C 语言入门手册:几小时内就能学会的 C 语言基础 |
您所在的位置:网站首页 › 编程c语言入门自学书籍推荐 › C 语言入门手册:几小时内就能学会的 C 语言基础 |
C 语言入门手册:几小时内就能学会的 C 语言基础
|
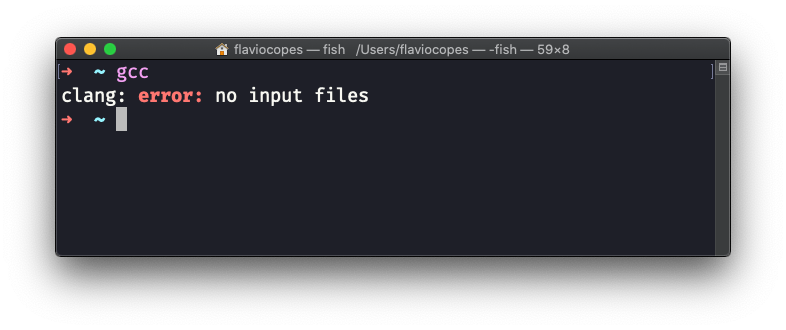
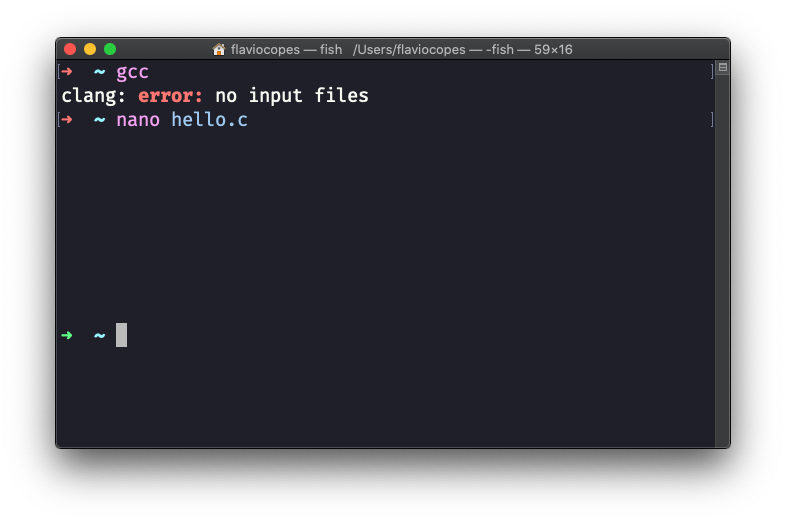
本手册遵循二八定律。你将在 20% 的时间内学习 80% 的 C 编程语言。 这种方式将会让你对这门语言有一个全面的认识。 本手册并不会尝试覆盖与 C 有关的一切。它只会关注这门语言的核心部分,尽量将更加复杂的主题简单化。 提示:你可以从这里获得这本手册的 PDF 或 ePub 版本。 尽情享受吧! 目录 C 语言简介 变量与类型 常量 运算符 条件语句 循环 数组 字符串 指针 函数 输入与输出 变量作用域 静态变量 全局变量 类型定义 枚举类型 结构体 命令行参数 头文件 预处理器 结语 C 语言简介C 可能是最广为人知的编程语言。它被全世界的计算机科学课程中用作参考语言,除了 Python 与 Java,它可能是人们在学校学得最多得编程语言。 我记得它是我在 Pascal 之后的第二门编程语言。 学生们用 C 来学习编程,但它的作用远不止这一点。它不是一门学术型语言。它不是最简单的语言,因为 C 是一门非常底层的编程语言。 今天,C 在嵌入式设备中广泛使用,它驱动着绝大多数用 Linux 搭建的因特网服务器。Linux 内核是用 C 写的,这也意味着 C 驱动着所有安卓设备的内核。可以这么说,此时此刻,整个世界的一大部分就是由 C 代码运行的,令人惊叹。 在诞生之初,C 被认为是一门高级语言,因为它可以在不同机器之间移植。如今,我们或多或少都认为在 Mac 或 Windows 或 Linux 运行一个程序(可能使用 Node.js 或 Python)是理所当然的。 在以前,完全不是这样的。C 带来了一门易于实现的语言,它的编译器可以很容易地被移植到不同的机器上。 我说下译器:C 是一门编译型语言,就像 Go、Java、Swift 或 Rust 一样。其它流行的语言,比如 Python、Ruby 或 JavaScript 都是解释型语言。编译型语言与解释型语言的差别是不变的:编译型语言生成的是可直接执行和分发的二进制文件。 C 不支持垃圾收集(garbage collection),这意味着我们必须自己管理内存。管理内存是一项复杂的任务,需要十分小心才能预防缺陷,但 C 也因此成为了嵌入式设备(例如 Arduino)编程的理想语言。 C 并不会隐藏下层机器的复杂性和能力。一旦知道你能做什么,你就能拥有巨大的能力。 现在,我想介绍第一个 C 程序,我们将会管它叫“Hello, World”。 hello.c #include int main(void) { printf("Hello, World!"); }让我们描述一下这段程序源代码:我们首先导入了 stdio 库(stdio 表示的是标准输入输出库(standard input-output library))。 这个库允许我们访问输入/输出函数。 C 是一门内核非常小的语言,任何内核以外的部分都以库的形式提供。其中一些库由普通编程人员构建并供他人使用。另一些库被内置在编译器中,比如 stdio 等。 stdio 库提供了 prinf() 函数。 这个函数被包裹在 main() 函数中,main() 函数是所有 C 程序的入口。 但是,究竟什么是函数呢? 函数(function)是一个例程,它接收一个或多个参数并返回一个值。 在 main() 的例子中,函数没有参数,返回一个整数。我们使用 void 关键字标识该参数,使用 int 关键字标识返回值。 函数有一个由花括号包裹的函数体,函数需要进行的所有操作的代码都在函数体内。 如你所见,printf() 函数的写法稍有不同。它没有定义返回值,并且我们给它传入了一个用双引号包裹的字符串。我们并没有声明参数的类型。 那是因为这是一个函数调用。在 stdio 库中的某个地方,printf 被定义成 int printf(const char *format, ...);你现在不需要理解这是何含义,简单来说,这是就是函数定义。当我们调用 printf("Hello, World!"); 时,这就是该函数运行的地方。 我们在上面定义的 main() 函数: #include int main(void) { printf("Hello, World!"); }将会在程序被执行的时候由操作系统运行。 我们如何执行一个 C 程序呢? 如我所说,C 是一门编译型语言。要运行程序,我们必须先编译它。任何 Linux 或 macOS 计算机都自带了 C 编译器。至于 Windows,你可以使用适用于 Linux 的 Windows 子系统(WSL)。 无论如何,你都可以在打开终端时输入 gcc,这个命令应该会返回一个错误,提示你没有声明任何文件:
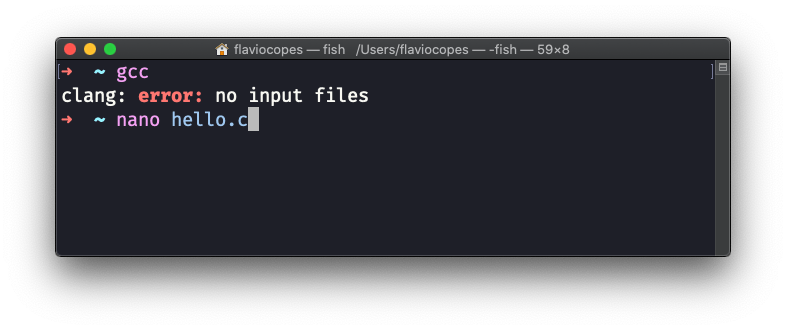
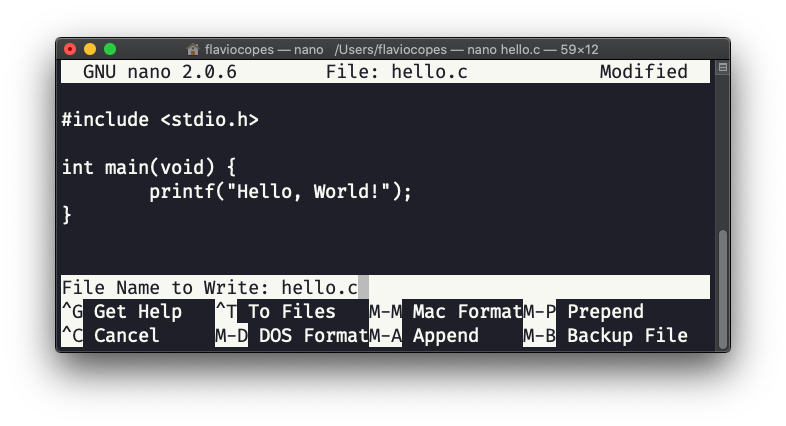
很好。它说明 C 编译器是有的,现在我们可以开始使用它了。 现在将上面的程序输入到一个名为 hello.c 的文件中。你可以使用任何编辑器,不过为了简单起见,我将在命令行中使用 nano 编辑器:
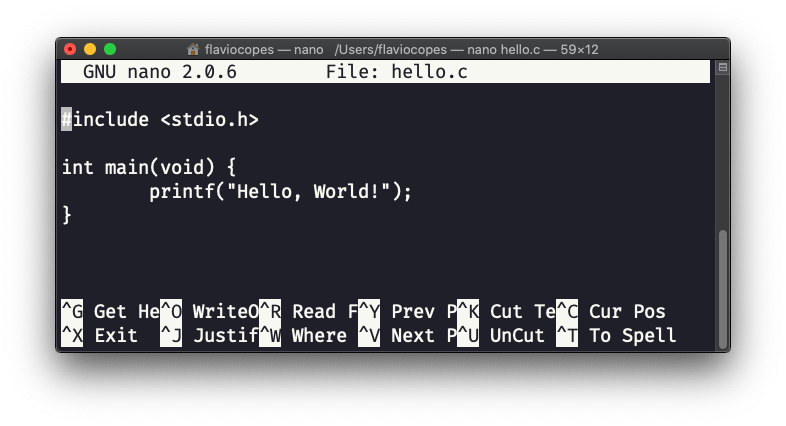
输入程序:
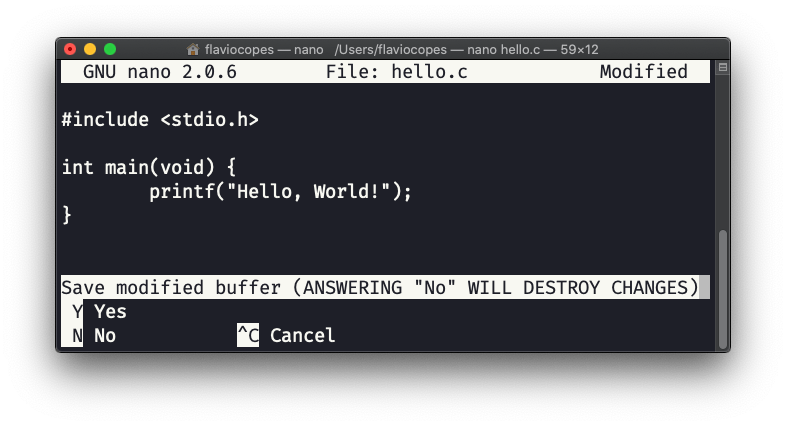
现在按 ctrl-X 退出:
按 y 键确认,然后按回车键确认文件名:
就是这样,我们现在应该已经回到终端了:
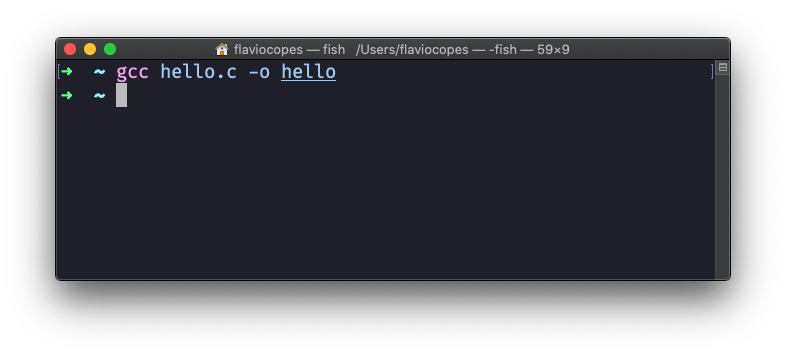
现在输入 gcc hello.c -o hello程序应该不会给你任何错误信息:
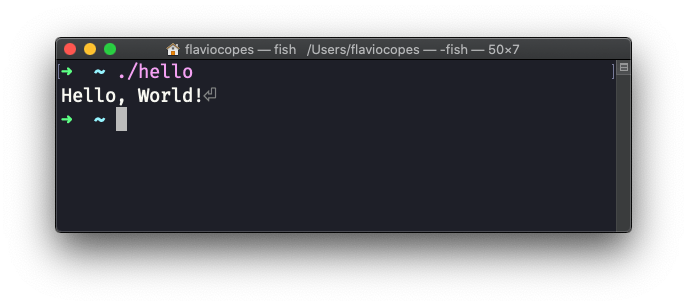
但是它应该已经生成了一个名为 hello 的可执行程序。现在输入 ./hello运行它:
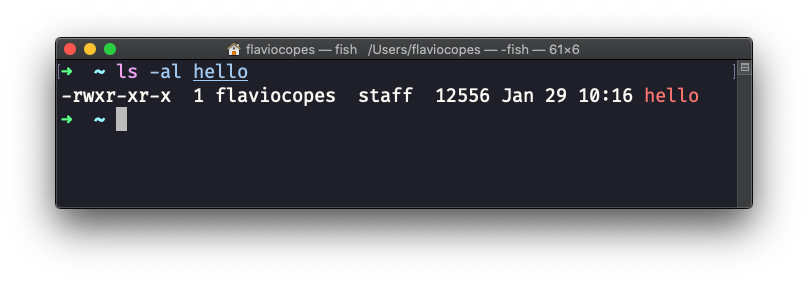
我在程序名的前面加了 ./,告诉终端要执行的命令就在当前目录下。 太棒了! 现在,如果你调用 ls -al hello,你能看到这个程序只有 12KB 大:
这是 C 的优点之一:它是高度优化的,这也是它非常适用于资源非常有限的嵌入式设备的原因之一。 变量与类型C 是一门静态类型语言。 这意味着任何变量都有一个相关联的类型,并且该类型在编译时是可知的。 这与你在 Python、JavaScript、PHP 和其它解释型语言中使用变量的方式大有不同。 当你在 C 中创建变量时,你必须在声明中给出该变量的类型。 在这个示例中,我们初始化一个 int 类型的变量 age: int age;变量名可以包含任意大写或小写字母,也可以包含数字和下划线,但是不能以数字开头。AGE 和 Age10 都是有效的变量名,但 1age 就不是了。 你还可以在声明中初始化变量,给出初始值即可: int age = 37;变量一旦声明,你就可以在程序代码中使用它了。你在任何时候都可以使用 = 改变它的值,例如 age = 100;(提供的新值的类型与原值相同)。 在这种情况下: #include int main(void) { int age = 0; age = 37.2; printf("%u", age); }编译器会在编译时发出警告,然后将小数转为整数。 C 的内置数据类型有 int、char、short、long、float、double、long double。咱们进一步了解这些数据类型吧。 整数C 给我们提供了下列定义整数的类型: char int short long通常,你很可能会使用 int 保存整数。但是在某些情况下,你或许想在其它三个选项中选取合适的类型。 char 类型通常被用来保存 ASCII 表中的字母,但是它也可以用来保存 -128 到 127 之间的小整数。它占据至少一个字节。 int 占据至少两个字节。short 占据至少两个字节。long 占据至少四个字节。 如你所见,我们并不保证不同环境下的值相同。我们只有一个指示。问题在于每种数据类型中所存储的具体值是由实现和系统架构决定的。 我们保证 short 不会比 int 长。并且我们还保证 long 不会比 int 短。 ANSI C 规范标准确定了每种类型的最小值,多亏了它,我们至少可以知道使用某个类型时可以期待的最小值。 如果你正在 Arduino 上用 C 编程,不同的板子上的限制会有所不同。 在 Arduino Uno 开发板上,int 占两个字节,范围从 -32,768 到 32,767。在 Arduino MKR 1010 上,int 占四个字节,范围从 -2,147,483,648 到 2,147,483,647。差异还真不小。 在所有的 Arduino 开发板上,short 都占两个字节,范围从 -32,768 到 32,767。long 占四个字节,范围从 -2,147,483,648 到 2,147,483,647。 无符号整数对于以上所有的数据类型,我们都可以在其前面追加一个 unsigned。这样一来,值的范围就不再从负数开始,而是从 0 开始。这在很多情况下是很有用的。 unsigned char 的范围从 0 开始,至少到 255 unsigned int 的范围从 0 开始,至少到 65,535 unsigned short 的范围从 0 开始,至少到 65,535 unsigned long 的范围从 0 开始,至少到 4,294,967,295 溢出的问题鉴于所有这些限制,可能会出现一个问题:我们如何确保数字不超过限制?如果超过了限制会怎样? 如果你有一个值为 255 的 unsigned int,自增返回的值为 256,这在意料之中。如果你有一个值为 255 的 unsigned char,你得到的结果就是 0。它重置为了初始值。 如果你有一个值为 255 的 unsigned char,给它加上 10 会得到数字 9: #include int main(void) { unsigned char j = 255; j = j + 10; printf("%u", j); /* 9 */ }If you don't have a signed value, the behavior is undefined. 原文这里可能是 typo,从代码来看,这里描述的是有符号整数的溢出行为。 如果你的值是有符号的,程序的行为则是未知的。程序基本上会给你一个很大的值,这个值可能变化,就像这样: include int main(void) { char j = 127; j = j + 10; printf("%u", j); /* 4294967177 */ }换句话说,C 并不会在你超出类型的限制时保护你。对于这种情况,你需要自己当心。 声明错误类型时的警告如果你声明变量并用错误的值进行初始化,gcc 编译器(你可能正在使用这个编译器)应该会发出警告: #include int main(void) { char j = 1000; } hello.c:4:11: warning: implicit conversion from 'int' to 'char' changes value from 1000 to -24 [-Wconstant-conversion] char j = 1000; ~ ^~ 1 warning generated.如果你直接赋值,也会有警告: #include int main(void) { char j; j = 1000; }但是对值进行增加操作(例如,使用 +=)就不会有警告: #include int main(void) { char j = 0; j += 1000; } 浮点数浮点类型可以表示的数值范围比整数大得多,还可以表示整数无法表示的分数。 使用浮点数时,我们将数表示成小数乘以 10 的幂。 你可能见过浮点数被写成 1.29e-3 -2.3e+5和其它的一些看起来很奇怪的形式。 下面的几种类型: float double long double是用来表示带有小数点的数字(浮点类型)的。这几种类型都可以表示正数和负数。 任何 C 的实现都必须满足的最小要求是 float 可以表示范围在 10^-37 到 10^+37 之间的数,这通常用 32 位比特实现。 double 可以表示一组更大范围的数,long double 可以保存的数还要更多。 与整数一样,浮点数的确切值取决于具体实现。 在现代的 Mac 上,float 用 32 位表示,精度为 24 个有效位,剩余 8 位被用来编码指数部分。 double 用 64 位表示,精度为 53 个有效位,剩余 11 为用于编码指数部分。 long double 类型用 80 位表示,精度为 64 位有效位,剩余 15 位被用来编码指数部分。 你如何能在自己的计算机上确定这些类型的大小呢?你可以写一个程序来干这事儿: #include int main(void) { printf("char size: %lu bytes\n", sizeof(char)); printf("int size: %lu bytes\n", sizeof(int)); printf("short size: %lu bytes\n", sizeof(short)); printf("long size: %lu bytes\n", sizeof(long)); printf("float size: %lu bytes\n", sizeof(float)); printf("double size: %lu bytes\n", sizeof(double)); printf("long double size: %lu bytes\n", sizeof(long double)); }在我的系统上(一台现代 Mac),输出如下: char size: 1 bytes int size: 4 bytes short size: 2 bytes long size: 8 bytes float size: 4 bytes double size: 8 bytes long double size: 16 bytes 常量咱们现在来谈谈常量。 常量的声明与变量类似,不同之处在于常量声明的前面带有 const 关键字,并且你总是需要给常量指定一个值。 就像这样: const int age = 37;这在 C 中是完全有效的,尽管通常情况下将常量声明为大写,就像这样: const int AGE = 37;虽然这只是一个惯例,但是在你阅读或编写 C 程序时,他能给你提供巨大的帮助,因为它提高了可读性。大写的名字意味着常量,小写的名字意味着变量。 常量的命名规则与变量相同:可以包含任意大小写字母、数字和下划线,但是不能以数字开头。AGE 和 Age10 都是有效的变量名,而 1AGE 就不是了。 另一种定义常量的方式是使用这种语法: #define AGE 37在这种情况下,你不需要添加类型,也不需要使用等于符号 =,并且可以省略末尾的分号。 C 编译器将会在编译时从声明的值推断出相应的类型。 运算符C 给我们提供了各种各样的运算符,我们可以用来操作数据。 特别地,我们可以识别不同分组的运算符: 算术运算符 比较运算符 逻辑运算符 复合赋值运算符 位运算符 指针运算符 结构运算符 混合运算符在这一节中,我们将用两个假想的变量 a 和 b 举例,详细介绍所有这些运算符。 为了简单起见,我将不会介绍位运算符、结构运算符和指针运算符。 算术运算符我将把这个小型分组分为二元运算符和一元运算符。 二元操作符需要两个操作数: 操作符 名字 示例 = 赋值 a = b + 加 a + b - 减 a - b * 乘 a * b / 除 a / b % 取模 a % b一元运算符只需要一个操作数: 运算符 名字 示例 + 一元加 +a - 一元减 -a ++ 自增 a++ or ++a -- 自减 a-- or --aa++ 与 ++a 的区别在于:a++ 在使用 a 之后才自增它的值,而 ++a 会在使用 a 之前自增它的值。 例如: int a = 2; int b; b = a++ /* b 为 2,a 为 3 */ b = ++a /* b 为 4,a 为 4 */这也适用于递减运算符。 比较运算符 运算符 名字 示例 == 相等 a == b != 不相等 a != b > 大于 a > b = 大于等于 a >= b |
【本文地址】
今日新闻 |
推荐新闻 |