C |
您所在的位置:网站首页 › 每个汉子几个字节 › C |
C
|
中文汉字占用字节长度
一、字符集和字符编码1、概念2、英文字母和中文汉字在不同字符集编码下的字节数
二、环境对应的字符编码1、Ubuntu16.04虚拟机2、Notepad++
三、sizeof运算汉字占用字节长度参考
一、字符集和字符编码
1、概念
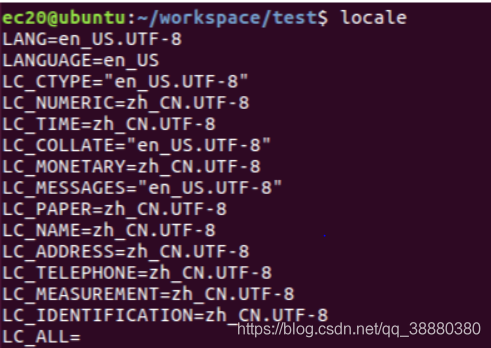
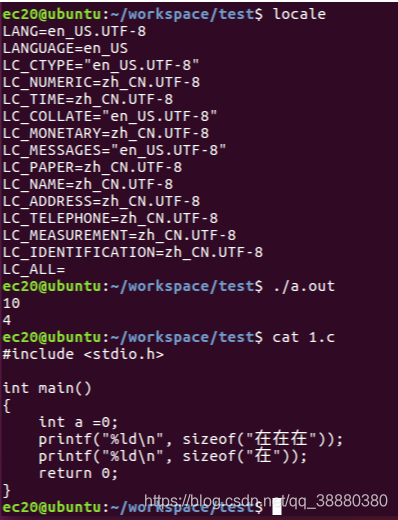
字符集(Charset):是一个系统支持的所有抽象字符的集合。字符是各种文字和符号的总称,包括各国家文字、标点符号、图形符号、数字等。 字符编码(Character Encoding):是一套法则,使用该法则能够对自然语言的字符的一个集合(如字母表或音节表),与其他东西的一个集合(如号码或电脉冲)进行配对。即在符号集合与数字系统之间建立对应关系,它是信息处理的一项基本技术。通常人们用符号集合(一般情况下就是文字)来表达信息。而以计算机为基础的信息处理系统则是利用元件(硬件)不同状态的组合来存储和处理信息的。元件不同状态的组合能代表数字系统的数字,因此字符编码就是将符号转换为计算机可以接受的数字系统的数,称为数字代码。 2、英文字母和中文汉字在不同字符集编码下的字节数 英文字母 字节数 : 1;编码:GB2312 字节数 : 1;编码:GBK 字节数 : 1;编码:GB18030 字节数 : 1;编码:ISO-8859-1 字节数 : 1;编码:UTF-8 字节数 : 4;编码:UTF-16 字节数 : 2;编码:UTF-16BE 字节数 : 2;编码:UTF-16LE 中文汉字 字节数 : 2;编码:GB2312 字节数 : 2;编码:GBK 字节数 : 2;编码:GB18030 字节数 : 1;编码:ISO-8859-1 字节数 : 3;编码:UTF-8 字节数 : 4;编码:UTF-16 字节数 : 2;编码:UTF-16BE 字节数 : 2;编码:UTF-16LE历史发展 (1)美国人首先对其英文字符进行了编码,也就是最早的ascii码,用一个字节的低7位来表示英文的128个字符,高1位统一为0; (2)后来欧洲人发现尼玛你这128位哪够用,比如我高贵的法国人字母上面的还有注音符,这个怎么区分,得,把高1位编进来吧,这样欧洲普遍使用一个全字节进行编码,最多可表示256位。欧美人就是喜欢直来直去,字符少,编码用得位数少; (3)但是即使位数少,不同国家地区用不同的字符编码,虽然0–127表示的符号是一样的,但是128–255这一段的解释完全乱套了,即使2进制完全一样,表示的字符完全不一样,比如135在法语,希伯来语,俄语编码中完全是不同的符号; (4)更麻烦的是,尼玛这电脑高科技传到中国后,中国人发现我们有10万多个汉字,你们欧美这256字塞牙缝都不够。于是就发明了GB2312这些汉字编码,典型的用2个字节来表示绝大部分的常用汉字,最多可以表示65536个汉字字符,这样就不难理解有些汉字你在新华字典里查得到,但是电脑上如果不处理一下你是显示不出来的了吧。 (5)这下各用各的字符集编码,这世界咋统一?俄国人发封email给中国人,两边字符集编码不同,尼玛显示都是乱码啊。为了统一,于是就发明了unicode,将世界上所有的符号都纳入其中,每一个符号都给予一个独一无二的编码,现在unicode可以容纳100多万个符号,每个符号的编码都不一样,这下可统一了,所有语言都可以互通,一个网页页面里可以同时显示各国文字。 (6)然而,unicode虽然统一了全世界字符的二进制编码,但没有规定如何存储啊,亲。x86和amd体系结构的电脑小端序和大端序都分不清,别提计算机如何识别到底是unicode还是acsii了。如果Unicode统一规定,每个符号用三个或四个字节表示,那么每个英文字母前都必然有二到三个字节是0,文本文件的大小会因此大出二三倍,这对于存储来说是极大的浪费。这样导致一个后果:出现了Unicode的多种存储方式。 (7)互联网的兴起,网页上要显示各种字符,必须统一啊,亲。utf-8就是Unicode最重要的实现方式之一。另外还有utf-16、utf-32等。UTF-8不是固定字长编码的,而是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。这是种比较巧妙的设计,如果一个字节的第一位是0,则这个字节单独就是一个字符;如果第一位是1,则连续有多少个1,就表示当前字符占用多少个字节。 (8)注意unicode的字符编码和utf-8的存储编码表示是不同的,例如”严”字的Unicode码是4E25,UTF-8编码是E4B8A5,这个7里面解释了的,UTF-8编码不仅考虑了编码,还考虑了存储,E4B8A5是在存储识别编码的基础上塞进了4E25。 (9)UTF-8 使用一至四个字节为每个字符编码。128 个 ASCII 字符(Unicode 范围由 U+0000 至 U+007F)只需一个字节,带有变音符号的拉丁文、希腊文、西里尔字母、亚美尼亚语、希伯来文、阿拉伯文、叙利亚文及马尔代夫语(Unicode 范围由 U+0080 至 U+07FF)需要二个字节,其他基本多文种平面(BMP)中的字符(CJK属于此类-Qieqie注)使用三个字节,其他 Unicode 辅助平面的字符使用四字节编码。 (10)最后,要回答你的问题,常规来看,中文汉字在utf-8中到底占几个字节,一般是3个字节,最常见的编码方式是1110xxxx 10xxxxxx 10xxxxxx。 二、环境对应的字符编码 1、Ubuntu16.04虚拟机
1、字符集–baike 2、字符编码–baike 3、字符编码–wiki 4、字符集和字符编码(Charset & Encoding) 5、中文汉字占二个字节还是三个字节长度 6、vim编译器(5):编码、字符格式 |
【本文地址】
今日新闻 |
推荐新闻 |