|
梯度下降法 首先你得先了解一下梯度的概念:梯度的本意是一个向量(矢量),表示某一函数(该函数一般是二元及以上的)在该点处的方向导数沿着该方向取得最大值,即函数在该点处沿着该方向(此梯度的方向)变化最快,变化率最大(为该梯度的模)。 当函数是一元函数时,梯度就是导数。这里我们用一个最简单的例子来讲解梯度下降法,然后推广理解更为复杂的函数。 还是用上面的例子,有n组数据,自变量x(x1,x2,…,xn),因变量y(y1,y2,…,yn),但这次我们假设它们之间的关系是:f(x)=ax。记J(a)为f(x)和y之间的差异,即 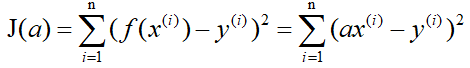 在梯度下降法中,需要我们先给参数a赋一个预设值,然后再一点一点的修改a,直到J(a)取最小值时,确定a的值。下面直接给出梯度下降法的公式(其中α为正数): 在梯度下降法中,需要我们先给参数a赋一个预设值,然后再一点一点的修改a,直到J(a)取最小值时,确定a的值。下面直接给出梯度下降法的公式(其中α为正数):  下面解释一下公式的意义,J(a)和a的关系如下图, 下面解释一下公式的意义,J(a)和a的关系如下图, 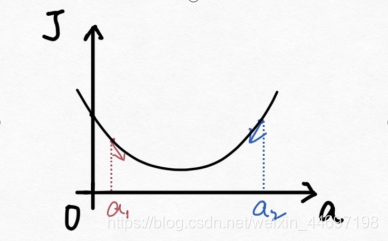 假设给a取的预设值是a1的话,那么a对J(a)的导数为负数,则 假设给a取的预设值是a1的话,那么a对J(a)的导数为负数,则 也为负数,所以 也为负数,所以  意味着a向右移一点。然后重复这个动作,直到J(a)到达最小值。 同理,假设给a取的预设值是a2的话,那么a对J(a)的导数为正数,则 意味着a向左移一点。然后重复这个动作,直到J(a)到达最小值。 所以我们可以看到,不管a的预设值取多少,J(a)经过梯度下降法的多次重复后,最后总能到达最小值。 这里再举个生活中的栗子,梯度下降法中随机给a赋一个预设值就好比你随机出现在一个山坡上,然后这时候你想以最快的方式走到山谷的最低点,那么你就得判断你的下一步该往那边走,走完一步之后同样再次判断下一步的方向,以此类推就能走到山谷的最低点了。而公式中的α我们称它为学习率,在栗子中可以理解为你每一步跨出去的步伐有多大,α越大,步伐就越大。(实际中α的取值不能太大也不能太小,太大会造成损失函数J接近最小值时,下一步就越过去了。好比在你接近山谷的最低点时,你步伐太大一步跨过去了,下一步往回走的时候又是如此跨过去,永远到达不了最低点;α太小又会造成移动速度太慢,因为我们当然希望在能确保走到最低点的前提下越快越好。) 到这里,梯度下降法的思想你基本就理解了,只不过在栗子中我们是用最简单的情况来说明,而事实上梯度下降法可以推广到多元线性函数上,这里直接给出公式,理解上(需要你对多元函数的相关知识有了解)和上面的栗子殊途同归。 假设有n组数据,其中目标值(因变量)与特征值(自变量)之间的关系为: 意味着a向右移一点。然后重复这个动作,直到J(a)到达最小值。 同理,假设给a取的预设值是a2的话,那么a对J(a)的导数为正数,则 意味着a向左移一点。然后重复这个动作,直到J(a)到达最小值。 所以我们可以看到,不管a的预设值取多少,J(a)经过梯度下降法的多次重复后,最后总能到达最小值。 这里再举个生活中的栗子,梯度下降法中随机给a赋一个预设值就好比你随机出现在一个山坡上,然后这时候你想以最快的方式走到山谷的最低点,那么你就得判断你的下一步该往那边走,走完一步之后同样再次判断下一步的方向,以此类推就能走到山谷的最低点了。而公式中的α我们称它为学习率,在栗子中可以理解为你每一步跨出去的步伐有多大,α越大,步伐就越大。(实际中α的取值不能太大也不能太小,太大会造成损失函数J接近最小值时,下一步就越过去了。好比在你接近山谷的最低点时,你步伐太大一步跨过去了,下一步往回走的时候又是如此跨过去,永远到达不了最低点;α太小又会造成移动速度太慢,因为我们当然希望在能确保走到最低点的前提下越快越好。) 到这里,梯度下降法的思想你基本就理解了,只不过在栗子中我们是用最简单的情况来说明,而事实上梯度下降法可以推广到多元线性函数上,这里直接给出公式,理解上(需要你对多元函数的相关知识有了解)和上面的栗子殊途同归。 假设有n组数据,其中目标值(因变量)与特征值(自变量)之间的关系为: 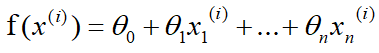 其中i表示第i组数据,损失函数为: 其中i表示第i组数据,损失函数为: 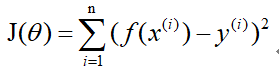 梯度下降法: 梯度下降法: 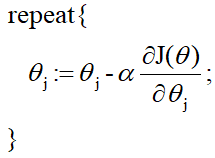 正规方程 (这里需要用到矩阵的知识) 正规方程一般用在多元线性回归中,原因等你看完也就能理解为什么。所以这里不再用一元线性回归举栗子了。 同样,假设有n组数据,其中目标值(因变量)与特征值(自变量)之间的关系为: 其中i表示第i组数据,这里先直接给出正规方程的公式: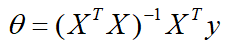 推导过程如下: 记矩阵 推导过程如下: 记矩阵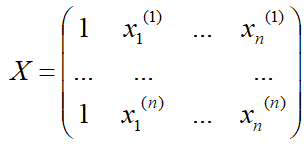 向量 向量 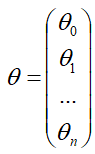  则 则 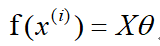 损失函数为: 损失函数为: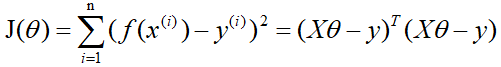 对损失函数求导并令其为0,有 对损失函数求导并令其为0,有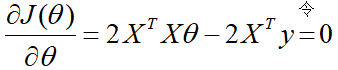 解得 到此,就求出了所有系数θ。不过正规方程需要注意的是 解得 到此,就求出了所有系数θ。不过正规方程需要注意的是 在实际中可能会出现是奇异矩阵,往往是因为特征值之间不独立。这时候需要对特征值进行筛选,剔除那些存在线性关系的特征值(好比在预测房价中,特征值1代表以英尺为尺寸计算房子,特征值2代表以平方米为尺寸计算房子,这时特征值1和特征值2只需要留1个即可)。 在实际中可能会出现是奇异矩阵,往往是因为特征值之间不独立。这时候需要对特征值进行筛选,剔除那些存在线性关系的特征值(好比在预测房价中,特征值1代表以英尺为尺寸计算房子,特征值2代表以平方米为尺寸计算房子,这时特征值1和特征值2只需要留1个即可)。
|