自然语言处理NLP(11) |
您所在的位置:网站首页 › 篇章结构分析怎么写好 › 自然语言处理NLP(11) |
自然语言处理NLP(11)
|
在上一部分中,我们介绍了语义分析的基本内容(自然语言处理NLP(10)——语义分析),重点介绍了格文法和语义角色标注(SRL)。 在这一部分中,我们将介绍篇章分析相关内容。 在介绍具体内容之前,我们首先要理解这样一个问题:什么是篇章? 篇章是由一个以上的句子(sentence)或语段(utterance)构成的有组织、有意义的自然语言文本整体。一篇文章、一段会话等都可以看成篇章。构成篇章的句子(或语段)彼此之间在形式上相互衔接,在意义上前后连贯。 这个定义有点太抽象了,我们举几个例子简单梳理一下: 小明学习刻苦,成绩每年进步,考上理想大学。花是红的,人工智能飞速发展,今天傍晚有雨。考上理想大学,成绩每年进步,小明学习刻苦。(对话) S1:电话铃响了 S2:我正在看书 S1:哦,好吧上述四个例子之中,1、4属于篇章,而2、3不属于。 大家对照着上面的定义看一看就明白是怎么一回事儿了 ,在这里重点解释一下4。 乍一看4的三句话是毫无关联的,但是在具体的语境、意图之下是很容易理解的,S2的回应在这段对话中可以很容易地理解为我正在看书不太方便接电话,因此也算作前后连贯的篇章。 篇章分析主要分为篇章连贯性分析和篇章衔接性分析两个部分。在这里我们主要对后者进行介绍,重点对中心理论进行介绍。值得一提的是,篇章衔接性分析与语义消歧有着紧密的联系。 【一】篇章衔接性分析 1. 浅层衔接理论Halliday 提出的浅层衔接理论是最早研究篇章衔接关系的理论体系。浅层衔接理论指出:当篇章中某个成分的解释依赖于篇章中另一个成分的解释时,这两个成分之间就产生了衔接关系。 衔接方式主要有如下几种: 大家可能对“指代消解”这个名词很熟悉,但是“指代”这件事情究竟指的是什么呢? 用一个抽象的概念来描述“指代”,就是:篇章中的一个语言单位(通常是词或短语)与之前出现的语言单位存在特殊语义关联,其语义解释依赖于前者。 像往常一样,我们举几个例子: 李明怕高妈妈一人呆在家里寂寞,他便将家里的电视搬了过来。人们都想创造美好的世界留给孩子,这可以理解,但不完全正确。上面例子中的加粗部分,很明显依赖于前文。 在语言学把用于指向的语言单位(上面例子中的粗体部分)称为照应语(或指代语Anaphor),被指向的语言单位(具体的实体)称为先行语(或先行词Antecedent)。 确定照应语所指的先行语的过程就是指代消解。 指代消解的分类根据语言学知识,从照应语的角度将指代消解分为三类: 按先行词与照应语出现的顺序分类 若照应语的位置在先行语之前则称为预指消解,当照应语位于先行语之后称为回指消解。 按照应语的抽象程度分类 根据指代的表现形式的抽象程度,指代消解分为名词消解、代词消解、零代词消解,具体有六种: 按照应语在句子中语义关系强弱程度分类 当先行语和照应语存在等价关系,并同时指向同一个实体时叫做共指。共指关系脱离上下文的语义仍旧独立存在,与上下文关系较弱。 (非等价)指代消解是指先行语与照应语之间存在着非对称关系并且和上下文的语义有着紧密联系,在不同的语义和语境下照应语指代的先行语是不同的。 中心理论认为篇章由三个分离但相互联系的部分组成:话语序列结构(语言结构),目的结构(说话者意图)和关注焦点状态(说话者注意力状态)。 中心理论对关注状态进行模型化,将关注焦点描述为“中心”,通过说话者注意力焦点来阐述语篇的衔接性,可以通过一张图来表示: 中心理论有两个要素: 中心:前看中心 C f C_f Cf,回视中心 C b C_b Cb,优先中心 C p C_p Cp话题关系:根据回视中心的变化状态来界定语篇结构的衔接性“中心”是话语中的语义实体,通常是名词性的。 一般来讲,每个话语单元有三个中心:前看中心 C f C_f Cf,回视中心 C b C_b Cb,优先中心 C p C_p Cp,其中 C f C_f Cf 是有序表,而 C b , C p C_b, C_p Cb,Cp 是唯一的。 a. 中心一个话语单元(utterance)通常包含若干个中心,它们根据语法关系的显著性和从左到右出现的线性顺序,形成一个中心序列,称为前看中心 C f C_f Cf。 优先中心 C p C_p Cp 是 C f C_f Cf 中排列第一的成分。 回视中心 C b C_b Cb 是在语义上同时出现在当前和前一个话语单元中排序最靠前的那个中心。 举个例子(我们假设两个句子是相邻的两个话语单元 U 1 , U 2 U_1, U_2 U1,U2): Cooper is standing around the corner. C f C_f Cf: Cooper, corner C p C_p Cp: Cooper C b C_b Cb: NULLHe is waiting for Grey. C f C_f Cf: He, Grey C p C_p Cp: He C b C_b Cb: He = Cooper b. 话题关系中心理论根据回视中心的变化状态将毗连着的语句关系分为四种,并由此来界定语篇结构的衔接性。 中心理论话题关系主要有四种: 延续话题 (continue)保持话题 (retain)顺畅转换 (smooth shift)不顺畅转换 (rough shift) 其优先级从上至下依次减弱。话题关系判定标准如下表所示: 了解了话题关系之后,我们举一个例子,试着用中心理论对下面两个语段略加分析: David loved Elizabeth. He had known her for years. At one time he had disliked her. She, on the other hand, hated him. She had always thought he was a creep.David loved Elizabeth. She, on the other hand, hated him. He had known her for years. She had always thought he was a creep. At one time he had disliked her. 我们可以看到,两个语段只有语句(话语单元)顺序有所不同。我们以语段1为例: U 1 U_1 U1: David loved Elizabeth. C f C_f Cf = {David, Elizabeth}; C p C_p Cp = David; C b C_b Cb = NULL. U 2 U_2 U2: He had known her for years. C f C_f Cf = {He (David), her (Elizabeth)}; C p C_p Cp = He (David); C b C_b Cb = He (David). (顺畅转换) U 3 U_3 U3: At one time he had disliked her. C f C_f Cf = {He (David), her (Elizabeth)}; C p C_p Cp = He (David); C b C_b Cb = He (David). (延续) U 4 U_4 U4: She, on the other hand, hated him. C f C_f Cf = {She (Elizabeth), him (David)}; C p C_p Cp = She (Elizabeth); C b C_b Cb = She (Elizabeth). (顺畅转换) U 5 U_5 U5: She had always thought he was a creep. C f C_f Cf = {She (Elizabeth), he (David)}; C p C_p Cp = She (Elizabeth); C b C_b Cb = She (Elizabeth). (延续) 值得一提的是,有研究者认为 U 2 U_2 U2 的话题关系是“延续”,基于话语单元 U 1 U_1 U1 并无回看中心 C b C_b Cb 的考虑,在这里我还是严格依照判定规则将其判定为“顺畅转换”,以免引起大家的误会。 以同样的方式对第二个语段进行分析,我们可以发现,语段2的连贯性比语段1要差(话题关系优先级底),于是我们可以得出结论:语段1在结构上比语段2流畅(衔接性好)。 c. 中心理论与指代消解如果在相邻的两个分析单元中,出现了语义上相关,但是又有区别的中心,把这些中心进行恰当地替换,可以使它们之间的关系更明朗,从而使话题之间的关系判断更明晰。 比如:一般代词被所指称的实际名词替换;同义词的替换;上义词与其下义词之间的替换;整体与其部分间的替换等等。 依靠这种替换技巧我们可以进行指代消解。 d. 中心理论的局限性 对篇章中心的刻画只能考虑局部的连贯性,没有对全局的连贯性加以考虑,所以消解工作只限于相邻的句子。主要用于人称代词消解,对零指代以及名词短语的消解效果不好。当需要指代的部分较多时很难做出准确判断。 4. 指代消解(后篇)在介绍了指代消解的概念和基础知识之后(本文第二部分),我们来看看指代消解的具体方法。与之前很多很多章节所介绍的相同,指代消解同样有基于规则的方法、概率统计方法和深度学习方法。 同样,我们秉持着一贯的“方法不重要,问题才重要”的想法,不在这里对其进行一一介绍,有兴趣的朋友们可以自行查阅相关资料。 基于中心理论的代词指代消解规则如果 C f ( U i − 1 ) C_f(U_{i-1}) Cf(Ui−1) 的某元素以代词形式出现在话语单元 U i U_i Ui 中,那么这个元素就可能是 C b ( U i ) C_b(U_i) Cb(Ui):如果有多个代词,那么其中之一是 C b ( U i ) C_b(U_i) Cb(Ui), 如果只有一个代词,那么它一定是 C b ( U i ) C_b(U_i) Cb(Ui)。 C b ( U i ) C_b(U_i) Cb(Ui) 的确定依赖于两个条件: 一定是在 U i U_i Ui 中出现的语义实体。该实体也一定在 C f ( U i − 1 ) C_f(U_{i-1}) Cf(Ui−1) ( U i − 1 U_{i-1} Ui−1)中出现过。如果 U i U_i Ui 中有多个实体都在 U i − 1 U_{i-1} Ui−1 中出现过,那么,作为 C b ( U i ) C_b(U_i) Cb(Ui) 出现的实体在 C f ( U i − 1 ) C_f(U_{i-1}) Cf(Ui−1) 中应有更高的排位。看起来有很多内容,但是如果理解了上文所介绍的中心理论的话,这一part这其实很好理解。 本文中,我们主要介绍一种基于规则的方法:基于中心理论的代词消解算法BFP。 BFP代词消解算法算法思想: Step 1. 如果在话语单元 U i U_i Ui 中出现人称代词, 则从左至右顺序检验 C f ( U i − 1 ) C_f(U_{i-1}) Cf(Ui−1) 中的元素,直至同时满足词汇句法,约束和类型标准。将这样的元素作为先行语。 Step 2. 完全读取表述 U i U_i Ui,生成 C f ( U i ) C_f(U_i) Cf(Ui),对 C f ( U i ) C_f(U_i) Cf(Ui) 进行排序,计算 C b ( U i ) C_b(U_i) Cb(Ui)。 在这里我们举两个例子。 例1(我们假设下面是五个连续的话语单元): U 1 U_1 U1: The sentry was not dead. C b C_b Cb: NULL C f C_f Cf: {(The) sentry} U 2 U_2 U2: He was in fact, showing signs of reviving… C b C_b Cb: He ( = sentry) C f C_f Cf: {He (sentry), signs} U 3 U_3 U3: He was partially uniformed in a cavalry tunic. C b C_b Cb: He ( = sentry) C f C_f Cf: {He (sentry), tunic} U 4 U_4 U4: Mike stripped this from him and donned it. C b C_b Cb: him ( = sentry) C f C_f Cf: {Mike, this, him (sentry), it} U 5 U_5 U5: He tied and gagged the man. C b C_b Cb: He ( = Mike) C f C_f Cf: {He (Mike), (the) man} 例2: U 1 U_1 U1: Cooper is standing around the corner. C b C_b Cb: NULL C f C_f Cf: {Cooper, corner} C p C_p Cp: Cooper U 2 U_2 U2: He is waiting for Grey C b C_b Cb: He ( = Cooper) C f C_f Cf: {He (Cooper), Grey} C p C_p Cp: He U 3 U_3 U3: He intends to see film with him. 情况A: C b C_b Cb: He ( = Cooper) him = Grey C f C_f Cf: {He (Cooper), film, him (Grey)} C p C_p Cp: He (Cooper) 情况B: C b C_b Cb: He ( = Grey) him = Cooper C f C_f Cf: {He (Grey), film, him (Cooper)} C p C_p Cp: He (Grey) 根据中心理论,情况A、B的状态转换分别为连续和转换,而连续的优先级大于转换,所以将情况A视为分析结果。 在这一部分中,我们介绍了篇章分析的基本知识,主要介绍了指代消解和中心理论。 如果本文中某些表述或理解有误,欢迎各位大神批评指正。 到这里,自然语言处理领域的基本框架已逐渐有了雏形,该系列博文也不会再继续更新下去啦。 本来还想再聊一聊attention机制或者transformer这种,但是想想还是算了,因为毕竟不是在搞NLP,这些细节方面的知识可能理解已经落伍了,就不误导大家啦~ 笔者已经脱坑NLP转行研究差分隐私(differential privacy),今后可能会逐渐更新一些差分隐私方面的知识~ 谢谢! |
 其中红色圆圈部分是指代消解所重点关注的部分,我们重点从这个部分进行展开。
其中红色圆圈部分是指代消解所重点关注的部分,我们重点从这个部分进行展开。 其中,零代词在中文句子中出现的频率很高。 出于文章篇幅的考虑,这个六种指代并未举例说明,有疑问或者感兴趣的朋友可以自行查阅相关资料或者私信交流~
其中,零代词在中文句子中出现的频率很高。 出于文章篇幅的考虑,这个六种指代并未举例说明,有疑问或者感兴趣的朋友可以自行查阅相关资料或者私信交流~ 非等价指代消解的目标是:寻找照应语对应的先行语; 而共指消解的目标是:发现指向相同实体的语言表示单元,很有可能包括多语篇任务。
非等价指代消解的目标是:寻找照应语对应的先行语; 而共指消解的目标是:发现指向相同实体的语言表示单元,很有可能包括多语篇任务。 其中
U
i
U_i
Ui 表示话语单元。
其中
U
i
U_i
Ui 表示话语单元。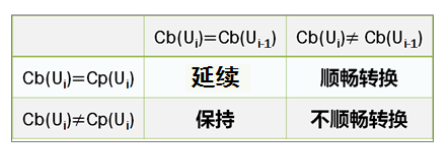 其中,
C
b
(
U
i
)
C_b(U_i)
Cb(Ui) 是当前话语单元回指中心,
C
b
(
U
i
−
1
)
C_b(U_{i-1})
Cb(Ui−1) 是上一个话语单元回指中心,
C
p
(
U
i
)
C_p(U_i)
Cp(Ui)是当前话语单元优先中心。
其中,
C
b
(
U
i
)
C_b(U_i)
Cb(Ui) 是当前话语单元回指中心,
C
b
(
U
i
−
1
)
C_b(U_{i-1})
Cb(Ui−1) 是上一个话语单元回指中心,
C
p
(
U
i
)
C_p(U_i)
Cp(Ui)是当前话语单元优先中心。【本文地址】
今日新闻 |
推荐新闻 |