matplotlib绘制偏差图 |
您所在的位置:网站首页 › 相对平均值偏差公式推导过程图 › matplotlib绘制偏差图 |
matplotlib绘制偏差图
|
2、偏差图
偏差图是单个特征中所有值与特定值之间的关系图,它反映的是所有值偏离特定值的距离。典型的偏差图有:发散型条形图,面积图,… 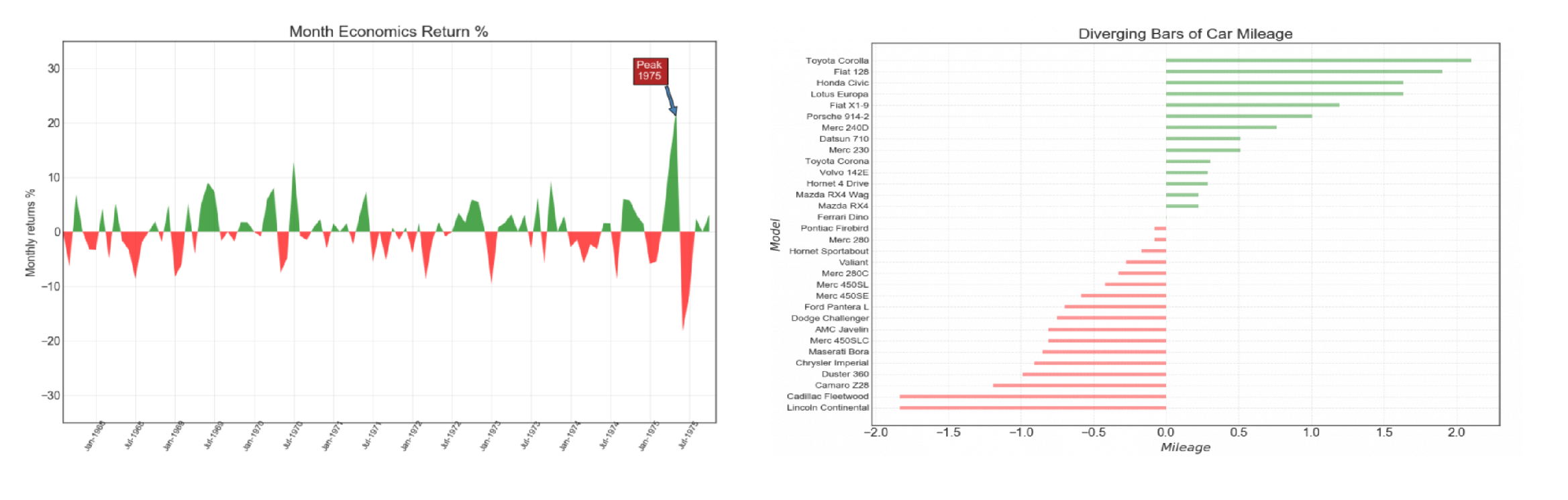
我们什么时候需要偏差图呢? 1.数据探索&数据解读 探索某一特征的分布,探索该特征偏离某个特定值(均值,方差等)的程度。 2.结果展示&报告呈现: 直观地展示某个特征的分布特征,快速得出结论。 2.1 发散条形图(Diverging Bars)如果你想根据单个指标查看项目的变化情况,并可视化此差异的顺序和数量,那么发散条形图是一个很好的工具。它有助于快速区分数据中的组的性能,并且非常直观,可以立即传达这一点。 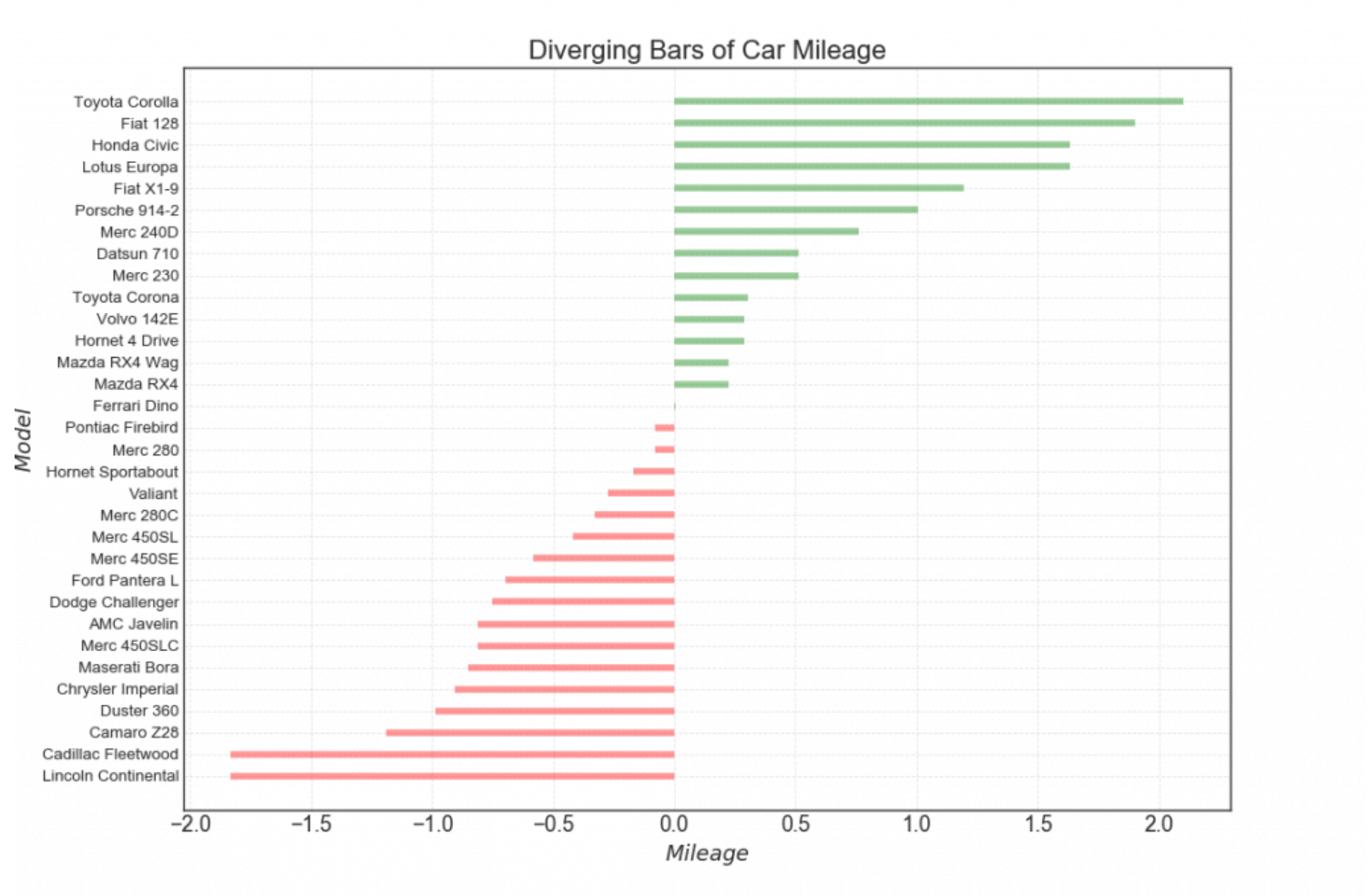 横坐标:里程纵坐标:各品牌汽车颜色:0显示绿色
横坐标:里程纵坐标:各品牌汽车颜色:0显示绿色
我们的目标就是绘制出这张图,并且利用现有数据解读图内信息。 1、导入需要的绘图库 import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns %matplotlib inline #如果用jupyter notebook则需要这行代码让你的图像显示,如果是jupyterlab则不需要2、先来认识一下绘制发散性条形图的函数 plt.hlines() plt.hlines()表示水平的条形图,类似的还有垂直的条形图plt.vlines() 参数说明: y:y轴索引 xmin:每行的开头 xmax:每行的结尾 colors:颜色,默认为“k”(黑色) linestyles:线的类型,可选择{‘solid’,‘dashed’,‘dashot’,‘dotted’} label:标签,默认为空 *linewidth:线的宽度 *alpha:色彩饱和度 绘制一个超级简单的条形图 #定义一个简单的数据 x = np.random.rand(10) #随机生成10个[0,1)的数字 x #绘图 plt.hlines(y=range(10),xmin=0,xmax=x);
与我们的目标图像相比,有什么区别吗? 目标图像时从大到小顺序排序的目标图像的线比较宽目标图像是基于某个特定值将数据分成两部分,并用不同的颜色表示(1)让图像顺序排列 使用sorted()函数,或者使用.sort()方法 a = sorted(x,reverse=True) #默认从小到大排列,reverse=True可以实现从大到小的排列,不会改变原数据的顺序 x.sort() #从小到大排列,并且会直接改变原数据(2)设置plt.hlines(linewidth=5)用于将图像的线变宽点。 (3)让图像基于均值分成两部分 方法:使用 x = x-x.mean()即可让图像的均值变为0 (4)让两部分显示不同的颜色 直接使用color=[‘green’,'red]可以吗?答案是不可以。 我们需要根据数据建立与数据长度相同的颜色列表(使用for循环/列表推导式) #创建颜色列表 #方法1.使用for循环 colors = [] for i in x: if i>> array([0, 0, 0, 0, 1, 1, 1, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 1, # 1, 1, 1, 0, 0, 0, 1, 1, 1, 0]) #新建一列标签列,将聚类的结果作为标签 df1["label"]=cluster.labels_ df1["label"].shape #由于我们前面的发散型条形图对数据进行了排序与z-score操作,所以在这里对df1数据集进行相同的操作 df1.sort_values('mpg',inplace=True) #重置索引 df1.reset_index(inplace=True) #现在判断KMeans的标签结果与经过条形图后的标签结果 相同的个数有几个 sum(df1["label"]==df["label"]) #>>> 31 #准确率 score = sum(df1["label"]==df["label"])/df1["label"].shape[0] score #>>> 0.96875 #查看唯一聚类错的数据 df[df["label"]!=df1["label"]] #这是中间的那个数,确实比较容易分类错 2.2 发散型文本(Diverging Texts)分散的文本类似于发散型条形图,如果你想以一种漂亮和可呈现的方式来希纳是图表中每个项目的价值,那么它是一个比较合适的方式。 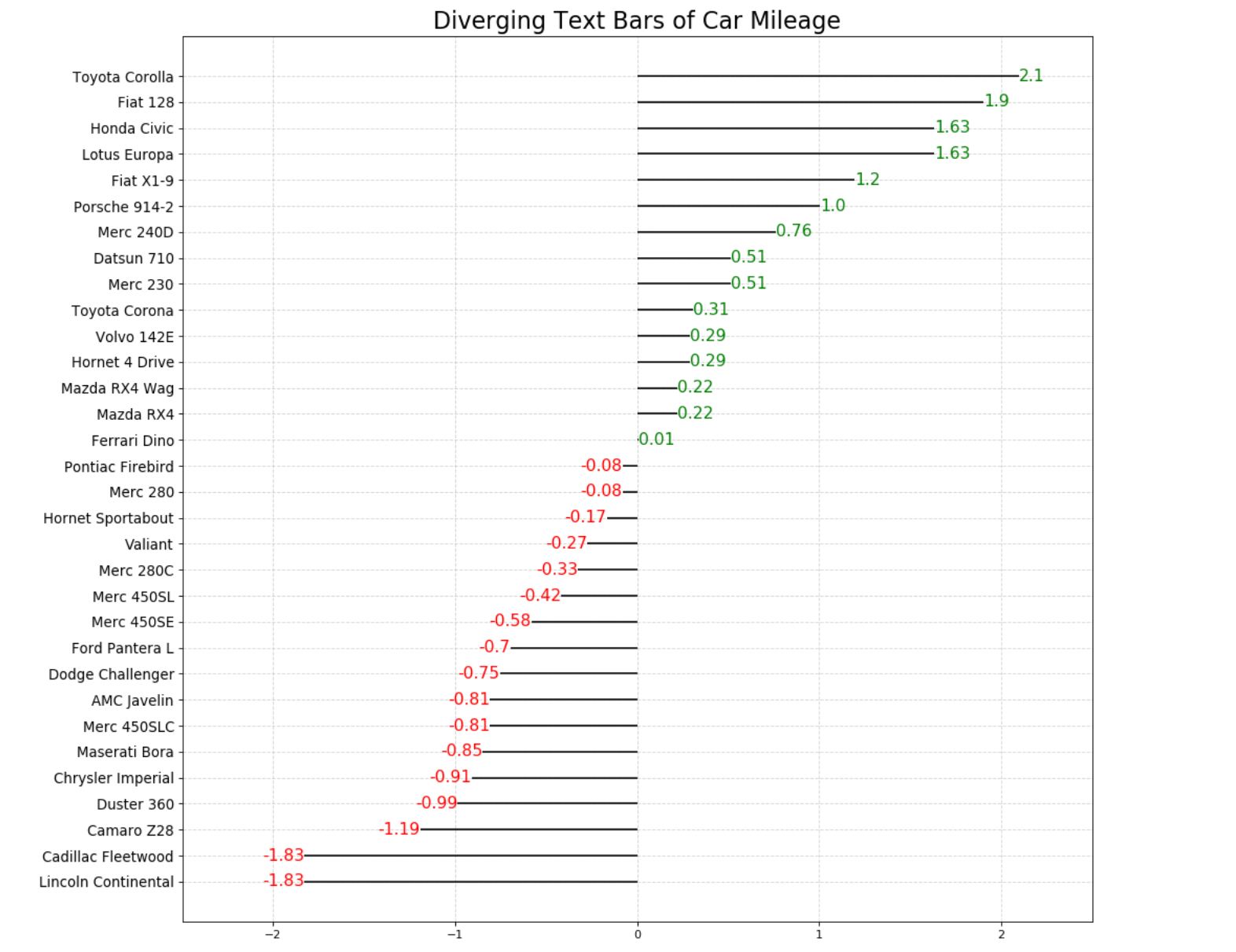
这和我们上面讲到的发散型条形图很相似,唯一不同的地方就是每个条形图上多了带颜色的文字 1、导入需要的库 import pandas as pd import numpy as np import matplotlib.pyplot as plt %matplotlib inline #如果用jupyter notebook则需要这行代码让你的图像显示,如果是jupyterlab则不需要2、来认识一下绘制文本的函数 plt.text() 参数说明: x,y:放置文本的位置。默认情况下,就是数据坐标s:要显示的文本内容fontdict:用于覆盖默认文本属性的字典。fontdict的默认值是None,默认值由rc参数决定 #定义数据 x = np.random.rand(1) y = np.random.rand(1) #创建画布 plt.figure(figsize=(8,4)) #绘制图形 plt.text(x=x,y=y,s="text" ,fontdict={'size':20,"color":"b"}); #plt.text()函数一次只能标准一个位置,如果想一次添加多个文本,-->写循环 plt.figure(figsize=(8,4)) #绘制图形 for i in range(10): x = np.random.rand(1) y = np.random.rand(1) plt.text(x,y,"text",fontdict={'size':16,"color":"b"});
绘制目标图像 #绘制目标图像 # 准备数据 df = pd.read_csv("https://github.com/selva86/datasets/raw/master/mtcars.csv") #导入数据集 x = df.loc[:, ['mpg']] #提取目标数据 df['mpg_z'] = (x - x.mean())/x.std() #对目标数据进行z-score标准化处理 df['colors'] = ['red' if x |



【本文地址】
今日新闻 |
推荐新闻 |