【神经网络学习笔记】所有神经网络的关系和分类-附思维导图 |
您所在的位置:网站首页 › 神经网络模型分类 › 【神经网络学习笔记】所有神经网络的关系和分类-附思维导图 |
【神经网络学习笔记】所有神经网络的关系和分类-附思维导图
|
本人根据MATLAB神经网络的仿真和应用和自己查的文献总结了神经网络的分类,有什么不对的请指出。 目录 1 思维导图 2 引言 3 单层神经网络 4 前馈神经网络 4.1 单层前馈神经网 4.1.1 感知器 4.2 多层前馈神经网络 4.2.1 径向基神经网络 4.2.1.1 广义回归神经网络(General Regression Neural Network,GPNN) 4.2.1.2 概率神经网络(Probabilistic Neural Network,PNN) 4.2.2 BP神经网络(Back Propagation,BP) 4.2.3 全连接神经网络 4.2.4 卷积神经网络(Convolutional Neural Networks, CNN) 4.3 线性神经网络 4.3.1 Madaline 神经网络 5 反馈型神经神经网络 5.1 递归神经网络(Recurrent neural network,RNN) 5.1.1 Elman网络 5.2 Hopfield神经网络 5.2.1 离散Hopfield网络 5.2.2 连续Hopfield网络 5.3 盒中脑模型(BSB) 6 自组织神经网络 6.1 竞争神经网络 6.2 自适应谐振理论网络(Adaptive Resonance Theory,ART) 6.3 自组织映射神经网络(Self-Organizing Map,SOM) 7 结构自适应神经网络 7.1 级联相关 (Cascade-Correlation) 网络 8 对抗神经网络GAN 9 随机神经网络 9.1 玻尔兹曼机(Boltzmann) 10 神经网络创建函数总结 1 思维导图
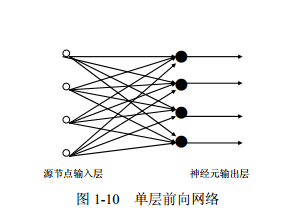
可以从不同的角度对人工神经网络进行分类 (1)从网络性能角度可分为连续型与离散型网络、确定性与随机性网络。 ( 2)从网络结构角度可为前向网络与反馈网络。 ( 3)从学习方式角度可分为有导师学习网络和无导师学习网络。 ( 4)按连续突触性质可分为一阶线性关联网络和高阶非线性关联网络。 以下内容主要从网络结构和算法结合的角度对人工神网络进行分类。 3 单层神经网络所谓单层前向网络是指拥有的计算节点(神经元)是“单层”的,如图 1-10 所示。这里表 示源节点个数的“输入层”被看做一层神经元,因为该“输入层”不具有执行计算的功能。 前馈神经网络(feedforward neural network,FNN)
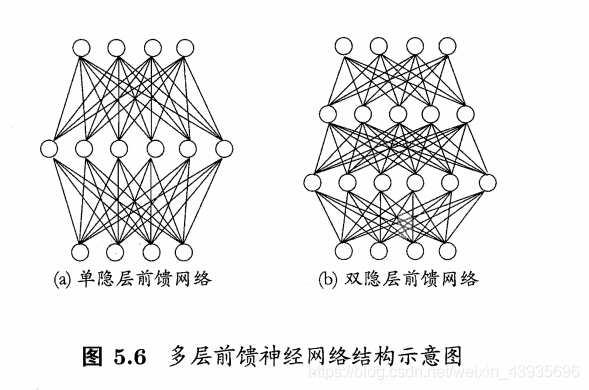
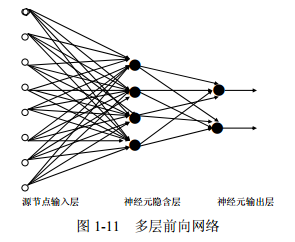
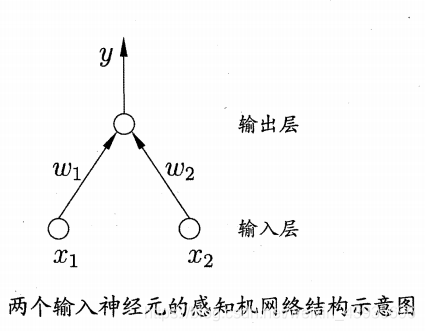
多层前向网络与单层前向网络的区别在于:多层前向网络含有一个或更多的隐含层,其中 计算节点被相应地称为隐含神经元或隐含单元,如图 1-11 所示 简介: 感知器(Perceptron)由两层神经元组成。如图所示,输入层接收外界输入信号后传递给输出层,输出层是M—P神经元,也称为“阈值逻辑单元”。
感知机只有输出层神经元需要激活函数激活,只有一层功能神经元,学习能力非常有限。感知机解决的都是线性可分的问题。要解决非线性可分问题,需要使用多层功能神经元。输出层和输入层之间的神经元成为隐层或者隐含层,隐含层层与输出层神经元都是有激活函数的功能神经元。至此引入多层前馈神经网络。 Matlab函数的使用 newp创建一个感知器 train训练感知器网络 sim对训练好的网络进行仿真 hardline/harddims感知器传输函数 init神经网络初始化函数 adapt神经网络的自适应 mae平均绝对误差性能函数 4.2 多层前馈神经网络 4.2.1 径向基神经网络简介: 径向基函数 RBF 神经网络((Radial Basis Function,RBF)是一个只有一个隐藏层的三层前馈神经网络结构,它与前向网络相比最大的不同在于,隐藏层得转换函数是局部响应的高斯函数,而以前的前向网络、转换函数都是全局响应的函数。由于这样的不同,如果要实现同一个功能,RBF 网络的神经元 个数 就可能要比前向 BP 网络的神经元个数要多。 但是,RBF 网络所需要的训练时间却比前向 BP 网络的要少。 使用径向基函数作为隐层神经元激活函数,而输出层则是对隐层神经元输出的线性组合。假定输入为d维向量x。输出为实值,则RBF网络可以表示为: 其中q为隐层神经元个数,ci和wi分别是第i个隐层神经元所对应的中心和权重, ρ \rho ρ(x,ci)设计径向基函数,这是某种沿径向对称的标量函数,通常定义为样本x到数据中心ci之间欧式距离的单调函数,常用的高斯径向基函数形如
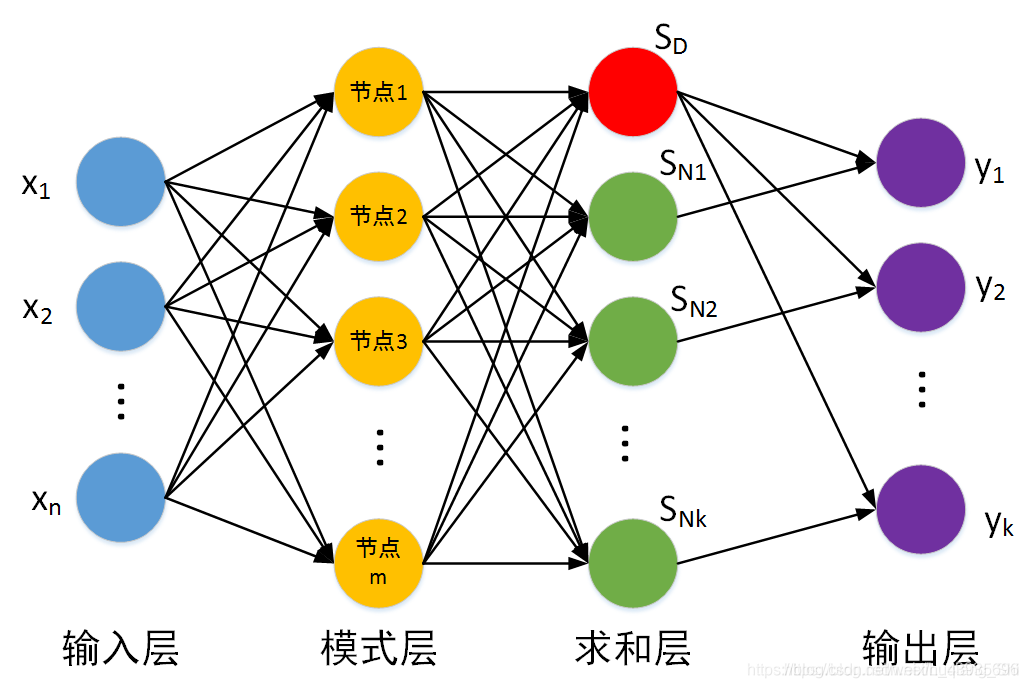
简介:径向基神经元和线性神经元可以建立广义回归神经网络,它是径RBF网络的一种变化形式,经常用于函数逼近。在某些方面比RBF网络更具优势。GRNN与PNN一样也是一个四层的网络结构:输入层、模式层、求和层、输出层。
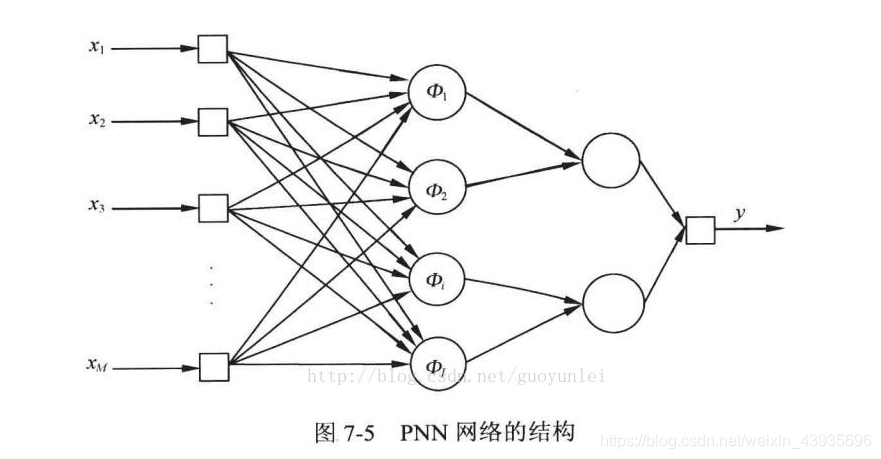
优点:GRNN具有很强的非线性映射能力和学习速度,比RBF具有更强的优势,网络最后普收敛于样本量集聚较多的优化回归,样本数据少时,预测效果很好, 网络还可以处理不稳定数据。广义回归神经网络对x的回归定义不同于径向基函数的对高斯权值的最小二乘法叠加,他是利用密度函数来预测输出。 与PNN的区别:GRNN用于求解回归问题,而PNN用于求解分类问题。 4.2.1.2 概率神经网络(Probabilistic Neural Network,PNN)简介:径向基神经元和竞争神经元还可以组成概率神经网络。PNN也是RBF的一种变化形式,结构简单训练快捷,特别适合于模式分类问题的解决。理论基础是贝叶斯最小风险准则,即是贝叶斯决策理论。 结构:由输入层、隐含层、求和层、输出层组成。也把隐含层称为模式层,把求和层叫做竞争层
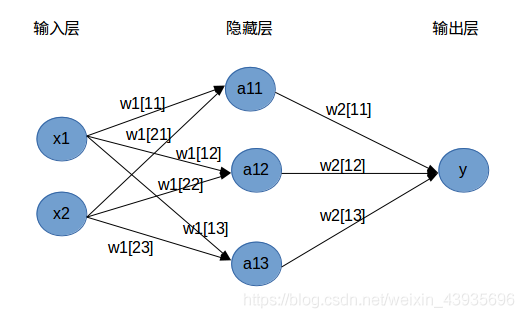
第一层为输入层,用于接收来自训练样本的值,将数据传递给隐含层,神经元个数与输入向量长度相等。 第二层隐含层是径向基层,每一个隐含层的神经元节点拥有一个中心,该层接收输入层的样本输入,计算输入向量与中心的距离,最后返回一个标量值,神经元个数与输入训练样本个数相同。 优点: 训练容易,收敛速度快,从而非常适用于实时处理。在基于密度函数核估计的PNN网络中,每一个训练样本确定一个隐含层神经元,神经元的权值直接取自输入样本值。口可以实现任意的非线性逼近,用PNN网络所形成的判决曲面与贝叶斯最优准则下的曲面非常接近。 隐含层采用径向基的非线性映射函数,考虑了不同类别模式样本的交错影响,具有很强的容错性。只要有充足的样本数据,概率神经网络都能收敛到贝叶斯分类器,没有BP网络的局部极小值问题。 隐含层的传输函数可以选用各种用来估计概率密度的基函数,且分类结果对基函数的形式不敏感。 扩充性能好。网络的学习过程简单,增加或减少类别模式时不需要重新进行长时间的训练学习。 各层神经元的数目比较固定,因而易于硬件实现。 4.2.2 BP神经网络(Back Propagation,BP)强化多层神经网络的训练,必须引入算法,其中最成功的是误差逆传播算法(Back Propagation,简称BP算法)。BP算法不仅用于多层前馈神经网络,还可以用于训练递归神经网络。解决了多层神经网络隐含层连接权学习问题,并在数学上给出了完整推导。人们把采用这种算法进行误差校正的多层前馈网络称为BP神经网络 BP神经网络网络主要四个方面的应用: 1)函数逼近:用输入向量和相应的输出向量训练一个网络逼近一个函数。 2)模式识别:用一个待定的输出向量将它与输入向量联系起来。 3)分类:把输入向量所定义的合适方式进行分类。 4)数据压缩:减少输出向量维数以便于传输或存储。 4.2.3 全连接神经网络全连接神经网络(fully connected neural network),顾名思义,就是相邻两层之间任意两个节点之间都有连接。全连接神经网络是最为普通的一种模型(比如和CNN相比),由于是全连接,所以会有更多的权重值和连接,因此也意味着占用更多的内存和计算。 如图定义了一个两层的全连接神经网络。
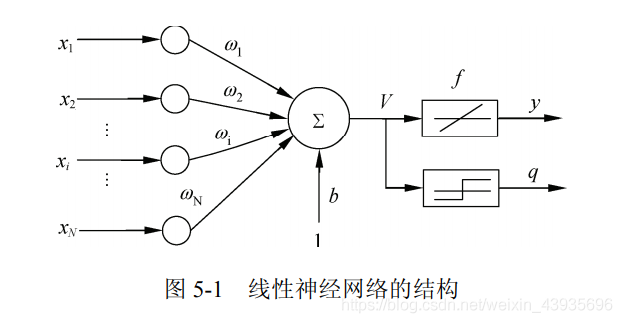
参考本人的另一篇博客 卷积神经网络CNN(Convolutional Neural Networks, CNN) 综述 4.3 线性神经网络线性神经网络详细原理及MATLAB实现pdf 简介: 线性神经网络最典型的例子是自适应线性元件(Adaptive Linear Element,Adaline)。自适应线性元件 20 世纪 50 年代末由 Widrow 和 Hoff 提出,主要用途是通过线性逼近一个函数式而进行模式联想以及信号滤波、预测、模型识别和控制等。 线性神经网络与感知器的主要区别: 感知器的传输函数只能输出两种可能的值,而线性神经网络的输出可以取任意值,其传输函数是线性函数。线性神经网络采用 Widrow-Hoff 学习规则,即 LMS(Least Mean Square)算法来调整网络的权值和偏置。线性神经网络在收敛的精度和速度上较感知器都有了较大提高,但其线性运算规则决定了它只能解决线性可分的问题。 线性神经网络在结构上与感知器网络非常相似,只是神经元传输函数不同。
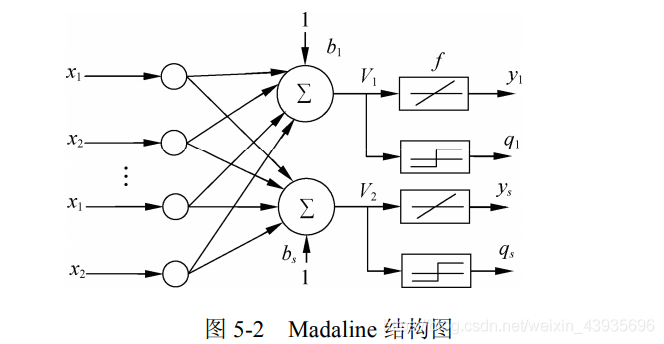
若网络中包含多个神经元节点,就能形成多个输出,这种线性神经网络叫Madaline神经网络。
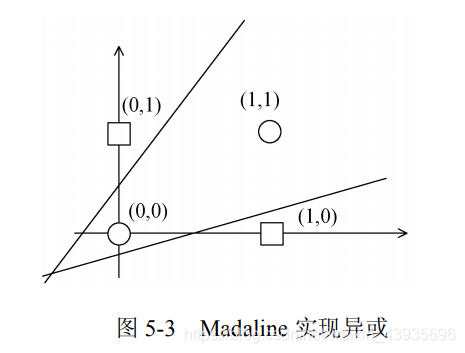
Madaline 可以用一种间接的方式解决线性不可分的问题,方法是用多个线性函数对区域进行划分,然后对各个神经元的输出做逻辑运算。如图所示,Madaline 用两条直线实现了异或逻辑。
所谓反馈网络是指在网络中至少含有一个反馈回路的神经网络。反馈网络可以包含一个单层神经元,其中每个神经元将自身的输出信号反馈给其他所有神经元的输入 反馈神经网络中神经元不但可以接收其他神经元的信号,而且可以接收自己的反馈信号。和前馈神经网络相比,反馈神经网络中的神经元具有记忆功能,在不同时刻具有不同的状态。反馈神经网络中的信息传播可以是单向也可以是双向传播,因此可以用一个有向循环图或者无向图来表示。 5.1 递归神经网络(Recurrent neural network,RNN)与前馈神经网络不同"递归神经网络" (recurrent neural networks)允许网络中出现环形结构,从而可让一些神经元的输出反馈回来作为输入信号.这样的结构与信息反馈过程,使得网络在 t 时刻的输出状态不仅与 t 时刻的输入有关,还与 t - 1 时刻的网络状态有关,从而能处理与时间有关的动态变化。 5.1.1 Elman网络
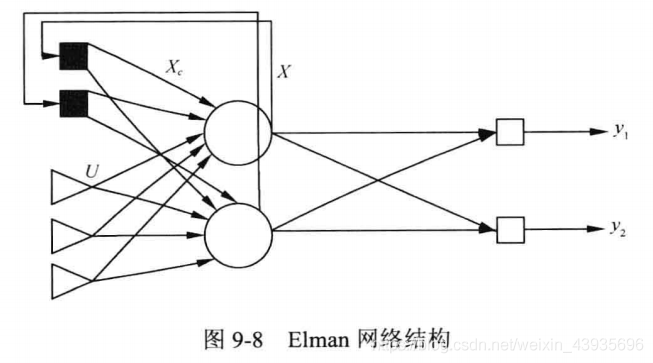
(1)简介 基本的Elman伸进网络由输入层、隐含层、连接层、输出层组成。与BP网络相比,在结构上了多了一个连接层,用于构成局部反馈。 (2)特点 连接层的传输函数为线性函数,但是多了一个延迟单元,因此连接层可以记忆过去的状态,并在下一时刻与网络的输入一起作为隐含层的输入,使网络具有动态记忆功能,非常适合时间序列预测问题。 输出层和连接层的的传递函数为线性函数,隐含层的传递函数则为某种非线性函数,如Sigmoid函数。由于隐含层不但接收来自输入层的数据,还要接收连接层中存储的数据,因此对于相同的输入数据,不同时刻产生的输出也可能不同。输入层数据反映了信号的空域信息,而连接层延迟则反映了信号的时域信息,这是Elman网络可以用于时域和空域模式识别的原因。 5.2 Hopfield神经网络
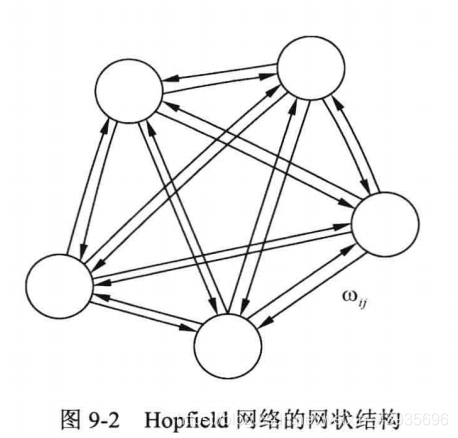
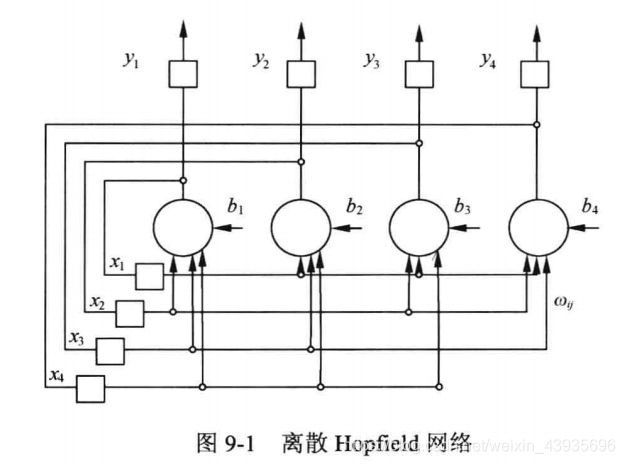
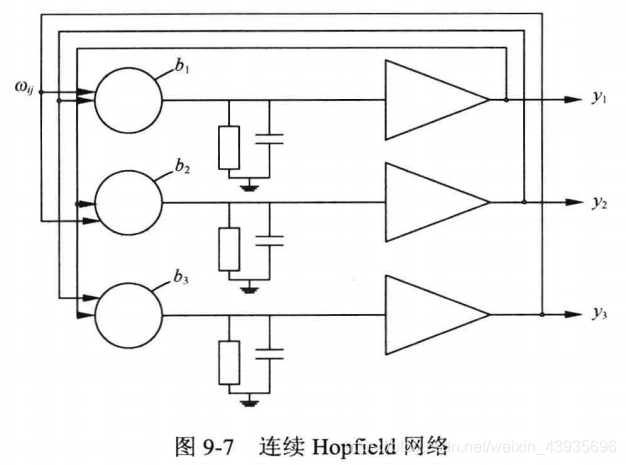
(1)简介 一种基于能量的模型(Energy Based Model,EBM)——可用作联想存储的互连网络,称该模型为 Hopfield 网络。根据其激活函数的不同,Hopfield 神经网络有两种:离散Hopfield 网络(Discrete Hopfield Neural Network,DHNN)和连续Hopfield 网络(Continues Hopfield Neural Network,CHNN)。 从上图中可以看出每个神经元的输出都成为其他神经元的输入,每个神经元的输入又都来自其他神经元。神经元输出的数据经过其他神经元之后最终又反馈给自己。具体讲解参考博客: Hopfield 网络详细讲解 5.2.1 离散Hopfield网络
(1)简介 输出值只能取0或1,分别表示神经元的抑制和兴奋状态。如上图所示输出神经元的取值为0/1或-1/1。对于中间层,任意两个神经元间的连接权值为wij = wji ,神经元的连接是对称的。如果wij等于0,即神经元自身无连接,则成为无自反馈的Hopfield网络,如果wij != 0,则成为有自反馈的Hopfield网络。但是出于稳定性考虑,一般避免使用有自反馈的网络。 5.2.2 连续Hopfield网络
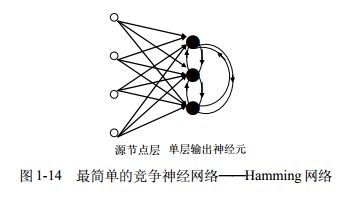
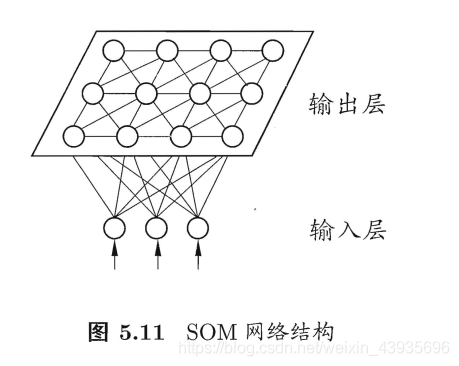
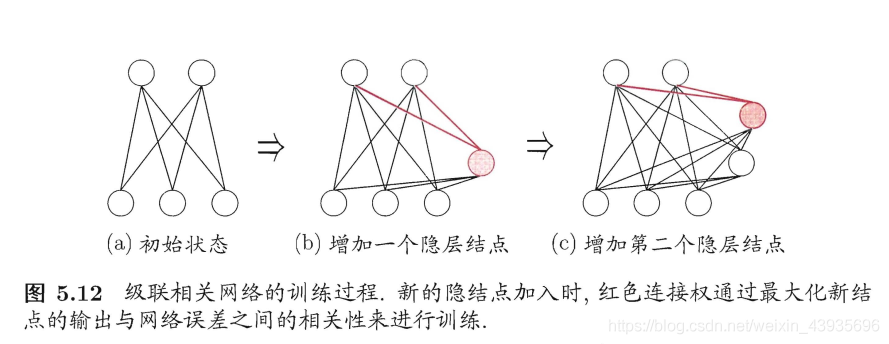
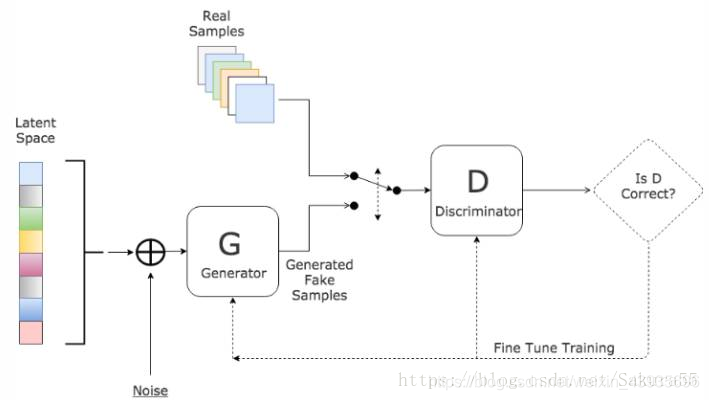
(1)特点 连续的Hopfield网络结构和离散的Hopfield网络的结构相同,不同之处在于传输函数不是阶跃函数或符号函数,而是S型的连续函数,如sigmoid函数。每个神经元由一个运算放大器和相关的元件组成,其输入一方面由输出的反馈形成,另一方面也有以电流形式从外界连接过来的输入。 5.3 盒中脑模型(BSB)(1)简介 盒中脑(Brain-State-in-a-Box,BSB)模型是一种节点之间存在横向连接和节点自反馈的单层网络,可以用作自联想最邻近分类器,并可存储任何模拟向量模式。该模型是一种神经动力学模型,可以看作是一个有幅度限制的正反馈系统。 (2)特点 BSB模型实际上是一种梯度下降法,在迭代的过程中,使得能量函数达到最小。 6 自组织神经网络 6.1 竞争神经网络(1)简介 竞争型学习(compaetitive learning)是神经网络的中一种常用的无监督学习策略,在使用该策略时,网络的输出神经元相互竞争,每一时刻仅有一个获胜的神经元被激活,其他神经元的状态被抑制,中级机制也别称为"胜者通吃"原则。 (2)特点 竞争神经网络的显著特点是它的输出神经元相互竞争以确定胜者,胜者指出哪一种原形模式最能代表输入模式。Hamming 网络是一个最简单的竞争神经网络,如图 1-14 所示。神经网络有一个单层的输出神经元,每个输出神经元都与输入节点全相连,输出神经元之间全互连。从源节点到神经元之间是兴奋性连接,输出神经元之间横向侧抑制。 简介:是一种竞争学习型神经网络。该网络由比较层、识别层、识别阈和重要模块构成。其中,比较层负责接受输入样本,并将其传递给识别层神经元。识别曾每个神经元对应一个模式类,神经元数目可在训练过程中动态增长以增加新的模式类。 优点:课进行增量学习(incremental Learning)或者在线学习(online learning) 6.3 自组织映射神经网络(Self-Organizing Map,SOM)(1)简介 SOM(Self-Organizing Map,自组织映射)网络,是一种竞争学习型的无监督神经网络,它能将高维输入数据映射到低维空间(通常是二维),同时保持输入数据在高维空间的拓扑结构,即将高维空间中想死的样本点映射到网络输出层中的邻近神经元。 如图所示, SOM 网络中的输出层神经元以矩阵方式排列在二维空间中,每个神经元都拥有一个权向量,网络在接收输入向量后,将会确定输出层获胜神经元,它决定了该输入向量在低维空间中的位置. (2)SOM的训练目标 每个输出层神经元找到合适的权向量,以达到保持拓扑结构的目的 (3)SOM训练过程 在接收到一个训练样本后.每个输出层神经局会计算该样本与自身携带的权向量之间的距离,距离最近的神经兀成为竞争获胜者,称为最佳匹配单元 (best matching unit). 然后,最佳匹配单元及其邻近神经 元的权向量将被调整,以使得这些权向量与当前输入样本的距离缩小.这个过程不断迭代,直至收敛. (4)与竞争神经网络的区别和联系 联系 • 非常类似,神经元都具有竞争性,都采用无监督的学习方式。 • 同样包含输入层、输出层两层网络 区别 • 自组织映射网络除了能学习输入样本的分布外,还能够识别输入向量的拓扑结构。 • 自组织网络中,单个神经元对模式分类不起决定性的作用,需要靠多个神经元协同作用完成。 • 自组织神经网络输出层引入网络的拓扑结构,以更好的模拟生物学中的侧抑制现象。 • 主要区别是竞争神经网络不存在核心层之前的相互连接,在更新权值时采用了胜者全得的方式,每次只更新获胜神经元对应的连接权值;而自组织神经网络中,每个神经元附近一定领域内的神经元也会得到更新,较远的神经元则不更新,从而使得几何上相近的神经元变得更相似。 7 结构自适应神经网络一般的神经网络模型通常假定 网络结构是事先固定的,训练的目的是利用训练样本来确定合适的连接权、 阙值等参数.与此不同, 结构自适应网络则将网络结构也当作学习的目标之 一,并希望能在训练过程中找到最利合数据特点的网络结构 7.1 级联相关 (Cascade-Correlation) 网络简介:,是结构自适应网络的重要代表。级联相关网络有两个主要成分"级联"和"相关" 级联是指建立层次连接的层级结构.在开始训练时,网络只有输入层和输出层,处于最小拓扑结 构;随着训练的进行,如图所示,新的隐层神经元逐渐加入,从而创建起层级结构. 当新的隐层神经元加入时,其输入端连接权值是冻结固 定的相关是指通过最大化新神经元的输出与网络误差之间的相关性(correlation)来训练相关的参数. 优缺点:与一般的前馈神经网络相比,级联相关网络无需设置网络层数、隐层神经元数目,且训练速度较快,但其在数据较小时易 陷入过拟合 8 对抗神经网络GAN简介: 对抗神经网络其实是两个网络的组合,可以理解为一个网络生成模拟数据,另一个网络判断生成的数据是真实的还是模拟的。生成模拟数据的网络要不断优化自己让判别的网络判断不出来,判别的网络也要不断优化自己让判断的更加精确。两者的关系形成对抗,因此叫对抗神经网络。 结构:GAN由generator(生成模型)和discriminator(判别式模型)两部分构成。 二者结合之后,经过大量次数的迭代训练会使generator尽可能模拟出以假乱真的样本,而discrimator会有更精确的鉴别真伪数据的能力,最终整个GAN会达到所谓的纳什均衡,即discriminator对于generator的数据鉴别结果为正确率和错误率各占50%。
举例:如果用到图片生成上,则训练完成后,G可以从一段随机数中生成逼真的图像。G, D的主要功能是: G是一个生成式的网络,它接收一个随机的噪声z(随机数),通过这个噪声生成图像 D是一个判别网络,判别一张图片是不是“真实的”。它的输入参数是x,x代表一张图片,输出D(x)代表x为真实图片的概率,如果为1,就代表100%是真实的图片,而输出为0,就代表不可能是真实的图片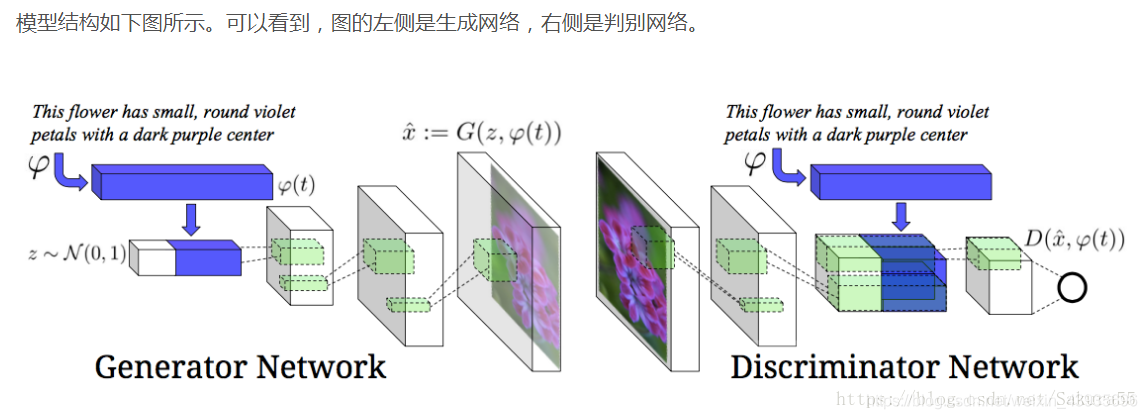 9 随机神经网络
9 随机神经网络
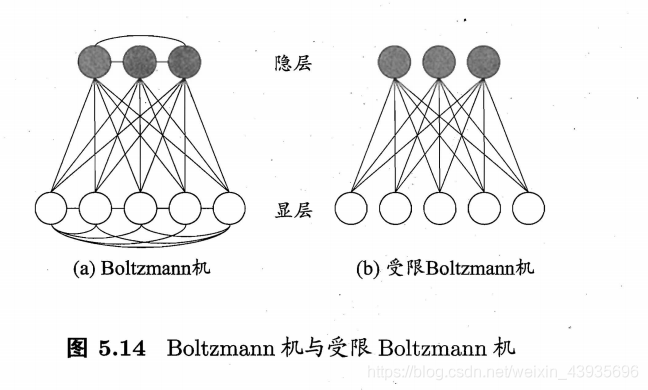
随机神经网络是对神经网络引入随机机制,认为神经元是按照概率的原理进行工作的,这就是说,每个神经元的兴奋或抑制具有随机性,其概率取决于神经元的输入。 9.1 玻尔兹曼机(Boltzmann)(1)简介 在Hopfield网络中引入随机机制,提出了Boltzmann机,这是第一个由统计力学导出的多层学习机,可以对给定数据集的固有概率分布进行建模,可以用于模式识别等领域。得此名的原因是,它将模拟退火算法反复更新网络状态,网络状态出现的概率服从Boltzmann分布,即最下能量状态的概率最高,能量越大,出现的概率越低。 由随机神经元组成,神经元分为可见神经元和隐藏神经元,与输入/输出有关的神经元为可见神经元,隐藏神经元需要通过可见神经元才能与外界交换信息。 (2)特点 Boltzmann机学习的主要目的在于产生一个神经网络,根据Bolazmann分布对输入模型进行正确建模,训练挽留过的权值,当其导出的可见神经元状态的概率分布和被约束时完全相同时,训练就完成了。 (3)训练过程 Boltzmann 机的训练过程:将每个训练样本视为一个状态向量,使其出现的概率尽可能大.标准的 Boltzmann 机是一个全连接图,训练网络的复杂度很高,这使其难以用于解决现实任务. 现实中 常采用受限Boltzmann机(Restricted Boltzmann Machine,简称 RBM) . 如下图所示,受限 Boltzmann 机仅保留显层与隐层之间的连接 从而将 Boltzmann 机结构由完全图简化为二部图。
|
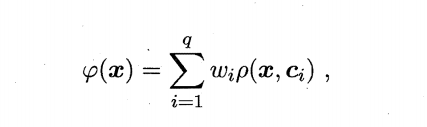
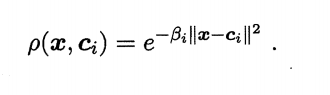
【本文地址】
今日新闻 |
推荐新闻 |