多目标遗传算法NSGA |
您所在的位置:网站首页 › 简述遗传算法的原理和应用 › 多目标遗传算法NSGA |
多目标遗传算法NSGA
|
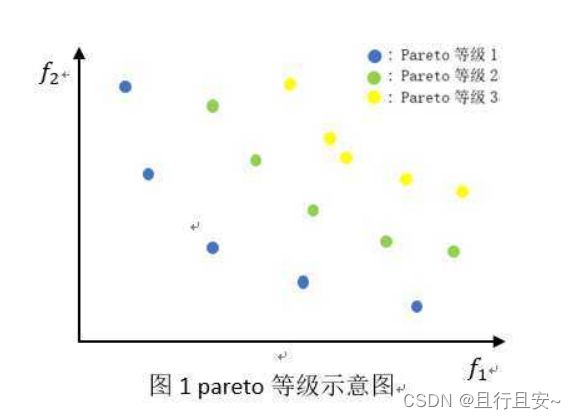
在接触学习多目标优化的问题上,经常会被提及到多目标遗传算法NSGA-II,网上也看到了很多人对该算法的总结,但真正讲解明白的以及配套用算法实现的文章很少,这里也对该算法进行一次详解与总结。会有侧重点的阐述,不会针对NSGA以及算法复杂度等等进行,有相关需求可自行学习了解。文末附有Python与Matlab两种的源代码案例。 目录 1、什么是非支配遗传算法 2、支配与非支配关系 2.1、种群分层 2.2、如何进行分支配排序 3、拥挤度(密度评估) 4、快速非支配性排序方法 5、偏序关系 6、 什么是精英策略 7、NSGA-II算法的基本思想 8、Matlab非支配代码实现 9、Python代码完整版实现 10、算法改进策略说明 文末有彩蛋 在串讲算法原理之前,先说明几个关键词。 1、什么是非支配遗传算法非支配排序遗传算法NSGA (Non-dominated Sorting Genetic Algorithms)是由Srinivas和Deb于1995年提出的。这是一种基于Pareto最优概念的遗传算法,它是众多的多目标优化遗传算法中体现Goldberg思想最直接的方法。该算法就是在基本遗传算法的基础上,对选择再生方法进行改进:将每个个体按照它们的支配与非支配关系进行分层,再做选择操作,从而使得该算法在多目标优化方面得到非常满意的结果。 2、支配与非支配关系 在最小化问题中, 当出现大量满足支配与非支配的个体时,会出现一种如下的分层现象。因为优化问题,通常存在一个解集,这些解之间就全体目标函数而言是无法比较优劣的,其特点是:无法在改进任何目标函数的同时不削弱至少一个其他目标函数。 这种解称作非支配解(nondominated solutions)或Pareto最优解(Pareto optimal solutions),形象展示如下:
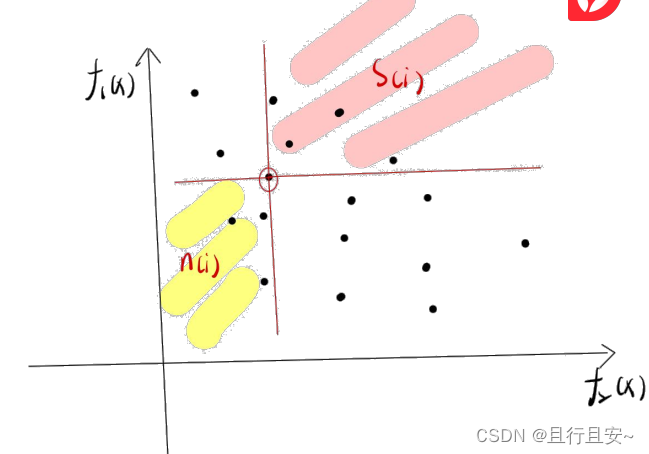
(1)设i=1; (2)所有的 (3)如果不存在任何一个个体 (4)令i=i+1,转到步骤(2),直到找到所有的非支配个体。 通过上述步骤得到的非支配个体集是种群的第一级非支配层,然后忽略这些已经标记的非支配个体(即这些个体不再进行下一轮比较),再遵循步骤(1)-(4),就会得到第二级非支配层。依此类推,直到整个种群被分层。 3、拥挤度(密度评估) 为了获得对种群中某一特定解附近的密度估计, 我们沿着对应目标计算这个解两侧的两点间的平均距离。 这个值
拥挤距离的计算需要根据每个目标函数值的大小对种群进行升序排序。此后,对于每个目标函数,边界解(对应函数最大最小值的解)被分配一个无穷距离值。所有中间的其他解被分配一个与两个相邻解的函数值的归一化差的绝对值相同的距离值。 对其他目标函数继续进行这种计算。总的拥挤距离值为对应于每个目标的各个距离之和。在计算拥挤距离之前, 归一化每个目标函数。 下面所示的算法概述了非支配性解集 中所有解的拥挤距离计算过程。对非支配性解集
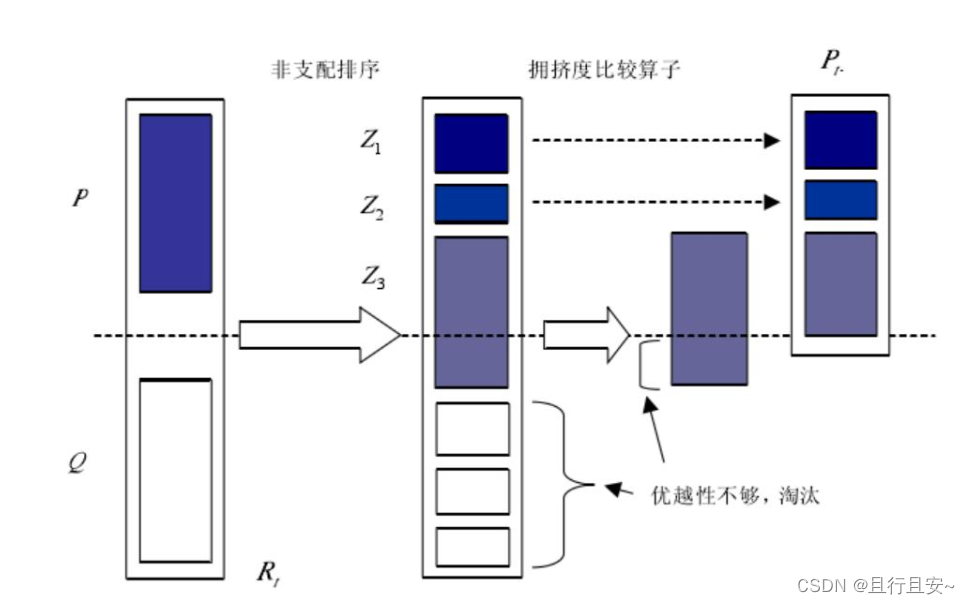
这里, 对于每个个体 1)找到种群中所有 n(i)=0 的个体, 将它们存入当前集合F(1); 2)对于当前集合 F(1) 中的每个个体 由于经过了排序和拥挤度的计算,群体中每个个体 NSGA-II 算法采用精英策略防止优秀个体的流失, 通过将父代和子代所有个体混合后进行 非支配排序的方法。 精英策略的执行步骤:
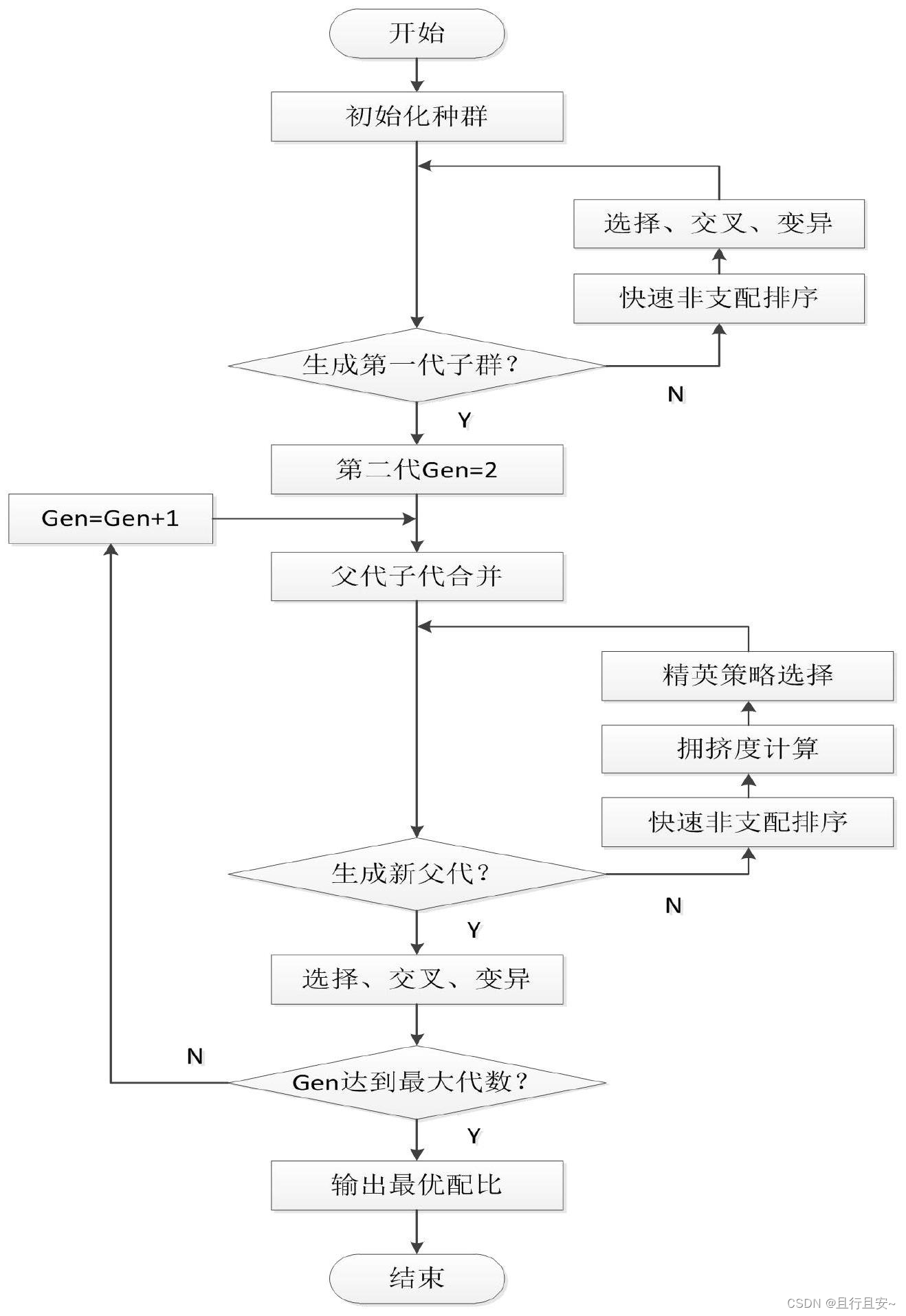
1) 随机产生规模为N的初始种群Pt,经过非支配排序、 选择、 交叉和变异, 产生子 代种群Qt, 并将两个种群联合在一起形成大小为2N的种群Rt,; 2)进行快速非支配排序, 同时对每个非支配层中的个体进行拥挤度计算, 根据非支 配关系以及个体的拥挤度选取合适的个体组成新的父代种群Pt+1﹔ 3) 通过遗传算法的基本操作产生新的子代种群Qt+1, 将Pt+1与Qt+1合并形成新的种 群Rt, 重复以上操作, 直到满足程序结束的条件 Matlab版本的数据案例(重点以拥挤度函数与非支配排序为主),网上案例很多都是使用matlab,请自行查阅学习。 function [FrontValue,MaxFront] = NonDominateSort(FunctionValue,Operation) % 进行非支配排序 % 输入: FunctionValue, 待排序的种群(目标空间),的目标函数 % Operation, 可指定仅排序第一个面,排序前一半个体,或是排序所有的个体, 默认为排序所有的个体 % 输出: FrontValue, 排序后的每个个体所在的前沿面编号, 未排序的个体前沿面编号为inf % MaxFront, 排序的最大前面编号 if Operation == 1 Kind = 2; else Kind = 1; %√ end [N,M] = size(FunctionValue); MaxFront = 0; cz = zeros(1,N); %%记录个体是否已被分配编号 FrontValue = zeros(1,N)+inf; %每个个体的前沿面编号 [FunctionValue,Rank] = sortrows(FunctionValue); %sortrows:由小到大以行的方式进行排序,返回排序结果和检索到的数据(按相关度排序)在原始数据中的索引 %开始迭代判断每个个体的前沿面,采用改进的deductive sort,Deb非支配排序算法 while (Kind==1 && sum(cz) |


【本文地址】
今日新闻 |
推荐新闻 |