真实世界大数据分析系列 |
您所在的位置:网站首页 › 混杂和混杂因素的概念区别和联系 › 真实世界大数据分析系列 |
真实世界大数据分析系列
|
基于上面的数据,我们可以计算Crude Odds Ratio (OR) = (91/2249)/(26/190) = 3.38 考虑到高血压可能作为混杂因素影响糖尿病与冠心病的关联,我们可以使用Maentel Hanzel方法校正高血压在其中的混杂效应,使用该方法后我们得到的校正后的OR值为2.84; Maentel Hanzel可以根据不同分组计算pooled效应值,并消除混杂因素的影响,计算方法如下:
但是Maentel Hanzel方法仅对混杂效应只有一个的情况有效,若存在多个混杂因素,需要使用多因素分析进行校正。 另外,我们也可以使用分层分析的方法去控制混杂因素对结果的影响,在上述的研究中,我们可以将研究对象按照是否患有高血压分为两组,然后分别计算两组的OR值。分层分析可以切断混杂因素与暴露之间的关联,从而去除对暴露与结果之间关联的影响。
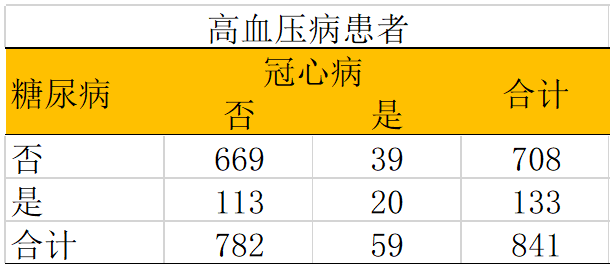
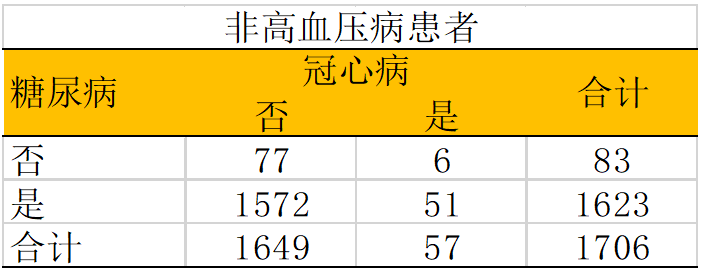
ORHYP = (20/113)/ (39/669) = 3.04 ORNON-HYP = (51/1649)/ (6/77) = 2.40 可以看见在高血压患者与非高血压患者中,OR值都比原本估计的crude OR要低。 如何控制混杂: 1. 对研究对象进行随机分组(试验式设计); 2. 限制或者仅选择特定分组的对象,像上述例子中仅选择有高血压的患者; 3. 根据混杂因素对两组研究对象进行匹配; 4. 在分析中进行分层分析或者校正; 效应修饰(Effect modification)的定义是暴露与结局的关联或者效应在不同分组中不同。效应修饰因子是指对暴露与结局之间关联或效应有影响(正向或者负向)的因素。在实际的分析中,效应修饰实际上是指交互效应(暴露与协变量的交互作用)。 例如在上述的例子中,我们发现糖尿病跟冠心病之间的关联在高血压与非高血压患者之间的关联不同。如果高血压与糖尿病(暴露)之间没有存在关联(高血压的分布在糖尿病与非糖尿病患者中没有差异),这时虽然高血压不是混杂因素,但它却是效应修饰因子。 研究效应修饰有助于我们发现高危组或者是治疗敏感组别,实现精准预防或者治疗。进行亚组分析也有助于我们进行不同研究的横向对比,因为不同研究纳入人群的基本信息会有差异。比如进行A研究中70%的对象都是男性,而B研究中只有50%,如果盲目比较总体结果是不准确的,这时候我们可以在男、女性亚组中分别比较两个研究的结果。
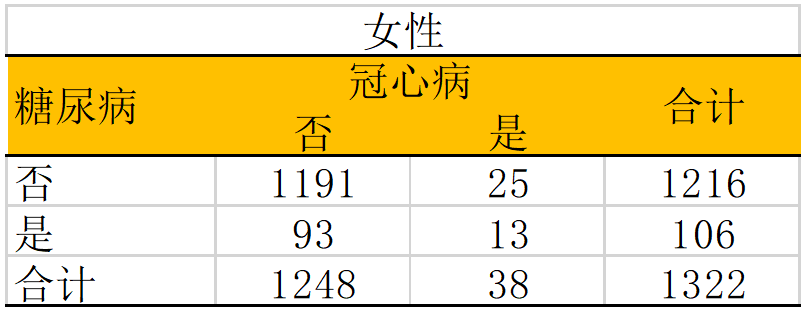
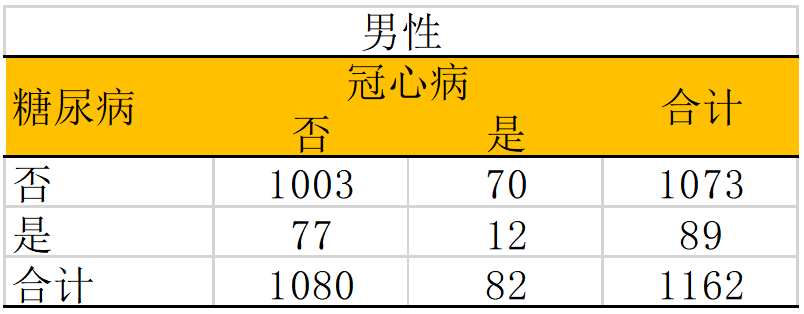
分别计算男女性中的OR值: OR女 = (13/93)/(25/1191) = 6.66 OR男 = (12/77)/(70/1003) = 2.23 对于上述的研究,它的crude OR是4.30,考虑到性别可能是效应修饰因子,因此我们根据性别进行分层分析。我们可以看到糖尿病在男性与女性中的分布并没有明显差异,糖尿病的患病率都是15%左右,因此在这个研究中性别并不是一个混杂因素。但是当我们做分层分析时,我们发现糖尿病与冠心病的关联在性别中的差异较大。此时,性别在这个研究中就是效应修饰因子,提示我们在女性人群中,应该更加关注两者的关联。 对于效应修饰的处理,我们应该根据可能存在效应修饰的因子进行亚组分析。如果各组的结果存在较大的差异,应该分别汇报各组的结果。在多因素分析中,我们也可以使用纳入交互项的方法探讨是否存在效应修饰。 在分析中我们应该怎么区分混杂效应与效应修饰呢? 第一步:计算暴露与结局之间粗效应值(例如 crude OR); 第二步:计算暴露与结局之间校正了可能的混杂因素以后的效值应(adjusted OR); 第三步:按照混杂或者效应修饰因子进行分层,计算每层中的效应值; 对于混杂因素: 粗效应值与分层后的各层效应值的加权平均不等(例如高血压案例中,粗效应值高于两个分层的值); 如果校正后的效应值对比原值改变量10%或以上,认为存在混杂效应; 可以使用各种统计学方法(Maentel Hanzel、多因素回归等)对效应值进行校正,也可以进行分层分析;对于效应修饰因子: 粗效应值与接近于分层后的各层效应值的加权平均; 分层后各层的效应值不同; 可以进行分层分析或者对交互效应项进行汇报;更多内容,请关注“医学大数据挖掘分析”公众号,欢迎留言联系~ 地址:广州市天河区珠江东路高德置地秋广场F座返回搜狐,查看更多 |

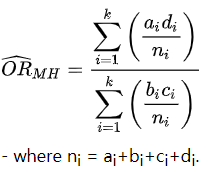
【本文地址】
今日新闻 |
推荐新闻 |