Java物流项目第六天 车辆轨迹服务开发(pd |
您所在的位置:网站首页 › 百度地图如何记录行驶路线轨迹 › Java物流项目第六天 车辆轨迹服务开发(pd |
Java物流项目第六天 车辆轨迹服务开发(pd
|
品达物流TMS项目
第7章 车辆轨迹服务开发(pd-netty、pd-druid)
1. apache druid概述
1.1 druid介绍
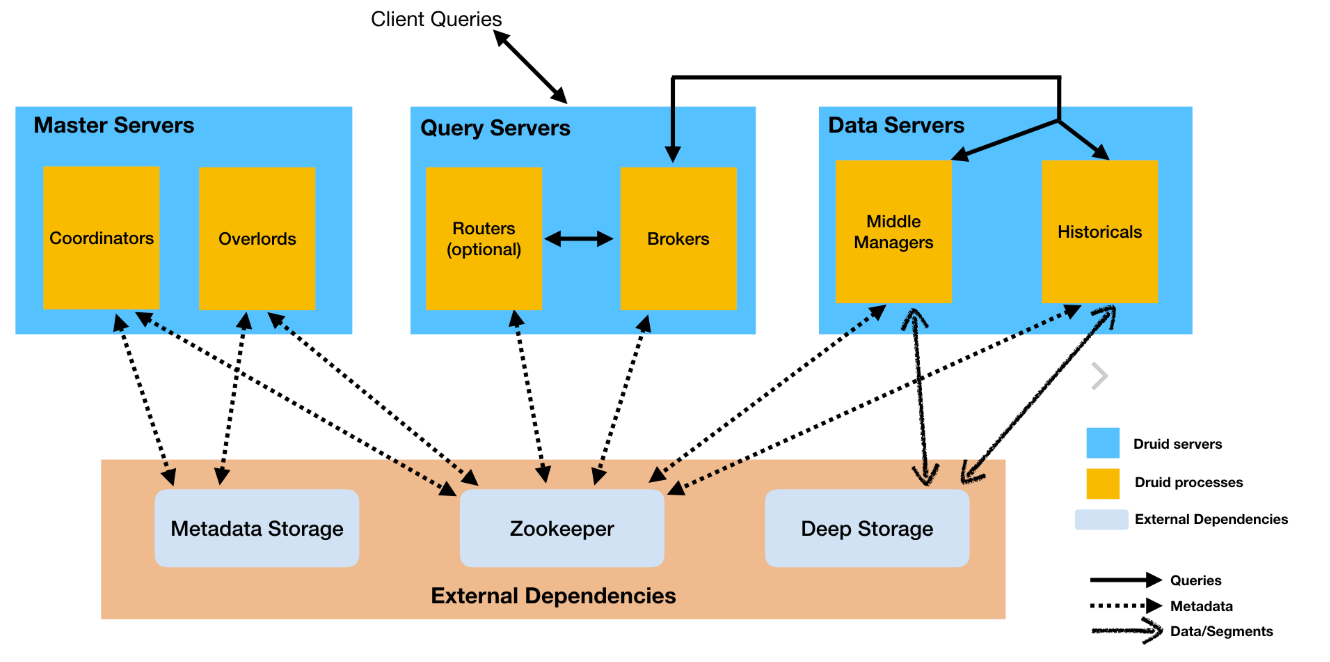
Apache Druid是一个开源、分布式、高性能的实时数据分析的数据存储系统。能快速的实现查询与数据分析,具有高可用、高拓展的能力。 中文网址:http://www.apache-druid.cn/ Druid的常用应用领域包括: 点击流分析(web和移动分析)网络遥测分析(网络性能监控)服务器指标存储供应链分析(制造指标)应用程序性能度量数字营销/广告分析商业智能/联机分析处理Druid可以运行在任意的商业硬件上,可以部署在云上也可以内部部署。同时也能够与诸如Hadoop、Spark、Kafka、Storm、Flink、Samza等数据系统进行集成。 1.2 druid应用场景Druid适合于以下场景: 插入频繁,但很少更新大多数查询都是聚合和报告性质的查询(“group by”查询)查询延迟要求为100毫秒到几秒数据中有一个时间组件(Druid包括具体与时间相关的优化和设计选择)有高基数数据列(例如URL,用户ID),需要对它们进行快速计数和排名 高基数数据,有一列或多列包含大量的唯一值。例如,用户名、电子邮件地址和银行帐号 希望从Kafka,HDFS,文件或对象存储(如Amazon S3)中加载数据 1.3 druid的特点Druid的核心架构结合了数据仓库,时间序列数据库和日志搜索系统的创意。Druid的一些主要特点是: 列式存储格式 Druid使用面向列的存储,这意味着它只需要加载特定的查询所需的精确列。这为仅查看几列的查询提供了巨大的速度提升。此外,每列都针对其特定数据类型进行了优化,支持快速扫描和聚合。可扩展的分布式系统 Druid通常部署在数十到数百台服务器的集群中,可以提供数百万条记录/秒的摄取率,保留数万亿条记录,以及亚秒级到几秒钟的查询延迟。大规模并行处理 Druid可以在整个集群中并行处理查询。实时或批量采集 Druid可以实时流式采集数据(采集的数据可立即用于查询)或批量采集。自愈,自平衡,易于操作 作为运营商,要将群集扩展或缩小,只需添加或删除服务器,群集将在后台自动重新平衡,无需任何停机时间。如果任何Druid服务器发生故障,系统将自动绕过损坏路由,直到可以更换这些服务器。Druid旨在全天候运行,无需任何原因计划停机,包括配置更改和软件更新。云本机,容错架构,不会丢失数据 一旦Druid采集了您的数据,副本就会安全地存储在[深层存储](通常是云存储,HDFS或共享文件系统)中。即使每个Druid服务器都出现故障,您的数据也可以从深层存储中恢复。对于仅影响少数Druid服务器的更有限的故障,复制可确保在系统恢复时仍可进行查询。用于快速过滤的索引 Druid使用[CONCISE]或 [Roaring]压缩bitmap索引来创建索引,这些索引可以跨多个列进行快速过滤和搜索。基于时间的分区 Druid首先按时间划分数据,并且可以基于其他字段进行额外划分。这意味着基于时间的查询将仅访问与查询的时间范围匹配的分区。这导致基于时间的数据的显着性能改进。近似算法 Druid包括用于近似count-distinct的算法,近似排序以及近似直方图和分位数的计算的算法。这些算法提供有限的内存使用,并且通常比精确计算快得多。对于精度比速度更重要的情况,Druid还提供精确的count-distinct以及精确的排序。在采集时自动汇总 Druid可选择在采集时支持数据汇总。提前预聚合数据,可以节省大量存储成本并提高性能。 1.4 druid的进程和服务Druid是一个多进程、分布式的架构。每个Druid进程都可以独立配置和扩展,在集群上提供最大的灵活性。 Druid有以下几个进程: Coordinator: 管理集群上的数据可用性Overlord: 控制数据摄取工作负载的分配Broker: 处理来自外部客户端的查询请求Router: 可选进程,可以将请求路由到Brokers, Coordinators, and OverlordsHistorical: 存储历史查询到的数据MiddleManager: 负责摄取数据Druid进程可以按您喜欢的任何方式部署,但是为了便于部署,我们建议将它们组织成三种服务器类型:主服务器(Master)、查询服务器(Query)和数据服务器(Data)。 Master:运行Coordinator和Overlord进程,管理数据可用性和摄取。Query:运行Broker和可选的Router进程,处理来自外部客户端的查询。Data:运行Historical和MiddleManager进程,运行数据的采集以及存储所有历史查询数据负载。
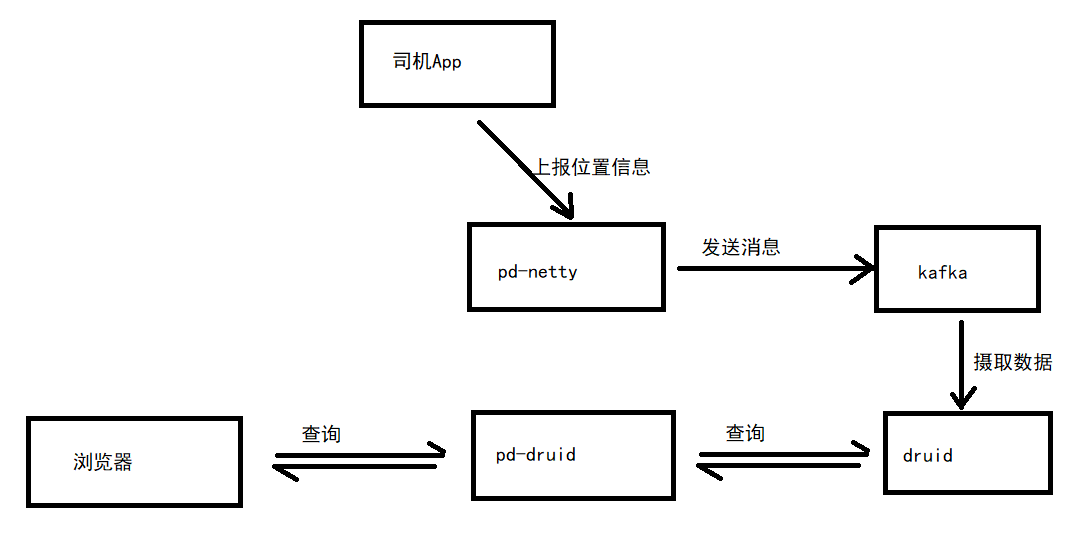
Druid中的所有数据都被组织成段,这些段是数据文件,通常每个段最多有几百万行。在Druid中加载数据称为摄取,它包括从源系统读取数据并基于该数据创建段。在大多数摄取方法中,加载数据的工作由MiddleManager进程完成。 Druid数据存储在数据源中,与传统关系型数据库中的表类似。 Druid把数据集分为三个部分: Timestamp column(时间戳):将时间字段单独处理,是因为Druid的所有查询都是围绕时间轴进行的。Dimension columns(维度列): 维度列是数据的属性,是按原样存储的列,可以在查询时以特殊方式对维度进行分组、筛选或应用聚合器。Metric columns(指标列):指标列是以聚合形式存储的列,用来做数据的聚合计算。指标列一般是可以衡量的数据,一般可以做count、sum等操作。 1.6 druid在本项目的应用本项目使用druid主要用于存储车辆定位信息,具体流程如下图:
Apache druid运行需要依赖其他一些软件环境,所以需要先安装依赖环境,最后再安装druid。 这些依赖的环境包括: jdkzookeeperkafka 2.1 jdk安装 # 解压命令 tar -zxf jdk-8u191-linux-x64.tar.gz -C /usr/local/ # 修改配置命令 vi /etc/profile # 添加内容: export JAVA_HOME=/usr/local/jdk1.8.0_191 export PATH=$JAVA_HOME/bin:$PATH # 配置生效命令 source /etc/profile #查看java版本命令 java -version 2.2 zookeeper安装 #启动容器: docker run -id --name my_zookeeper -p 2181:2181 -v /etc/localtime:/etc/localtime zookeeper:3.4.14 #查看容器运行情况: docker logs -f my_zookeeper 2.3 kafka安装 下载安装 #拉取镜像 docker pull wurstmeister/kafka #启动容器 docker run -id --name kafka -p 9092:9092 -e KAFKA_BROKER_ID=0 -e KAFKA_ZOOKEEPER_CONNECT=68.79.63.42:2181 -e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://68.79.63.42:9092 -e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 -v /etc/localtime:/etc/localtime wurstmeister/kafka #查看容器运行情况: docker logs -f kafka 参数说明 -e KAFKA_BROKER_ID=0 在kafka集群中,每个kafka都有一个BROKER_ID来区分自己 -e KAFKA_ZOOKEEPER_CONNECT=68.79.63.42:2181 配置zookeeper管理kafka的路径 -e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://68.79.63.42:9092 把kafka的地址端口注册给zookeeper -e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 配置kafka的监听端口 -v /etc/localtime:/etc/localtime 容器时间同步虚拟机的时间 验证安装完成后需要测试一下安装是否成功: #进入kafka容器 docker exec -it kafka /bin/bash #进入bin目录 cd /opt/kafka_2.12-2.5.0/bin/ #执行命令,创建名称为test的队列,此队列有一个副本,一个分区 ./kafka-topics.sh --create --zookeeper 68.79.63.42:2181 --replication-factor 1 --partitions 1 --topic test #查看刚刚创建的队列 ./kafka-topics.sh -list -zookeeper 68.79.63.42:2181 消息发送和接收接下来通过kafka提供的脚本测试发送消息和接收消息: #执行命令,启动消费端,监听test队列 ./kafka-console-consumer.sh --bootstrap-server 68.79.63.42:9092 --topic test --from-beginning #新开一个命令窗口,启动生产者,向test队列发送消息 ./kafka-console-producer.sh --broker-list 68.79.63.42:9092 --topic test #测试完成后按Ctrl+C退出 2.4 druid安装 下载 cd /root wget https://archive.apache.org/dist/incubator/druid/0.15.0-incubating/apache-druid-0.15.0-incubating-bin.tar.gz 安装 tar -zxvf apache-druid-0.15.0-incubating-bin.tar.gz mv apache-druid-0.15.0-incubating druid #此时druid已经安装在/root目录下,根目录为/root/druid 配置 # 因为使用了本地zk,所以需要去掉2181端口的检测 vi /root/druid/bin/verify-default-ports my @ports = (1527, 8081, 8082, 8083, 8090, 8091, 8200, 9095); # 注释Zookeeper配置 vi /root/druid/conf/supervise/single-server/small.conf #!p10 zk bin/run-zk conf # 修改公共配置 vi /root/druid/conf/druid/single-server/small/_common/common.runtime.properties # # Hostname # druid.host=127.0.0.1 # # Zookeeper # druid.zk.service.host=127.0.0.1 druid.zk.paths.base=/druid # 设置各组件时区 vi /root/druid/conf/druid/single-server/small/broker/jvm.config -Duser.timezone=UTC+8 vi /root/druid/conf/druid/single-server/small/coordinator-overlord/jvm.config -Duser.timezone=UTC+8 vi /root/druid/conf/druid/single-server/small/historical/jvm.config -Duser.timezone=UTC+8 vi /root/druid/conf/druid/single-server/small/middleManager/jvm.config -Duser.timezone=UTC+8 vi /root/druid/conf/druid/single-server/small/router/jvm.config -Duser.timezone=UTC+8 启动 # 执行启动脚本 /root/druid/bin/start-single-server-small启动完成后访问:http://{druid服务ip}:8888
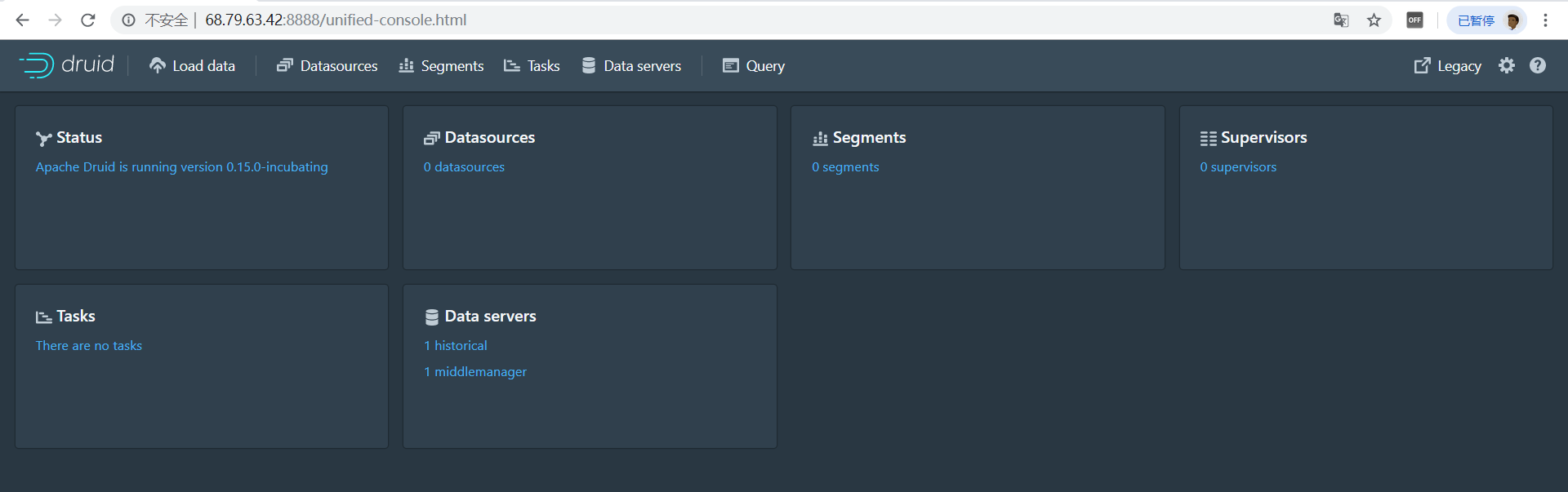
第一步:访问druid控制台http://{druid服务ip}:8888/
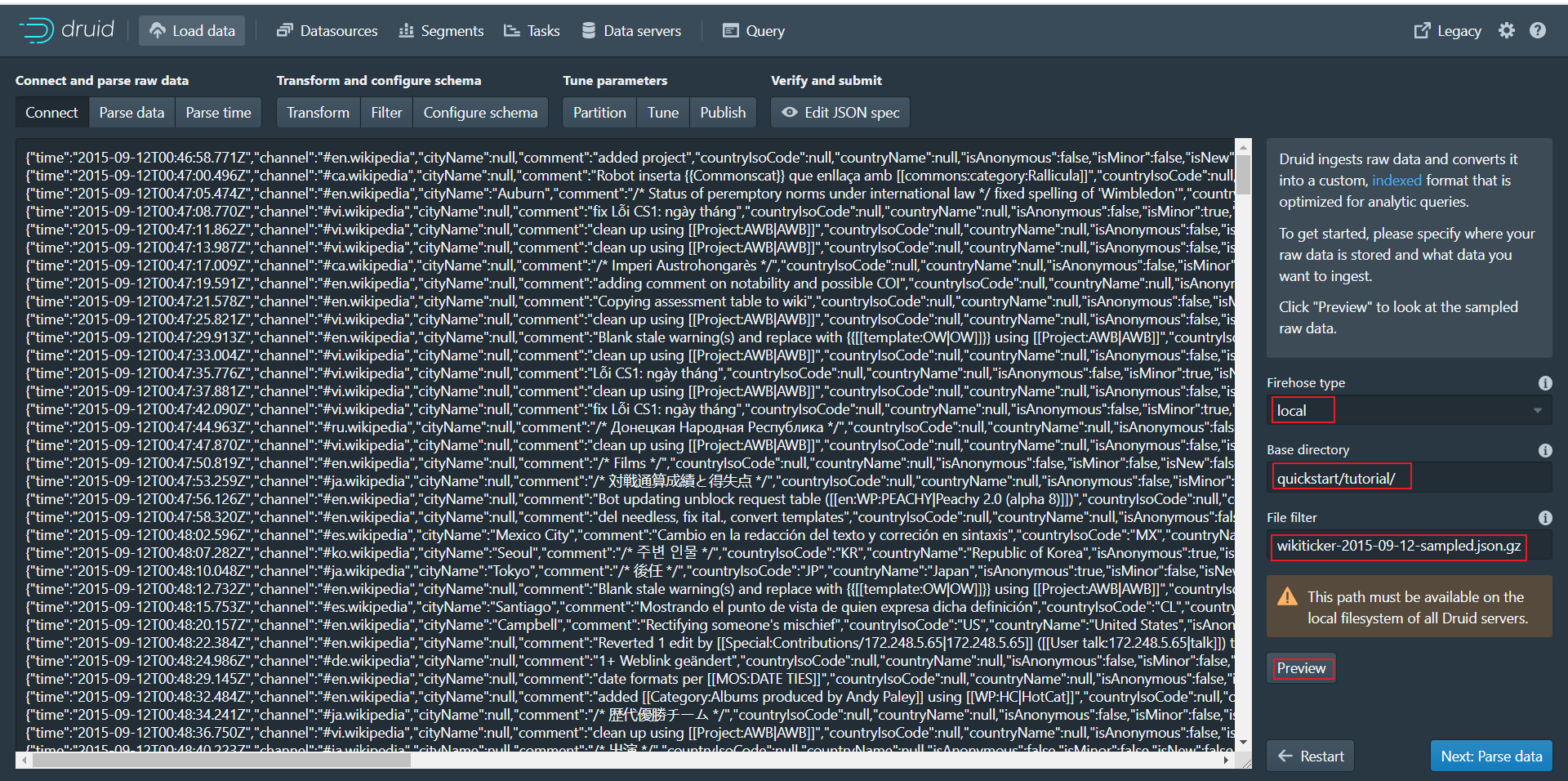
第二步:点击Load data进入加载数据页面,并输入下面相关参数
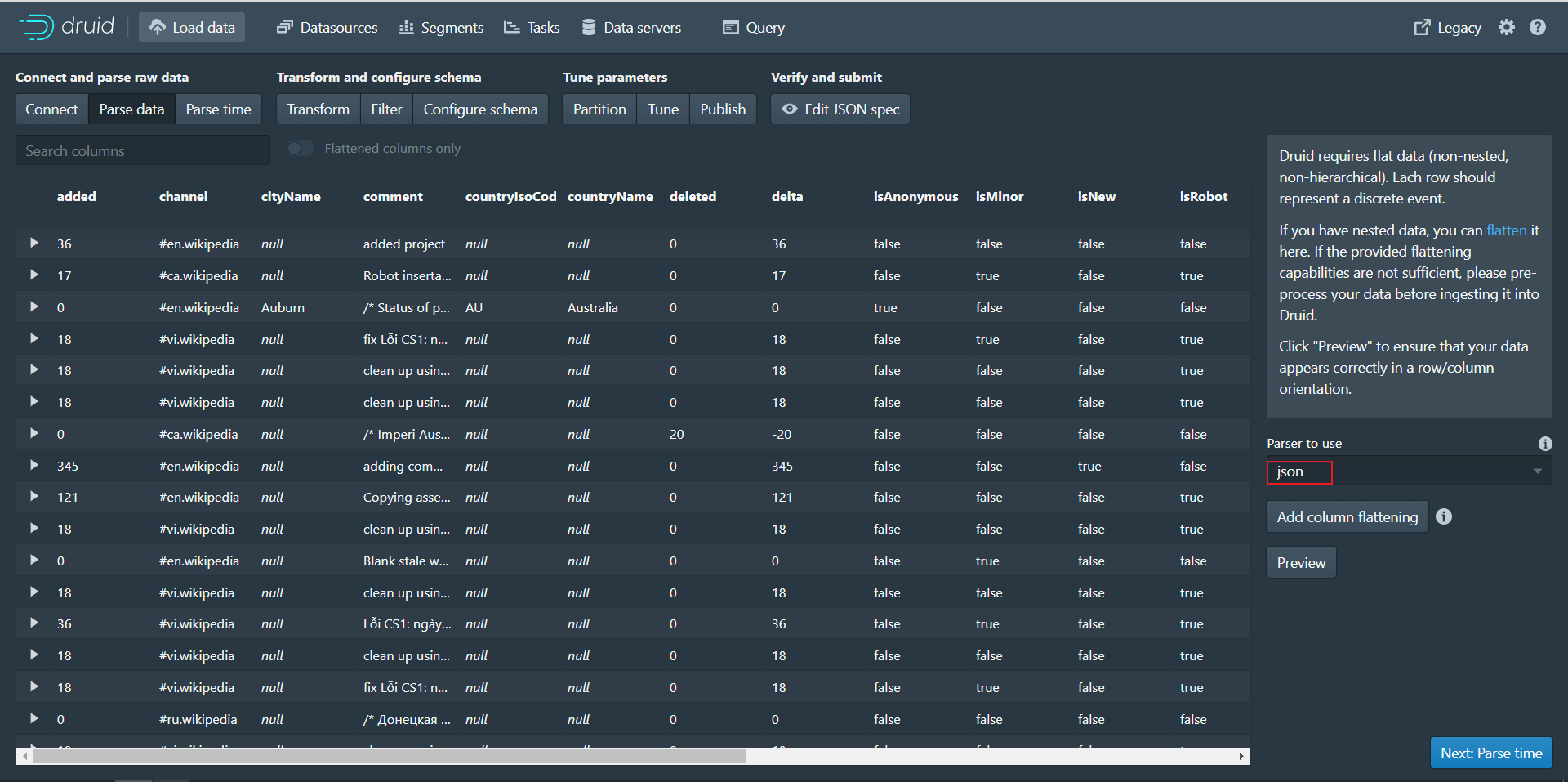
在 Base directory 中输入 quickstart/tutorial/, 在 File filter 中输入 wikiticker-2015-09-12-sampled.json.gz。 第三步:点击Next:Parse data进入下个页面
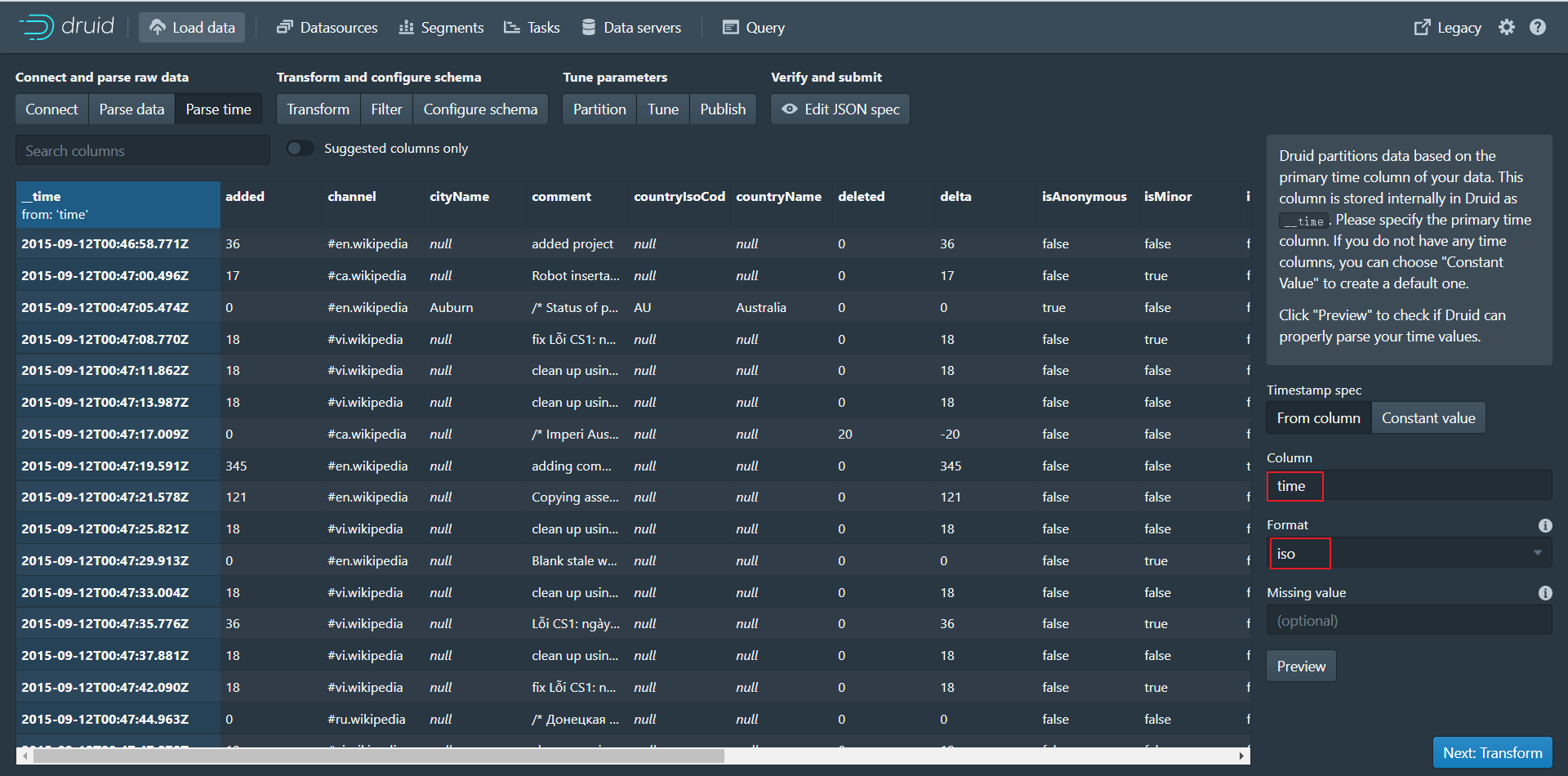
第四步:点击Next:Parse time进入下个页面
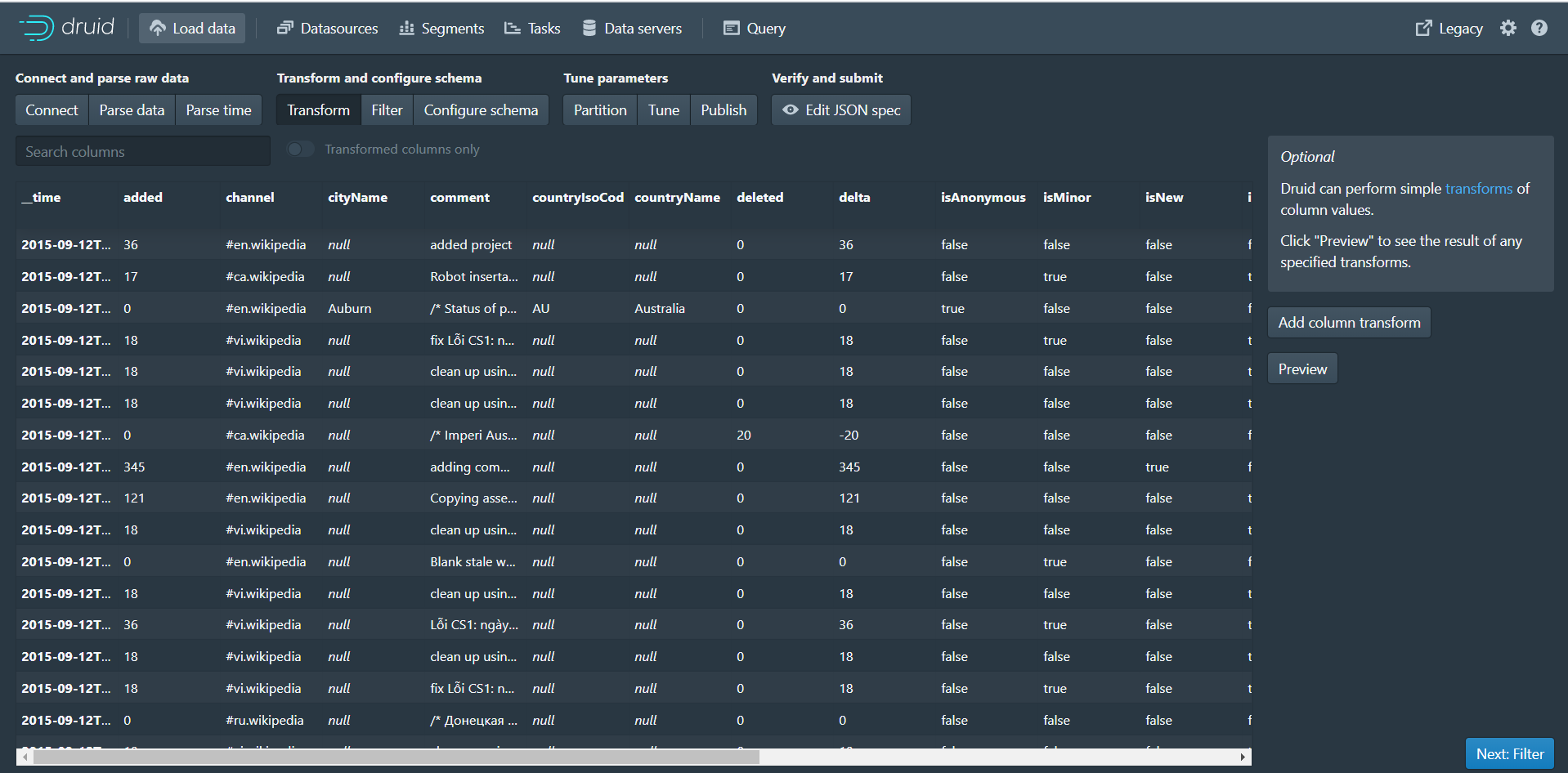
第五步:点击Next:Transform进入下个页面
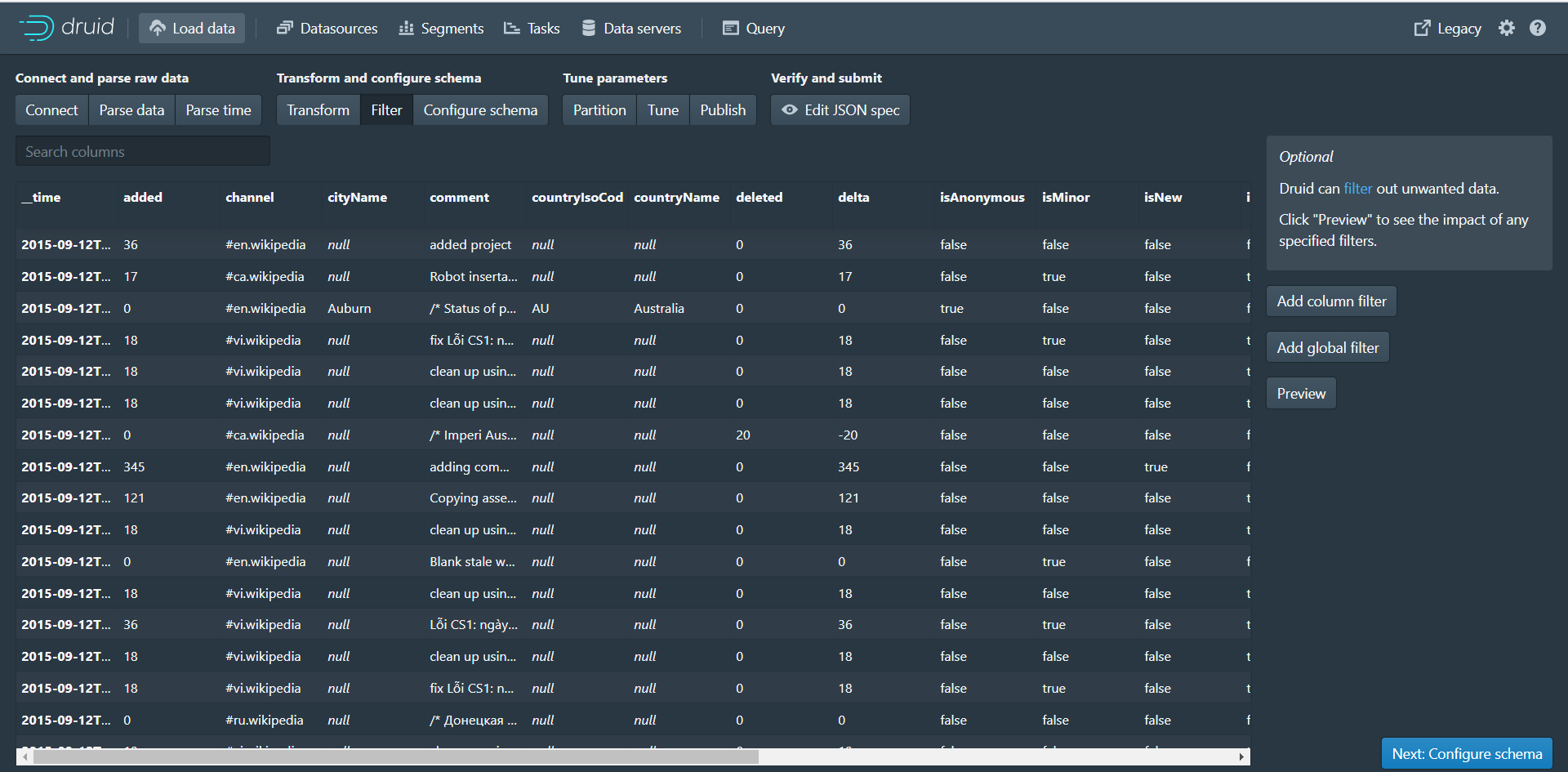
第六步:点击Next:Filter进入下个页面
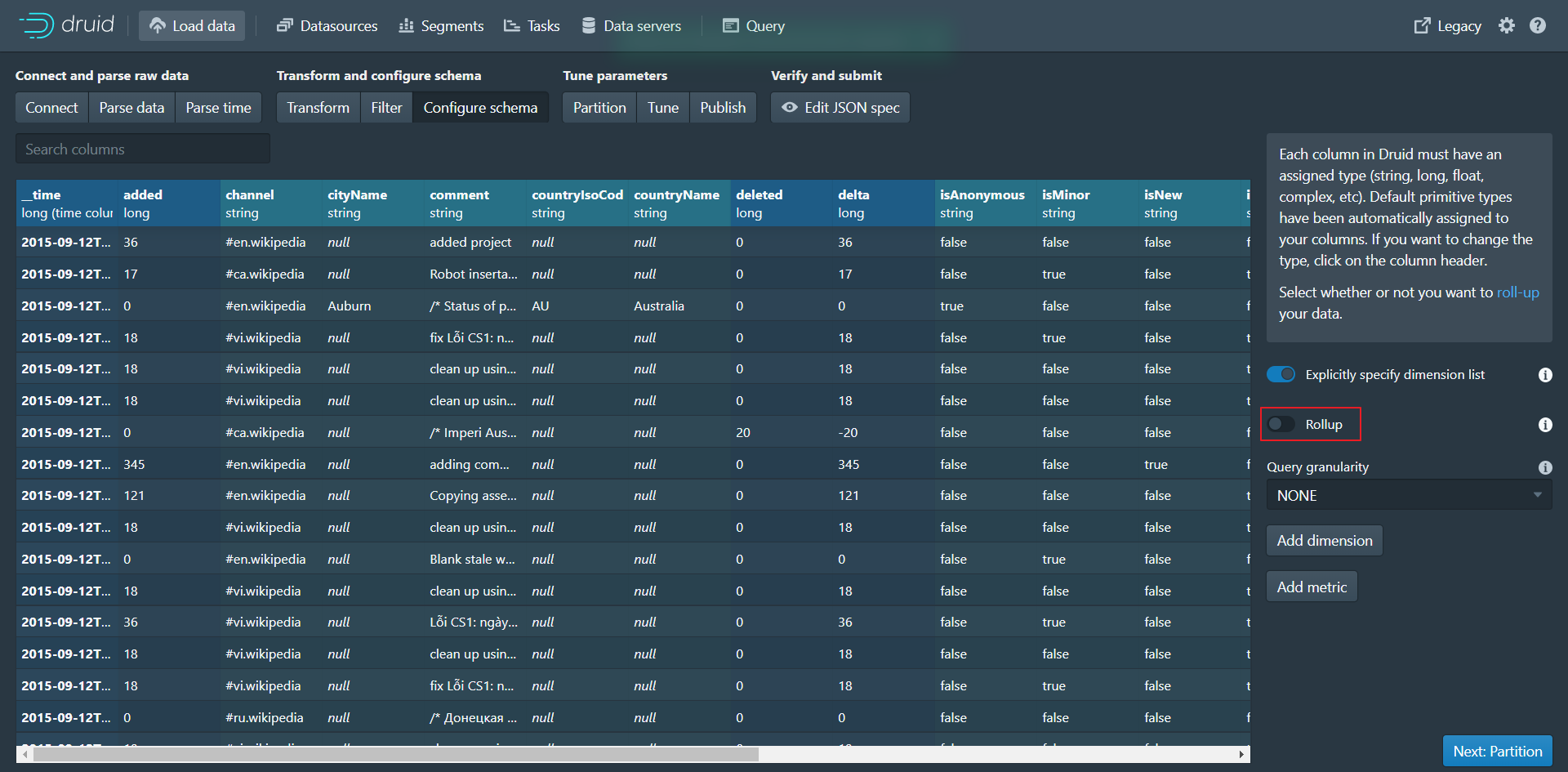
第七步:点击Next:Configure schema进入下个页面
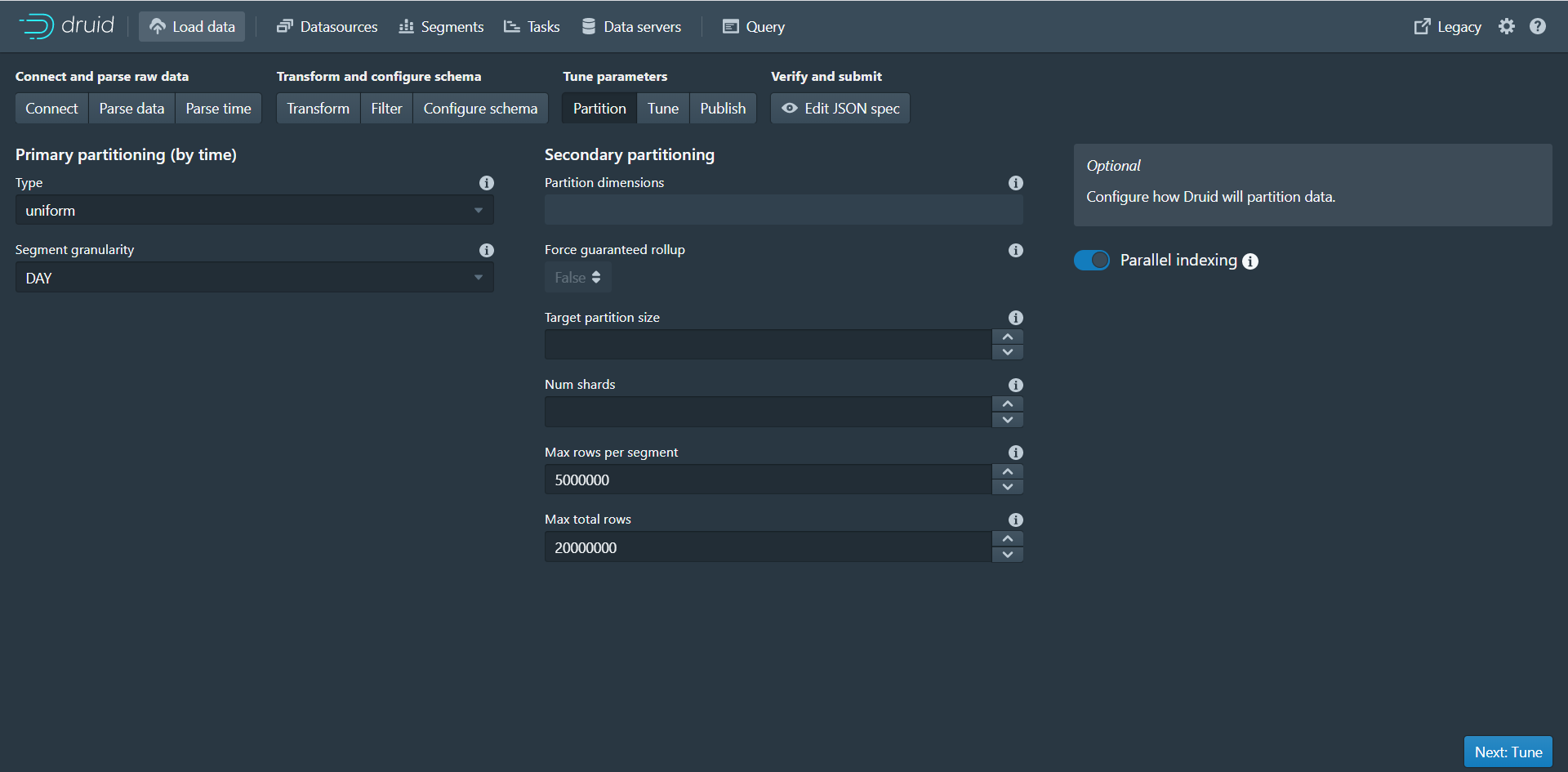
第八步:点击Next:Partition进入下个页面
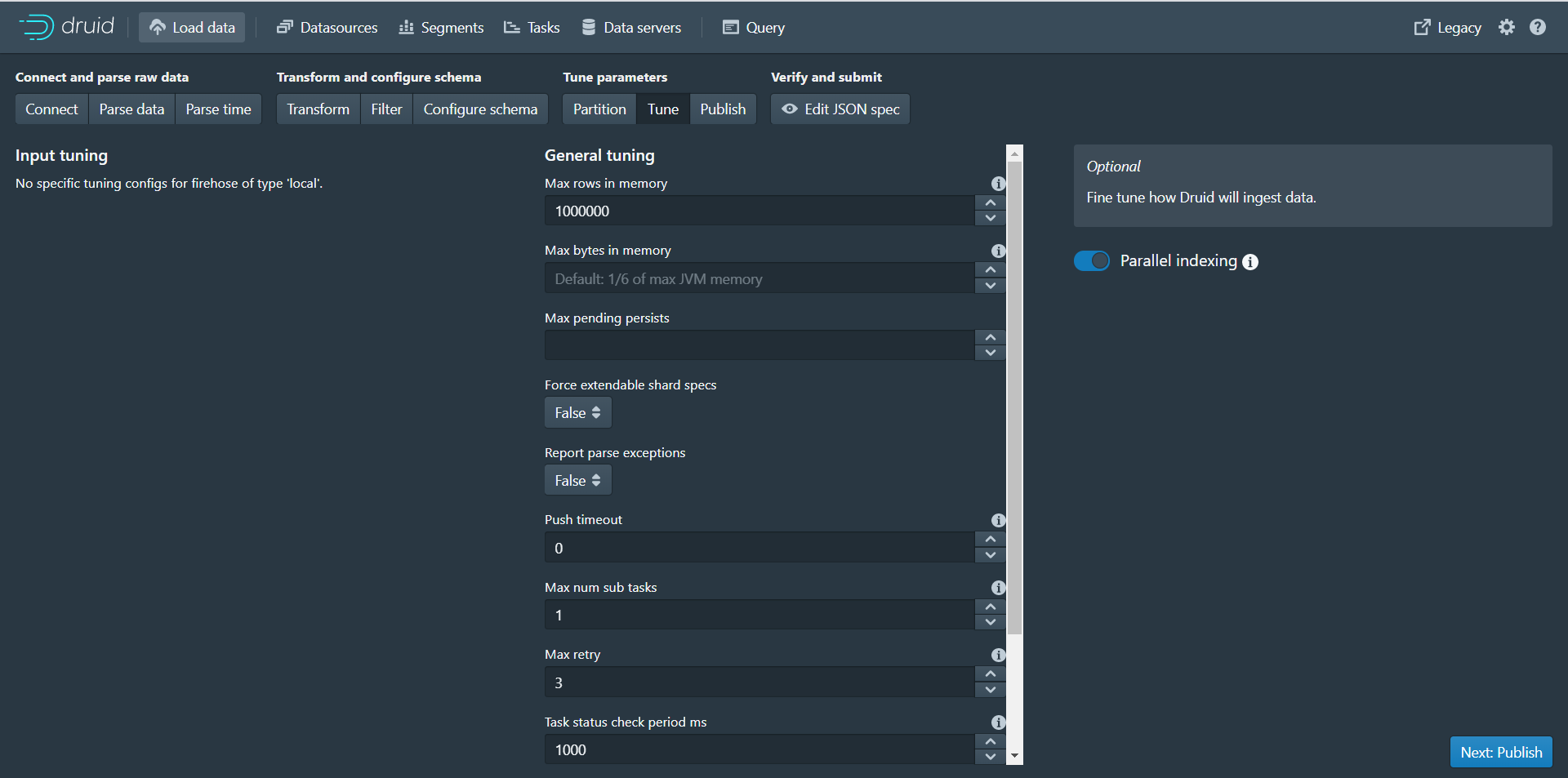
第九步:点击Next:Tune进入下个页面
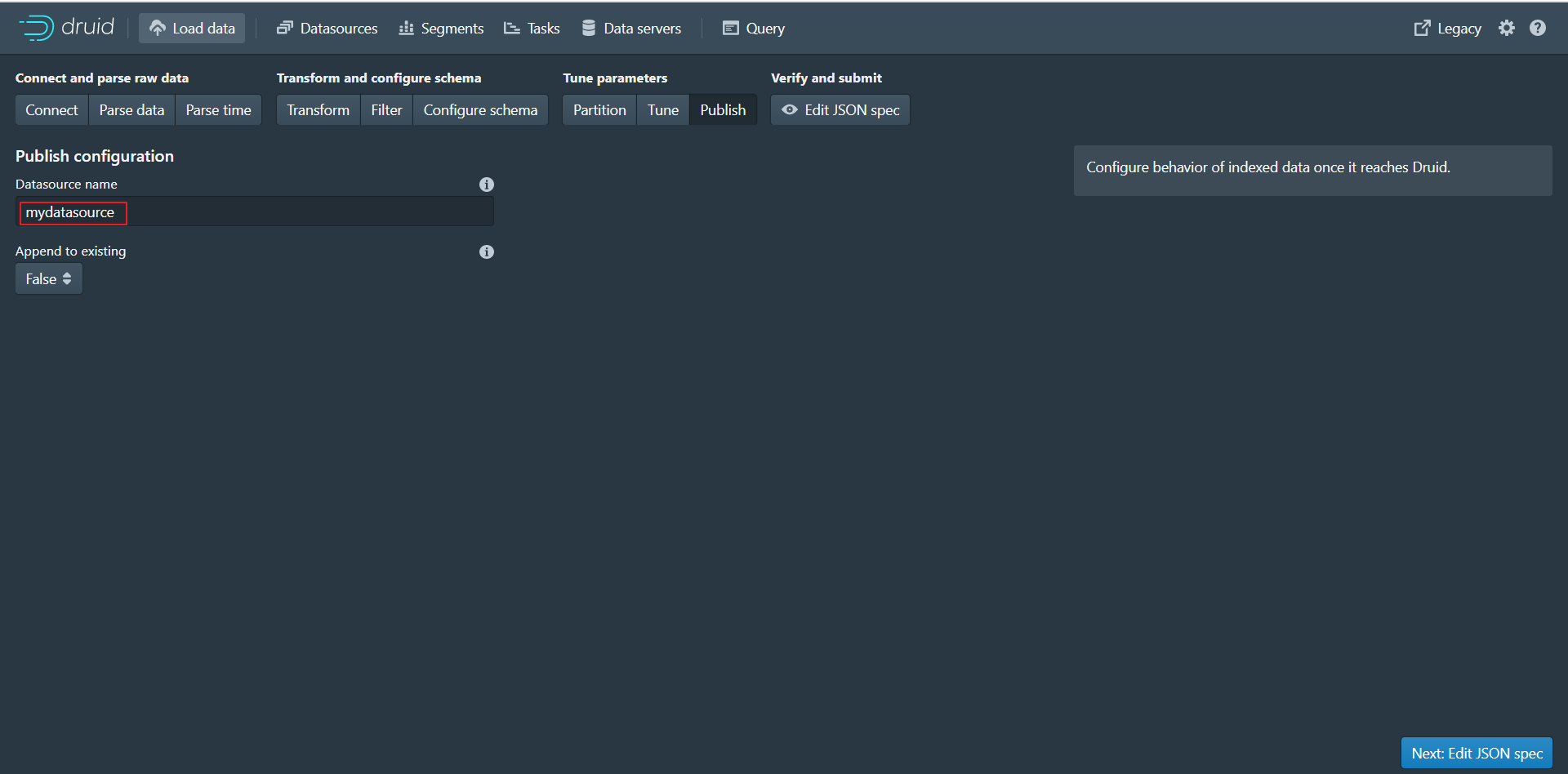
第十步:点击Next:Publish进入下个页面
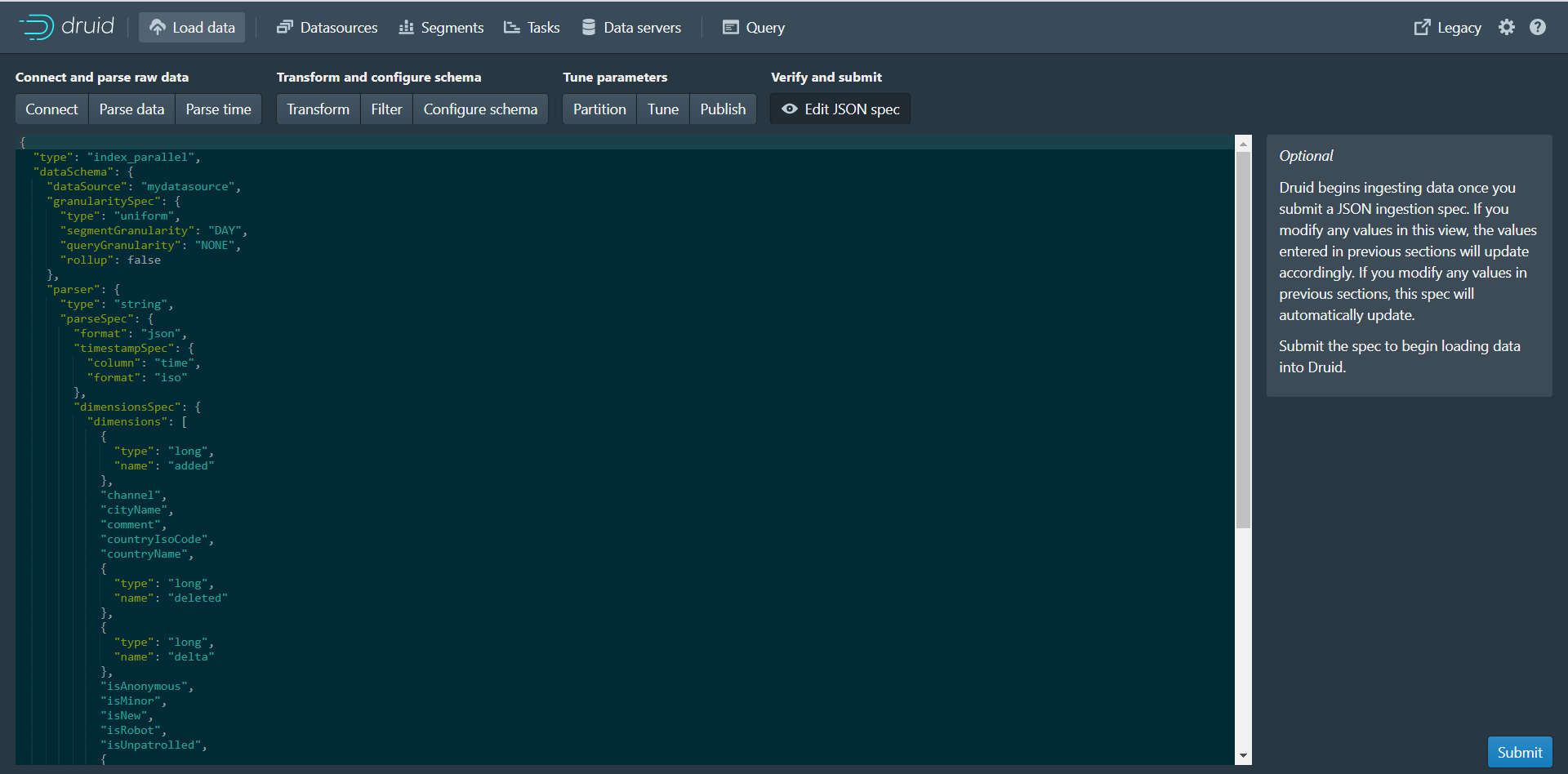
第十一步:点击Next:Edit JSON spec进入下个页面
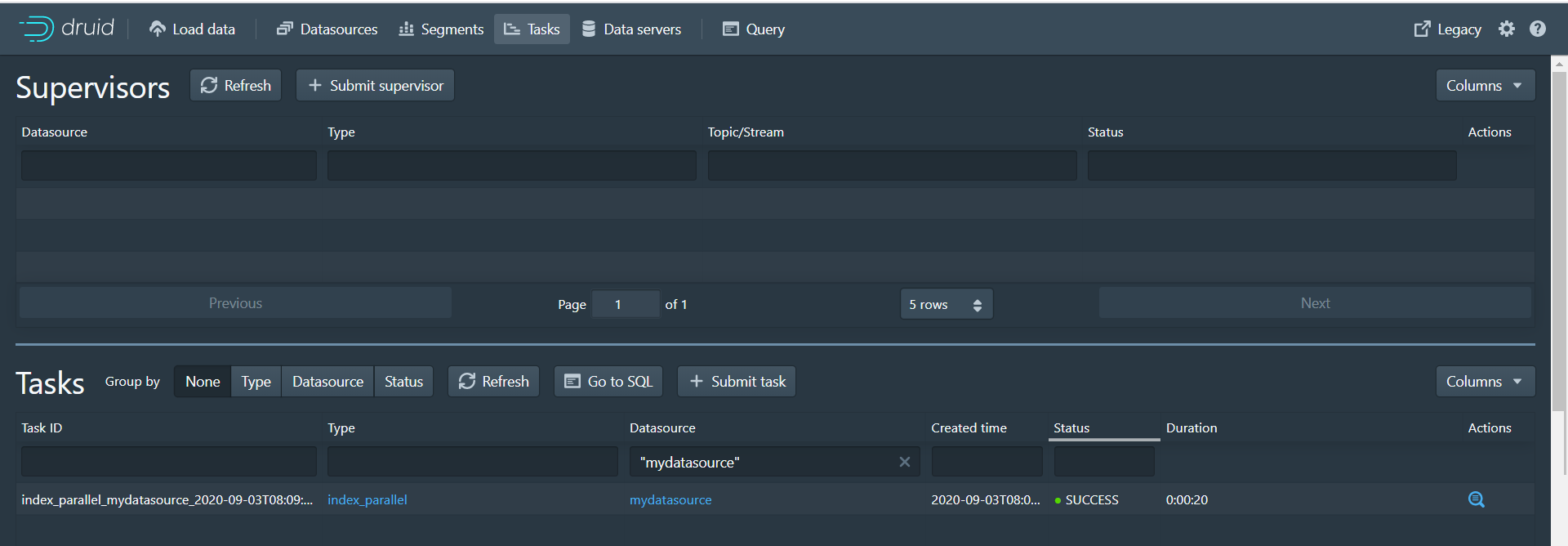
可以看到本页面展示的json数据其实就是数据摄取规范,根据我们前面每个页面设置的参数最终生成了当前的json数据。 数据摄取任务规范可以手动编写,也可以通过Druid控制台里内置的数据加载器编写。数据加载器可以通过采样摄入的数据并配置各种摄入参数来帮助您生成摄取任务规范。数据加载器当前仅支持本地批处理提取(将来的版本中将提供对流的支持,包括存储在Apache Kafka和AWS Kinesis中的数据)。目前只能通过手动书写摄入规范来进行流式摄入。第十二步:点击Submit按钮进行任务提交,跳转到任务页面
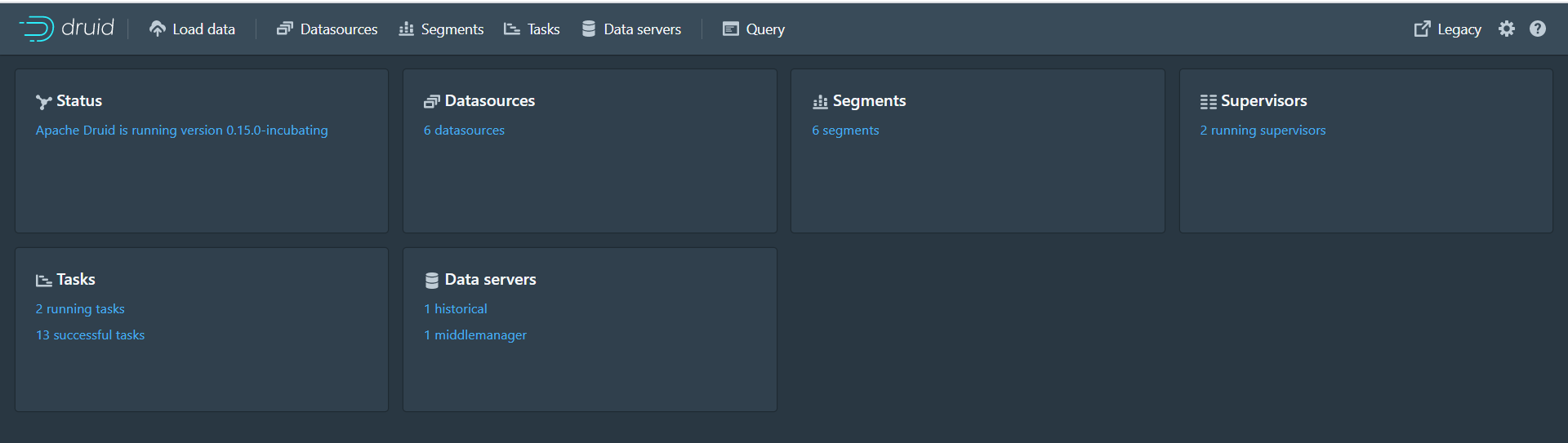
第十三步:任务执行完成后,点击Datasources进入数据源页面,可以看到mydatasource数据源
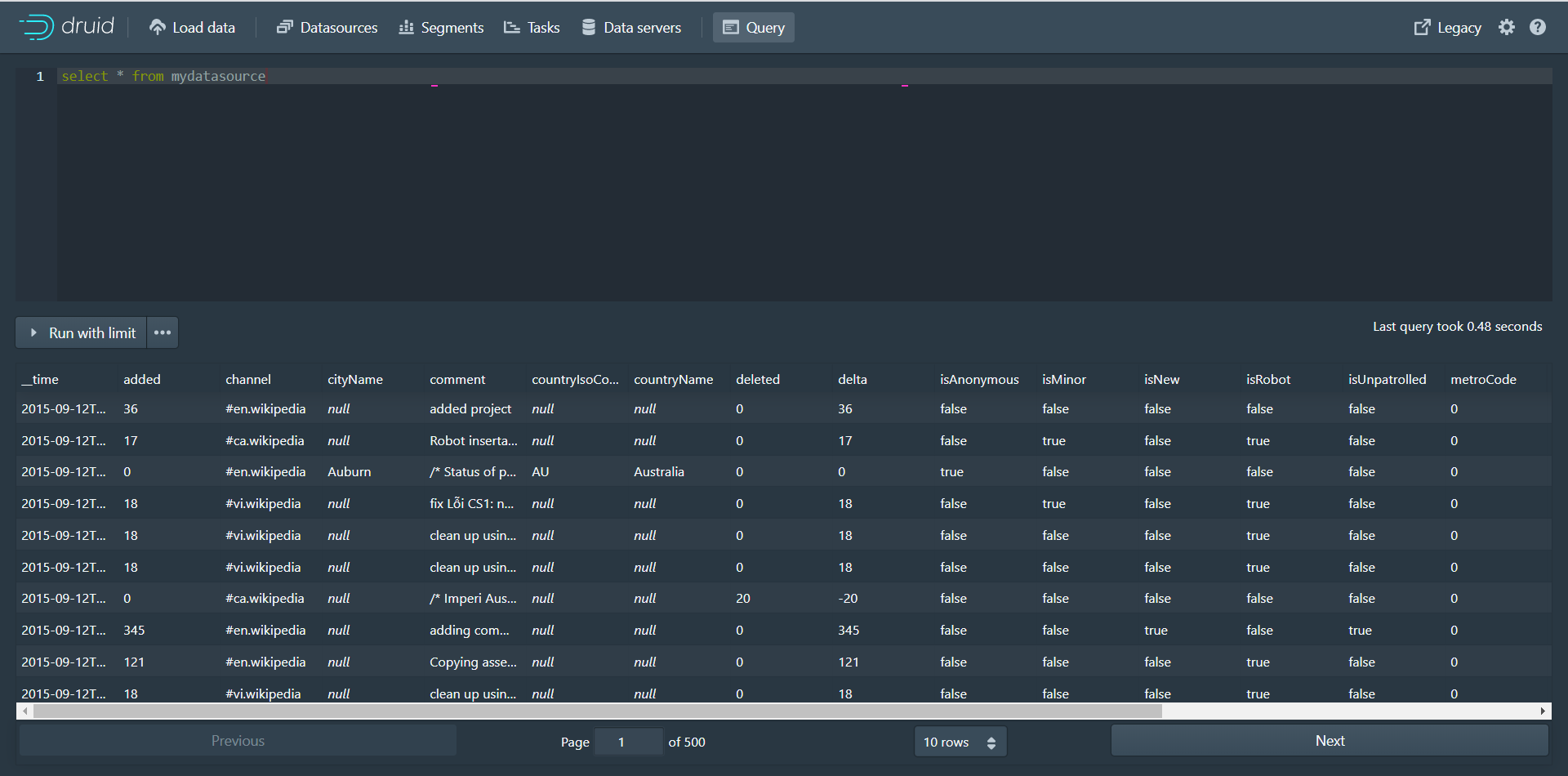
第十四步:点击Query进入数据查询页面,可以查询数据
第一步:访问druid控制台,点击Tasks进入任务页面
第二步:点击Submit task按钮,选择Raw JSON task
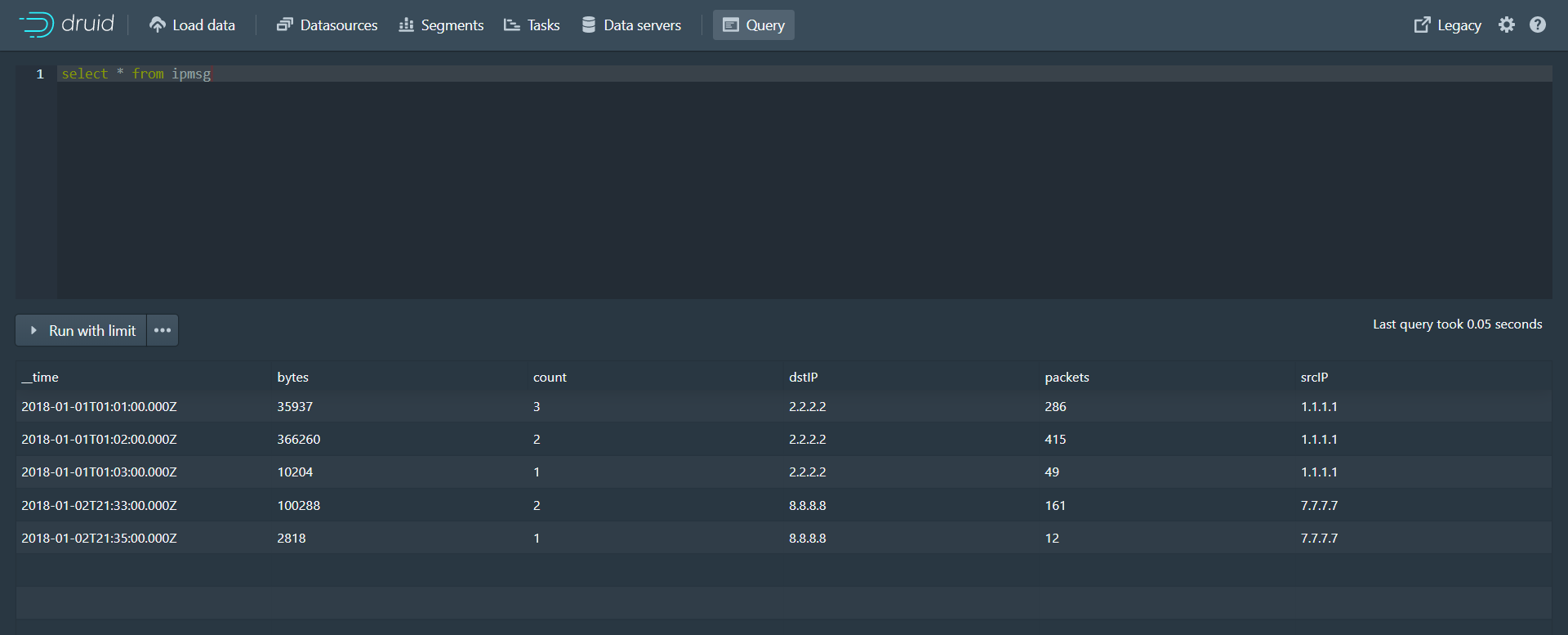
第三步:在弹出的编辑窗口中输入下面数据摄取规范 { "type" : "index", "spec" : { "dataSchema" : { "dataSource" : "ipmsg", "parser" : { "type" : "string", "parseSpec" : { "format" : "json", "dimensionsSpec" : { "dimensions" : [ "srcIP", "dstIP" ] }, "timestampSpec": { "column": "timestamp", "format": "iso" } } }, "metricsSpec" : [ { "type" : "count", "name" : "count" }, { "type" : "longSum", "name" : "packets", "fieldName" : "packets" }, { "type" : "longSum", "name" : "bytes", "fieldName" : "bytes" } ], "granularitySpec" : { "type" : "uniform", "segmentGranularity" : "week", "queryGranularity" : "minute", "intervals" : ["2018-01-01/2018-01-03"], "rollup" : true } }, "ioConfig" : { "type" : "index", "firehose" : { "type" : "local", "baseDir" : "quickstart/tutorial", "filter" : "rollup-data.json" }, "appendToExisting" : false }, "tuningConfig" : { "type" : "index", "maxRowsPerSegment" : 5000000, "maxRowsInMemory" : 25000 } } }第四步:点击Submit提交任务,任务执行完成后点击Query进入查询页面进行数据查询
原始数据(rollup-data.json文件中的数据,共9条数据):
存储到druid的数据(共5条数据):
可以看到原始json文件中的数据是9条,存储到druid后的数据变为5条,这是因为数据摄取时按照我们设置的指标进行了数据聚合,并且还进行了count和longsum的计算。 3.2.3 案例三第一步:访问druid控制台,点击Tasks进入任务页面
第二步:点击Submit task按钮,选择Raw JSON task
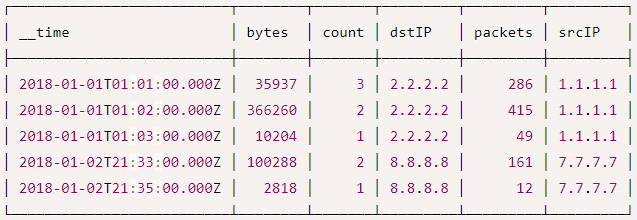
第三步:在弹出的编辑窗口中输入下面数据摄取规范 { "type" : "index", "spec" : { "dataSchema" : { "dataSource" : "mydatasource2", "parser" : { "type" : "string", "parseSpec" : { "format" : "json", "dimensionsSpec" : { "dimensions" : [ "animal", { "name": "location", "type": "long" } ] }, "timestampSpec": { "column": "timestamp", "format": "iso" } } }, "metricsSpec" : [ { "type" : "count", "name" : "count" }, { "type" : "longSum", "name" : "number", "fieldName" : "number" }, { "type" : "longSum", "name" : "triple-number", "fieldName" : "triple-number" } ], "granularitySpec" : { "type" : "uniform", "segmentGranularity" : "week", "queryGranularity" : "minute", "intervals" : ["2018-01-01/2018-01-03"], "rollup" : true }, "transformSpec": { "transforms": [ { "type": "expression", "name": "animal", "expression": "concat('super-', animal)" }, { "type": "expression", "name": "triple-number", "expression": "number * 3" } ], "filter": { "type":"or", "fields": [ { "type": "selector", "dimension": "animal", "value": "super-mongoose" }, { "type": "selector", "dimension": "triple-number", "value": "300" }, { "type": "selector", "dimension": "location", "value": "3" } ] } } }, "ioConfig" : { "type" : "index", "firehose" : { "type" : "local", "baseDir" : "quickstart/tutorial", "filter" : "transform-data.json" }, "appendToExisting" : false }, "tuningConfig" : { "type" : "index", "maxRowsPerSegment" : 5000000, "maxRowsInMemory" : 25000 } } }第四步:点击Submit提交任务,任务执行完成后点击Query进入查询页面进行数据查询
原始数据(transform-data.json文件中的数据,共4条数据):
存储到druid的数据(共3条数据):
可以看到原始json文件中的数据是4条,存储到druid后的数据变为3条,这是因为数据摄取时进行了过滤,并且进行了数据加工处理。 3.3 从Kafka摄取数据准备工作: #进入kafka容器 docker exec -it kafka /bin/bash #进入bin目录 cd /opt/kafka_2.12-2.5.0/bin/ #执行命令,创建名称为test的队列,此队列有一个副本,一个分区 ./kafka-topics.sh --create --zookeeper 68.79.63.42:2181 --replication-factor 1 --partitions 1 --topic ip_msg #查看刚刚创建的队列 ./kafka-topics.sh -list -zookeeper 68.79.63.42:2181第一步:访问druid控制台http://{druid服务ip}:8888/
第二步:点击Tasks按钮进入任务页面
第三步:点击Submit supervisor按钮弹出窗口
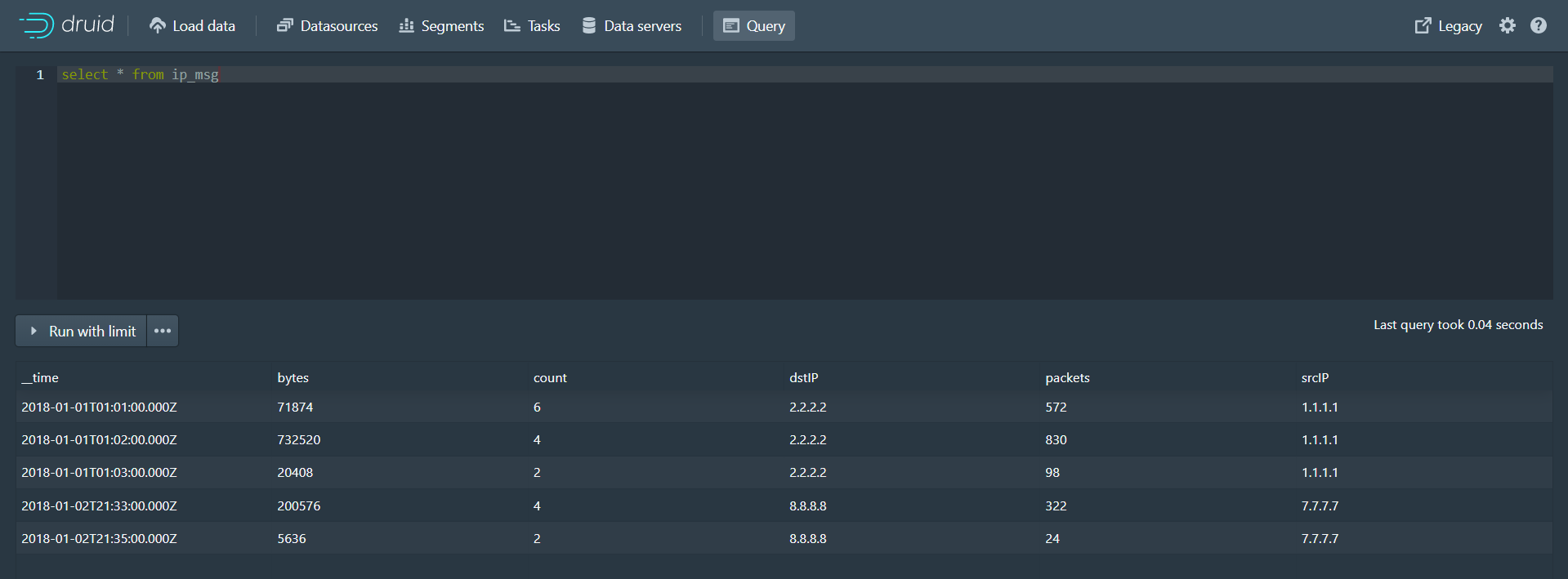
第四步:在弹出窗口中输入如下内容,用于配置数据摄取策略(从kafka的ip_msg队列中摄取数据) { "type": "kafka", "dataSchema": { "dataSource": "ip_msg", "parser": { "type": "string", "parseSpec": { "format": "json", "timestampSpec": { "column": "timestamp", "format": "iso" }, "dimensionsSpec": { "dimensions": [ "srcIP", "dstIP" ] } } }, "metricsSpec" : [ { "type" : "count", "name" : "count" }, { "type" : "longSum", "name" : "packets", "fieldName" : "packets" }, { "type" : "longSum", "name" : "bytes", "fieldName" : "bytes" } ], "granularitySpec": { "type": "uniform", "segmentGranularity": "week", "queryGranularity": "minute", "rollup": true } }, "tuningConfig": { "type": "kafka", "reportParseExceptions": false }, "ioConfig": { "topic": "ip_msg", "replicas": 1, "taskDuration": "PT10M", "completionTimeout": "PT20M", "consumerProperties": { "bootstrap.servers": "39.99.56.166:9092" } } }第五步:执行命令,向kafka队列发送消息 #启动生产者,向ip_msg队列发送消息 ./kafka-console-producer.sh --broker-list 68.79.63.42:9092 --topic ip_msg消息内容如下: {"timestamp":"2018-01-01T01:01:35Z","srcIP":"1.1.1.1", "dstIP":"2.2.2.2","packets":20,"bytes":9024} {"timestamp":"2018-01-01T01:01:51Z","srcIP":"1.1.1.1", "dstIP":"2.2.2.2","packets":255,"bytes":21133} {"timestamp":"2018-01-01T01:01:59Z","srcIP":"1.1.1.1", "dstIP":"2.2.2.2","packets":11,"bytes":5780} {"timestamp":"2018-01-01T01:02:14Z","srcIP":"1.1.1.1", "dstIP":"2.2.2.2","packets":38,"bytes":6289} {"timestamp":"2018-01-01T01:02:29Z","srcIP":"1.1.1.1", "dstIP":"2.2.2.2","packets":377,"bytes":359971} {"timestamp":"2018-01-01T01:03:29Z","srcIP":"1.1.1.1", "dstIP":"2.2.2.2","packets":49,"bytes":10204} {"timestamp":"2018-01-02T21:33:14Z","srcIP":"7.7.7.7", "dstIP":"8.8.8.8","packets":38,"bytes":6289} {"timestamp":"2018-01-02T21:33:45Z","srcIP":"7.7.7.7", "dstIP":"8.8.8.8","packets":123,"bytes":93999} {"timestamp":"2018-01-02T21:35:45Z","srcIP":"7.7.7.7", "dstIP":"8.8.8.8","packets":12,"bytes":2818}第六步:在druid控制台的Query页面查询数据
pd-netty服务的作用是接收司机端上报的车辆定位信息并将信息发送到kafka队列。pd-netty共提供两种方式来接收司机端上报的定位信息:基于netty实现的TCP方式、HTTP接口方式。 5.1.1 HTTP接口方式第一步:编写bootstrap.yml server: tomcat: uri-encoding: UTF-8 max-threads: 1000 min-spare-threads: 30 port: 8192 connection-timeout: 50000ms spring: application: name: pd-netty profiles: active: dev main: allow-bean-definition-overriding: true第二步:编写bootstrap-dev.yml spring: cloud: nacos: username: tms password: itheima123 discovery: server-addr: 68.79.63.42:8848 group: pinda-tms namespace: 301c574e-ae40-42c4-b717-d5379057f6a4 config: server-addr: 68.79.63.42:8848 file-extension: yml group: pinda-tms namespace: 301c574e-ae40-42c4-b717-d5379057f6a4 # jackson时间格式化 jackson: time-zone: ${spring.jackson.time-zone} date-format: ${spring.jackson.date-format} servlet: multipart: max-file-size: ${spring.servlet.multipart.max-file-size} max-request-size: ${spring.servlet.multipart.max-request-size} enabled: ${spring.servlet.multipart.enabled} # kafka kafka: bootstrap-servers: ${spring.kafka.bootstrap-servers} listener: # 指定listener 容器中的线程数,用于提高并发量 concurrency: ${spring.kafka.listener.concurrency} producer: retries: ${spring.kafka.producer.retries} batch-size: ${spring.kafka.producer.batch-size} buffer-memory: ${spring.kafka.producer.buffer-memory} key-serializer: ${spring.kafka.producer.key-serializer} value-serializer: ${spring.kafka.producer.value-serializer} consumer: group-id: ${spring.kafka.consumer.group-id}第三步:编写LocationEntity实体 package com.itheima.pinda.entity; import io.swagger.annotations.ApiModel; import io.swagger.annotations.ApiModelProperty; import lombok.Data; @Data @ApiModel("位置信息") public class LocationEntity { public String getId() { return businessId + "#" + type + "#" + currentTime; } /** * 车辆Id */ @ApiModelProperty("业务id, 快递员id 或者 车辆id") private String businessId; /** * 司机名称 */ @ApiModelProperty("司机名称") private String name; /** * 司机电话 */ @ApiModelProperty("司机电话") private String phone; /** * 车牌号 */ @ApiModelProperty("licensePlate") private String licensePlate; /** * 类型 */ @ApiModelProperty("类型,车辆:truck,快递员:courier") private String type; /** * 经度 */ @ApiModelProperty("经度") private String lng; /** * 维度 */ @ApiModelProperty("维度") private String lat; /** * 当前时间 */ @ApiModelProperty("当前时间 格式:yyyyMMddHHmmss") private String currentTime; @ApiModelProperty("所属车队") private String team; @ApiModelProperty("运输任务id") private String transportTaskId; }第四步:编写启动类 package com.itheima.pinda; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; import org.springframework.cloud.client.discovery.EnableDiscoveryClient; @SpringBootApplication @EnableDiscoveryClient public class NettyApplication { public static void main(String[] args) { SpringApplication.run(NettyApplication.class, args); } }第五步:编写KafkaSender,用于操作kafka package com.itheima.pinda.service; import lombok.extern.slf4j.Slf4j; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.kafka.core.KafkaTemplate; import org.springframework.stereotype.Component; import javax.annotation.PostConstruct; @Component @Slf4j public class KafkaSender { public final static String MSG_TOPIC = "tms_order_location"; @Autowired private KafkaTemplate kafkaTemplate; private static KafkaTemplate template; @PostConstruct public void init() { KafkaSender.template = this.kafkaTemplate; } //发送消息到kafka队列 public static boolean send(String topic, String message) { try { template.send(topic, message); log.info("消息发送成功:{} , {}", topic, message); } catch (Exception e) { log.error("消息发送失败:{} , {}", topic, message, e); return false; } return true; } }第六步:编写NettyController,通过HTTP接口方式接受司机端上报的车辆位置信息 package com.itheima.pinda.controller; import com.alibaba.fastjson.JSON; import com.itheima.pinda.common.utils.Result; import com.itheima.pinda.entity.LocationEntity; import com.itheima.pinda.service.KafkaSender; import io.swagger.annotations.Api; import lombok.extern.slf4j.Slf4j; import org.springframework.web.bind.annotation.PostMapping; import org.springframework.web.bind.annotation.RequestBody; import org.springframework.web.bind.annotation.RequestMapping; import org.springframework.web.bind.annotation.RestController; @RestController @Api(tags = "车辆轨迹服务") @RequestMapping("netty") @Slf4j public class NettyController { @PostMapping(value = "/push") public Result push(@RequestBody LocationEntity locationEntity) { String message = JSON.toJSONString(locationEntity); log.info("HTTP 方式推送位置信息:{}", message); KafkaSender.send(KafkaSender.MSG_TOPIC, message); return Result.ok(); } } 5.1.2 TCP方式 Netty是由JBOSS提供的一个Java开源框架。Netty提供异步的、事件驱动的网络应用程序框架和工具,用以快速开发高性能、高可靠性的网络服务器和客户端程序。第一步:编写NettyServer服务启动类 package com.itheima.pinda.config; import com.itheima.pinda.service.NettyServerHandler; import io.netty.bootstrap.ServerBootstrap; import io.netty.channel.ChannelFuture; import io.netty.channel.ChannelOption; import io.netty.channel.EventLoopGroup; import io.netty.channel.nio.NioEventLoopGroup; import io.netty.channel.socket.nio.NioServerSocketChannel; import lombok.extern.slf4j.Slf4j; import org.springframework.beans.factory.annotation.Value; import org.springframework.boot.CommandLineRunner; import org.springframework.stereotype.Component; import javax.annotation.PostConstruct; /** * netty 服务启动类 */ @Component @Slf4j public class NettyServer implements CommandLineRunner { private static NettyServer nettyServer; @PostConstruct public void init() { nettyServer = this; } @Value("${netty.port}") private int port; private EventLoopGroup mainGroup; private EventLoopGroup subGroup; private ServerBootstrap server; private ChannelFuture future; public NettyServer() { // NIO线程组,用于处理网络事件 mainGroup = new NioEventLoopGroup(); subGroup = new NioEventLoopGroup(); // 服务初始化工具,封装初始化服务的复杂代码 server = new ServerBootstrap(); server.group(mainGroup, subGroup) .option(ChannelOption.SO_BACKLOG, 128)// 设置缓存 .childOption(ChannelOption.SO_KEEPALIVE, true) .channel(NioServerSocketChannel.class)// 指定使用NioServerSocketChannel产生一个Channel用来接收连接 .childHandler(new NettyServerHandler());//具体处理网络IO事件 } public void start() { // 启动服务端,绑定端口 this.future = server.bind(nettyServer.port); log.info("Netty Server 启动完毕!!!! 端口:" + nettyServer.port); } @Override public void run(String... args) { this.start(); } }第二步:编写NettyServerHandler处理类 package com.itheima.pinda.service; import com.alibaba.fastjson.JSON; import com.itheima.pinda.entity.LocationEntity; import io.netty.buffer.ByteBuf; import io.netty.buffer.Unpooled; import io.netty.channel.ChannelFutureListener; import io.netty.channel.ChannelHandler; import io.netty.channel.ChannelHandlerContext; import io.netty.channel.ChannelInboundHandlerAdapter; import io.netty.util.ReferenceCountUtil; import lombok.extern.slf4j.Slf4j; import org.apache.commons.lang.StringUtils; import java.io.UnsupportedEncodingException; /** * netty 业务处理 */ @Slf4j @ChannelHandler.Sharable public class NettyServerHandler extends ChannelInboundHandlerAdapter { @Override public void channelRead(ChannelHandlerContext ctx, Object msg) { log.info("ServerHandler.channelRead()"); ByteBuf in = (ByteBuf) msg; try { //接收报文 String body = getRequestBody(in); log.info("报文内容:{}", body); //解析报文 String message = parseMessage(body); if (StringUtils.isBlank(message)) { log.info("报文解析失败"); return; } //发送至kafka队列 KafkaSender.send(KafkaSender.MSG_TOPIC, message); } catch (Exception e) { log.error(e.getMessage()); } finally { //使用完ByteBuf之后,需要主动去释放资源,否则,资源一直在内存中加载,容易造成内存泄漏 ReferenceCountUtil.release(msg); } if (null != in) { //把当前的写指针 writerIndex 恢复到之前保存的 markedWriterIndex值 in.resetWriterIndex(); } } /** * 解析请求内容 * * @param in * @return * @throws UnsupportedEncodingException */ private String getRequestBody(ByteBuf in) throws UnsupportedEncodingException { if (in.readableBytes() |







【本文地址】
今日新闻 |
推荐新闻 |