【基于深度学习进行多变量纵向数据和生存数据的动态预测】 |
您所在的位置:网站首页 › 生存分析模型的优势 › 【基于深度学习进行多变量纵向数据和生存数据的动态预测】 |
【基于深度学习进行多变量纵向数据和生存数据的动态预测】
|
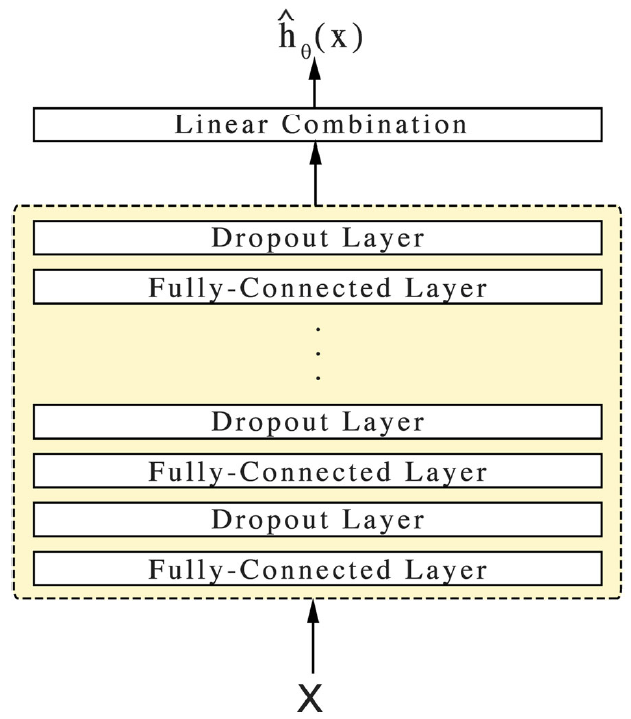
01 【研究背景】 阿尔茨海默病(AD)是一种进行性神经退行性疾病,在疾病的早期阶段准确预测AD的进展对于治疗至关重要。AD患者通常在疾病的整个过程中进行随访,从而重复测量多个纵向变量,将多个纵向变量纳入生存模型将会改善AD预测。 许多现有的预测方法只使用最后可用的观测,忽略了累积纵向信息,具有局限性;适用于纵向和生存数据的联合模型(JM)被用于评估各种纵向生物标志物预测AD的能力,当考虑多个纵向结果,JM涉及大量的随机效应,计算困难。 02 【当前进展和关键科学问题】 目前已经提出了几种使用多个纵向变量对生存数据建模的方案。 (1)MFPCA:MFPCA-Cox是一个两阶段建模框架,它将多元纵向结果视为函数型数据,与多变量JM相比计算速度更快。在MFPCA-Cox第一步中,使用多元函数型主成分分析(MFPCA)提取多个纵向指标的信息特征,将其表示为多元函数型主成分(MFPC)得分。MFPC得分既考虑了多元纵向结果内部的自相关性,也考虑了多个纵向结果之间的相关性。在第二步中,MFPC评分与其他基线变量一起被直接作为时间固定的协变量纳入Cox比例风险模型。类似地,MFPCA-RSF将MFPCA与随机生存森林(RSF)结合使用,在生存数据建模时捕获变量之间更复杂的交互作用。MFPCA还可将纵向信息纳入其他灵活的非参数生存模型,如适用于生存数据的神经网络。多层感知器(一种前馈人工神经网络模型)被用来扩展cox模型以考虑非线性协变量效应。后来,使用激活函数和dropout等现代深度学习技术对多层感知器进行了改进,形成了一个名为DeepSurv的新模型,DeepSurv是一个基于Cox模型的深度前馈神经网络。 (2)MATCH-net(missingness-aware temporal convolutional time-hitting network):感知缺失的时域卷积时间命中网络,它使用卷积神经网络(CNN) 基于多个纵向结果来预测未来生存概率。MATCH-net通过考虑不规则抽样(允许临床随访之间的间隔变化)和异步缺失(在某些随访中可能缺少一些纵向测量)来解决非结构化纵向数据的挑战。结合多个纵向结果,MATCH-net在AD发病建模中实现了较高的预测性能。 (3)transformer是最近为自然语言处理任务设计的神经网络架构。与之前使用循环神经网络(RNN)和CNN的方法相比,它在语言翻译、文本生成和图像识别方面性能改进。此外,transformer已成功应用于电子病历数据,将纵向临床数据用于患者结果分类等任务,并提供一系列疾病的诊断。本研究提出了一种名为TransformerJM的新型变压器架构,用于联合建模多元纵向结果和生存数据。类似原始transformer接收单词序列并将其从一种语言转换为另一种语言,所提出的TransformerJM模型将多元纵向数据序列作为输入,并预测未来纵向结果序列和生存概率。TransformerJM允许个性化预测,可以在新的纵向信息可用时动态更新。为临床医生提供准确的生存预测,有助于他们做出指导性的决定和诊断。 03 【研究目标】 比较先前提出的MFPCA-Cox,MFPCA-DS,MATCH-net等方法和新提出的TransformerJM在进行多变量纵向数据和生存数据动态预测方面的性能。 04 【研究设计和方法】 方法介绍: 1、MFPCA-Cox(见之前的文献解读,不再进行赘述) 参考文献:Li K, Luo S. Dynamic prediction of Alzheimer's disease progression using features of multiple longitudinal outcomes and time-to-event data. Stat Med. 2019 Oct 30;38(24):4804-4818. doi: 10.1002/sim.8334. Epub 2019 Aug 6. PMID: 31386218; PMCID: PMC6800781. 2、MFPCA-DeepSurv 参考文献:Katzman JL, Shaham U, Cloninger A, Bates J, Jiang T, Kluger Y. DeepSurv: personalized treatment recommender system using a Cox proportional hazards deep neural network. BMC Med Res Methodol. 2018 Feb 26;18(1):24. doi: 10.1186/s12874-018-0482-1. PMID: 29482517; PMCID: PMC5828433. DeepSurv是一个基于Cox模型的深度前馈神经网络。在传统的Cox模型中,患者经历事件的对数风险被建模为患者协变量的线性组合。非线性效应,如协变量之间的相互作用,通过专业知识或变量选择添加到模型中。然而,DeepSurv可以在不明确建模的情况下,学习患者协变量与事件风险之间复杂的非线性关系。患者的协变量作为输入传递到网络中,并通过前馈神经网络的一系列隐藏层进行传递。与Cox模型类似,DeepSurv用单个log-hazard值表示每个患者的危险,并假设危险成比例。在存在非比例风险的情况下,Cox和deepsurv模型不适合。 下图展示了DeepSurv的基本组成。网络的输入是患者的基线数据X,通过权重为θ的隐藏层传播输入,网络的隐藏层由完全连接层的非线性激活函数和dropout层组成。最后一层执行隐藏特征的线性组合,网络的输出取生存预测的log-risk函数 。
当用MFPCA方法从纵向数据中提取信息特征时,MFPC得分可以与基线协变量一起作为神经网络的输入传递。DeepSurv是基于Cox部分似然函数的损失函数进行训练的。更具体地说,该模型最小化平均负对数似然函数。
当与MFPCA一起使用时,由纵向结果得出的MFPC评分与基线协变量一起传递到网络中。MFPCA-DeepSurv的架构符合标准前馈神经网络的架构。每个线性层后面都有一个激活函数。本研究使用了修正线性单元(Rectified linear unit,ReLU)是神经网络中最常用的激活函数。其中 。其次是dropout,这是一种正则化技术,在训练过程中,一些节点被随机省略以避免过拟合。最后,归一化重新集中和重新缩放层输出,以允许更快和更稳定的训练。
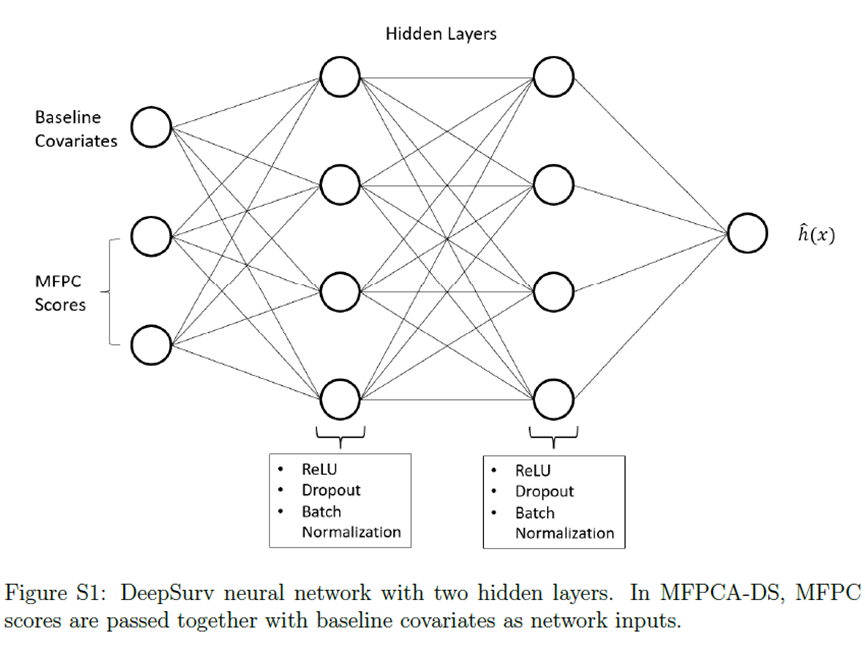
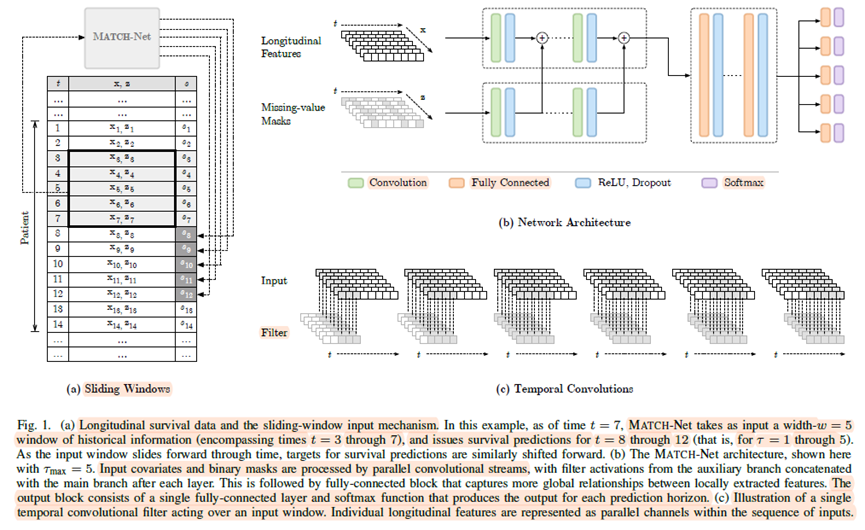
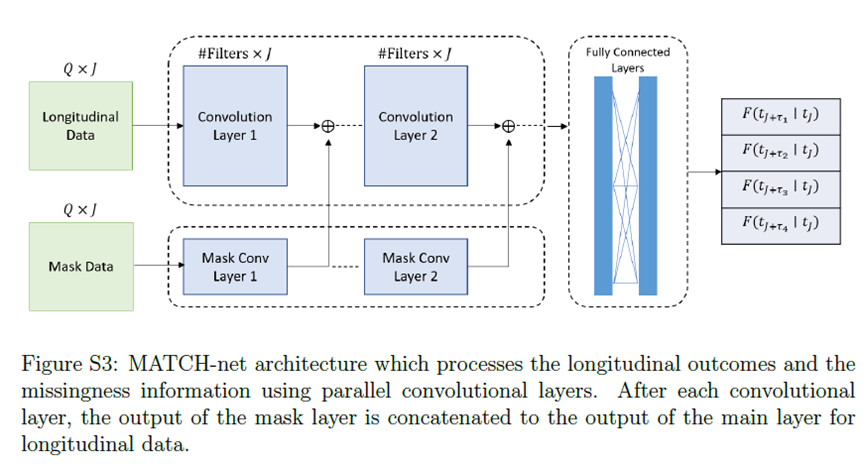
3、MATCH-Net 参考文献:Jarrett D, Yoon J, van der Schaar M. Dynamic Prediction in Clinical Survival Analysis Using Temporal Convolutional Networks. IEEE J Biomed Health Inform. 2020 Feb;24(2):424-436. doi: 10.1109/JBHI.2019.2929264. Epub 2019 Jul 17. PMID: 31331898. Convolutional Neural Network(CNN)被用于时间序列和纵向数据等序列数据的建模。MATCH-net是结合多个纵向结果进行生存预测的CNN。为了适应临床纵向数据的特点,观测数据 首先四舍五入到与建立的网格对应的最接近的时间。缺失值是由最后观测到的测量值推算出来的。这导致输入矩阵 ,其中 是容纳最大观测时间所需的网格长度。MATCH-net模型的可视化如下图所示:纵向数据使用卷积层进行处理。与纵向数据相同大小的缺失掩码表示观测到纵向数据的位置。掩码用它自己的卷积层并行处理,并连接到主卷积层的输出。
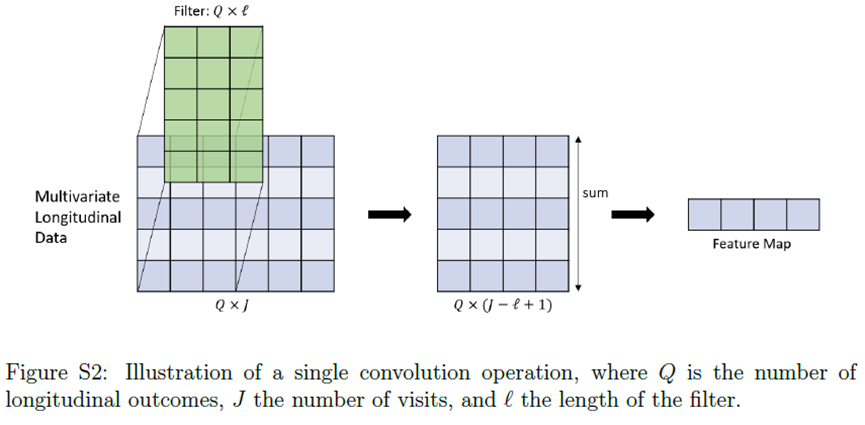
在单变量纵向数据的情况下,卷积运算通常表示为在观测值上滑动一维滤波器。更具体地说,长度为 的单变量纵向结果 与长度为 的滤波器进行卷积,通过计算滤波器沿序列长度传递时的点积,将会得到一个长度为 的新序列。当 是指多个纵向结果的情况时,Q个结果被堆叠在一个叫做深度的新维度上。它们与一组相同长度的 滤波器进行卷积:每个纵向结果对应一个滤波器。应用这组滤波器产生 个序列,然后将它们相加,得到长度为 的单个序列。这个由卷积产生的序列通常被称为特征映射。这些步骤如图S2所示。
在本研究中,纵向数据使用卷积层进行处理,与纵向数据相同大小的缺失掩码表示观测到纵向数据的位置,缺失掩码用它自己的卷积层并行处理,并连接到主卷积层的输出。在每个卷积层和全连接层之后使用ReLU、dropout和批量归一化。最后一个卷积层之后是一个全局平均池化操作,对特征映射的值进行平均。MATCH-net直接预测事件发生的概率,最终输出是一个与感兴趣的连续预测窗口数量长度相同的向量,在最终输出向量上使用一个函数来约束所有预测窗口的事件概率之和为1。 MATCH-net的损失函数为:
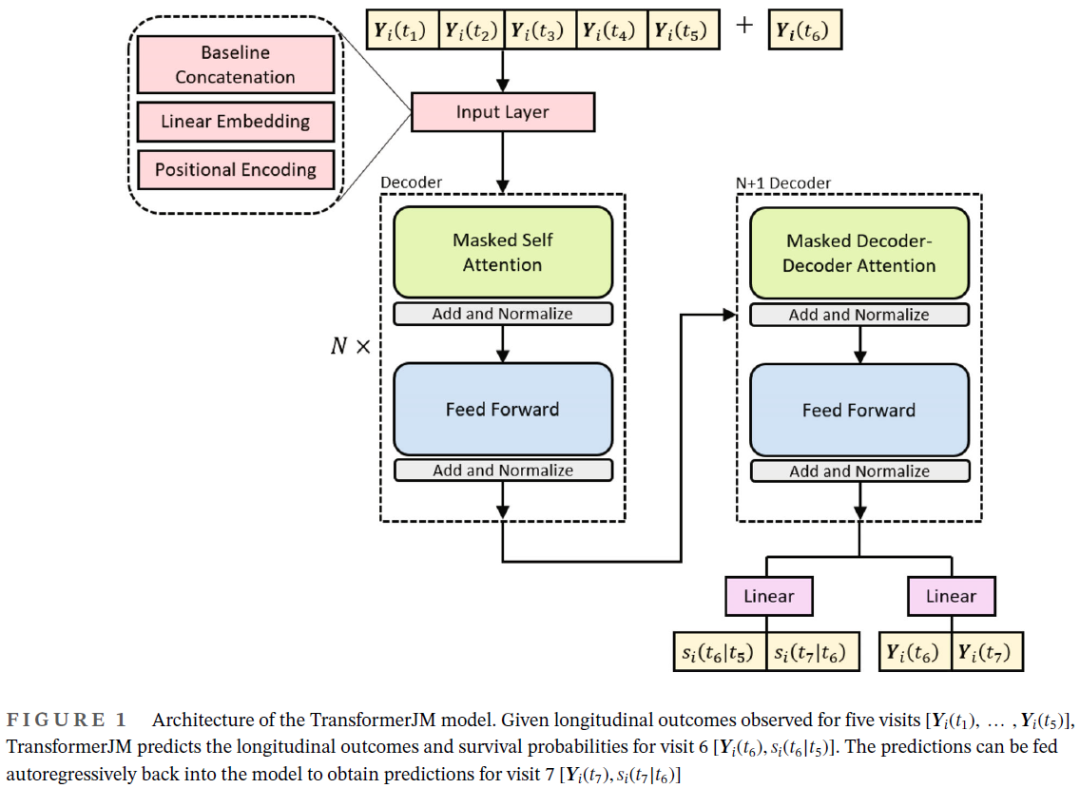
4、TransformerJM transformer是一种神经网络,最初是为翻译等自然语言处理任务开发的。这是一个序列到序列的模型,它提取元素(即句子中的单词)序列并将其转换为另一个序列(翻译后的句子)。在这里,我们提出了一个名为TransformerJM的基于变压器的架构,该架构采用一系列纵向测量并预测未来纵向和生存轨迹的序列。纵向结果数据建模类似于自然语言处理。具体来说,每次随访都是一个包含 个纵向结果的向量,对应于一个单词。一个个体的 次访问可以看作是一个句子。数据由 个个体或若干个句子组成。 transformer的一个关键原则是attention机制。attention是一种功能,它接受一个序列,并将其与第二个序列进行比较,识别具有匹配或相关上下文的区域。当attention被用来比较序列本身时,它被称为self-attention。这允许序列中的每个元素基于相同序列的其他部分来表示。这在自然语言处理中很有用,因为一个词的意思可以在整个句子的上下文中改变或变得更具体。同样地,尽管在同一次随访中可以在两名患者中观察到相同的测量值,但他们的疾病进展可能不相同,应考虑之前的随访和,确定每个患者的整体状况是改善还是下降。通过self-attention,transformer能够了解多次随访之间的依赖关系,并建立更完整的患者病情概况。在对纵向数据进行self-attention时,transformer需要从过去而不是从尚未发生的未来随访中获得信息。从attention计算中去除不恰当的连接被称为Masked Self-attention。 attention可以并行计算多次,以给出数据的几种不同表示形式,这被称为multihead attention。当一个attention head发现随访之间的关系时,multihead attention允许每个attention head关注更微妙的关系。例如,在个体患者的重复测量中,先前的访问可能与当前的访问相关,因为纵向结果的值接近,或者它们可能相关,因为它们发生的时间接近。为模型提供不同的随访相关信息,可以更精确地表示患者的疾病状况。 关于transformer的最后一点说明是它使用了位置编码。attention机制学习所有允许的时间点之间的依赖关系,但是,它没有说明随访发生的实际时间。在每次随访中添加一条表示发生时间的信息可以给transformer添加秩序。虽然位置编码有几种选择,但transformer的常用选择是使用不同频率的正弦和余弦函数来表示时间。 图1概述了TransformerJM的体系结构,并说明了一个 次随访的示例输入序列是如何通过网络传递的。设 为在给定就诊 时表示患者 疾病状态的向量序列。注意 在网络中传递时,其形式会发生变化。输入序列经过几个步骤处理。首先,将基线变量连接到每个 。然后将每个向量通过前馈神经网络来学习 元素之间的相互作用(线性嵌入)。最后,使用位置编码将观测时间与每个 联系起来。此时,每个 仅来自第 次访问期间观察到的数据。例如, 是由基线协变量和第三次随访时观察到的纵向结果导出的向量。
TransformerJM由N+1个解码器块组成,其中N是要选择的超参数。前N个解码器块由两个子层组成:masked multihead self-attention机制和前馈神经网络。self-attention允许每个 结合以前的随访信息来更全面地反映患者的病情,而前馈层进一步集成这些信息。这意味着患者在第三次就诊 时的疾病状态现在考虑了前两次就诊的信息。最后的解码器块输出的仍然是一个向量序列: 。然而,现在每个 都包含了以前的随访信息。请注意, 表示观察到的就诊时患者的病情,但在本例中,我们感兴趣的是预测下一次就诊时患者的状态, 。为了对下一次访问进行预测,将期望预测时间 的位置编码添加到上次访问的向量 中,并传递给final“N+1”解码器块。这个解码器块的不同之处在于它计算预测时间编码向量和 之间的attention,结果是预测 时刻患者状态。这个输出被传递给线性层的两个分支:第一个分支预测 ,即 时刻的 个纵向结果;第二个分支预测 ,即 时刻的条件生存概率。在评估期间,预测的纵向测量被反馈到模型的开始,作为预测未来额外时间点的输入。在本例中,可以将预测值 添加回输入序列以生成预测值 和 。 为了同时预测纵向结果和生存概率,模型训练时联合最小化两个损失函数:纵向损失由均方误差给出,生存损失由负对数似然函数给出。总损失为两个损失函数的和。
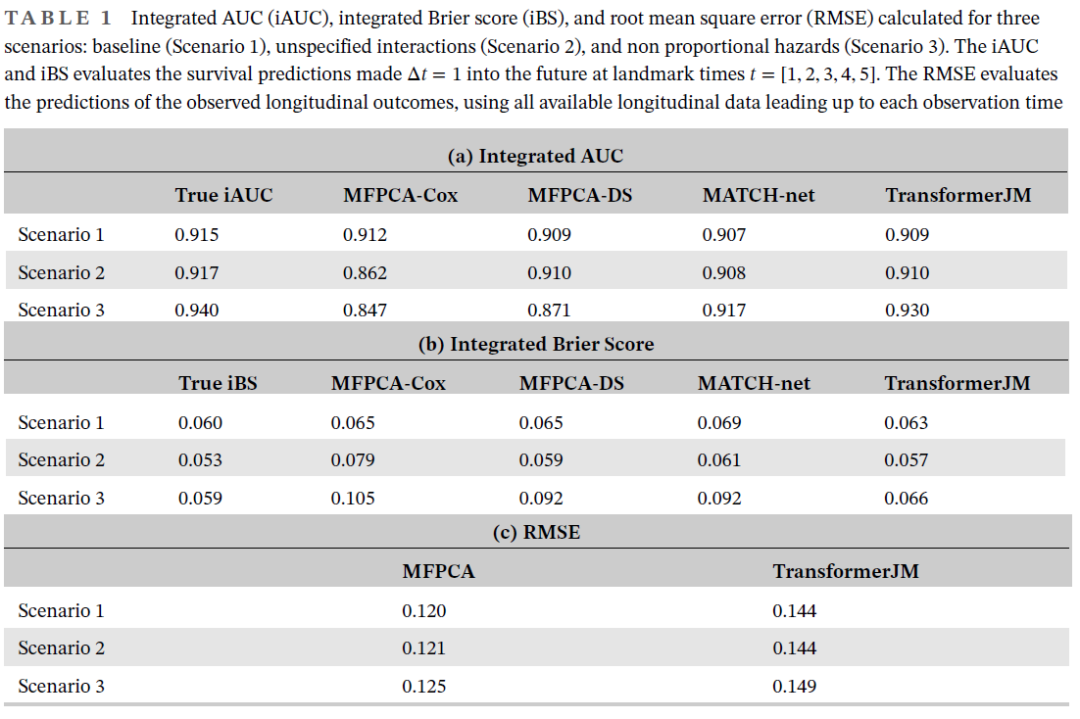
05 【核心结果解读】 一、模拟研究: 场景1:创建100个模拟数据集,每个数据集的样本量为 个受试者。每位受试者有 个基线协变量和 个纵向结果,观察时间 ,最多 次随访,删失率30%。
场景2:为了展示模型错误设定的影响,在创建模拟数据时,在基线协变量中添加了一个交互项。在训练模型时,没有指定交互项作为预测因子,评估模型在不显式输入的情况下捕获交互项效果的能力。
场景3:构建与时间相关的协变量,创建具有非比例风险的模拟情景。
对于每个模拟数据集,随机选择70%的数据进行训练,其余30%的数据用于进行动态预测。本研究在里程碑时间 进行了预测。在每个具有里程碑意义的时间点,对未来进行了 的预测。 在场景1中,MFPCA-Cox表现非常好,因为生存数据是由Cox模型模拟的。然而,其他方法也有很强的性能,AUC和BS接近真实值。在情景2中,在模拟生存数据时添加未指定的交互项,使得MFPCA-Cox的AUC显著下降,BS显著升高,MFPCA-Cox无法隐式地考虑交互项。相比之下,MFPCA-DS,MATCH-net,TransformerJM能够充分解释协变量之间发生的相互作用,这些方法保持了高AUC和低BS值。在情景3中,当比例风险假设不满足时,MFPCA-Cox和MFPCA-DS的AUC和BS与真实值有显著差异。相比之下,TransformerJM在这种情况下表现出色,AUC和BS接近真实值。尽管MATCH-net也考虑了非比例风险,TransformerJM在场景3中表现更好,这可能是由于TransformerJM的自回归方法更适合于预测生存概率序列。相比之下,MATCH-net使用softmax函数输出生存概率序列,常用于多分类问题的输出。 除了生存预测外,使用MFPCA和TransformerJM模型对纵向结果进行了预测,请注意MATCH-net仅预测生存概率,不包括在本次比较中。MFPCA和TransformerJM两种方法都具有较低的RMSE。与TransformerJM相比,MFPCA在三种场景下的RMSE略低。使用MFPCA对纵向结果建模的另一个优点是计算时间,两阶段MFPCA模型完成模拟的速度明显快于其他神经网络方法。
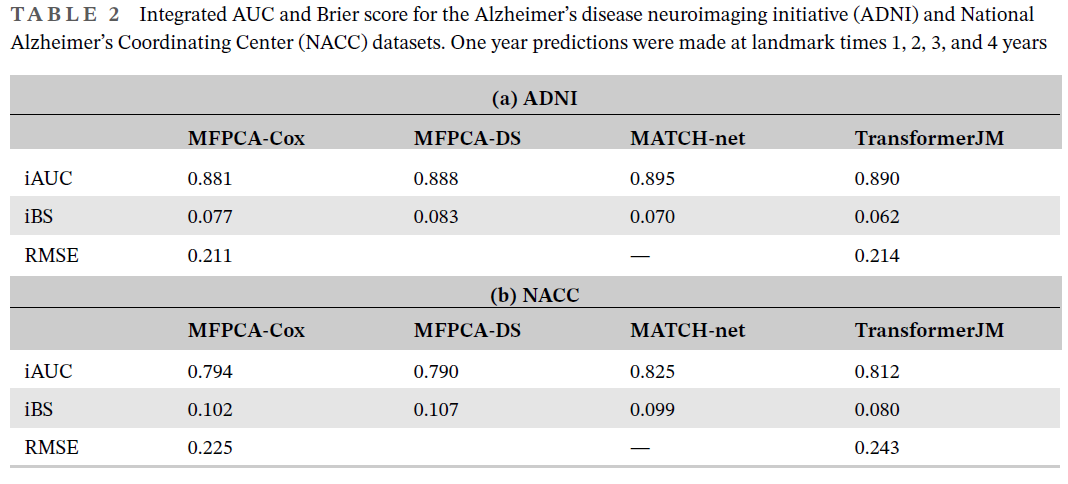
二、实例研究: 1、ADNI: ADNI是一项纵向多中心研究,收集临床、影像学、遗传等生物标志物,以更好地跟踪AD的进展。ADNI目前处于第三阶段,之前的阶段是ADNI 1、Go和2。 研究人群:所有阶段ADNI,包括ADNI 3的基线MCI患者 基线协变量:年龄、性别、受教育年限、载脂蛋白E4 纵向变量:ADAS-Cog13、MMSE、FAQ、CDRSB、RAVLT(即时、学习和遗忘得分)
2、NACC: NACC是由NIA资助的阿尔茨海默病研究中心(ADRC)在美国的集合数据库,每个ADRC通过医生转诊、自我转诊或主动招募的方式招募患者,并根据自己的方案对患者进行诊断。NACC不包含ADNI中出现的所有纵向结果,基于单变量联合模型分析的显著性选择了选择重要的纵向临床评估进行预测模型构建。MMSE、CDRSB、Logical Memory、WAIS-R、the Semantic Verbal Fluency Test、the TrailMaking Test parts A and B, and the Boston Naming Test
MATCH-net和TransformerJM具有较好的性能,AUC高于MFPCA-Cox和MFPCA-DS。MATCH-net的AUC高于TransformerJM,而TransformerJM的BS明显较低,总体性能较好。 ADNI:
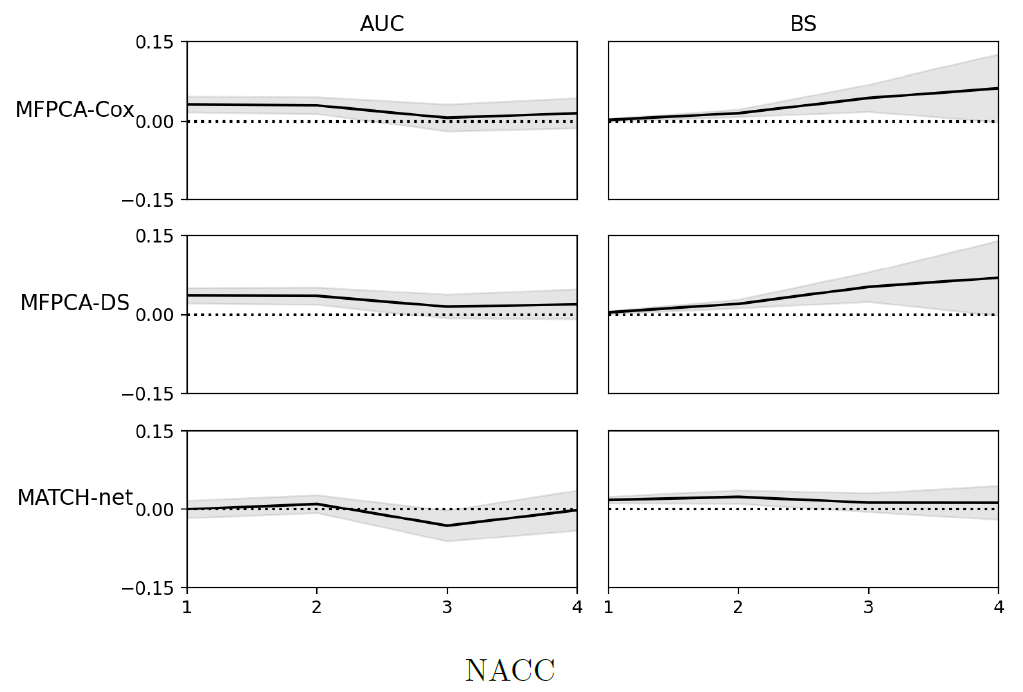
NACC:
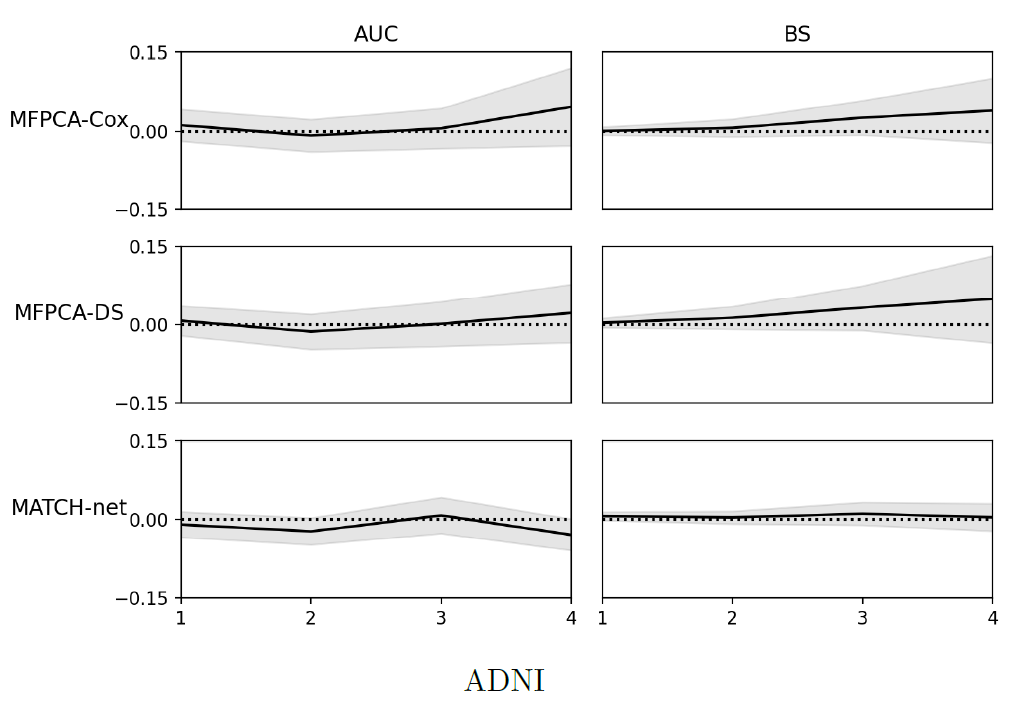
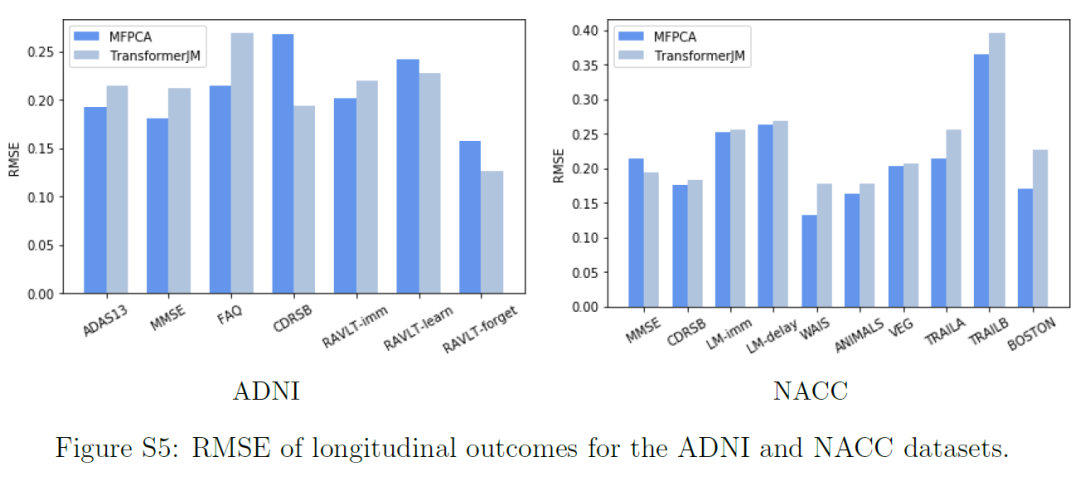
在NACC数据集中,与MFPCA-Cox和MFPCA-DS相比,TransformerJM的AUC或BS在地标时间1、2和3处的差异与零有显著差异。在ADNI数据集中,差异与零没有显著差异。这可能表明,虽然MFPCA-Cox和MFPCA-DS在ADNI数据集上表现良好,但MATCH-net和TransformerJM更适合包含更多异质性的NACC数据集。尽管由于变量和样本量的不同,两个数据集的结果不能直接比较,但NACC数据集的较大异质性也可以解释为什么与ADNI数据集的结果相比,NACC数据集的结果产生了更低的AUC和更高的BS和RMSE。 NACC患者来自更广泛的人群。例如,在ADNI数据集中,94%的患者是白人,不到3%的患者是非裔美国人。相比之下,在NACC数据集中,82%的患者是白人,12%是非裔美国人。先前的研究表明,阿尔茨海默病在非裔美国人社区中患病率更高。虽然NACC数据集的更大异质性增加了预测的难度,但结果更适用于一般人群。 使用MFPCA和TransformerJM对纵向结果进行了预测。RMSE由结果的归一化值计算,以便进行直接比较。TransformerJM的结果与MFPCA设定的基准相当。虽然MFPCA的RMSE似乎略低,但TransformerJM仍然很有竞争力,除了生存概率外,还提供了有效的纵向结果预测。
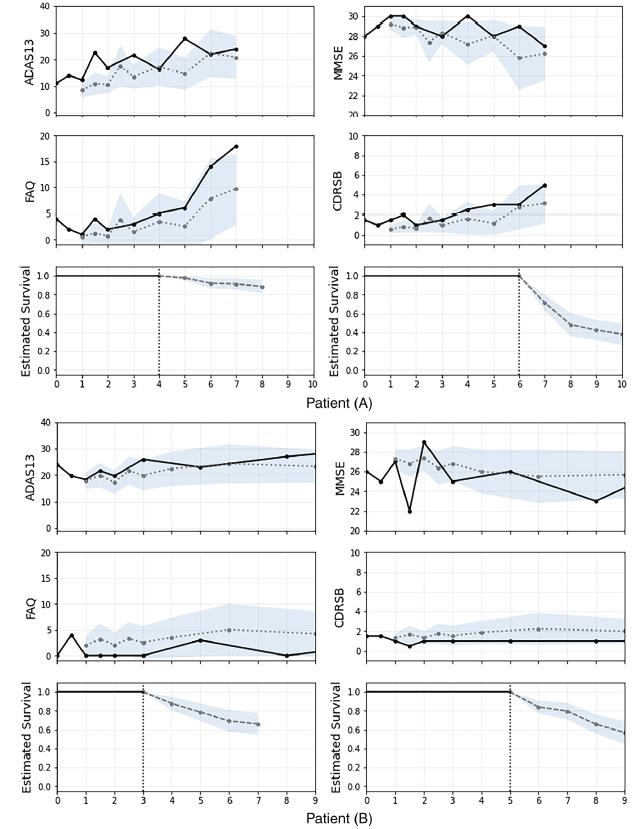
个体化动态预测: 患者A的FAQ和CDRSB测量值逐渐上升,纵向结果的变化反映在生存预测中,估计生存概率在第6年后急剧下降。这与第4年的预测形成了鲜明对比,当时的预测显示患者的病情将保持稳定。患者A最终在第8年被诊断为AD,证实了模型的性能。这个例子展示了该模型如何根据反映患者病情下降的新数据调整其预测。患者B纵向指标保持相对稳定,第3年的生存预测和第5年的生存预测保持相似的风险轨迹。
【总结感悟】 本研究阐述了几种使用多个纵向结果对生存数据建模的方法。MFPCA能够从纵向数据中捕获信息特征,这些特征可以直接作为协变量用于后续Cox模型和DeepSurv神经网络作进行生存建模。MATCH-net是一种使用卷积层来解释多个纵向结果的神经网络。本研究提出了一种新的变压器神经网络,命名为TransformerJM,以联合建模纵向和生存数据。模拟研究和实例应用显示上述模型都具有一定的应用价值。 首先,在模拟研究和真实数据分析中,TransformerJM展示了与其他方法相匹配或更好的预测性能。模拟研究表明,在传统Cox模型无法处理的协变量非线性组合和非比例风险两种情况下,TransformerJM具有更好的性能。即使这两个问题不存在,TransformerJM的AUC和BS接近真实值。在处理真实数据时,TransformerJM的这种优势尤其明显,因为实际应用时很难确定应该包括哪些特定的交互项,或者存在多大程度的非比例危险。与之前的动态预测模型相同,TransformerJM允许在随访获得新的标志物测量值时更新预测。 TransformerJM可以处理不规则的观察时间(连续访问之间的时间间隔可能不同),但它要求每次访问都要观察所有纵向结果,即TransformerJM无法处理异步缺失(在某些访问中可能会丢失某些纵向测量)。这一要求在使用临床评估进行真实数据分析时不会造成大问题,因为所有相关的临床评估通常都是在同一次访问中进行的。然而,当考虑多个数据来源时,这个局限性就比较明显,例如同时使用不同的访问中收集的临床评估和MRI数据训练模型。在这种情况下,我们建议使用MFPCA或MATCH-net的卷积双流架构来处理纵向数据中的异步缺失。 MFPCA和TransformerJM均可用于获得纵向结果的未来轨迹预测,而MATCH-net仅用于预测生存概率。在结果中,MFPCA和TransformerJM都能够预测低MSE的纵向结果。虽然MFPCA的MSE略低于TransformerJM,但当除生存概率外,还需要预测纵向结果的未来轨迹时,这两种方法都是合适的选择。实际应用时考虑计算需求和数据大小。与神经网络模型相比,MFPCA模型的构建计算速度更快。MATCH-net和TransformerJM的训练时间大约是MFPCA-Cox或MFPCA-DS的10倍。另一方面,MFPCA要求计算机有足够的内存,这对于许多大规模数据集来说是不可行的,而MATCH-net和TransformerJM是批量处理数据的,不需要在训练时一次性加载所有数据。 未来的重要工作是提高这些模型的可解释性和可视化。由于模型能够纳入多个纵向结果,因此有必要了解哪些变量的影响更大,以及它们如何对预测作出贡献。虽然MFPCA和神经网络方法可以将纵向结果编码为信息特征,但评估每个纵向结果在特征中的贡献目前仍具有挑战性,需要进一步研究。 |
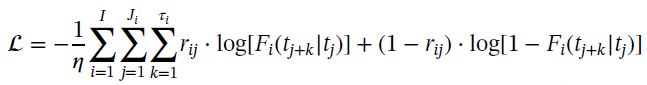
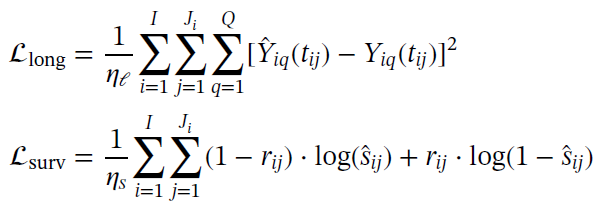
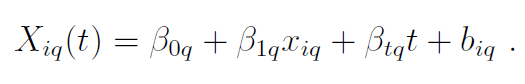
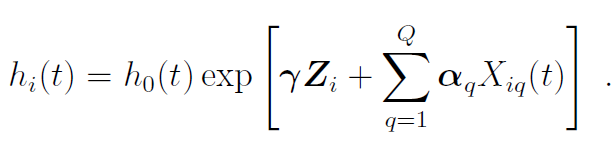
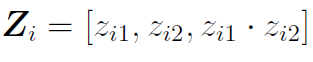
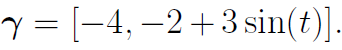
【本文地址】
今日新闻 |
推荐新闻 |