Spark 分区(Partition)的认识、理解和应用法 |
您所在的位置:网站首页 › 现金有几种概念是什么 › Spark 分区(Partition)的认识、理解和应用法 |
Spark 分区(Partition)的认识、理解和应用法
|
Spark 分区(Partition)的认识、理解和应用 一、什么是分区以及为什么要分区? Spark RDD 是一种分布式的数据集,由于数据量很大,因此要它被切分并存储在各个结点的分区当中。从而当我们对RDD进行操作时,实际上是对每个分区中的数据并行操作。
分区方式的优劣 HashPartitioner分区弊端: 可能导致每个分区中数据量的不均匀,极端情况下会导致某些分区拥有RDD的全部数据(HashCode为负数时,为了避免小于0,spark做了以下处理)。 /* Calculates ‘x’ modulo ‘mod’, takes to consideration sign of x, i.e. if ‘x’ is negative, than ‘x’ % ‘mod’ is negative tooso function return (x % mod) + mod in that case. */ def nonNegativeMod(x: Int, mod: Int): Int = { val rawMod = x % mod rawMod + (if (rawMod < 0) mod else 0) }RangePartitioner分区优势: 尽量保证每个分区中数据量的均匀,而且分区与分区之间是有序的,一个分区中的元素肯定都是比另一个分区内的元素小或者大;但是分区内的元素是不能保证顺序的。简单的说就是将一定范围内的数映射到某一个分区内。 1、HashPartitioner /** Choose a partitioner to use for a cogroup-like operation between a number of RDDs. *--------------------------------------------------------------------------------------------------------------------If any of the RDDs already has a partitioner, choose that one. *---------------------------------------------------------------------------------------------------------------------Otherwise, we use a default HashPartitioner. For the number of partitions, ifspark.default.parallelism is set, then we’ll use the value from SparkContextdefaultParallelism, otherwise we’ll use the max number of upstream partitions.Unless spark.default.parallelism is set, the number of partitions will be thesame as the number of partitions in the largest upstream RDD, as this shouldbe least likely to cause out-of-memory errors. *-----------------------------------------------------------------------------------------------------------------------We use two method parameters (rdd, others) to enforce callers passing at least 1 RDD. / def defaultPartitioner(rdd: RDD[], others: RDD[]): Partitioner = { val bySize = (Seq(rdd) ++ others).sortBy(_.partitions.size).reverse for (r 0) { return r.partitioner.get } if (rdd.context.conf.contains(“spark.default.parallelism”)) { new HashPartitioner(rdd.context.defaultParallelism) } else { new HashPartitioner(bySize.head.partitions.size) } }HashPartitioner确定分区的方式:partition = key.hashCode () % numPartitions HashPartitioner分区的原理: 对于给定的key,计算其hashCode,并除于分区的个数取余,如果余数小于0,则用余数+分区的个数,最后返回的值就是这个key所属的分区ID。实现如下: /** A [[org.apache.spark.Partitioner]] that implements hash-based partitioning usingJava’s Object.hashCode.Java arrays have hashCodes that are based on the arrays’ identities rather than their contents,so attempting to partition an RDD[Array[]] or RDD[(Array[], _)] using a HashPartitioner willproduce an unexpected or incorrect result. */ class HashPartitioner(partitions: Int) extends Partitioner { require(partitions >= 0, s"Number of partitions ($partitions) cannot be negative.")def numPartitions: Int = partitions def getPartition(key: Any): Int = key match { case null => 0 case _ => Utils.nonNegativeMod(key.hashCode, numPartitions) } override def equals(other: Any): Boolean = other match { case h: HashPartitioner => h.numPartitions == numPartitions case _ => false } override def hashCode: Int = numPartitions } 2、RangePartitioner RangePartitioner会对key值进行排序。 RangePartitioner作用:将一定范围内的数映射到某一个分区内,在实现中,分界的算法尤为重要。算法对应的函数是rangeBounds。 代码如下: /** A [[org.apache.spark.Partitioner]] that partitions sortable records by range into roughlyequal ranges. The ranges are determined by sampling the content of the RDD passed in.Note that the actual number of partitions created by the RangePartitioner might not be the sameas the partitions parameter, in the case where the number of sampled records is less thanthe value of partitions. */ class RangePartitioner[K : Ordering : ClassTag, V]( partitions: Int, rdd: RDD[_ = 0, s"Number of partitions cannot be negative but found $partitions.")private var ordering = implicitly[Ordering[K]] // An array of upper bounds for the first (partitions - 1) partitions private var rangeBounds: Array[K] = { if (partitions if (fraction * n > sampleSizePerPartition) { imbalancedPartitions += idx } else { // The weight is 1 over the sampling probability. val weight = (n.toDouble / sample.size).toFloat for (key (x, weight)) } RangePartitioner.determineBounds(candidates, partitions) } } } def numPartitions: Int = rangeBounds.length + 1 private var binarySearch: ((Array[K], K) => Int) = CollectionsUtils.makeBinarySearch[K] def getPartition(key: Any): Int = { val k = key.asInstanceOf[K] var partition = 0 if (rangeBounds.length rangeBounds.length) { partition = rangeBounds.length } } if (ascending) { partition } else { rangeBounds.length - partition } } override def equals(other: Any): Boolean = other match { case r: RangePartitioner[, _] => r.rangeBounds.sameElements(rangeBounds) && r.ascending == ascending case _ => false } override def hashCode(): Int = { val prime = 31 var result = 1 var i = 0 while (i < rangeBounds.length) { result = prime * result + rangeBounds(i).hashCode i += 1 } result = prime * result + ascending.hashCode result } @throws(classOf[IOException]) private def writeObject(out: ObjectOutputStream): Unit = Utils.tryOrIOException { val sfactory = SparkEnv.get.serializer sfactory match { case js: JavaSerializer => out.defaultWriteObject() case _ => out.writeBoolean(ascending) out.writeObject(ordering) out.writeObject(binarySearch) val ser = sfactory.newInstance() Utils.serializeViaNestedStream(out, ser) { stream => stream.writeObject(scala.reflect.classTag[Array[K]]) stream.writeObject(rangeBounds) } } } @throws(classOf[IOException]) private def readObject(in: ObjectInputStream): Unit = Utils.tryOrIOException { val sfactory = SparkEnv.get.serializer sfactory match { case js: JavaSerializer => in.defaultReadObject() case _ => ascending = in.readBoolean() ordering = in.readObject().asInstanceOf[Ordering[K]] binarySearch = in.readObject().asInstanceOf[(Array[K], K) => Int] val ser = sfactory.newInstance() Utils.deserializeViaNestedStream(in, ser) { ds => implicit val classTag = ds.readObject[ClassTag[Array[K]]]() rangeBounds = ds.readObject[Array[K]]() } }} } 3、CustomPartitioner CustomPartitioner可以根据自己具体的应用需求,自定义分区。 需要继承org.apache.spark.Partitioner类,实现如下: import org.apache.spark.Partitioner class MySparkPartition(numParts: Int) extends Partitioner { override def numPartitions: Int = numParts /** * 可以自定义分区算法 * @param key * @return / override def getPartition(key: Any): Int = { val domain = new java.net.URL(key.toString).getHost() val code = (domain.hashCode % numPartitions) if (code < 0) { code + numPartitions } else { code } } override def equals(other: Any): Boolean = other match { case mypartition: MySparkPartition => mypartition.numPartitions == numPartitions case _ => false } override def hashCode: Int = numPartitions } /* * * def numPartitions:这个方法需要返回你想要创建分区的个数;def getPartition:这个函数需要对输入的key做计算,然后返回该key的分区ID,范围一定是0到numPartitions-1;equals():这个是Java标准的判断相等的函数,之所以要求用户实现这个函数是因为Spark内部会比较两个RDD的分区是否一样。/使用分区 创建了自定义分区后,使用方式如下: import org.apache.spark.{SparkConf, SparkContext} object UseMyPartitioner { def main(args: Array[String]) { val conf=new SparkConf() .setMaster(“local[2]”) .setAppName(“TestMyParttioner”) .set(“spark.app.id”,“test-partition-id”) val sc=new SparkContext(conf) //读取hdfs文件 val lines=sc.textFile(“hdfs://hadoop2:8020/user/test/word.txt”) val splitMap=lines.flatMap(line=>line.split("\t")).map(word=>(word,2))//注意:RDD一定要是key-value //保存 splitMap.partitionBy(new MySparkPartition(3)).saveAsTextFile(“F:/partrion/test”) sc.stop() } } 三、理解从HDFS读入文件默认是怎样分区的 Spark从HDFS读入文件的分区数默认等于HDFS文件的块数(blocks),HDFS中的block是分布式存储的最小单元。如果我们上传一个30GB的非压缩的文件到HDFS,HDFS默认的块容量大小128MB,因此该文件在HDFS上会被分为235块(30GB/128MB);Spark读取SparkContext.textFile()读取该文件,默认分区数等于块数即235。 四、如何设置合理的分区数 1、分区数越多越好吗? 不是的,分区数太多意味着任务数太多,每次调度任务也是很耗时的,所以分区数太多会导致总体耗时增多。 2、分区数太少会有什么影响? 分区数太少的话,会导致一些结点没有分配到任务;另一方面,分区数少则每个分区要处理的数据量就会增大,从而对每个结点的内存要求就会提高;还有分区数不合理,会导致数据倾斜问题。 3、合理的分区数是多少?如何设置? 总核数=executor-cores * num-executor 五、延伸- Spark先分区再排序 处理数据时,比我们想对一个年级的所有语文考试成绩先按班级分类,再在每个班级里按成绩排名,最终每个班级的数据保存为一个文件,这就要用到spark分区加排序的技巧 数据为DF格式时 val spark =SparkSession.builder().config(new SparkConf()).getOrCreate() val sc =spark.sparkContext val data = sc.parallelize(Array((100,2),(200,1),(300,3),(100,4),(200,4),(300,8) ,(200,5),(300,6),(100,5),(100,0),(200,6),(200,-1))) import spark.implicits._ val DF_sort_partition =data.toDF(“key”,“value”) .sort(desc(“value”)) .write .partitionBy(“key”) .mode(SaveMode.Overwrite) .parquet(“develop/wangdaopeng/partitionTest”) val s1 =spark.read.parquet(“develop/wangdaopeng/partitionTest/key=100”).show() val s2 =spark.read.parquet(“develop/wangdaopeng/partitionTest/key=200”).show() 结果的保存形式 |
 图一:数据如何被分区并存储到各个结点
图一:数据如何被分区并存储到各个结点  图二:RDD、Partition以及task的关系
图二:RDD、Partition以及task的关系  图三:分区数在shuffle操作会变化 二、分区的3种方式 Spark中分区器直接决定了RDD中分区的个数、RDD中每条数据经过Shuffle过程属于哪个分区和Reduce的个数。 注意: (1)只有Key-Value类型的RDD才有分区的,非Key-Value类型的RDD分区的值是None (2)每个RDD的分区ID范围:0~numPartitions-1,决定这个值是属于那个分区的。
图三:分区数在shuffle操作会变化 二、分区的3种方式 Spark中分区器直接决定了RDD中分区的个数、RDD中每条数据经过Shuffle过程属于哪个分区和Reduce的个数。 注意: (1)只有Key-Value类型的RDD才有分区的,非Key-Value类型的RDD分区的值是None (2)每个RDD的分区ID范围:0~numPartitions-1,决定这个值是属于那个分区的。 因为我们是根据"key"字段来保存,所以保存结果的目录是key=xx的形式,每个key对应一个分区 结果内容 key=100:
因为我们是根据"key"字段来保存,所以保存结果的目录是key=xx的形式,每个key对应一个分区 结果内容 key=100: 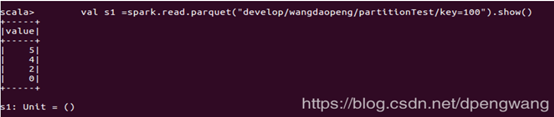 结果完全符合预期 数据为RDD格式时,如果像DF格式那样写,是达不到预期的效果的,比如下列代码: 先排序再分区 data .sortBy(_.2) .partitionBy(new HashPartitioner(3)) 或者先分区再排序 data .partitionBy(new HashPartitioner(3)) .sortBy(.2) 结果都是不符合预期的 对于RDD,一种简单的先分区再再分区里进行排序的方法如下,先repartition,RDD的partitionBy默认都是根据key值来进行的(对于pair 对,就是第一个元素),mapPartitions 输入和返回的都是一个迭代器,排序的方法在于先把iterator转化为list 排序再以iterator的形式返回 val res =data .partitionBy(new HashPartitioner(3)) .mapPartitions{x=> x.toList.sortBy(._2).toIterator }.saveAsTextFile(path) 结果:
结果完全符合预期 数据为RDD格式时,如果像DF格式那样写,是达不到预期的效果的,比如下列代码: 先排序再分区 data .sortBy(_.2) .partitionBy(new HashPartitioner(3)) 或者先分区再排序 data .partitionBy(new HashPartitioner(3)) .sortBy(.2) 结果都是不符合预期的 对于RDD,一种简单的先分区再再分区里进行排序的方法如下,先repartition,RDD的partitionBy默认都是根据key值来进行的(对于pair 对,就是第一个元素),mapPartitions 输入和返回的都是一个迭代器,排序的方法在于先把iterator转化为list 排序再以iterator的形式返回 val res =data .partitionBy(new HashPartitioner(3)) .mapPartitions{x=> x.toList.sortBy(._2).toIterator }.saveAsTextFile(path) 结果:  参考文献:https://blog.csdn.net/high2011/article/details/68491115 参考文献:https://blog.csdn.net/dpengwang/article/details/83417014
参考文献:https://blog.csdn.net/high2011/article/details/68491115 参考文献:https://blog.csdn.net/dpengwang/article/details/83417014【本文地址】
今日新闻 |
推荐新闻 |