python爬虫入门 |
您所在的位置:网站首页 › 王者荣耀人物角色分析 › python爬虫入门 |
python爬虫入门
|
王者荣耀英雄及皮肤数据爬取项目
一:做前需知
笔者这段学习了一些爬虫的知识,然后做了一个小项目。接下来,我会把项目的流程展示出来。 运行环境:python 3.6.3、pycharm 2019-3-3、win10、phantomjs、谷歌浏览器(版本 81.0.4044.129(正式版本) (64 位)) 用到的python第三方库:urllib3、lxml、matplotlib、requests、selenium 关于注解的:笔者会在图片下方添加一些解析 二:预期效果 1.将王者荣耀的英雄数据(英雄名称+英雄图片)保存为本地.json文件 2.根据本地英雄json文件中的数据下载英雄图像 3.将王者荣耀的英雄的皮肤数据信息(皮肤名称+皮肤图片)保存为本地.json文件 4.根据本地皮肤json文件中的数据下载皮肤图像 5.将英雄数据与皮肤数量信息的对应关系以柱状图形式表现出来 三:项目开始1.创建项目 2.爬取英雄信息并保存到本地 在项目名那里右键创建一个名为:herodatacrawl的py文件 from selenium import webdriver import lxml.html import os import json import time #禁用 urllib3 import urllib3 urllib3.disable_warnings() def parse_wangzhe_url(http_url): #phantomjs安装目录 pjs_path = r"E:\PhantomJS\phantomjs-2.1.1-windows\bin\phantomjs.exe" browser = webdriver.PhantomJS(pjs_path) browser.get(http_url) time.sleep(2) hero_html_content = browser.page_source #print(hero_html_content) browser.quit() return hero_html_content def catch_hero_into_list(html_content): #提取英雄数据信息 metree = lxml.html.etree #获取etree对象 parse = metree.HTML(html_content) #获取解析器对象 li_list = parse.xpath("//div[@class='herolist-content']/ul[@class='herolist clearfix']/li") #开始解析 # print(li_list) # print(len(li_list)) hero_info_list = [] for li_element in li_list: hero_item = {} #英雄名称 hero_name = li_element.xpath("./a/text()")[0] #print(hero_name) hero_item["hero_name"] = hero_name #英雄图片地址 hero_image_url = "https:" + li_element.xpath("./a/img/@src")[0] #print(hero_image_url) hero_item["hero_image_url"] = hero_image_url #详情链接地址 hero_href_url = "https://pvp.qq.com/web201605/" + li_element.xpath("./a/@href")[0] #print(hero_href_url) hero_item["hero_href_url"] = hero_href_url #print(hero_item) hero_info_list.append(hero_item) #返回 return hero_info_list def save_hero_file(datas): #把所有英雄数据保存到文件中 #先创建一个目录 hero_path = "./hero" if not os.path.exists(hero_path): os.makedirs(hero_path) print("目录(%s)创建成功!"%hero_path) #保存数据 wangzhefile = open(hero_path + "/hero.json", "w", encoding="utf-8") json.dump(datas,wangzhefile,ensure_ascii=False,indent=2) print("数据文件保存成功!") def main(): #王者荣耀英雄资料网页 wangzhe_url = "https://pvp.qq.com/web201605/herolist.shtml" hero_html_datas = parse_wangzhe_url(wangzhe_url) #print(hero_html_datas) #print(html_date) hero_info_list = catch_hero_into_list(hero_html_datas) # #print(hero_info_list) # #将python数据存入到json文件中 save_hero_file(hero_info_list) if __name__ == '__main__': main()运行效果: 3.根据本地hero.json文件下载英雄图片 在项目名那里右键创建两个py文件:一个名为herodatacrawl,一个名为useragentutil(工具类,让某讯那边不知道你这是爬虫,而只是普通的下载东西) herodatacrawl.py代码: import json import os import requests import useragentutil # def read_hero_info_file_from_json(): #从hero.json中获取信息 jsonreader = open("./hero/hero.json","r",encoding="utf-8") hero_json_message = json.load(jsonreader) return hero_json_message def create_hero_image_save_dirs(datas): #获取英雄名称后创建目录 for hero_element in datas: #print(hero_element) #path_name = hero_element["hero_name"] path_name = hero_element.get("hero_name") #print("./hero/picture/" + path_name) hero_save_path_dir = "./hero/picture2/" + path_name #print(hero_save_path_dir) if not os.path.exists(hero_save_path_dir): os.makedirs(hero_save_path_dir) print("目录[%s]已创建成功"%hero_save_path_dir) print("所有英雄目录创建成功") def download_hero_image(datas): #下载图片 #获取英雄名称和下载链接 for hero_message in datas: hero_name = hero_message.get("hero_name") hero_image_url = hero_message.get("hero_image_url") #print("英雄名称:%s,英雄图片:链接%s"%(hero_name,hero_image_url)) response = requests.get(hero_image_url,headers=useragentutil.get_headers()) pic_content = response.content #保存到文件中 pic_path = "./hero/picture2/" + hero_name hero_image_file = open(pic_path+"/1"+hero_name+".jpg","wb") #写入数据 hero_image_file.write(pic_content) #关闭数据 hero_image_file.close() print("正在下载%s英雄的图片"%hero_name) print("所有英雄图片下载完毕!") def main(): #读取文件数据 hero_info_list = read_hero_info_file_from_json() #print(hero_info_list) create_hero_image_save_dirs(hero_info_list) download_hero_image(hero_info_list) if __name__ == '__main__': main()useragentutil.py代码: # coding:utf-8 import random # User-Agent列表 user_agent_datas = [ { "User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36 OPR/26.0.1656.60"}, {"User-Agent": "Opera/8.0 (Windows NT 5.1; U; en)"}, {"User-Agent": "Mozilla/5.0 (Windows NT 5.1; U; en; rv:1.8.1) Gecko/20061208 Firefox/2.0.0 Opera 9.50"}, {"User-Agent": "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; en) Opera 9.50"}, {"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:34.0) Gecko/20100101 Firefox/34.0"}, { "User-Agent": "Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10"}, { "User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.57.2 (KHTML, like Gecko) Version/5.1.7 Safari/534.57.2"}, { "User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.71 Safari/537.36"}, { "User-Agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11"}, { "User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.16 (KHTML, like Gecko) Chrome/10.0.648.133 Safari/534.16"}, { "User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/30.0.1599.101 Safari/537.36"}, {"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko"}, { "User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.11 TaoBrowser/2.0 Safari/536.11"}, { "User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER"}, { "User-Agent": "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; LBBROWSER)"}, { "User-Agent": "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E; LBBROWSER)"}, { "User-Agent": "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; QQBrowser/7.0.3698.400)"}, {"User-Agent": "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)"}, { "User-Agent": "Mozilla/5.0 (Windows NT 5.1) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 SE 2.X MetaSr 1.0"}, { "User-Agent": "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SV1; QQDownload 732; .NET4.0C; .NET4.0E; SE 2.X MetaSr 1.0)"}, { "User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Maxthon/4.4.3.4000 Chrome/30.0.1599.101 Safari/537.36"}, { "User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 UBrowser/4.0.3214.0 Safari/537.36"}, ] def get_headers(): """随机获取User-Agent值""" # 获得随机数 index = random.randint(0, len(user_agent_datas) - 1) return user_agent_datas[index] if __name__ == '__main__': print("随机获得值为:", get_headers())herodatadown.py运行效果: 4.爬取英雄皮肤信息并保存到本地 在项目名那里右键创建名为:heroskindatacrawl的py文件 heroskindatacrawl.py代码: import json from selenium import webdriver #获取json数据 def read_hero_into_file_json(): hero_file = open("./hero/hero.json","r",encoding="utf-8") hero_result = json.load(hero_file) return hero_result def catch_hero_skin_href_url(url): #动态提取 pjs_path = r"E:\PhantomJS\phantomjs-2.1.1-windows\bin\phantomjs.exe" #phantomjs安装目录 browser = webdriver.PhantomJS(pjs_path) browser.maximize_window() #发送请求 browser.get(url) #提取数据 li_list = browser.find_elements_by_xpath("//div[@class='pic-pf']/ul/li") #print(len(li_list)) skin_duixiang = [] #遍历 for li_element in li_list: skin_zidian = {} skin_name = li_element.find_element_by_xpath("./p").text #print(skin_name) skin_zidian["skin_name"] = skin_name skin_url = "https:" + li_element.find_element_by_xpath("./i/img").get_attribute("data-imgname") #print(skin_url) skin_zidian["skin_url"] = skin_url #print(skin_zidian) skin_duixiang.append(skin_zidian) #关闭 browser.quit() return skin_duixiang def save_hero_skin_file(datas): skin_file = open("./hero/heroskin2.json","w",encoding="utf-8") json.dump(datas, skin_file, ensure_ascii=False, indent=2) def main(): hero_list = read_hero_into_file_json() #print(hero_list) #英雄列表 hero_info_list = [] for hero_element in hero_list: hero_item = {} hero_name = hero_element["hero_name"] hero_item["hero_name"] = hero_name #获取链接地址 skin_href_url = hero_element["hero_href_url"] #print(skin_href_url) #对链接发送请求 skin_duixiang = catch_hero_skin_href_url(skin_href_url) hero_item["skin_duixiang"] = skin_duixiang #print("正在输出%s英雄的皮肤"%hero_name,skin_duixiang) #print(hero_item) hero_info_list.append(hero_item) #print(hero_info_list) save_hero_skin_file(hero_info_list) print("正在保存英雄%s的皮肤数据信息,请稍候。。。"%hero_name) print("您好,所以英雄皮肤数据已经保存成功。") if __name__ == '__main__': main()heroskindata.py运行效果: 5.根据本地heroskin.json文件下载皮肤图片 在项目名那里右键创建名为:heroskindown的py文件 heroskindown.py代码: import json import requests import useragentutil #禁用 urllib3 import urllib3 urllib3.disable_warnings() def read_hero_skin_file_from_json(): skin_file = open("./hero/heroskin.json","r",encoding="utf-8") skin_result = json.load(skin_file) return skin_result def main(): #1.从已经获取到的皮肤信息数据中,读取文件,获得数据 hero_skin_datas = read_hero_skin_file_from_json() #2.遍历并获取单个的英雄数据 i = 0 while i |

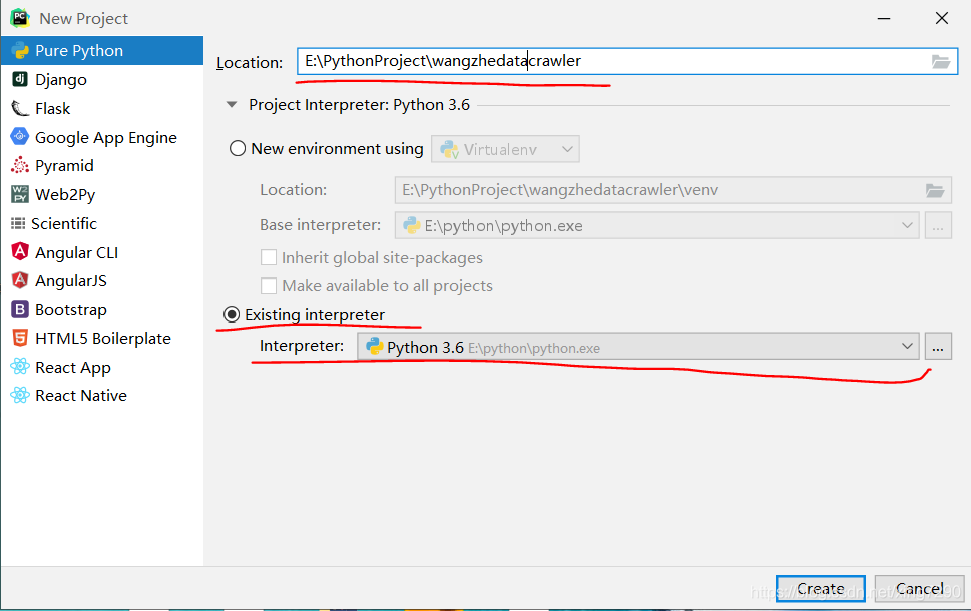 项目名命名规范:全部小写 interpreter为解释器:要选择本地的python安装路径,这样才能用到项目运行时在本地安装第三方库
项目名命名规范:全部小写 interpreter为解释器:要选择本地的python安装路径,这样才能用到项目运行时在本地安装第三方库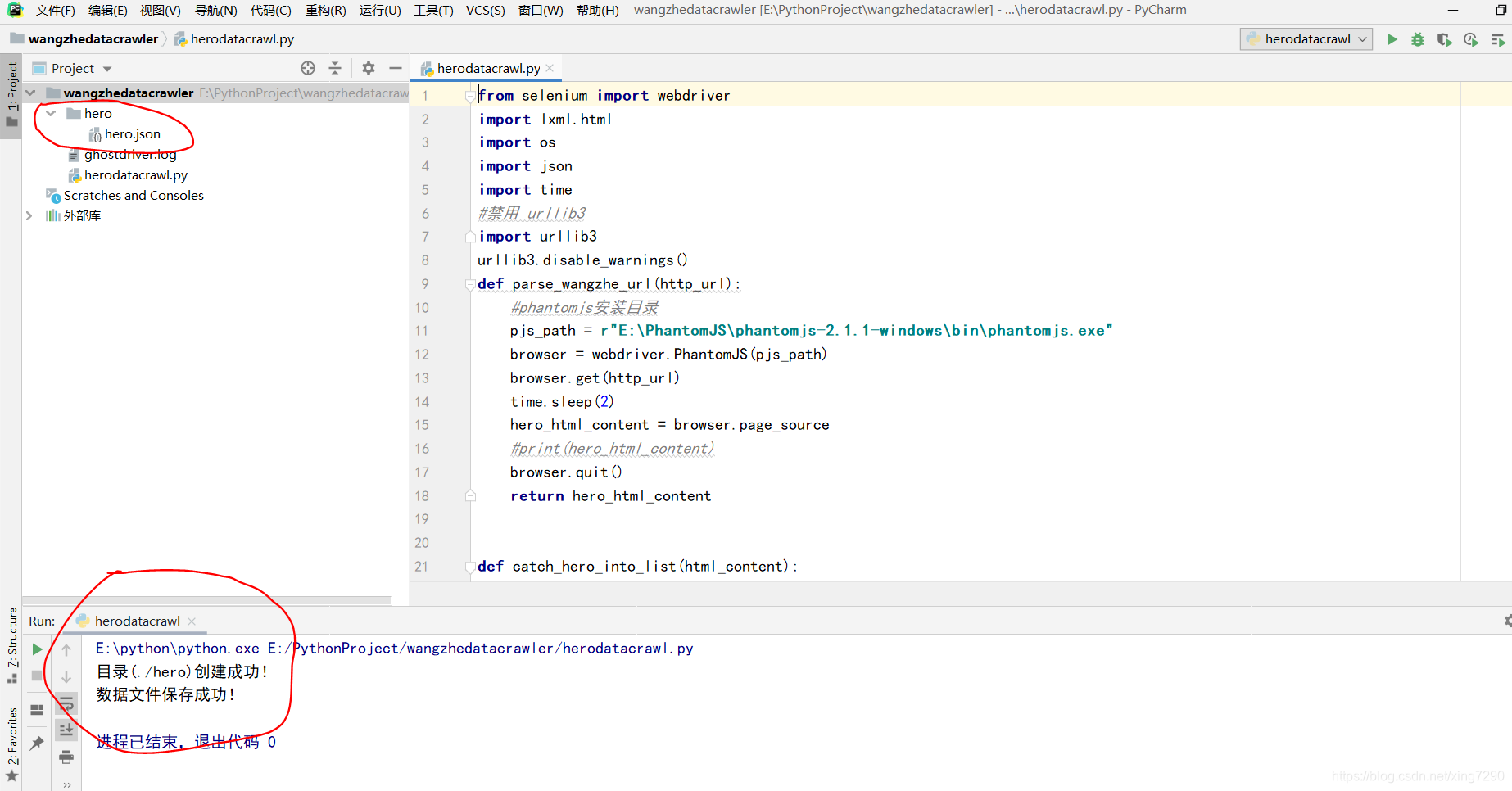 目录创建成功,并在控制台输出信息
目录创建成功,并在控制台输出信息  生成json文件中包含了英雄名称,英雄图片链接,英雄详情链接
生成json文件中包含了英雄名称,英雄图片链接,英雄详情链接 控制台输出实时信息,并且创建子目录picture,并以每个英雄的名称创建了目录,然后也下载了英雄头像
控制台输出实时信息,并且创建子目录picture,并以每个英雄的名称创建了目录,然后也下载了英雄头像 控制台输出信息,并创建了heroskin.json文件,保存了英雄名称,英雄皮肤名称,皮肤链接
控制台输出信息,并创建了heroskin.json文件,保存了英雄名称,英雄皮肤名称,皮肤链接【本文地址】
今日新闻 |
推荐新闻 |