学算法先学数据结构?是否是无稽之谈? |
您所在的位置:网站首页 › 算法导论值得看吗 › 学算法先学数据结构?是否是无稽之谈? |
学算法先学数据结构?是否是无稽之谈?
|
前言
「 数据结构 」 和 「 算法 」 是密不可分的,两者往往是「 相辅相成 」的存在,所以,在学习 「 数据结构 」 的过程中,不免会遇到各种「 算法 」。 到底是先学 数据结构 ,还是先学 算法,我认为不必纠结这个问题,一定是一起学的。 数据结构 常用的操作一般为:「 增 」「 删 」「 改 」「 查 」。基本上所有的数据结构都是围绕这几个操作进行展开的。 那么这篇文章,作者将主要来聊聊: 「 算法和数据结构 」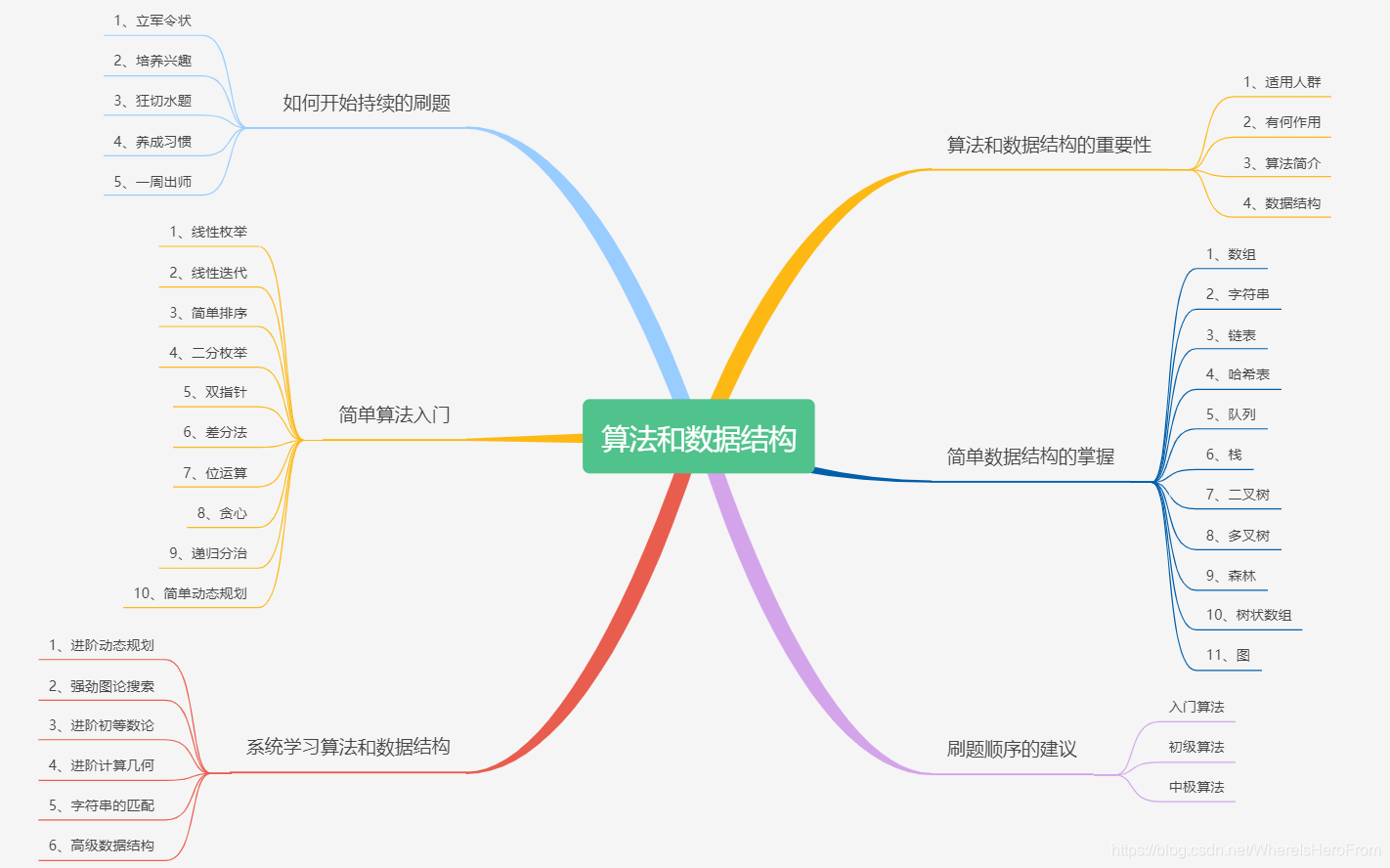
10分钟过一遍算法学习路线 | 面试 | 蓝桥杯 | ACM 完整版视频地址 在学习数据结构的过程中,如果你能够自己把图画出来,并且能够描述整个 「 增 」「 删 」「 改 」「 查 」 的过程,那么说明你已经真正理解了数据结构的真谛,来看下下面几张图: 如果你只是想学会写代码,或许 「 算法与数据结构 」 并不是那么重要,但是,想要进一步发展自己的事业,「 算法与数据结构 」 是必不可少的。 现在一些主流的大厂,诸如:字节、网易、腾讯、阿里、美团、京东、滴滴 等等,在面时都会让候选人写一道 「 算法题 」 ,如果你敲不出来,可能你的 offer 年包就打了骨折,或者直接与 offer 失之交臂,都是有可能的。 当然,它不能完全代表你的编码能力(因为有些算法确实是很巧妙,加上紧张的面试氛围,想不出来其实也是正常的),但是你能确保面试官是这么想的吗?我们要做的是十足的准备,既然决定出来,offer 当然是越高越好,毕竟大家都要养家糊口,房价又这么贵,如果能够在算法这一块取得先机,也不失为一个捷径。 所以,你问我算法和数据结构有什么用?我可以很明确的说,和你的年薪息息相关。当然,面试中 「算法与数据结构」 知识的考察只是面试内容的一部分。其它还有很多面试要考察的内容,当然不是本文主要核心内容,这里就不做展开了。 2、如何有效的学习这篇文章中,我会着重讲解一些常见的 「 算法和数据结构 」 的设计思想,并且配上动图。主要针对面试中常见的问题和新手朋友们比较难理解的点进行解析。当然,后面也会给出面向算法竞赛的提纲,如果有兴趣深入学习的欢迎在评论区留言,一起成长交流。 零基础学算法的最好方法,莫过于 「 刷题 」 了。任何事情都是需要 「 坚持 」 的,刷题也一样,没有刷够足够的题,就很难做出系统性的总结。所以上大学的时候,我花了三年的时间来刷题, 工作以后还是会抽点时间出来刷题。 当然,每天不需要花太多时间在这个上面,把这个事情做成一个 「 规划 」 ,按照长期去推进。反正也没有 KPI 压力,就当成是工作之余的一种消遣,还能够提升思维能力。所谓: 「 十年磨一剑,今朝把示君 」 。 3、坚持并且把它当成兴趣相信看我文章的大多数都是「 大学生 」,能上大学的都是「 精英 」,那么我们自然要「 精益求精 」,如果你还是「 大一 」,那么太好了,你拥有大把时间,当然你可以选择「 刷剧 」,然而,「 学好算法 」,三年后的你自然「 不能同日而语 」。 如果你满足如下: ( 1 ) (1) (1) 有强烈欲望「 想要学好C语言 」的人 ( 2 ) (2) (2) 有强烈欲望「 想要学好C++ 」的人 ( 3 ) (3) (3) 有强烈欲望「 想要学好数据结构 」的人 ( 4 ) (4) (4) 有强烈欲望「 想学好算法 」的人 ( 5 ) (5) (5) 有强烈欲望「 想进大厂 」的人 如果你满足以上任意一点,那么,我们就是志同道合的人啦! 🔥联系作者,或者扫作者主页二维码加群,加入我们吧🔥 4、首先要有语言基础 单纯学习语言未免太过枯燥乏味,所以建议一边学习一遍刷题,养成每天刷题的习惯,在刷题的过程中巩固语法,每过一个题相当于是一次正反馈,能够让你在刷题旅途中酣畅淋漓,从而更好的保证你一直坚持下去,在没有任何算法基础的情况下,可以按照我提供的专栏来刷题,这也是上上个视频提到的 九日集训 的完整教材,主要有以下几个内容: 这个专栏主要讲解了一些 LeetCode 刷题时的一些难点和要点,主要分为以下几个章节,并且会持续补充一些方法论的文章。文章有试读,可以简单先看一看试读文章。 🍠《LeetCode零基础指南》🍠 导读 (第一讲)函数 (第二讲)循环 (第三讲)数组 (第四讲)指针 (第五讲)排序 (第六讲)贪心 (第七讲)矩阵 (第八讲)二级指针 (第九讲)简单递归 5、九日集训「 九日集训 」是博主推出的一个能够白嫖付费专栏「 LeetCode零基础指南 」的活动。通过 「 专栏中的联系方式 」 或者 「 本文末尾的联系方式 」 联系博主,进行报名即可参加。九日一个循环,第二期计划 「 2021.12.02 」 开启。 玩法很简单,每天会开启一篇试读文章,要求有三点: 1)阅读完文章后,课后习题 「 全部刷完 」(都能在文中找到解法,需要自己敲一遍代码); 2)写 「 学习报告 」 并发布社区 九日集训(每日打卡) 频道 3)在 「 打卡帖 」 提交 「 学习报告 」 链接; 完成以上三点后方可晋级到下一天,所有坚持到 9天 的同学,会成为 「 英雄算法联盟合伙人 」 群成员,只限500个名额,优胜劣汰,和精英在一起,无论是沟通,学习,都能有更好的发展,你接触到的人脉也都是不一样的,等找工作的时候,我也会为大家打通 hr 和猎头,让你前程无忧~ 详细规则参见:九日集训规则详解。 目前第四轮「 九日集训 」已经进行到第四天,即将开启第五轮。 6、零基础如何学习算法 数学是算法的基石,可以先从刷数学题开始。 LeetCode上的题目相比ACM来说,数学题较少,所以对数学有恐惧的同学也不必担心,比较常见的数学题主要有:位运算,线性代数,计算几何,组合数学 ,数论,概率论。 位运算主要有:位与、位或、按位取反、异或、左移 和 右移。对应的文章可以看: (第42讲) 位运算 (位与) 入门 (第44讲) 位运算 (位或) 入门 (第46讲) 位运算 (异或) 入门 (第48讲) 位运算 (左移) 入门 (第49讲) 位运算 (右移) 入门 (第50讲) 位运算 (取反) 入门位运算是计算机的精华所在,是必须掌握的内容。大概每个运算操作刷 三 到 五 题就基本有感觉了。 2)线性代数线性代数在刷题中,主要内容有 矩阵运算 和 高斯消元。矩阵在程序中的抽象就是二维数组。如下: (第七讲)矩阵高斯消元是求解多元一次方程组的,一般在竞赛中会遇到,面试一般不问,因为面试官可能也不会。 夜深人静写算法 (十六) 高斯消元 3)计算几何数论 是 ACM 中一个比较重要的内容,至少一旦出现,一定不会是一个水题,编码量较大,但是在 LeetCode 中题型较少,可以适当掌握一些基础内容即可。对应文章如下: 夜深人静写算法 (四)- 计算几何入门 夜夜深人静写算法(十二)- 凸包 4)数论数论 是 ACM 中一个比较重要的内容,但是在 LeetCode 中题型较少,可以适当掌握一些基础内容即可。对应文章如下: 夜深人静写算法 (三) 初等数论入门 5)组合数学 和 概率论组合数学 和 概率论,在 LeetCode 中题目较少,有兴趣可以刷一刷,没有兴趣就不要去刷了,毕竟兴趣才是最好的老师。对应的文章如下: (第4讲) 组合数 (第30讲) 概率问题 7、零基础如何学习数据结构学习数据结构之前,选择一款相对来说心仪的教程是必不可少的,我这里准备了一个用动画来解释数据结构的教程,在我这也有,就是: 🌳《画解数据结构》🌳 这是我目前来说,写的最用心的一个教程,里面汇集了大量的动图,目前更新已经过半,好评如潮。 当然,一边学习,一边做一些练习题是必不可少的,接下来就是推荐一个我自己整理的题集了,这个题集汇集了大量的算法。可以帮你在前行的路上扫平不少障碍。 🌌《算法入门指引》🌌 在看上述题目时,如果遇到难以解决的问题,可以参考如下解题报告专栏: 🌌《算法解题报告》🌌 8、数据结构和算法是相辅相成的如果你在刷题的过程中,已经爱上了算法,那么恭喜你,你将会无法自拔,一直刷题一直爽,在遇到一些高端的算法时,也不要惊慌,这里推荐一个竞赛选手金典图文教程,如下: 💜《夜深人静写算法》💜 二、数据结构是根基学习算法,数据结构是根基,没有一些数据结构做支撑,这个算法都没有落脚点,任何一个简单的算法都是需要数据结构来支撑的,比如最简单的算法, 1、数组内存结构:内存空间连续实现难度:简单下标访问:支持分类:静态数组、动态数组插入时间复杂度: O ( n ) O(n) O(n)查找时间复杂度: O ( n ) O(n) O(n)删除时间复杂度: O ( n ) O(n) O(n) 一、概念 1、顺序存储 顺序存储结构,是指用一段地址连续的存储单元依次存储线性表的数据元素。 在编程语言中,用一维数组来实现顺序存储结构,在C语言中,把第一个数据元素存储到下标为 0 的位置中,把第 2 个数据元素存储到下标为 1 的位置中,以此类推。 3、长度和容量 数组的长度指的是数组当前有多少个元素,数组的容量指的是数组最大能够存放多少个元素。如果数组元素大于最大能存储的范围,在程序上是不允许的,可能会产生意想不到的问题,实现上是需要规避的。 索引 就是通过 数组下标 寻找 数组元素 的过程。C语言实现如下: DataType SeqListIndex(struct SeqList *sq, int i) { return sq->data[i]; // (1) } ( 1 ) (1) (1) 调用方需要注意 i i i 的取值必须为非负整数,且小于数组最大长度。否则有可能导致异常,引发崩溃。索引的算法时间复杂度为 O ( 1 ) O(1) O(1)。 2、查找
2、查找
查找 就是通过 数组元素 寻找 数组下标 的过程,是索引的逆过程。 对于有序数组,可以采用 二分 进行查找,时间复杂度为 O ( l o g 2 n ) O(log_2n) O(log2n);对于无序数组,只能通过遍历比较,由于元素可能不在数组中,可能遍历全表,所以查找的最坏时间复杂度为 O ( n ) O(n) O(n)。 简单介绍一个线性查找的例子,实现如下: DataType SeqListFind(struct SeqList *sq, DataType dt) { int i; for(i = 0; i length; ++i) { // (1) if(sq->data[i] == dt) { return i; // (2) } } return -1; // (3) } ( 1 ) (1) (1) 遍历数组元素; ( 2 ) (2) (2) 对数组元素 和 传入的数据进行判等,一旦发现相等就返回对应数据的下标; ( 3 ) (3) (3) 当数组遍历完还是找不到,说明这个数据肯定是不存在的,直接返回 − 1 -1 −1。 3、获取长度
3、获取长度
获取 数组的长度 指的是查询当前有多少元素。可以直接用结构体的内部变量。C语言代码实现如下: DataType SeqListGetLength(struct SeqList *sq) { return sq->length; } 4、插入插入接口定义为:在数组的第 k k k 个元素前插入一个数 v v v。由于数组是连续存储的,那么从 k k k 个元素往后的元素都必须往后移动一位,当 k = 0 k=0 k=0 时,所有元素都必须移动,所以最坏时间复杂度为 O ( n ) O(n) O(n)。C语言代码实现如下: int SeqListInsert(struct SeqList *sq, int k, DataType v) { int i; if(sq->length == MAXN) { return 0; // (1) } for(i = sq->length; i > k; --i) { sq->data[i] = sq->data[i-1]; // (2) } sq->data[k] = v; // (3) sq->length ++; // (4) return 1; // (5) } ( 1 ) (1) (1) 当元素个数已满时,返回 0 0 0 代表插入失败; ( 2 ) (2) (2) 从第 k k k 个数开始,每个数往后移动一个位置,注意必须逆序; ( 3 ) (3) (3) 将第 k k k 个数变成 v v v; ( 4 ) (4) (4) 插入了一个数,数组长度加一; ( 5 ) (5) (5) 返回 1 1 1 代表插入成功; 5、删除插入接口定义为:将数组的第 k k k 个元素删除。由于数组是连续存储的,那么第 k k k 个元素删除,往后的元素势必要往前移动一位,当 k = 0 k=0 k=0 时,所有元素都必须移动,所以最坏时间复杂度为 O ( n ) O(n) O(n)。C语言代码实现如下: int SeqListDelete(struct SeqList *sq, int k) { int i; if(sq->length == 0) { return 0; // (1) } for(i = k; i length - 1; ++i) { sq->data[i] = sq->data[i+1]; // (2) } sq->length --; // (3) return 1; // (4) } ( 1 ) (1) (1) 返回0代表删除失败; ( 2 ) (2) (2) 从前往后; ( 3 ) (3) (3) 数组长度减一; ( 4 ) (4) (4) 返回1代表删除成功;想要了解更多数组相关内容,可以参考:《画解数据结构》(1 - 1)- 数组。 2、链表内存结构:内存空间连续不连续,看具体实现实现难度:一般下标访问:不支持分类:单向链表、双向链表、循环链表、DancingLinks插入时间复杂度: O ( 1 ) O(1) O(1)查找时间复杂度: O ( n ) O(n) O(n)删除时间复杂度: O ( 1 ) O(1) O(1) 一、概念 对于顺序存储的结构,如数组,最大的缺点就是:插入 和 删除 的时候需要移动大量的元素。所以,基于前人的智慧,他们发明了链表。 1、链表定义链表 是由一个个 结点 组成,每个 结点 之间通过 链接关系 串联起来,每个 结点 都有一个 后继节点,最后一个 结点 的 后继结点 为 空结点。如下图所示:
 3、结点的创建
我们通过 C语言 中的库函数malloc来创建一个 链表结点,然后对 数据域 和 指针域 进行赋值,代码实现如下:
ListNode *ListCreateNode(DataType data) {
ListNode *node = (ListNode *) malloc ( sizeof(ListNode) ); // (1)
node->data = data; // (2)
node->next = NULL; // (3)
return node; // (4)
}
(
1
)
(1)
(1) 利用系统库函数malloc分配一块内存空间,用来存放ListNode即链表结点对象;
(
2
)
(2)
(2) 将 数据域 置为函数传参data;
(
3
)
(3)
(3) 将 指针域 置空,代表这是一个孤立的 链表结点;
(
4
)
(4)
(4) 返回这个结点的指针。创建完毕以后,这个孤立结点如下所示:
3、结点的创建
我们通过 C语言 中的库函数malloc来创建一个 链表结点,然后对 数据域 和 指针域 进行赋值,代码实现如下:
ListNode *ListCreateNode(DataType data) {
ListNode *node = (ListNode *) malloc ( sizeof(ListNode) ); // (1)
node->data = data; // (2)
node->next = NULL; // (3)
return node; // (4)
}
(
1
)
(1)
(1) 利用系统库函数malloc分配一块内存空间,用来存放ListNode即链表结点对象;
(
2
)
(2)
(2) 将 数据域 置为函数传参data;
(
3
)
(3)
(3) 将 指针域 置空,代表这是一个孤立的 链表结点;
(
4
)
(4)
(4) 返回这个结点的指针。创建完毕以后,这个孤立结点如下所示:  二、链表的创建 - 尾插法
那么接下来,让我们看下如何通过一个 数组中的数据 来创建一个链表。
1、算法描述
二、链表的创建 - 尾插法
那么接下来,让我们看下如何通过一个 数组中的数据 来创建一个链表。
1、算法描述
首先介绍 尾插法 ,顾名思义,即 从链表尾部插入 的意思,就是记录一个 链表尾结点,然后遍历给定数组,将数组元素一个一个插到链表的尾部,每插入一个结点,则将它更新为新的 链表尾结点。注意初始情况下,链表尾结点 为空。 2、动画演示
上图演示的是 尾插法 的整个过程,其中: head 代表链表头结点,创建完一个结点以后,它就保持不变了; tail 代表链表尾结点,即动图中的 绿色结点; vtx 代表正在插入链表尾部的结点,即动图中的 橙色结点,插入完毕以后,vtx 变成 tail; 看完这个动图,你应该已经大致理解了 链表的创建过程。那么接下来,我们用程序语言来描述一下整个过程,这里采用的是 C语言 的形式,如果你是 Java、C#、Python 技术栈的,也可以试着写出自己的版本。语言并不是关键,思维才是关键。 3、源码详解 C语言 实现如下: ListNode *ListCreateListByTail(int n, int a[]) { ListNode *head, *tail, *vtx; // (1) int idx; if(n next = head; // (4) head = vtx; // (5) } return head; // (6) }对应的注释如下: ( 1 ) (1) (1) head存储头结点的地址,初始为空链表, vtx存储当前正在插入结点的地址; ( 2 ) (2) (2) 总共需要插入 n n n 个结点,所以采用逆序的 n n n 次循环; ( 3 ) (3) (3) 创建一个元素值为a[i]的链表结点,注意,由于逆序,所以这里 i i i 的取值为 n − 1 → 0 n-1 \to 0 n−1→0; ( 4 ) (4) (4) 将当前创建的结点的 后继结点 置为 链表的头结点head; ( 5 ) (5) (5) 将链表头结点head置为vtx; ( 6 ) (6) (6) 返回链表头结点; 头插法 的代码量比 尾插法 少了三分之一,而且将 创建结点的逻辑 统一起来了。这句话什么意思呢?仔细观察可以发现,尾插法 在实现过程中,ListCreateNode在代码里出现了两次,而 头插法 只出现了一次,将流程简化了,所以还是推荐使用 头插法。 想要了解更多链表相关内容,可以参考:《画解数据结构》(1 - 3)- 链表。 3、哈希表内存结构:哈希表本身连续,但是衍生出来的结点逻辑上不连续实现难度:一般下标访问:不支持分类:正数哈希、字符串哈希、滚动哈希插入时间复杂度: O ( 1 ) O(1) O(1)查找时间复杂度: O ( 1 ) O(1) O(1)删除时间复杂度: O ( 1 ) O(1) O(1) 一、哈希表的概念 1、查找算法 当我们在一个 链表 或者 顺序表 中 查找 一个数据元素 是否存在 的时候,唯一的方法就是遍历整个表,这种方法称为 线性枚举。 由于它不是顺序结构,所以很多数据结构书上称之为 散列表,下文会统一采用 哈希表 的形式来说明,作为读者,只需要知道这两者是同一种数据结构即可。 我们把需要查找的数据,通过一个 函数映射,找到 存储数据的位置 的过程称为 哈希。这里涉及到几个概念: a)需要 查找的数据 本身被称为 关键字; b)通过 函数映射 将 关键字 变成一个 哈希值 的过程中,这里的 函数 被称为 哈希函数; c)生成 哈希值 的过程过程可能产生冲突,需要进行 冲突解决; d)解决完冲突以后,实际 存储数据的位置 被称为 哈希地址,通俗的说,它就是一个数组下标; e)存储所有这些数据的数据结构就是 哈希表,程序实现上一般采用数组实现,所以又叫 哈希数组。整个过程如下图所示: 为了方便下标索引,哈希表 的底层实现结构是一个数组,数组类型可以是任意类型,每个位置被称为一个槽。如下图所示,它代表的是一个长度为 8 的 哈希表,又叫 哈希数组。
关键字 是哈希数组中的元素,可以是任意类型的,它可以是整型、浮点型、字符型、字符串,甚至是结构体或者类。如下的 A、C、M 都可以是关键字; int A = 5; char C[100] = "Hello World!"; struct Obj { }; Obj M;哈希表的实现过程中,我们需要通过一些手段,将一个非整型的 关键字 转换成 数组下标,也就是 哈希值,从而通过 O ( 1 ) O(1) O(1) 的时间快速索引到它所对应的位置。 而将一个非整型的 关键字 转换成 整型 的手段就是 哈希函数。 4、哈希函数 哈希函数可以简单的理解为就是小学课本上那个函数,即
y
=
f
(
x
)
y = f(x)
y=f(x),这里的
f
(
x
)
f(x)
f(x) 就是哈希函数,
x
x
x 是关键字,
y
y
y 是哈希值。好的哈希函数应该具备以下两个特质: a)单射; b)雪崩效应:输入值
x
x
x 的
1
1
1 比特的变化,能够造成输出值
y
y
y 至少一半比特的变化; 单射很容易理解,图
(
a
)
(a)
(a) 中已知哈希值
y
y
y 时,键
x
x
x 可能有两种情况,不是一个单射;而图
(
b
)
(b)
(b) 中已知哈希值
y
y
y 时,键
x
x
x 一定是唯一确定的,所以它是单射。由于
x
x
x 和
y
y
y 一一对应,这样就从本原上减少了冲突。 哈希函数在生成 哈希值 的过程中,如果产生 不同的关键字得到相同的哈希值 的情况,就被称为 哈希冲突。 即对于哈希函数 y = f ( x ) y = f(x) y=f(x),当关键字 x 1 ≠ x 2 x_1 \neq x_2 x1=x2,但是却有 f ( x 1 ) = f ( x 2 ) f(x_1) = f(x_2) f(x1)=f(x2),这时候,我们需要进行冲突解决。 冲突解决方法有很多,主要有:开放定址法、再散列函数法、链地址法、公共溢出区法 等等。有关解决冲突的内容,下文会进行详细讲解。 6、哈希地址哈希地址 就是一个 数组下标 ,即哈希数组的下标。通过下标获得数据,被称为 索引。通过数据获得下标,被称为 哈希。平时工作的时候,和同事交流时用到的一个词 反查 就是说的 哈希。 二、常用哈希函数 1、直接定址法直接定址法 就是 关键字 本身就是 哈希值,表示成函数值就是 f ( x ) = x f(x) = x f(x)=x 例如,我们需要统计一个字符串中每个字符的出现次数,就可以通过这种方法。任何一个字符的范围都是 [ 0 , 255 ] [0, 255] [0,255],所以只要用一个长度为 256 的哈希数组就可以存储每个字符对应的出现次数,利用一次遍历枚举就可以解决这个问题。C代码实现如下: int i, hash[256]; for(i = 0; str[i]; ++i) { ++hash[ str[i] ]; }这个就是最基础的直接定址法的实现。hash[c]代表字符c在这个字符串str中的出现次数。 2、平方取中法平方取中法 就是对 关键字 进行平方,再取中间的某几位作为 哈希值。 例如,对于关键字 1314 1314 1314,得到平方为 1726596 1726596 1726596,取中间三位作为哈希值,即 265 265 265。 平方取中法 比较适用于 不清楚关键字的分布,且位数也不是很大 的情况。 3、折叠法折叠法 是将关键字分割成位数相等的几部分(注意最后一部分位数不够可以短一些),然后再进行求和,得到一个 哈希值。 例如,对于关键字 5201314 5201314 5201314,将它分为四组,并且相加得到: 52 + 01 + 31 + 4 = 88 52+01+31+4 = 88 52+01+31+4=88,这就是哈希值。 折叠法 比较适用于 不清楚关键字的分布,但是关键字位数较多 的情况。 4、除留余数法 除留余数法 就是 关键字 模上 哈希表 长度,表示成函数值就是
f
(
x
)
=
x
m
o
d
m
f(x) = x \ mod \ m
f(x)=x mod m 其中
m
m
m 代表了哈希表的长度,这种方法,不仅可以对关键字直接取模,也可以在 平方取中法、折叠法 之后再取模。 例如,对于一个长度为 4 的哈希数组,我们可以将关键字 模 4 得到哈希值,如图所示: 哈希数组的长度一般选择 2 的幂,因为我们知道取模运算是比较耗时的,而位运算相对较为高效。 选择 2 的幂作为数组长度,可以将 取模运算 转换成 二进制位与。 令 m = 2 k m = 2^k m=2k,那么它的二进制表示就是: m = ( 1 000...000 ⏟ k ) 2 m = (1\underbrace{000...000}_{\rm k})_2 m=(1k 000...000)2,任何一个数模上 m m m,就相当于取了 m m m 的二进制低 k k k 位,而 m − 1 = ( 111...111 ⏟ k ) 2 m-1 = (\underbrace{111...111}_{\rm k})_2 m−1=(k 111...111)2 ,所以和 位与 m − 1 m-1 m−1 的效果是一样的。即: x % S = = x & ( S − 1 ) x \ \% \ S == x \ \& \ (S - 1) x % S==x & (S−1) 除了直接定址法,其它三种方法都有可能导致哈希冲突,接下来,我们就来讨论下常用的一些哈希冲突的解决方案。 三、常见哈希冲突解决方案 1、开放定址法 1)原理讲解开放定址法 就是一旦发生冲突,就去寻找下一个空的地址,只要哈希表足够大,总能找到一个空的位置,并且记录下来作为它的 哈希地址。公式如下: f i ( x ) = ( f ( x ) + d i ) m o d m f_i(x) = (f(x)+d_i) \ mod \ m fi(x)=(f(x)+di) mod m 这里的 d i d_i di 是一个数列,可以是常数列 ( 1 , 1 , 1 , . . . , 1 ) (1, 1, 1, ...,1) (1,1,1,...,1),也可以是等差数列 ( 1 , 2 , 3 , . . . , m − 1 ) (1,2,3,...,m-1) (1,2,3,...,m−1)。 2)动画演示
上图中,采用的是哈希函数算法是 除留余数法,采用的哈希冲突解决方案是 开放定址法,哈希表的每个数据就是一个关键字,插入之前需要先进行查找,如果找到的位置未被插入,则执行插入;否则,找到下一个未被插入的位置进行插入;总共插入了 6 个数据,分别为:11、12、13、20、19、28。 这种方法需要注意的是,当插入数据超过哈希表长度时,不能再执行插入。 本文在第四章讲解 哈希表的现实 时采用的就是常数列的开放定址法。 2、再散列函数法 1)原理讲解再散列函数法 就是一旦发生冲突,就采用另一个哈希函数,可以是 平方取中法、折叠法、除留余数法 等等的组合,一般用两个哈希函数,产生冲突的概率已经微乎其微了。 再散列函数法 能够使关键字不产生聚集,当然,也会增加不少哈希函数的计算时间。 3、链地址法 1)原理讲解当然,产生冲突后,我们也可以选择不换位置,还是在原来的位置,只是把 哈希值 相同的用链表串联起来。这种方法被称为 链地址法。 2)动画演示
上图中,采用的是哈希函数算法是 除留余数法,采用的哈希冲突解决方案是 链地址法,哈希表的每个数据保留了一个 链表头结点 和 尾结点,插入之前需要先进行查找,如果找到的位置,链表非空,则插入尾结点并且更新尾结点;否则,生成一个新的链表头结点和尾结点;总共插入了 6 个数据,分别为:11、12、13、20、19、28。 4、公共溢出区法 1)原理讲解一旦产生冲突的数据,统一放到另外一个顺序表中,每次查找数据,在哈希数组中到的关键字和给定关键字相等,则认为查找成功;否则,就去公共溢出区顺序查找,这种方法被称为 公共溢出区法。 这种方法适合冲突较少的情况。 哈希表相关的内容,可以参考我的这篇文章:夜深人静写算法(九)- 哈希表 4、队列内存结构:看用数组实现,还是链表实现实现难度:一般下标访问:不支持分类:FIFO、单调队列、双端队列插入时间复杂度: O ( 1 ) O(1) O(1)查找时间复杂度:理论上不支持删除时间复杂度: O ( 1 ) O(1) O(1) 一、概念 1、队列的定义 队列 是仅限在 一端 进行 插入,另一端 进行 删除 的 线性表。 队列 又被称为 先进先出 (First In First Out) 的线性表,简称 FIFO 。 允许进行元素删除的一端称为 队首。如下图所示: 允许进行元素插入的一端称为 队尾。如下图所示: 队列的插入操作,叫做 入队。它是将 数据元素 从 队尾 进行插入的过程,如图所示,表示的是 插入 两个数据(绿色 和 蓝色)的过程: 队列的删除操作,叫做 出队。它是将 队首 元素进行删除的过程,如图所示,表示的是 依次 删除 两个数据(红色 和 橙色)的过程: 队列的清空操作,就是一直 出队,直到队列为空的过程,当 队首 和 队尾 重合时,就代表队尾为空了,如图所示: 对于一个队列来说只能获取 队首 数据,一般不支持获取 其它数据。 5、获取队列元素个数队列元素个数一般用一个额外变量存储,入队 时加一,出队 时减一。这样获取队列元素的时候就不需要遍历整个队列。通过 O ( 1 ) O(1) O(1) 的时间复杂度获取队列元素个数。 6、队列的判空当队列元素个数为零时,就是一个 空队,空队 不允许 出队 操作。 有关队列的更多内容,可以参考我的这篇文章:《画解数据结构》(1 - 6)- 队列 5、栈内存结构:看用数组实现,还是链表实现实现难度:一般下标访问:不支持分类:FILO、单调栈插入时间复杂度: O ( 1 ) O(1) O(1)查找时间复杂度:理论上不支持删除时间复杂度: O ( 1 ) O(1) O(1) 一、概念 1、栈的定义栈 是仅限在 表尾 进行 插入 和 删除 的 线性表。 栈 又被称为 后进先出 (Last In First Out) 的线性表,简称 LIFO 。 2、栈顶 栈 是一个线性表,我们把允许 插入 和 删除 的一端称为 栈顶。 和 栈顶 相对,另一端称为 栈底,实际上,栈底的元素我们不需要关心。 栈的插入操作,叫做 入栈,也可称为 进栈、压栈。如下图所示,代表了三次入栈操作: 栈的删除操作,叫做 出栈,也可称为 弹栈。如下图所示,代表了两次出栈操作: 一直 出栈,直到栈为空,如下图所示: 对于一个栈来说只能获取 栈顶 数据,一般不支持获取 其它数据。 2、获取栈元素个数栈元素个数一般用一个额外变量存储,入栈 时加一,出栈 时减一。这样获取栈元素的时候就不需要遍历整个栈。通过 O ( 1 ) O(1) O(1) 的时间复杂度获取栈元素个数。 3、栈的判空当栈元素个数为零时,就是一个空栈,空栈不允许 出栈 操作。 栈相关的内容,可以参考我的这篇文章:《画解数据结构》(1 - 5)- 栈 🌵7、二叉树优先队列 是 堆实现的,所以也属于 二叉树 范畴。它和队列不同,不属于线性表。 内存结构:内存结构一般不连续,但是有时候实现的时候,为了方便,一般是物理连续,逻辑不连续实现难度:较难下标访问:不支持分类:二叉树 和 多叉树插入时间复杂度:看情况而定查找时间复杂度:理论上 O ( l o g 2 n ) O(log_2n) O(log2n)删除时间复杂度:看情况而定 🌳8、多叉树内存结构:内存结构一般不连续,但是有时候实现的时候,为了方便,一般是物理连续,逻辑不连续实现难度:较难下标访问:不支持分类:二叉树 和 多叉树插入时间复杂度:看情况而定查找时间复杂度:理论上 O ( l o g 2 n ) O(log_2n) O(log2n)删除时间复杂度:看情况而定 一种经典的多叉树是字典树,可以参考我的这篇文章:夜深人静写算法(七)- 字典树 🌲9、森林 比较经典的森林是:并查集,可以参考我的这篇文章:夜深人静写算法(五)- 并查集 🍀10、树状数组 树状数组是用来做 单点更新,成端求和 的问题的,有关于它的内容,可以参考:夜深人静写算法(十三)- 树状数组 🌍11、图内存结构:不一定实现难度:难下标访问:不支持分类:有向图、无向图插入时间复杂度:根据算法而定查找时间复杂度:根据算法而定删除时间复杂度:根据算法而定 1、图的概念 在讲解最短路问题之前,首先需要介绍一下计算机中图(图论)的概念,如下:图 G G G 是一个有序二元组 ( V , E ) (V,E) (V,E),其中 V V V 称为顶点集合, E E E 称为边集合, E E E 与 V V V 不相交。顶点集合的元素被称为顶点,边集合的元素被称为边。对于无权图,边由二元组 ( u , v ) (u,v) (u,v) 表示,其中 u , v ∈ V u, v \in V u,v∈V。对于带权图,边由三元组 ( u , v , w ) (u,v, w) (u,v,w) 表示,其中 u , v ∈ V u, v \in V u,v∈V, w w w 为权值,可以是任意类型。图分为有向图和无向图,对于有向图, ( u , v ) (u, v) (u,v) 表示的是 从顶点 u u u 到 顶点 v v v 的边,即 u → v u \to v u→v;对于无向图, ( u , v ) (u, v) (u,v) 可以理解成两条边,一条是 从顶点 u u u 到 顶点 v v v 的边,即 u → v u \to v u→v,另一条是从顶点 v v v 到 顶点 u u u 的边,即 v → u v \to u v→u;2、图的存储 对于图的存储,程序实现上也有多种方案,根据不同情况采用不同的方案。接下来以图二-3-1所表示的图为例,讲解四种存储图的方案。
1)邻接矩阵 邻接矩阵是直接利用一个二维数组对边的关系进行存储,矩阵的第 i i i 行第 j j j 列的值 表示 i → j i \to j i→j 这条边的权值;特殊的,如果不存在这条边,用一个特殊标记 ∞ \infty ∞ 来表示;如果 i = j i = j i=j,则权值为 0 0 0。它的优点是:实现非常简单,而且很容易理解;缺点也很明显,如果这个图是一个非常稀疏的图,图中边很少,但是点很多,就会造成非常大的内存浪费,点数过大的时候根本就无法存储。 [ 0 ∞ 3 ∞ 1 0 2 ∞ ∞ ∞ 0 3 9 8 ∞ 0 ] \left[ \begin{matrix} 0 & \infty & 3 & \infty \\ 1 & 0 & 2 & \infty \\ \infty & \infty & 0 & 3 \\ 9 & 8 & \infty & 0 \end{matrix} \right] ⎣⎢⎢⎡01∞9∞0∞8320∞∞∞30⎦⎥⎥⎤2)邻接表 邻接表是图中常用的存储结构之一,采用链表来存储,每个顶点都有一个链表,链表的数据表示和当前顶点直接相邻的顶点的数据 ( v , w ) (v, w) (v,w),即 顶点 和 边权。它的优点是:对于稀疏图不会有数据浪费;缺点就是实现相对邻接矩阵来说较麻烦,需要自己实现链表,动态分配内存。如图所示, d a t a data data 即 ( v , w ) (v, w) (v,w) 二元组,代表和对应顶点 u u u 直接相连的顶点数据, w w w 代表 u → v u \to v u→v 的边权, n e x t next next 是一个指针,指向下一个 ( v , w ) (v, w) (v,w) 二元组。 在 C++ 中,还可以使用 vector 这个容器来代替链表的功能;
vector edges[maxn]; 在 C++ 中,还可以使用 vector 这个容器来代替链表的功能;
vector edges[maxn];
3)前向星 前向星是以存储边的方式来存储图,先将边读入并存储在连续的数组中,然后按照边的起点进行排序,这样数组中起点相等的边就能够在数组中进行连续访问了。它的优点是实现简单,容易理解;缺点是需要在所有边都读入完毕的情况下对所有边进行一次排序,带来了时间开销,实用性也较差,只适合离线算法。如图所示,表示的是三元组 ( u , v , w ) (u, v, w) (u,v,w) 的数组, i d x idx idx 代表数组下标。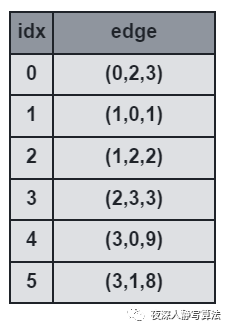 那么用哪种数据结构才能满足所有图的需求呢?接下来介绍一种新的数据结构 —— 链式前向星。 那么用哪种数据结构才能满足所有图的需求呢?接下来介绍一种新的数据结构 —— 链式前向星。
4)链式前向星 链式前向星和邻接表类似,也是链式结构和数组结构的结合,每个结点 i i i 都有一个链表,链表的所有数据是从 i i i 出发的所有边的集合(对比邻接表存的是顶点集合),边的表示为一个四元组 ( u , v , w , n e x t ) (u, v, w, next) (u,v,w,next),其中 ( u , v ) (u, v) (u,v) 代表该条边的有向顶点对 u → v u \to v u→v, w w w 代表边上的权值, n e x t next next 指向下一条边。具体的,我们需要一个边的结构体数组 edge[maxm],maxm表示边的总数,所有边都存储在这个结构体数组中,并且用head[i]来指向 i i i 结点的第一条边。边的结构体声明如下: struct Edge { int u, v, w, next; Edge() {} Edge(int _u, int _v, int _w, int _next) : u(_u), v(_v), w(_w), next(_next) { } }edge[maxm]; 初始化所有的head[i] = -1,当前边总数 edgeCount = 0;每读入一条 u → v u \to v u→v 的边,调用 addEdge(u, v, w),具体函数的实现如下: void addEdge(int u, int v, int w) { edge[edgeCount] = Edge(u, v, w, head[u]); head[u] = edgeCount++; } 这个函数的含义是每加入一条边 ( u , v , w ) (u, v, w) (u,v,w),就在原有的链表结构的首部插入这条边,使得每次插入的时间复杂度为 O ( 1 ) O(1) O(1),所以链表的边的顺序和读入顺序正好是逆序的。这种结构在无论是稠密的还是稀疏的图上都有非常好的表现,空间上没有浪费,时间上也是最小开销。调用的时候只要通过head[i]就能访问到由 i i i 出发的第一条边的编号,通过编号到edge数组进行索引可以得到边的具体信息,然后根据这条边的next域可以得到第二条边的编号,以此类推,直到 next域为 -1 为止。 for (int e = head[u]; ~e; e = edges[e].next) { int v = edges[e].v; ValueType w = edges[e].w; ... } 文中的 ~e等价于 e != -1,是对e进行二进制取反的操作(-1 的的补码二进制全是 1,取反后变成全 0,这样就使得条件不满足跳出循环)。 三、四个入门算法 1、排序 一般网上的文章在讲各种 「 排序 」 算法的时候,都会甩出一张 「 思维导图 」,如下:
I、例题描述 给你两个有序整数数组 n u m s 1 nums1 nums1 和 n u m s 2 nums2 nums2,请你将 n u m s 2 nums2 nums2 合并到 n u m s 1 nums1 nums1 中,使 n u m s 1 nums1 nums1 成为一个有序数组。初始化 n u m s 1 nums1 nums1 和 n u m s 2 nums2 nums2 的元素数量分别为 m m m 和 n n n 。你可以假设 n u m s 1 nums1 nums1 的空间大小等于 m + n m + n m+n,这样它就有足够的空间保存来自 n u m s 2 nums2 nums2 的元素。 样例输入: n u m s 1 = [ 1 , 2 , 3 , 0 , 0 , 0 ] , m = 3 , n u m s 2 = [ 2 , 5 , 6 ] , n = 3 nums1 = [1,2,3,0,0,0], m = 3, nums2 = [2,5,6], n = 3 nums1=[1,2,3,0,0,0],m=3,nums2=[2,5,6],n=3 样例输出: [ 1 , 2 , 2 , 3 , 5 , 6 ] [1,2,2,3,5,6] [1,2,2,3,5,6] 原题出处: LeetCode 88. 合并两个有序数组 II、基础框架 c++ 版本给出的基础框架代码如下: class Solution { public: void merge(vector& nums1, int m, vector& nums2, int n) { } };III、思路分析 这个题别想太多,直接把第二个数组的元素加到第一个数组元素的后面,然后直接排序就成。
IV、时间复杂度 STL 排序函数的时间复杂度为 O ( n l o g 2 n ) O(nlog_2n) O(nlog2n),遍历的时间复杂度为 O ( n ) O(n) O(n),所以总的时间复杂度为 O ( n l o g 2 n ) O(nlog_2n) O(nlog2n)。IV、源码详解 class Solution { public: void merge(vector& nums1, int m, vector& nums2, int n) { for(int i = m; i next == nullptr) { return nullptr; // (2) } ListNode *retNode = now->next; // (3) now->next = now->next->next; // (4) return retNode; } public: ListNode* reverseList(ListNode* head) { ListNode *doRemoveNode = head; // (5) while(doRemoveNode) { // (6) ListNode *newHead = removeNextAndReturn(doRemoveNode); // (7) if(newHead) { // (8) newHead->next = head; head = newHead; }else { break; // (9) } } return head; } }; ( 1 ) (1) (1) ListNode *removeNextAndReturn(ListNode* now)函数的作用是删除now的next节点,并且返回; ( 2 ) (2) (2) 本身为空或者下一个节点为空,返回空; ( 3 ) (3) (3) 将需要删除的节点缓存起来,供后续返回; ( 4 ) (4) (4) 执行删除 now->next 的操作; ( 5 ) (5) (5) doRemoveNode指向的下一个节点是将要被删除的节点,所以doRemoveNode需要被缓存起来,不然都不知道怎么进行删除; ( 6 ) (6) (6) 没有需要删除的节点了就结束迭代; ( 7 ) (7) (7) 删除 doRemoveNode 的下一个节点并返回被删除的节点; ( 8 ) (8) (8) 如果有被删除的节点,则插入头部; ( 9 ) (9) (9) 如果没有,则跳出迭代。VI、本题小知识 复杂问题简单化的最好办法就是将问题拆细,比如这个问题中,将一个节点取出来插到头部这件事情可以分为两步: 1)删除给定节点; 2)将删除的节点插入头部; 3、线性枚举 线性枚举,一般配合的 数据结构 是 【数组】 或者 【链表】,实现方式就是一个循环。正因为只有一个循环,所以线性枚举解决的问题一般比较简单,而且很容易从题目中看出来。I、例题描述 编写一个函数,将输入的字符串反转过来。输入字符串以字符数组 char[] 的形式给出。 必须原地修改输入数组、使用 O(1) 的额外空间解决这一问题。 样例输入: [ “ a ” , “ b ” , “ c ” , “ d ” ] [“a”, “b”, “c”, “d”] [“a”,“b”,“c”,“d”] 样例输出: [ “ d ” , “ c ” , “ b ” , “ a ” ] [ “d”, “c”, “b”, “a”] [“d”,“c”,“b”,“a”] 原题出处: LeetCode 344. 反转字符串 II、基础框架 c++ 版本给出的基础框架代码如下,要求不采用任何的辅助数组;也就是空间复杂度要求 O ( 1 ) O(1) O(1)。 class Solution { public: void reverseString(vector& s) { } };III、思路分析 翻转的含义,相当于就是 第一个字符 和 最后一个交换,第二个字符 和 最后第二个交换,… 以此类推,所以我们首先实现一个交换变量的函数 swap,然后再枚举 第一个字符、第二个字符、第三个字符 …… 即可。 对于第 i i i 个字符,它的交换对象是 第 l e n − i − 1 len-i-1 len−i−1 个字符 (其中 l e n len len 为字符串长度)。swap函数的实现,可以参考:《C语言入门100例》 - 例2 | 交换变量。 IV、时间复杂度 线性枚举的过程为 O ( n ) O(n) O(n),交换变量为 O ( 1 ) O(1) O(1),两个过程是相乘的关系,所以整个算法的时间复杂度为 O ( n ) O(n) O(n)。IV、源码详解 class Solution { public: void swap(char& a, char& b) { // (1) char tmp = a; a = b; b = tmp; } void reverseString(vector& s) { int len = s.size(); for(int i = 0; i |








 如上图所示,数组的长度为 5,即红色部分;容量为 8,即红色 加 蓝色部分。
如上图所示,数组的长度为 5,即红色部分;容量为 8,即红色 加 蓝色部分。



 雪崩效应是为了让哈希值更加符合随机分布的原则,哈希表中的键分布的越随机,利用率越高,效率也越高。 常用的哈希函数有:直接定址法、除留余数法、数字分析法、平方取中法、折叠法、随机数法 等等。有关哈希函数的内容,下文会进行详细讲解。
雪崩效应是为了让哈希值更加符合随机分布的原则,哈希表中的键分布的越随机,利用率越高,效率也越高。 常用的哈希函数有:直接定址法、除留余数法、数字分析法、平方取中法、折叠法、随机数法 等等。有关哈希函数的内容,下文会进行详细讲解。













【本文地址】
今日新闻 |
推荐新闻 |