个隧道,并进行配置。 1) 选择【本地端口转发】 2)【我的电脑】选择6006端口 3)【ssh服务器】和我们通过SSH连接远程服务器的设置是一样的,分别填写相应的IP地址,用户名,端口号(通常为22)即可 4)【远程服务器】远程服务器 填localhost , 远程端口填6006
然后新建一个隧道,并进行配置。 1) 选择【本地端口转发】 2)【我的电脑】选择6006端口 3)【ssh服务器】和我们通过SSH连接远程服务器的设置是一样的,分别填写相应的IP地址,用户名,端口号(通常为22)即可 4)【远程服务器】远程服务器 填localhost , 远程端口填6006 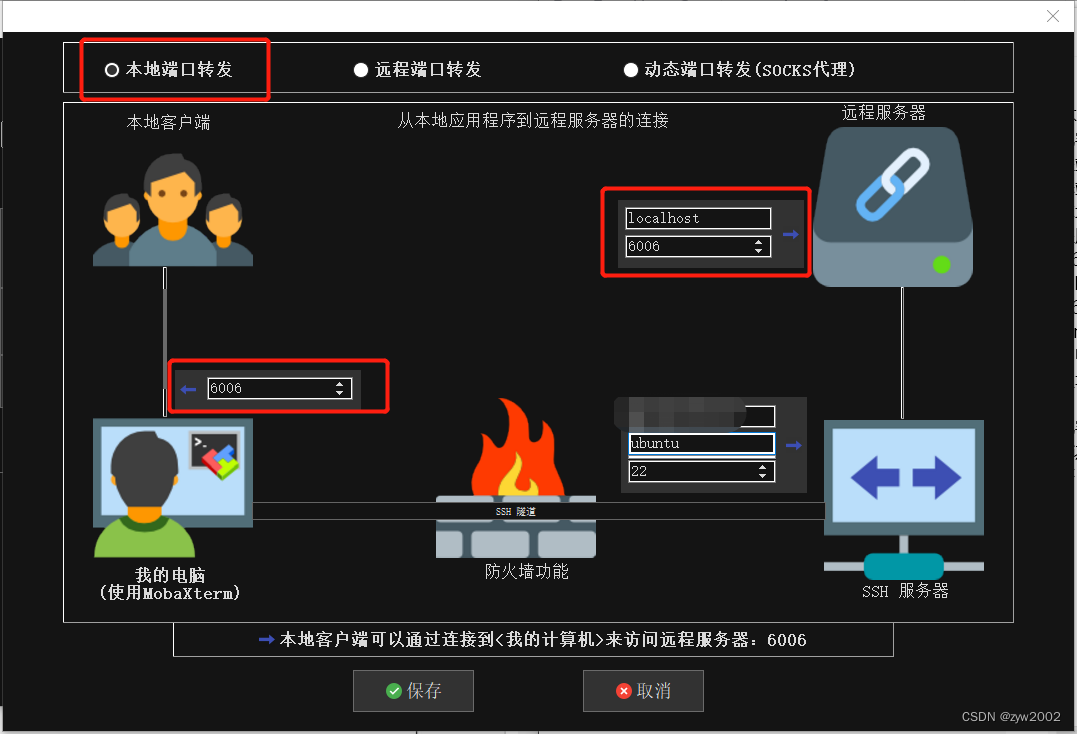 然后启动隧道
然后启动隧道 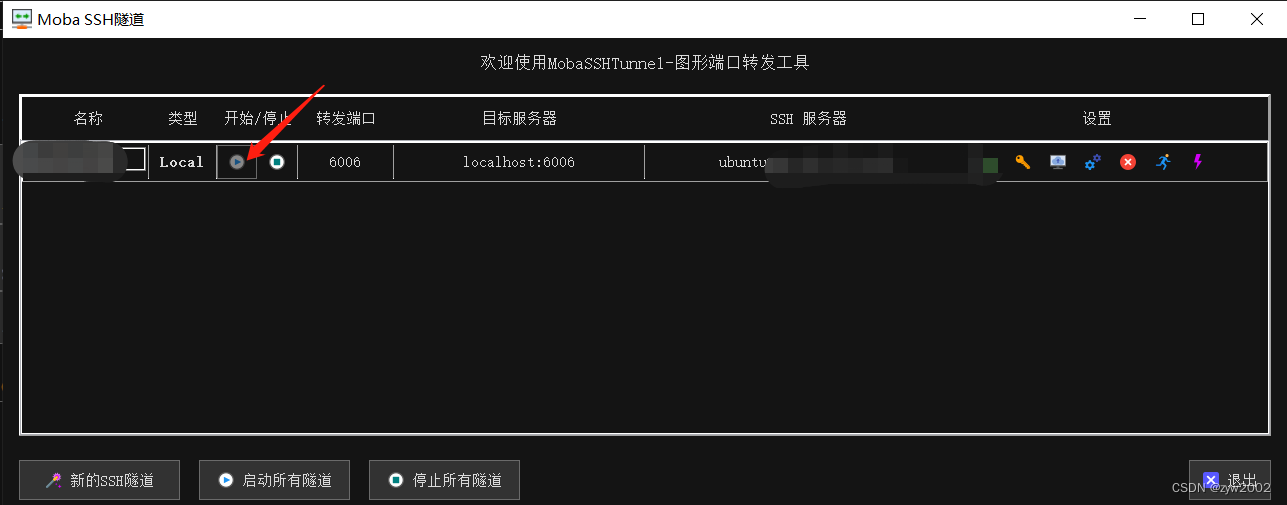
【本文地址】
今日新闻 |
推荐新闻 |