python3调用百度人脸识别api检测颜值demo |
您所在的位置:网站首页 › 百度的人脸识别颜值会改变吗 › python3调用百度人脸识别api检测颜值demo |
python3调用百度人脸识别api检测颜值demo
|
https://ai.baidu.com/docs#/Face-Detect/top 这个是百度人脸识别api 调用主要有三步: 获取access_token将图片处理成base64编码格式post请求访问接口得到结果 1.获取access_token
官方给的python示例代码,不过这个是python2的代码,python3里已经没有了urllib2,而且很繁琐 给出博主自己编写的py3利用requests的demo: # -*- coding: utf-8 -*- __author__ = 'fff_zrx' import requests #获取access_token #client_id 为官网获取的AK, client_secret 为官网获取的SK host = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=your ak&client_secret=your sk' header={'Content-Type': 'application/json; charset=UTF-8'} response1=requests.post(url=host,headers=header)# json1 = response1.json()# access_token=json1['access_token'] 2.将图片处理成base64编码格式流程大致是将图片读取为二进制格式,再利用二进制到base64格式的函数转换 参考博客
图片来自here 转换代码: import base64 filepath='zrx.jpg' f = open(r'%s' % filepath, 'rb') pic = base64.b64encode(f.read()) f.close() base64=str(pic,'utf-8') print(base64) 3.post请求访问接口得到结果 request_url = "https://aip.baidubce.com/rest/2.0/face/v3/detect" params = {"image":base64,"image_type":"BASE64","face_field":"faceshape,facetype,beauty,"} header={'Content-Type': 'application/json'} request_url = request_url + "?access_token=" + access_token response1=requests.post(url=request_url,data=params,headers=header)# json1 = response1.json()# print(json1) print("颜值评分为") print (json1["result"]["face_list"][0]['beauty'],'分/100分')完整代码: # -*- coding: utf-8 -*- __author__ = 'fff_zrx' import requests import base64 #获取access_token #client_id 为官网获取的AK, client_secret 为官网获取的SK host = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=your ak&client_secret=your sk' header={'Content-Type': 'application/json; charset=UTF-8'} response1=requests.post(url=host,headers=header)# json1 = response1.json()# access_token=json1['access_token'] #转换图片格式 filepath='zrx.jpg' f = open(r'%s' % filepath, 'rb') pic = base64.b64encode(f.read()) f.close() base64=str(pic,'utf-8') print(base64) #访问人脸检测api request_url = "https://aip.baidubce.com/rest/2.0/face/v3/detect" params = {"image":base64,"image_type":"BASE64","face_field":"faceshape,facetype,beauty,"} header={'Content-Type': 'application/json'} request_url = request_url + "?access_token=" + access_token response1=requests.post(url=request_url,data=params,headers=header)# json1 = response1.json()# print(json1) print("颜值评分为") print (json1["result"]["face_list"][0]['beauty'],'分/100分')
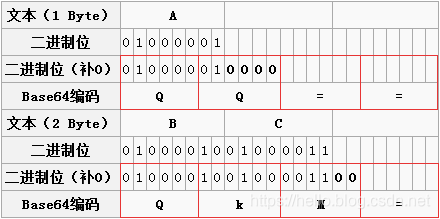
此部分转载于:一篇文章彻底弄懂Base64编码原理 电子邮件刚问世的时候,只能传输英文,但后来随着用户的增加,中文、日文等文字的用户也有需求,但这些字符并不能被服务器或网关有效处理,因此Base64就登场了 大多数编码都是由字符串转化成二进制的过程,而Base64的编码则是从二进制转换为字符串 1.具体转换步骤: 第一步,将待转换的字符串每三个字节分为一组,每个字节占8bit,那么共有24个二进制位。 第二步,将上面的24个二进制位每6个一组,共分为4组。 第三步,在每组前面添加两个0,每组由6个变为8个二进制位,总共32个二进制位,即四个字节。 第四步,根据Base64编码对照表(见下图)获得对应的值。 0 A 17 R 34 i 51 z 1 B 18 S 35 j 52 0 2 C 19 T 36 k 53 1 3 D 20 U 37 l 54 2 4 E 21 V 38 m 55 3 5 F 22 W 39 n 56 4 6 G 23 X 40 o 57 5 7 H 24 Y 41 p 58 6 8 I 25 Z 42 q 59 7 9 J 26 a 43 r 60 8 10 K 27 b 44 s 61 9 11 L 28 c 45 t 62 + 12 M 29 d 46 u 63 / 13 N 30 e 47 v 14 O 31 f 48 w 15 P 32 g 49 x 16 Q 33 h 50 y 2.示例说明: 以下图的表格为示例,我们具体分析一下整个过程。
第一步:“M”、“a”、"n"对应的ASCII码值分别为77,97,110,对应的二进制值是01001101、01100001、01101110。如图第二三行所示,由此组成一个24位的二进制字符串。 第二步:如图红色框,将24位每6位二进制位一组分成四组。 第三步:在上面每一组前面补两个0,扩展成32个二进制位,此时变为四个字节:00010011、00010110、00000101、00101110。分别对应的值(Base64编码索引)为:19、22、5、46。 第四步:用上面的值在Base64编码表中进行查找,分别对应:T、W、F、u。因此“Man”Base64编码之后就变为:TWFu。3.位数不足情况: 上面是按照三个字节来举例说明的,如果字节数不足三个,那么该如何处理?
上面我们已经看到了Base64就是用6位(2的6次幂就是64)表示字符,因此成为Base64。同理,Base32就是用5位,Base16就是用4位。 |




【本文地址】
今日新闻 |
推荐新闻 |