[深度学习]激活函数(Sigmoid等)、前向传播、反向传播和梯度优化;optimizer.zero |
您所在的位置:网站首页 › 激活函数有什么作用,请举出两个例子 › [深度学习]激活函数(Sigmoid等)、前向传播、反向传播和梯度优化;optimizer.zero |
[深度学习]激活函数(Sigmoid等)、前向传播、反向传播和梯度优化;optimizer.zero
|
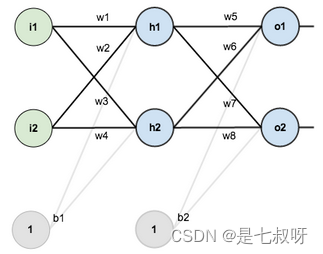
用Matt Mazur的例子,来简单告诉读者推导过程吧(其实就是链式)!
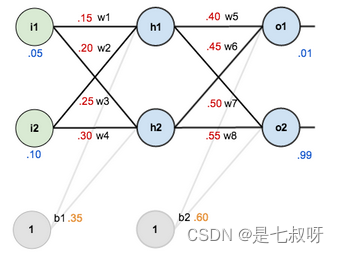
先初始化权重和偏置量,得到如下效果:
激活函数可以分为线性激活函数(线性方程控制输入到输出的映射,如f(x)=x等)以及非线性激活函数(非线性方程控制输入到输出的映射,比如Sigmoid、Tanh、ReLU、LReLU、PReLU、Swish 等) 激活函数是向神经网络中引入非线性因素,通过激活函数神经网络就可以拟合各种曲线。激活函数又可以分为饱和激活函数(Saturated Neurons)和非饱和函数(One-sided Saturations)。Sigmoid和Tanh是饱和激活函数,而ReLU以及其变种为非饱和激活函数。非饱和激活函数主要有如下优势: 非饱和激活函数可以解决梯度消失问题。非饱和激活函数可以加速收敛。
S
i
g
m
o
i
d
函
数
也
叫
L
o
g
i
s
t
i
c
函
数
\color{red}{Sigmoid函数也叫Logistic函数}
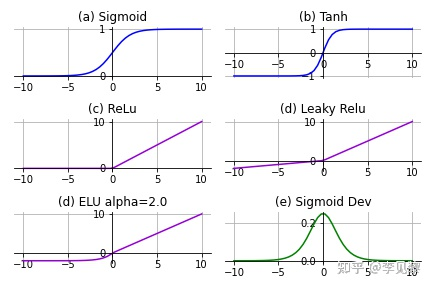
Sigmoid函数也叫Logistic函数,用于隐层神经元输出,取值范围为(0,1),它可以将一个实数映射到(0,1)的区间,可以用来做二分类。在特征相差比较复杂或是相差不是特别大时效果比较好。sigmoid是一个十分常见的激活函数,函数的表达式如下: ReLU函数又称为修正线性单元(Rectified Linear Unit),是一种分段线性函数,其弥补了sigmoid函数以及tanh函数的梯度消失问题,在目前的深度神经网络中被广泛使用。ReLU函数本质上是一个斜坡(ramp)函数,公式及函数图像如下: Softmax 是用于多类分类问题的激活函数,在多类分类问题中,超过两个类标签则需要类成员关系。对于长度为 K 的任意实向量,Softmax 可以将其压缩为长度为 K,值在(0,1)范围内,并且向量中元素的总和为 1 的实向量。函数表达式如下:
仔细观察成本函数,其形式为Y=X²。在笛卡尔坐标系中,这是一个抛物线方程,用图形表示如下: 由于这是一个二维图像,因此很容易找到其最小值,但是在 维 度 比 较 大 \color{red}{维度比较大} 维度比较大的情况下,情况会更加复杂。对于这种情况,需要设计一种算法来定位最小值,该算法称为梯度下降算法(Gradient Descent)。 梯度下降是优化模型的方法中最流行的算法之一,也是迄今为止优化神经网络的最常用方法。它本质上是一种迭代优化算法,用于查找函数的最小值。 4.2 表示假设你是沿着下面的图表走,目前位于曲线’绿’点处,而目标是到达最小值,即红点位置,但你是无法看到该最低点。 在下图中,在绿点处绘制切线,如果向上移动,就将远离最小值,反之亦然。此外,切线也能让我们感觉到斜坡的陡峭程度: 在机器学习的核心内容就是把数据喂给一个人工设计的模型,然后让模型自动的“学习”,从而优化模型自身的各种参数,最终使得在某一组参数下该模型能够最佳的匹配该学习任务。那么这个“学习”的过程就是机器学习算法的关键。梯度下降法就是实现该“学习”过程的一种最常见的方式,尤其是在深度学习(神经网络)模型中,BP反向传播方法的核心就是对每层的权重参数不断使用梯度下降来进行优化。 批梯度下降法(stochastic gradient descent)是指使用每一条数据来计算梯度值更新参数: 在用pytorch训练模型时,通常会在遍历epochs的过程中依次用到optimizer.zero_grad(),loss.backward()和optimizer.step()三个函数,如下所示: model = MyModel() criterion = nn.CrossEntropyLoss() optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9, weight_decay=1e-4) for epoch in range(1, epochs): for i, (inputs, labels) in enumerate(train_loader): output= model(inputs) loss = criterion(output, labels) # compute gradient and do SGD step optimizer.zero_grad() loss.backward() optimizer.step()总得来说,在学习pytorch的时候注意到,对于每个batch大都执行了这三种操作。这三个函数的作用是 先将每一个batsize的梯度归零(optimizer.zero_grad()),然后反向传播计算得到 l o s s 关 于 每 个 参 数 的 梯 度 值 \color{red}{loss关于每个参数的梯度值} loss关于每个参数的梯度值(loss.backward())【此处和具体的loss值无关,和其梯度有关】,最后通过梯度下降执行一步参数更新(optimizer.step())参考:理解optimizer.zero_grad(), loss.backward(), optimizer.step()的作用及原理 参考:[pytorch] torch代码解析 为什么要使用optimizer.zero_grad() |
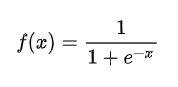 图像类似一个S形曲线:
图像类似一个S形曲线: 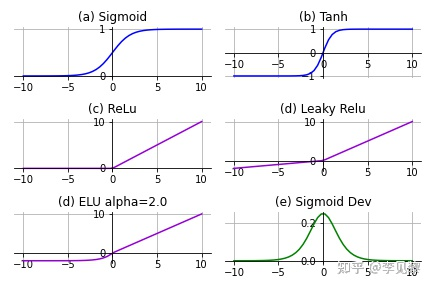
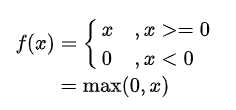 图像:
图像: 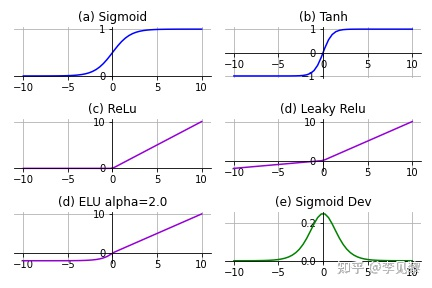
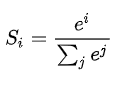 图像:
图像:  作用示例:
一
般
用
来
放
在
网
络
最
后
输
出
各
类
别
概
率
值
\color{red}{一般用来放在网络最后输出各类别概率值}
一般用来放在网络最后输出各类别概率值
作用示例:
一
般
用
来
放
在
网
络
最
后
输
出
各
类
别
概
率
值
\color{red}{一般用来放在网络最后输出各类别概率值}
一般用来放在网络最后输出各类别概率值 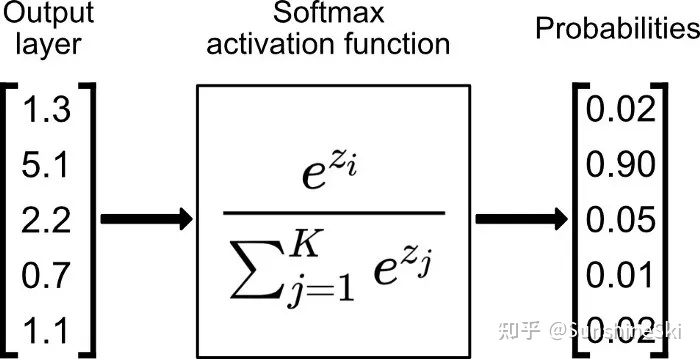 Softmax 激活函数的不足:
Softmax 激活函数的不足:

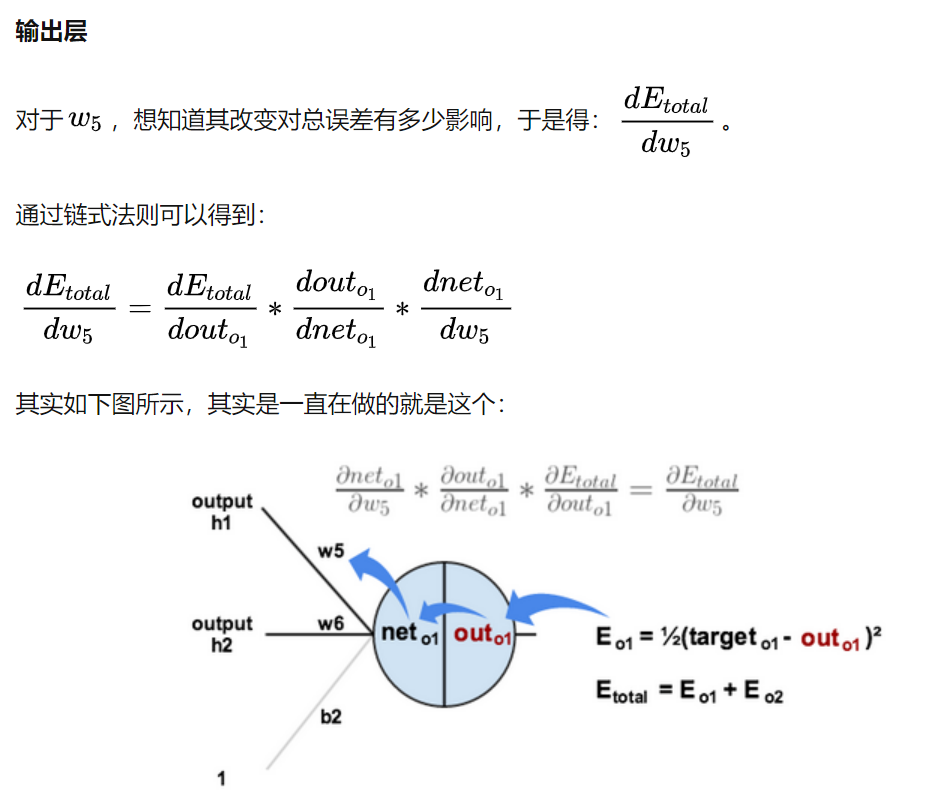
 通过相同的步骤就可以更新所有的w:
通过相同的步骤就可以更新所有的w:  参考:
参考: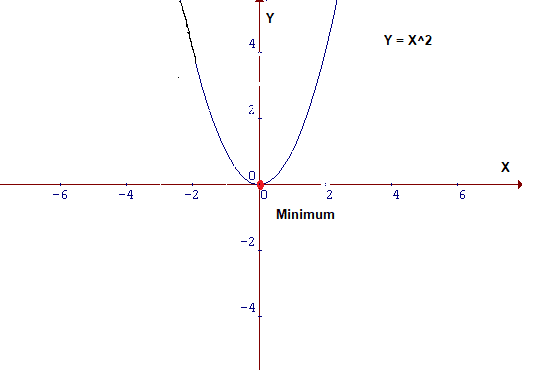 为了最小化上面的函数,需要找到一个x,函数在该点能产生小值Y,即图中的红点。
为了最小化上面的函数,需要找到一个x,函数在该点能产生小值Y,即图中的红点。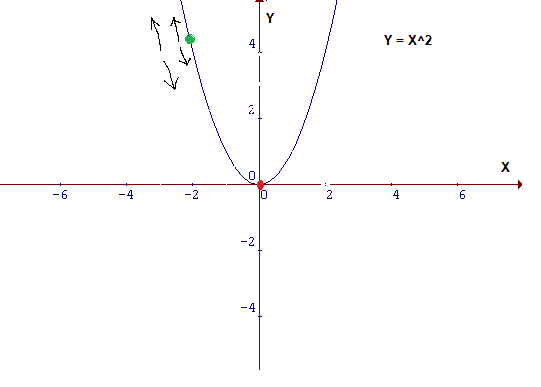 可能采取的行动:
可能采取的行动: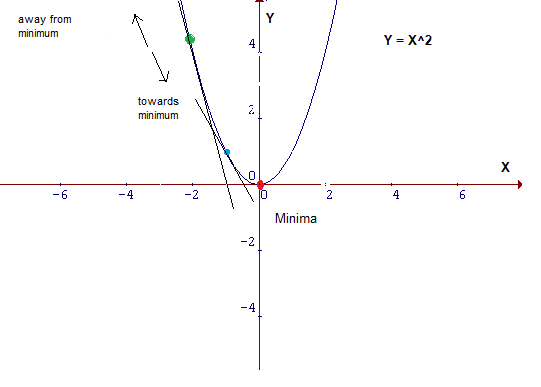 蓝点处的斜率比绿点处的斜率低,这意味着从蓝点到绿点所需的步长要小得多。 参考:图解梯度下降背后的数学原理
蓝点处的斜率比绿点处的斜率低,这意味着从蓝点到绿点所需的步长要小得多。 参考:图解梯度下降背后的数学原理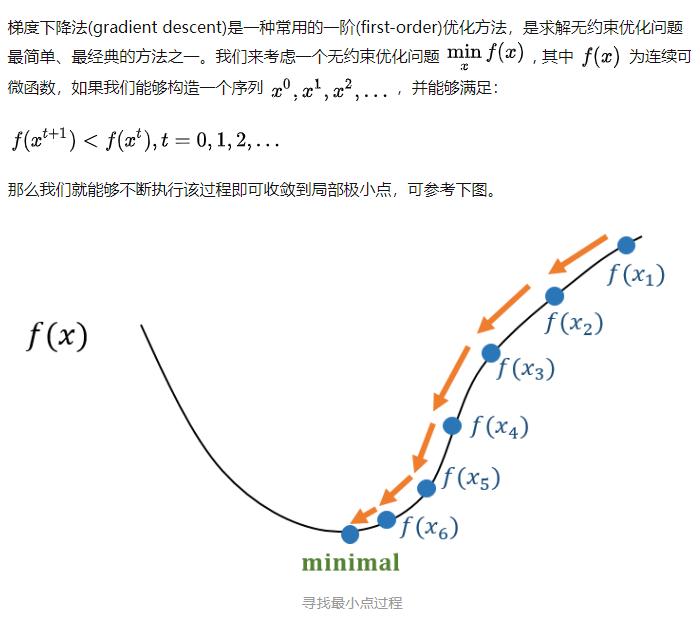 参考:梯度下降法 —— 经典的优化方法
参考:梯度下降法 —— 经典的优化方法 通常,随机梯度下降法相比于批梯度下降法具有更快的速度,可用于在线学习,SGD以高方差频繁地更新,因此容易出现下列剧烈波动的情况。
通常,随机梯度下降法相比于批梯度下降法具有更快的速度,可用于在线学习,SGD以高方差频繁地更新,因此容易出现下列剧烈波动的情况。【本文地址】
今日新闻 |
推荐新闻 |