|
本文作者:是老王吖 原文链接:https://blog.csdn.net/jdkss/article/details/106077755?utm_source=app
1、项目需求
项目需求:这个问题是朋友托我帮完成一份地区教育类型公司的经营范围。 已有信息:表中已经有了公司的名称及地点等信息。 缺省信息:但是还缺少经营范围。 出现的问题:由于数据量比较大,一个一个的去百度搜再复制到表里,工作量有点大,可能需要我好几天不吃不喝的Ctrl c、Ctrl v,这样显然不是个好办法。 解决办法:我们可以利用python从excel中把公司名称都读出来,然后让它自动去网页中,搜索获取该公司的经营范围,并批量回填到excel中。
2、完成步骤
拿到这个问题,我首先想到的是利用selenium自动化测试工具。可以利用该工具,模拟人为操作浏览器,来获取公司的经营范围,并将获取到的数据抓取下来,批量填回到excel中。
1)安装selenium模块和下载chromedriver驱动
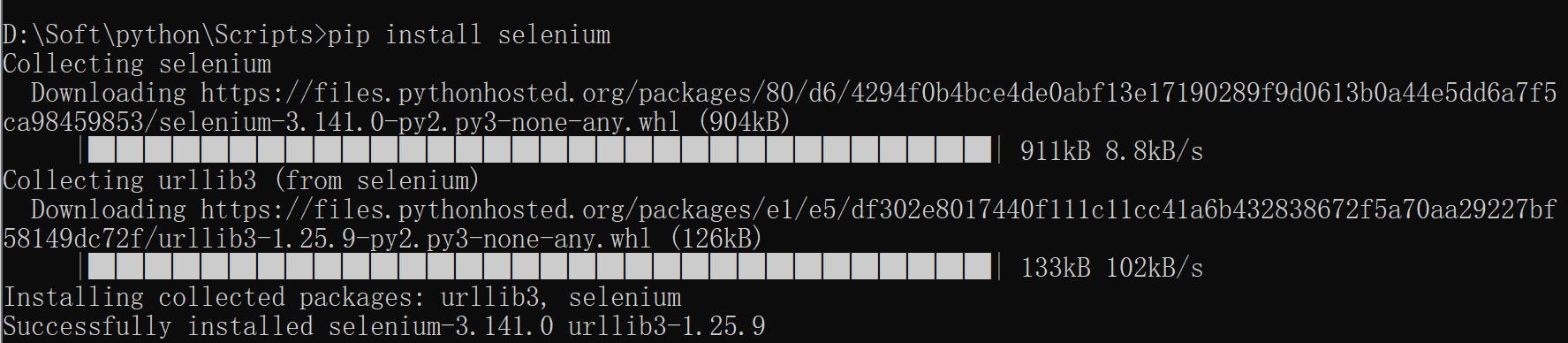
① 安装selenium库
② 下载chromedriver驱动
下载地址:http://chromedriver.storage.googleapis.com/index.html 注意事项一:下载的chromedriver驱动必须和谷歌浏览器相匹配。 注意事项二:下载好的chromedriver.exe文件,需要放到python的安装路径下或者scripts目录下(如图所示)。 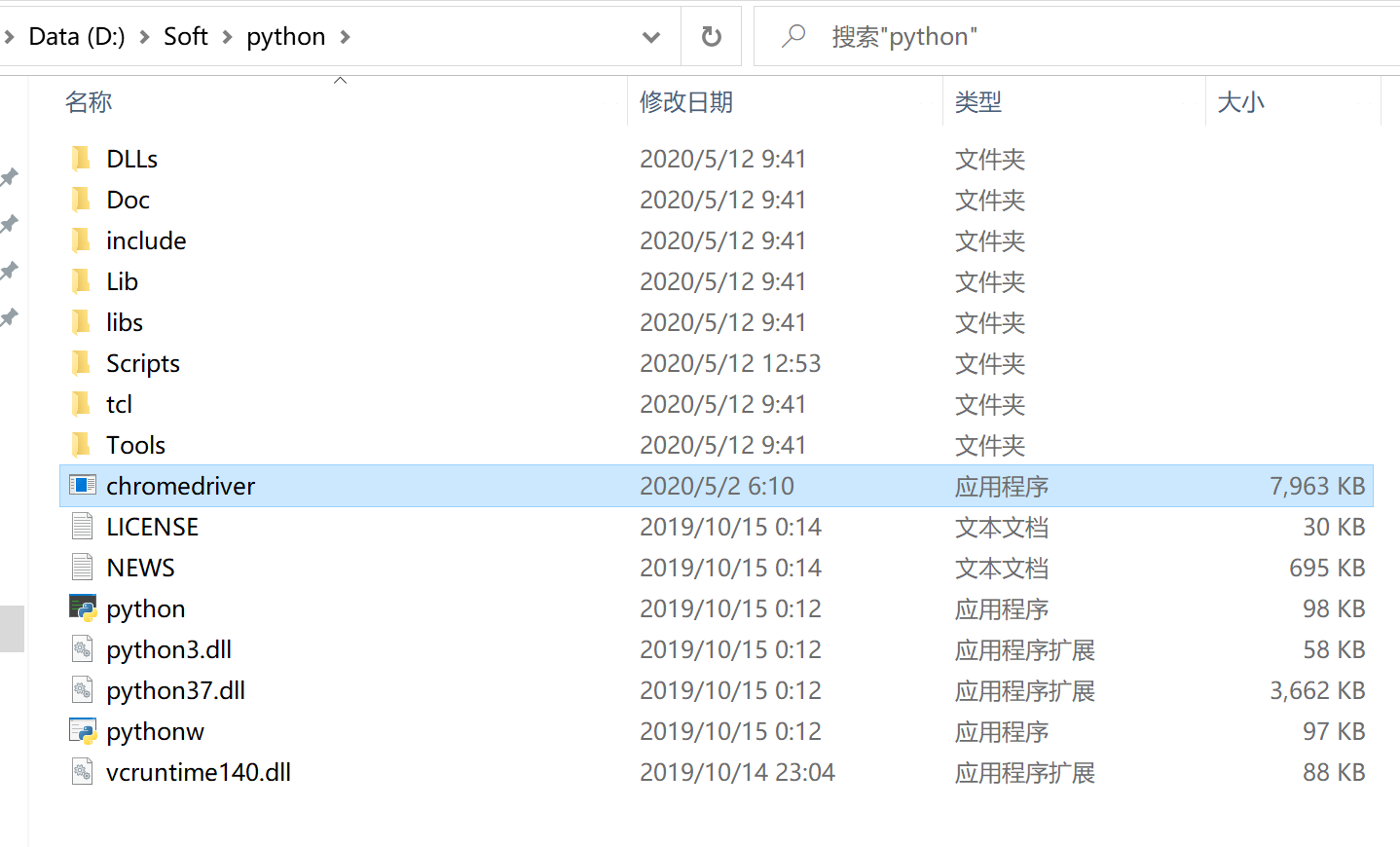 接着,进行一个小的测试。导入webdriver后,我们先利用代码看看是否可以打开浏览器。如果可以正常打开,说明selenium安装配置没有问题。 接着,进行一个小的测试。导入webdriver后,我们先利用代码看看是否可以打开浏览器。如果可以正常打开,说明selenium安装配置没有问题。
from selenium import webdriver
browser = webdriver.Chrome()
首先,在编辑器中输入以下代码。 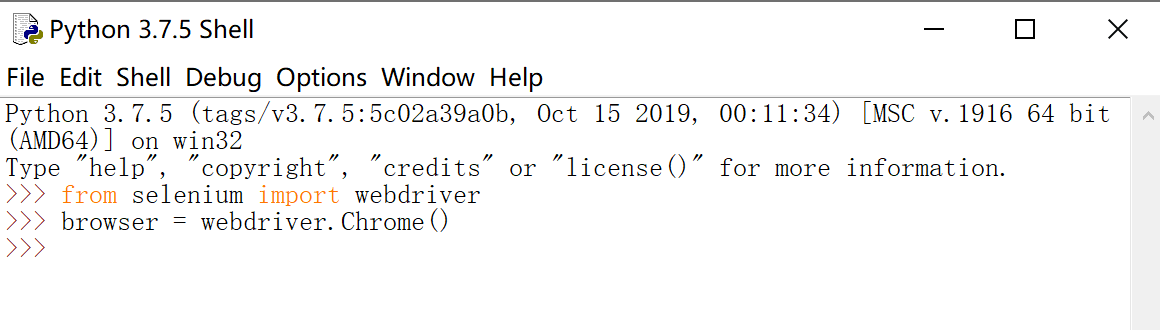 可以看到”谷歌浏览器“被自动打开了。 可以看到”谷歌浏览器“被自动打开了。 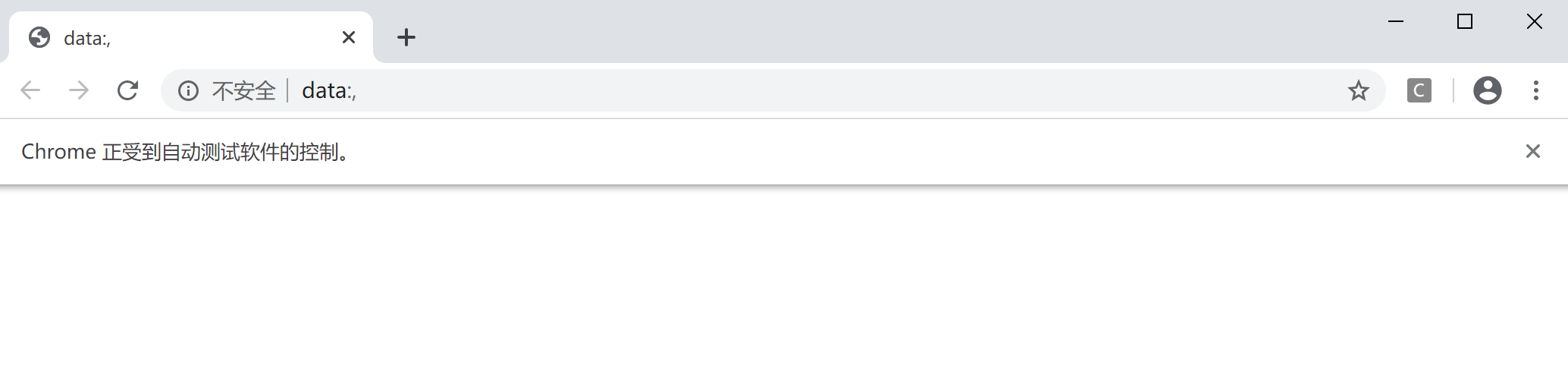 上面只是做了一个小的测试。下面我们以访问”百度“为例,做一个简单的说明。 上面只是做了一个小的测试。下面我们以访问”百度“为例,做一个简单的说明。
from selenium import webdriver
# 打开谷歌浏览器
browser = webdriver.Chrome()
try:
# 获取访问地址www.baidu.com
browser.get("https://www.baidu.com")
# 通过id获取到百度搜索输入框并赋予搜索条件
browser.find_element_by_id('kw').send_keys('python')
# 通过id获取到搜索按钮并赋予点击操作
browser.find_element_by_id('su').click()
except Excception as e:
print("搜索失败:{}".format(e))
可以看到:浏览器被成功打开,同时也打开了”百度“的页面。同时在输入框中自动输入了”python“二字,并成功点击进行了搜索。 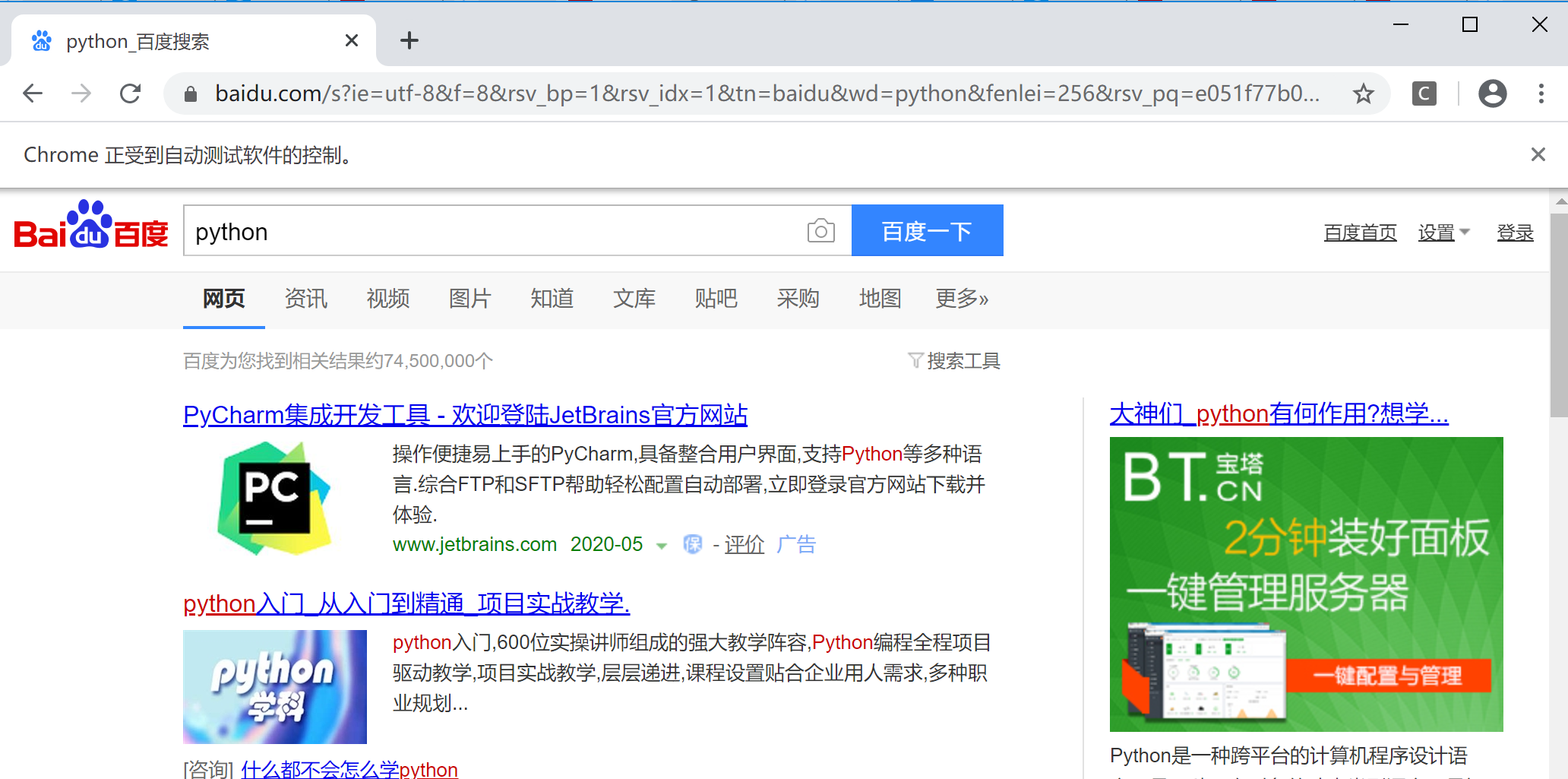
至于怎么定位到百度浏览器输入框和搜索按钮的id,我们可以通过F12查看页面元素来获取 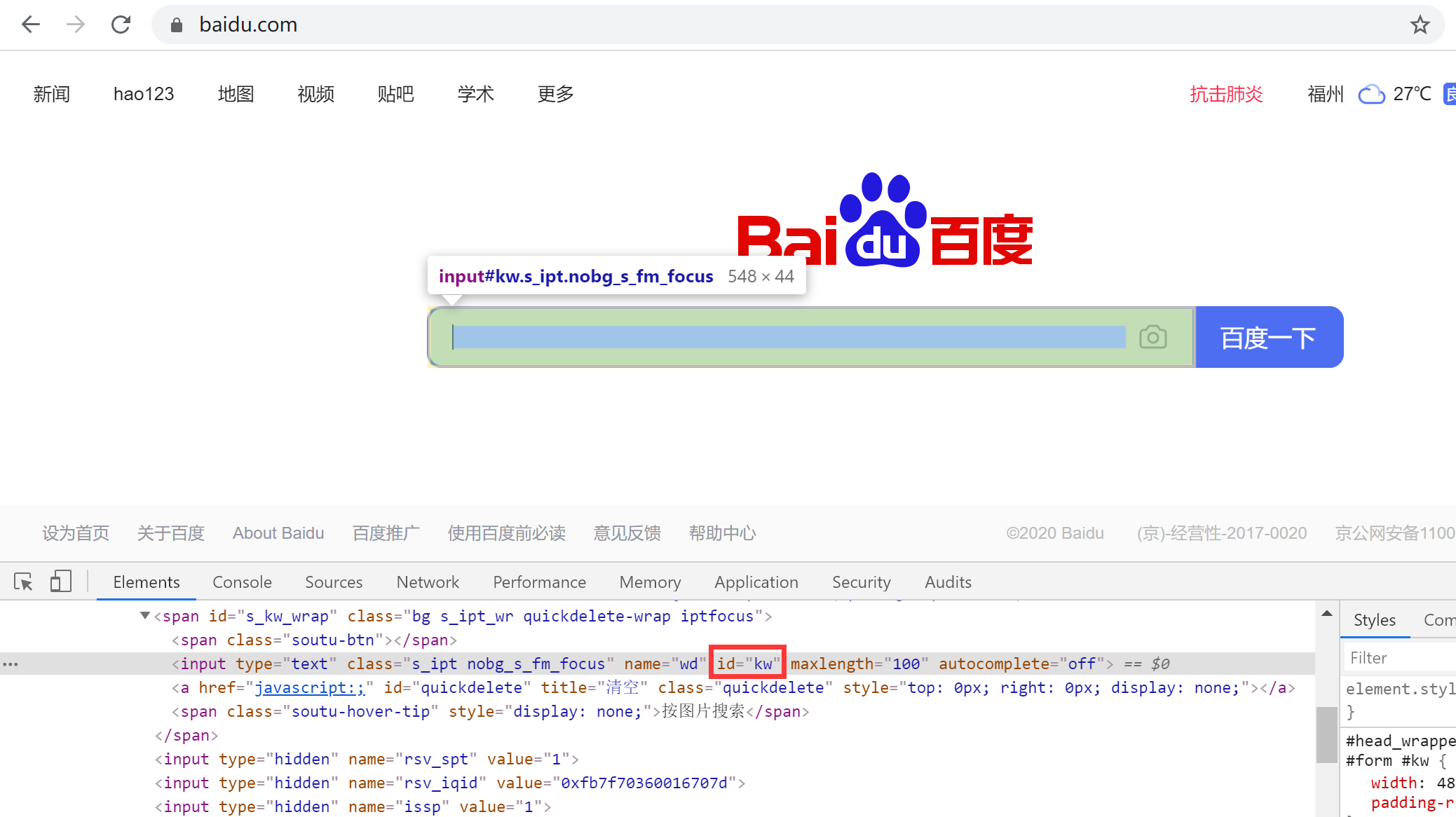 其实,进行界面定位的方式有很多,我们选取自己最喜欢、最熟悉的方式即可。下面我列举了一些定位方法,大家可以自行下去尝试。 其实,进行界面定位的方式有很多,我们选取自己最喜欢、最熟悉的方式即可。下面我列举了一些定位方法,大家可以自行下去尝试。
find_element_by_id
find_element_by_name
find_element_by_xpath
find_element_by_link_text
find_element_by_partial_link_text
find_element_by_tag_name
find_element_by_class_name
find_element_by_css_selector
2)进入主题(分析思路)
好了!基础的搜索步骤已经差不多了,我们来进入正题,公司经营范围一般我们可以去百度信誉去查询,百度信誉的网址: https://xin.baidu.com/
我们看到:这个查询是直接把查询条件拼接在地址后面的一个get请求,这样就说明我们根本就不需要通过模拟浏览器去查询数据了,直接请求这个地址就可以获取到数据了,瞬间工作量少了很多哈哈哈哈,那我们就开始吧。 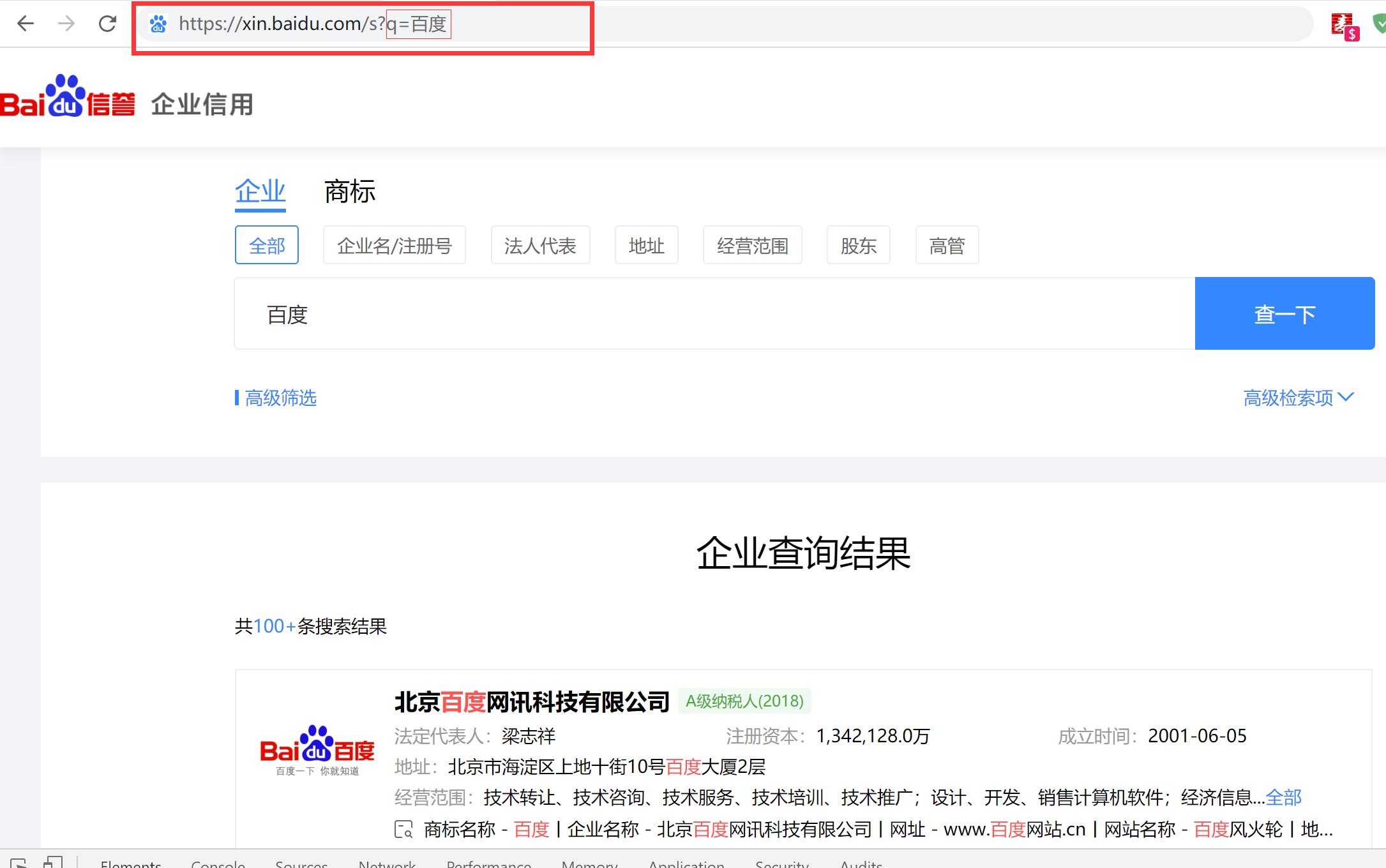 既然直接请求地址获取数据,那我们就解析获取到的数据拿到我们想要的东西就好了,这里我习惯用xpath来解析,感兴趣的也可以用正则等其他方法解析。我需要企业的经营范围信息,那么F12选中经营范围元素,我们要的数据就是这个,右击这个标签选择Copy选项 --> Copy XPath复制这个标签的xpath信息。 既然直接请求地址获取数据,那我们就解析获取到的数据拿到我们想要的东西就好了,这里我习惯用xpath来解析,感兴趣的也可以用正则等其他方法解析。我需要企业的经营范围信息,那么F12选中经营范围元素,我们要的数据就是这个,右击这个标签选择Copy选项 --> Copy XPath复制这个标签的xpath信息。  我们通过xpath去解析页面内容需要先安装一下lxml模块和requests模块 我们通过xpath去解析页面内容需要先安装一下lxml模块和requests模块  获取到xpath=/html/body/div[2]/div/div[2]/div[5]/div[1]/div[1]/div[2]/div/div[1]/span[5]/span[2],然后后面接上text()便可以获取到标签的文本信息了 获取到xpath=/html/body/div[2]/div/div[2]/div[5]/div[1]/div[1]/div[2]/div/div[1]/span[5]/span[2],然后后面接上text()便可以获取到标签的文本信息了
from lxml import etree
import requests
root = etree.HTML(requests.get("https://xin.baidu.com/s?q="+"百度").text)
scope = root.xpath("/html/body/div[2]/div/div[2]/div[5]/div[1]/div[1]/div[2]/div/div[1]/span[5]/span[2]/text()")
print(scope)
获取到的内容如下 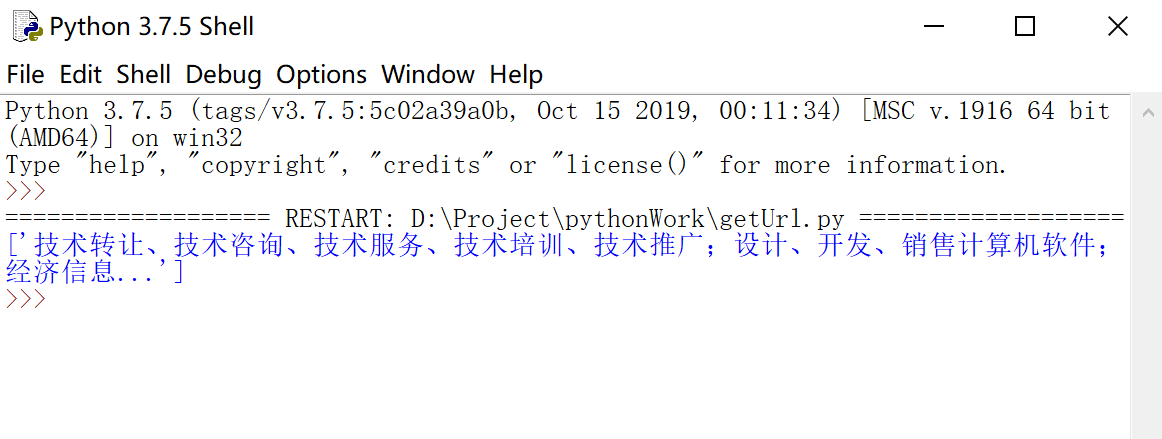 但是我们仔细一看,这里获取到的经营范围是带了省略号的,所以是不完整的,我们再看看页面,发现页面上外面的标签中才是完整的信息,但是此时我们用text()是获取不到的,这个时候得用@来选择属性,获取data-content中的信息 但是我们仔细一看,这里获取到的经营范围是带了省略号的,所以是不完整的,我们再看看页面,发现页面上外面的标签中才是完整的信息,但是此时我们用text()是获取不到的,这个时候得用@来选择属性,获取data-content中的信息 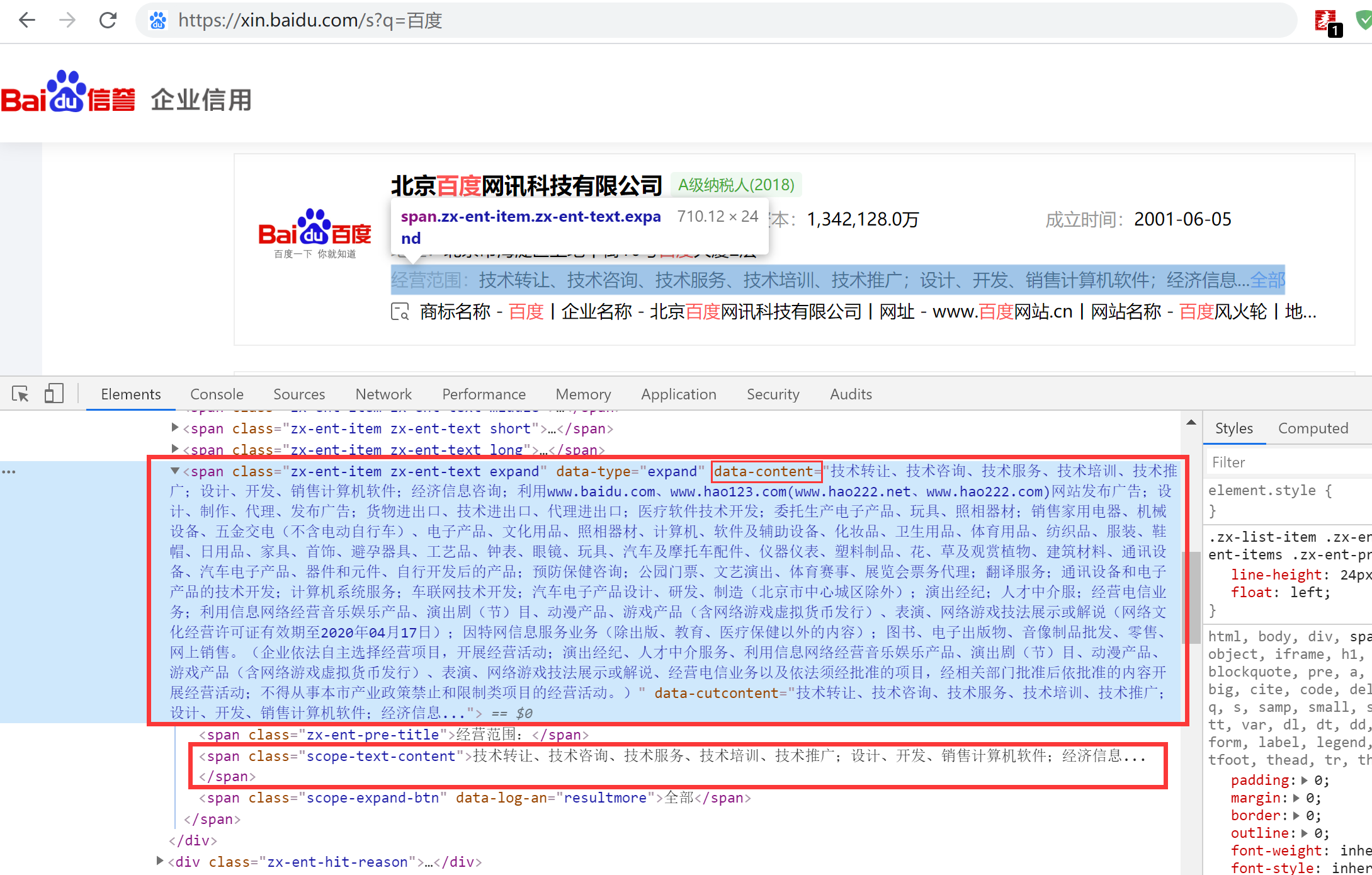 修改后的代码 修改后的代码
from lxml import etree
import requests
root = etree.HTML(requests.get("https://xin.baidu.com/s?q="+"百度").text)
scope = root.xpath("/html/body/div[2]/div/div[2]/div[5]/div[1]/div[1]/div[2]/div/div[1]/span[5]/@data-content")
print(scope)
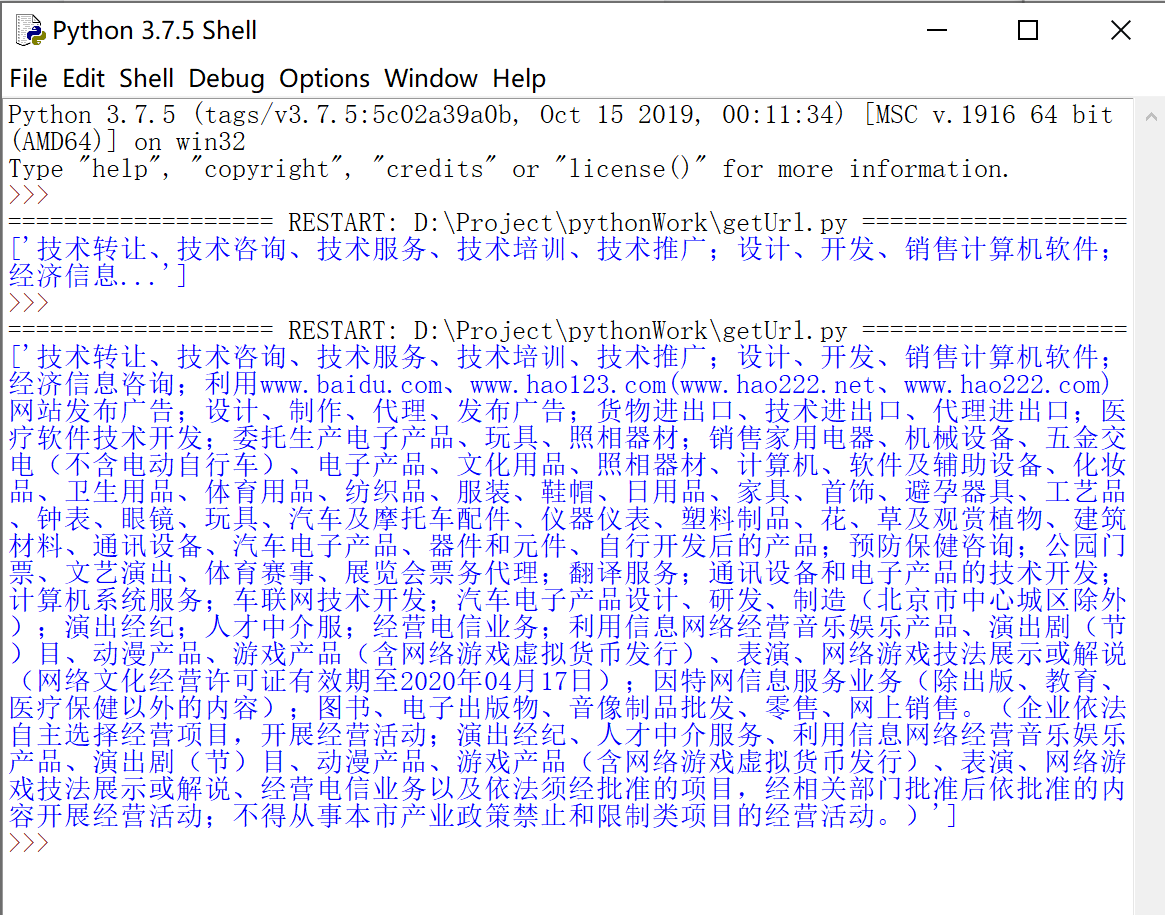 单条数据的获取我们已经可以实现了,接下来我们就可以进行批量操作了,把查询到参数换成可变的从excel中读取的,我们先来实现从excel中读取到数据吧,开干。 单条数据的获取我们已经可以实现了,接下来我们就可以进行批量操作了,把查询到参数换成可变的从excel中读取的,我们先来实现从excel中读取到数据吧,开干。
读取excel我这里用的是xlrd模块,先安装一下  我们把excel表中的数据读出来打印出来看一下,表格信息大致如下 我们把excel表中的数据读出来打印出来看一下,表格信息大致如下 
import xlrd
#读取本地的excel文件
wb = xlrd.open_workbook("教育类.xls",formatting_info=True)
#获取sheet1
sheet = wb.sheet_by_index(0)
#遍历每行数据
for i in range(sheet.nrows):
if(i!=0):
#获取到excel表中的第三列的数据
query = sheet.cell_value(i,2)
print(query)
查询的参数我们也读出来了,下面可以先把这块的代码合二为一,批量获取经营范围数据,这里为了方便我就先不写成独立的方法了,直接放在一起了
import xlrd
from lxml import etree
import requests
import time
#读取本地的excel文件
wb = xlrd.open_workbook("教育类.xls",formatting_info=True)
#获取sheet1
sheet = wb.sheet_by_index(0)
#遍历每行数据
for i in range(sheet.nrows):
if(i!=0):
#获取到excel表中的第三列的数据
query = sheet.cell_value(i,2)
print(query)
root = etree.HTML(requests.get("https://xin.baidu.com/s?q="+query).text)
scope= root.xpath("/html/body/div[2]/div/div[2]/div[5]/div[1]/div[1]/div[2]/div/div[1]/span[5]/@data-content")
data.append(scope[0])
time.sleep(1)
print(data)
data输出是一个数组,存储着excel表中所有公司的经营范围信息 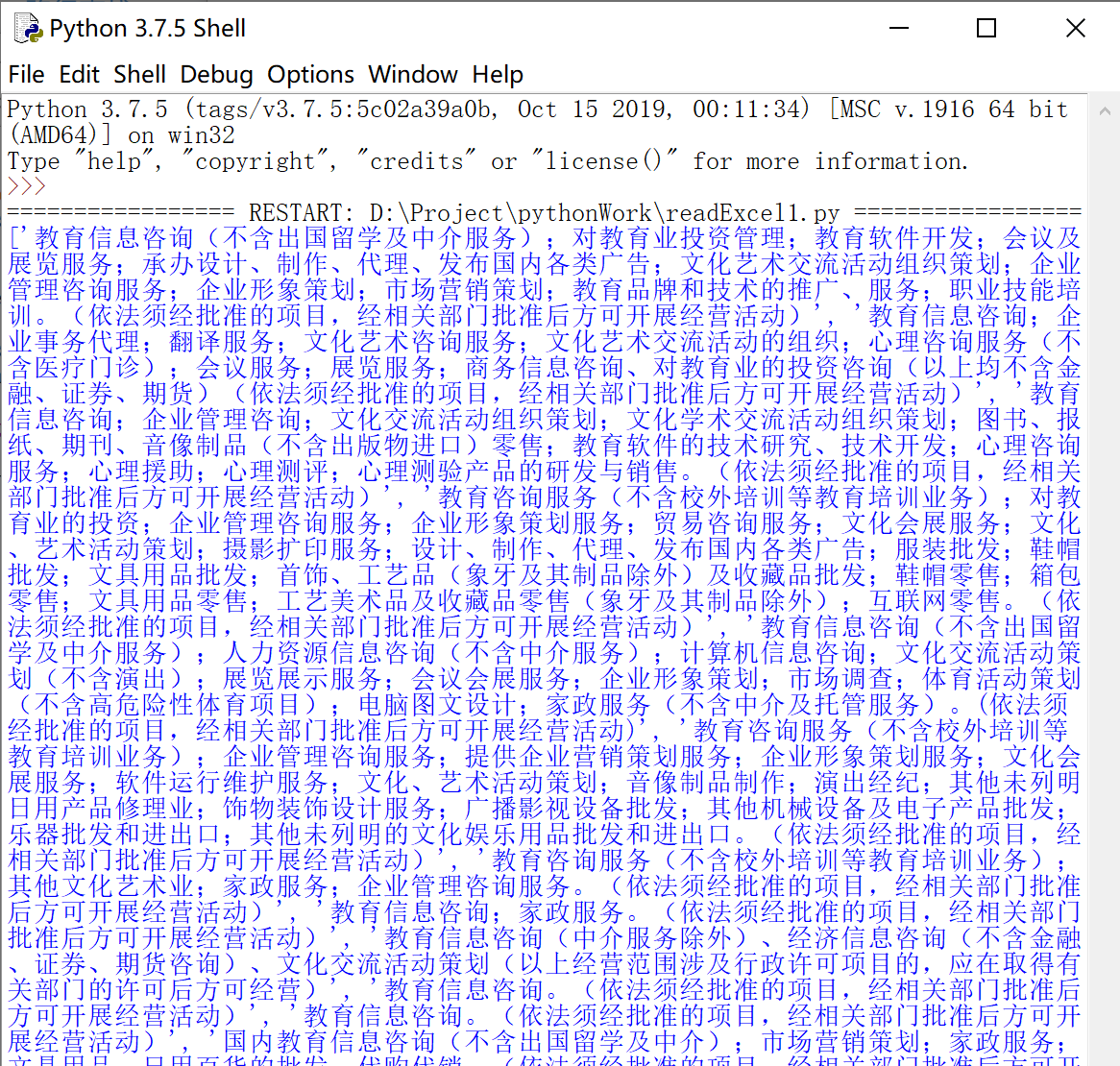 数据有了,接下来我们就把数据写入excel中,把数据完善,首先得安装写excel的xlwt模块。 数据有了,接下来我们就把数据写入excel中,把数据完善,首先得安装写excel的xlwt模块。  我们写入的方法是利用复制一份写入数据再覆盖的方法,所以还得安装xlutils模块使用它的copy方法 我们写入的方法是利用复制一份写入数据再覆盖的方法,所以还得安装xlutils模块使用它的copy方法  完整的代码如下 完整的代码如下
import xlrd
import xlwt
from lxml import etree
import requests
import time
from xlutils.copy import copy
wb = xlrd.open_workbook("教育类.xls",formatting_info=True)
sheets = wb.sheet_names()
sheet = wb.sheet_by_index(0)
data = []
for i in range(sheet.nrows):
if(i!=0):
query = sheet.cell_value(i,2)
root = etree.HTML(requests.get("https://xin.baidu.com/s?q="+query).text)
scope = root.xpath("/html/body/div[2]/div/div[2]/div[5]/div[1]/div[1]/div[2]/div/div[1]/span[5]/@data-content")
data.append(scope[0])
time.sleep(1)
wb = xlrd.open_workbook("教育类.xls",formatting_info=True)
old = copy(wb)
ws = old.get_sheet(0)
for j in range(len(data)):
print(data[j])
print('\n')
ws.write(j+1,7,data[j])
old.save("教育类.xls")
运行结束之后可以发现excel中的经营范围已经有数据了,整个过程就结束了,收工。  代码比较简单随意,主要是一个思路,本人也是个初学者,python只是个闲时爱好,不专业,有不对的地方欢迎大佬们指正,共同进步。 代码比较简单随意,主要是一个思路,本人也是个初学者,python只是个闲时爱好,不专业,有不对的地方欢迎大佬们指正,共同进步。
|