SparrowRecSys电影推荐系统项目(四)模型评估 |
您所在的位置:网站首页 › 电影评分推荐系统有哪些 › SparrowRecSys电影推荐系统项目(四)模型评估 |
SparrowRecSys电影推荐系统项目(四)模型评估
|
SparrowRecSys电影推荐系统项目(四)模型评估
一、模型评估方法:1.离线评估:Holdout检验、交叉检验、自助法离线Replay:
二、评估指标低阶评估指标1.准确率2.精确率和召回率3.对数损失4.均方根误差
高阶评估指标1.P-R曲线2.ROC曲线3.平均精度均值(mAP)
三、线上测试-ABTestA/B Test内容A/B Test测试评估指标
一、模型评估方法:
1.离线评估:
定义:在将模型部署到线上环境之前,在离线环境下进行的评估。 Holdout检验、交叉检验、自助法Holdout检验:将样本集随机划分为训练集和测试集,比如将样本集70%作为训练集,30%作为测试集。优点:简单使用。缺点:划分训练集和测试机具有随机性,导致评价结果也具有随机性。 交叉检验:将所有样本划分为k个大小相等的样本子集,依次遍历k个子集将当前遍历到的子集作为测试集,将其他k-1子集作为训练集,依次进行k次模型的训练和评估,最后将k次模型的的得分取平均值。优点:解决了Holdout检验随机性导致评估结果具有波动性。缺点:和Holdout检验一样适合样本规模较大的情况,样本规模较小则影响模型的训练效果。 自助法:对于总数为n的样本集合,进行n次有放回的采样,得到大小为n的训练集,在n次采样过程中有样本会被重复采样,有样本没有被抽到过,没有抽到的样本就被作为测试集。优点:扩充了小样本数据集的规模。缺点:改变了数据集原有的分布,可能让模型产生一定的偏差。 时间切割: 未来信息:在t时刻进行预测,t+1时刻就是未来信息 时间切割:按照某个时间点进行分割,时间点之前作为训练集,时间点之后作为测试集。在代码中可以使用where语句进行划分,大于某个时间戳在前,小于某个时间戳在后。 离线Replay:时间切割避免了“信息穿越”,但是整个评估过程是静态的,比如用25天的数据作为训练集,5天后的数据作为测试集。如果生产环境模型是日更新的,5天后的评测过程就不准确,并没有在后5天的评测过程中做到日更模型。
精确率指的是分类正确的正样本个数占分类器判定为正样本个数的比例 召回率指的是分类正确的正样本个数占真正的正样本个数的比例 推荐系统中不是通过阈值将预测样本看作为正样本和负样本,而是采用Top N排序结果的精确率和召回率衡量性能,具体来说就是将推荐的N个结果判定为模型的正样本,再去计算N个结果的精确率和召回率。 精确率和召回率是矛盾统一的指标,F1-score可以综合反映精确率和召回率的高低呢? 二分类: 多分类: 准确率、精确率、召回率、logloss都是针对分类模型指定的指标。分类模型就是指预测某个样本属于哪个类别的模型,比如点击率预估模型。除此之外还有回归模型即预测一个连续值,比如预测某个用户对某个电影打多少分。 回归模型评估指标:RMSE
P-R曲线上的点代表“在某一阈值下,模型将大于该阈值的结果判定为正样本,将小于该阈值的结果判定为负样本”,一个点的召回率和精确率不能全面衡量模型性能,只有通过P-R曲线整体表现,才能对模型进行全面评估。 P-R曲线是一条曲线,没有数字直观,很难衡量模型的好坏,因此有了AUC指标衡量模型效果。AUC指的是P-R曲线下的面积大小,计算AUC值只需要沿着P-R曲线做切分。 2.ROC曲线ROC曲线横坐标为FPR(False Positive Rate,假阳性率),纵坐标是TPR(True Positive Rate,真阳性率): 和PR曲线一样,ROC曲线也是通过不断移动模型正样本阈值生成的。ROC曲线同样也可以计算AUC,AUC越高推荐模型效果越好。 3.平均精度均值(mAP)mAP不仅在推荐领域常用,在信息检索领域也非常常用,mAP是对平均精度(AP)的再次平均, 假设推荐系统对某一用户测试集排序结果是1,0,0,1,1,1,其中1代表为正样本,0代表为负样本。在计算平均精度AP时候,只对正样本precision进行平均,得到AP=(1/1+2/4+3/5+4/6)=0.6917。 首先离线测试无法还原线上的所有变量,比如视频网站的用户观看时长,新闻网站的用户留存率等等这些在离线环境下都是难以完成的。 线上ABTest测试都是验证新模型、新功能、新产品的测试方法,在前端、推荐、后端领域均有应用。 A/B测试将用户分为对照组和实验组,给实验组用户用于新模型,给对照组用户旧模型,经过一定时间测试后计算实验组和对照组各项线上评估指标。 A/B测试的优势:离线评估无法还原线上工程环境。比如数据丢失、线上环境延迟、标签数据丢失。线上系统商业指标在离线评估中无法计算,比如用户点击率、留存时长、PV访问量(网站访问量)。离线评估无法完全消除数据有偏现象影响。数据有偏:因为离线数据都是系统利用当前算法生成的数据,因此这些数据本身就不是完全客观中立的,它是用户在当前模型下的反馈。所以说,用户本身有可能已经被当前的模型“带跑偏了”,你再用这些有偏的数据来衡量你的新模型,得到的结果就可能不客观。 A/B Test内容A/B Test分桶原则需要注意样本独立性、分桶过程无偏性。 独立性:同一个用户在测试过程中只能被分到同一个桶中。无偏性:分桶过程中用户被分到哪个实验桶应该是随机的过程。 分桶:我们把用户 ID 是奇数的用户分到对照组,把用户 ID 是偶数的用户分到实验组,这个策略只有在用户 ID 完全是随机生成的前提下才能说是无偏的,如果用户 ID 的奇偶分布不均,我们就无法保证分桶过程的无偏性。所以在实践的时候,我们经常会使用一些比较复杂的 Hash 函数,让用户 ID 尽量随机地映射到不同的桶中。 分层:层与层之间流量正交,同层之间流量互斥。 正交理解·:层与层之间独立实验流量是正交的,一批实验流量穿越每层实验后都会再次随机打散用于下一层实验 X层先被分为X1或X2两部分,X层做完实验后,流量会被随机且均匀的被分到Y层的Y1和Y2。 互斥理解:同层之间进行多组A/BTest测试,不同测试之间流量不可以重叠一组A/B Test测试中实验组和对照组流量不重叠 在推荐系统中基于用户A/BTest测试中,用户体验性很重要,不能让同一个用户在不同实验组之间来回跳跃,严重影响用户的实际体验,因此再A/B Test测试中保证同一用户始终分配到同一个组是非常有必要的。
A/B Test测试评估指标 X层先被分为X1或X2两部分,X层做完实验后,流量会被随机且均匀的被分到Y层的Y1和Y2。 互斥理解:同层之间进行多组A/BTest测试,不同测试之间流量不可以重叠一组A/B Test测试中实验组和对照组流量不重叠 在推荐系统中基于用户A/BTest测试中,用户体验性很重要,不能让同一个用户在不同实验组之间来回跳跃,严重影响用户的实际体验,因此再A/B Test测试中保证同一用户始终分配到同一个组是非常有必要的。
A/B Test测试评估指标
A/B Test测试应与线上服务核心指标保持一致。 电商类推荐模型、新闻类推荐模型··、视频类推荐模型线上评估指标: 电商类推荐模型:点击率、转化率、客单价(用户平均消费金额)新闻类推荐模型:留存率(x日后还活跃的用户数/x日前的用户个数)、平均停留时长、平均点击个数视频类推荐模型:播放完成率(播放时长/视频时长)、平均播放时长、播放总时长 |
 Replay评估方法根据产生时间对测试样本由早到晚进行排序,再让模型根据样本时间先后进行预测,增量学习更新时间点之前的样本,更新模型后在继续评估更新点之后的样本。
Replay评估方法根据产生时间对测试样本由早到晚进行排序,再让模型根据样本时间先后进行预测,增量学习更新时间点之前的样本,更新模型后在继续评估更新点之后的样本。 正负样本不均衡,比如样本数99%都是正样本,那我全部预测为正样本也可以得到99%的正确率。 推荐模型经常会被看做是点击/不点击问题,在实际场景中我们会生成一个推荐列表,那怎么评估模型预测的推荐列表的效果呢?使用精确率和召回率两个指标。
正负样本不均衡,比如样本数99%都是正样本,那我全部预测为正样本也可以得到99%的正确率。 推荐模型经常会被看做是点击/不点击问题,在实际场景中我们会生成一个推荐列表,那怎么评估模型预测的推荐列表的效果呢?使用精确率和召回率两个指标。
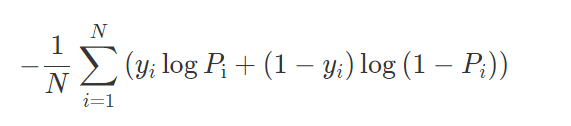
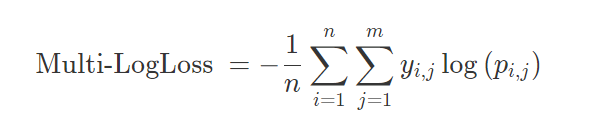 采用logloss可以非常直观感受到模型损失函数的变化
采用logloss可以非常直观感受到模型损失函数的变化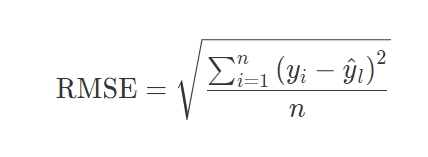 n是样本的个数,真正推荐问题中n的值是变化的,因为用户可能通过不断的翻页、下滑拉去更多的推荐结果。
n是样本的个数,真正推荐问题中n的值是变化的,因为用户可能通过不断的翻页、下滑拉去更多的推荐结果。 纵轴为精确率,横轴为召回率
纵轴为精确率,横轴为召回率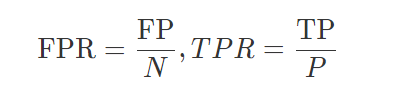 P指的是真实的正样本数量,N是真实的负样本数量,TP指的是P个正样本中被分类器预测为正样本的个数,FP指的是N个负样本中被分类器预测为负样本个数。
P指的是真实的正样本数量,N是真实的负样本数量,TP指的是P个正样本中被分类器预测为正样本的个数,FP指的是N个负样本中被分类器预测为负样本个数。 
 推荐系统对测试集每个用户进行样本排序。每个用户都会得到一个AP值,再对所有用户的AP值进行平均,就得到了mAP,mAP是对精度平均的再次平均。 注:mAP计算方法和P-R曲线、ROC曲线不同,mAP需要对每个用户样本进行分用户排序,而P-R曲线和ROC曲线是对全量样本进行排序。
推荐系统对测试集每个用户进行样本排序。每个用户都会得到一个AP值,再对所有用户的AP值进行平均,就得到了mAP,mAP是对精度平均的再次平均。 注:mAP计算方法和P-R曲线、ROC曲线不同,mAP需要对每个用户样本进行分用户排序,而P-R曲线和ROC曲线是对全量样本进行排序。【本文地址】
今日新闻 |
推荐新闻 |