快速理解哈夫曼编码和其中的贪心思想 |
您所在的位置:网站首页 › 简述绿色设计的基本思想 › 快速理解哈夫曼编码和其中的贪心思想 |
快速理解哈夫曼编码和其中的贪心思想
|
目录
1.哈夫曼编码原理2.哈夫曼树2.1构造规则2.2构造时要注意的内容
3编码3.1编码规则
4解码4.1解码规则4.2解码要注意的内容
5.实例代码6.贪心思想7.总结
1.哈夫曼编码原理
根据字符出现的概率大小进行编码,出现概率高的字符使用较短的编码,出现概率低的字符使用较长的编码,从而使平均码长尽可能短。是数据压缩技术的一种体现。 可以这么理解,出现概率高的字符则说明使用到这个字符的次数多,那么为了方便使用就要把这种常用的字符设置的简短方便一些,编码越短越好。例如A的编码有1和11111111两种选择,而且经常使用到A,那么肯定是选择编码为1更方便,每次只需要输入一个1就可以了,而不用输入那么长的一串。 2.哈夫曼树要实现哈夫曼编码,首先需要构造一棵哈夫曼树。 哈夫曼树是根据各个字符的概率大小(也可理解为重要程度,以下用重要程度来说能更好理解)来构造的,构造的顺序是从叶子结点开始往上新构造,直到构造出根结点为止。 2.1构造规则 从现有的所有结点中选择重要程度最小的两个组合构造出它们的父结点,父结点的重要程度为两个子结点的重要程度之和生成父结点后,已经用过的两个结点就不再之后的考虑范围内了,但要把新生成的父结点加入到现有的尚未使用过的结点集合中重复1、2步骤,直到所有的结点都使用过假设有一下字符: 字符概率(重要程度)A8B10C3D4E5
C、D已经使用过了,就不再考虑。将新生成的父结点加入到可用结点中,然后再从这些结点里选重要程度最低的两个结点,重复之前的操作。
编码的过程是通过从哈夫曼树的根结点开始,到对应的叶子结点的路径进行编码的。 3.1编码规则 往左子结点走记为 0往右子结点走记为 1编码顺序是从根结点到叶子节点把上面的例子按照这个编码规则处理后如下图 解码就是输入一串哈夫曼编码,然后将其翻译成字符的形式 4.1解码规则 从根结点开始,按照编码,若是0则看左子结点,若是1则看右子结点,直到走到叶子节点,叶子节点代表的字符是什么则解码的结果就是什么当解码出一个字符后便回到根结点,从下一个字符开始,继续重复上一点的方法,直到所有的编码都结束为止 4.2解码要注意的内容 每个编码都从哈夫曼树的根结点开始找任意的编码都不可能是其他编码的前缀或者后缀,所以只需要将所有的编码按顺序直接处理就可以了不用考虑出现歧义的情况。 5.实例代码 #include #include #define MAXBIT 100 #define MAXVALUE 10000 #define MAXLEAF 30 #define MAXNODE MAXLEAF*2 -1 typedef struct { //编码结构体 int bit[MAXBIT]; //码 int start; } HCodeType; typedef struct { //结点结构体 int weight; //权值 int parent; //父亲结点 int lchild; //左子结点 int rchild; //右子结点 char value; //结点的实际值 } HNodeType; void init (HNodeType HuffNode[MAXNODE], int n) { //初始化 for (int i=0; i |
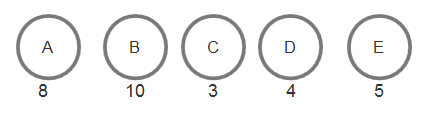 初始的结点就是这五个,在其中选出重要程度最小的两个,分别是C、D,然后用这两个结点构造一个父结点出来
初始的结点就是这五个,在其中选出重要程度最小的两个,分别是C、D,然后用这两个结点构造一个父结点出来 

 可以看到,每次重复这样的操作之后可用的结点是越来越少的,而且每生成一个新的父结点,可用的结点就会减一。
可以看到,每次重复这样的操作之后可用的结点是越来越少的,而且每生成一个新的父结点,可用的结点就会减一。  当可用结点没有了,也就是根结点构造出来的时候。此时哈夫曼树就构造好了
当可用结点没有了,也就是根结点构造出来的时候。此时哈夫曼树就构造好了 按照从根节点到叶子结点的顺序进行编码得到
按照从根节点到叶子结点的顺序进行编码得到【本文地址】
今日新闻 |
推荐新闻 |