数据分析学习总结笔记13:生存分析及Python实现 |
您所在的位置:网站首页 › 死亡率曲线图分析方法 › 数据分析学习总结笔记13:生存分析及Python实现 |
数据分析学习总结笔记13:生存分析及Python实现
|
文章目录
1 引言
2 定义
3 数学直观
4 Kaplan-Meier 估计
5 Cox比例风险模型
6 总结
1 引言
生存分析是一套统计方法,用来解决诸如“多长时间后,某个特定事件发生”这样的问题; 换句话说,也可以称之为事件时间分析。 这种方法被称为生存分析,是由于主要是由医学研究人员开发的,他们更感兴趣的是寻找不同群体患者的预期寿命(例如: 用药物a治疗的组群1和用药物b治疗的组群2)。这种分析不仅可以应用于传统的死亡事件,还可以应用于不同商业领域中的许多不同类型的事件。 2 定义如上所述,生存分析也称为事件时间分析。因此,从名称本身来看,事件和时间的定义对于生存分析是至关重要的。为了理解时间和事件,本文将为一些事例定义时间和事件。 (1)机械操作中的预测性维护:生存分析应用于机械部件/机器,以预测“机器能够运行的时长? ”。预测性维护是其应用之一。 事件:机器出现故障的时间点。 初始时间:连续作业时机器启动的时间。 时间的尺度:可以是周、天、小时。 事件发生所需时间:事件发生的时间点和初始时间的差。(2)客户分析(客户留存):通过生存分析,专注于那些高收益但低留存的客户,进行流失预防工作。这种分析也有助于计算客户生命时间价值。 事件:客户流失的时间点。 初始时间:客户与公司开始服务 / 订阅的时间。 时间尺度:几个月/几周。 事件发生所需时间:事件发生的时间点和初始时间的差。(3)营销分析(同期群分析):生存分析评估每个营销渠道的留存率。 事件:客户取消订阅某个营销渠道的时间点。 初始时间:客户开始该营销渠道的服务 / 订阅的时间。 时间尺度:几个月/几周。(4)精算:给定人群的风险,生存分析评估该人群在特定时间范围内死亡的概率。这种分析有助于保险公司对保费进行评估。 3 数学直观假设有一个非负连续随机变量T,代表直到某些事件发生的时间。例如,T可能表示: 从客户订阅到客户流失的时间。 从机器启动到故障的时间。 从诊断出一种疾病到死亡的时间。T是非负连续型随机变量,因此可以取任何非负实数值(包括0)。 对于这样的随机变量,通常使用概率密度函数和累积分布函数描述它们的分布特征。 假设该随机变量的概率密度函数f(t)和累积分布函数F(t)。 定义的形式: h(t) = [(S(t) -S(t + dt))/dt] / S(t) (limit dt->0) 从上面的公式中可以看出它有两个部分 瞬时事件发生率: (s(t) - s(t + dt)) / dt;也可以看作生存曲线任意点t的斜率,或任意时刻t的死亡率。 举例来说: 假设总人口为P。在这里,s(t) - s(t + dt),这个差值给出了dt时间内死亡人数的比例: 在t时刻存活的人数是s(t)*P;在t + dt时刻存活的人数是s(t + dt)*P。 在时刻死亡的人数是(s(t) - s(t + dt))*p,在t时的瞬时死亡率是(s(t) - s(t + dt))*p / dt。 t时刻的存活率:s(t);t时刻的存活种群:s(t)*p。因此,将在dt时间内死亡的人数,除以在t时间内存活的人数,得到危险率函数作为衡量在t时刻存活的人的死亡风险的方法。 危险率函数不是密度或概率。然而,假定受试者一直存活到t时刻,可以把它看作是在(t)和(t + dt)之间一个无穷小时间周期内的失败概率。从这个意义上说,危险是一种风险的度量: 在t1和t2时刻间的危险越大,那么在这个时间间隔内失败的风险越大。 因为(s(t) - s(t + dt)) / dt = f (t),则h(t) = f(t) / S(t);这个函数的美妙之处在于,生存函数可以由危险率函数导出,反之亦然。在Cox比例风险模型(本文最后一部分)中,当从给定的危险率函数导出一个生存函数时,这种方法的作用将更加明显。 这些是理解生存分析所需的最重要的数学定义和公式。下面,本文将向前推进到生存曲线的估计。 4 Kaplan-Meier 估计在上面的数学公式中,假设了pdf函数,从而从中推导出了生存函数。由于无法得到真正的种群生存曲线,因此从数据中估计生存曲线将是最好的选择。 估计生存曲线主要有两种方法。 第一种方法是参数方法。这种方法假设一个参数模型,这个模型基于一定的分布,如指数分布,然后估计参数,最后推导出生存函数的估计量。 第二种方法是一种强有力的非参数方法,称为 Kaplan-Meier估计。本文将在这一部分讨论它,并尝试手动得到Kaplan-Meier 曲线,以及使用Python库(lifelines)。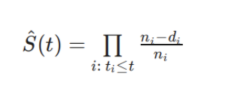 这里,定义ni为在ti时刻前处于危险状态的人口;定义di为在ti时刻之前发生事件的数量。通过下面的例子,这些概念将变得更加清晰。 这里,定义ni为在ti时刻前处于危险状态的人口;定义di为在ti时刻之前发生事件的数量。通过下面的例子,这些概念将变得更加清晰。
本文将使用一个非常小的自创数据,以了解Kaplan Meier估计曲线的创建,以及python库的使用。 示例的事件、时间和时间尺度定义: 下面的例子(见下图)显示了某网站6个用户的数据。这些用户访问该网站,并于几分钟后离开。 因此,关注的事件是用户在网站停留的时间。初始时间定义为用户打开网站的时间,时间尺度以分钟为单位。这项研究从t=0开始,到t=6分钟时结束。截尾: 这里值得注意的是,在研究期间, 6个用户中有4个发生事件(红色显示),而另两个用户(绿色显示)仍在继续,直到研究结束也未发生事件;这样的数据称为截尾数据。 在出现截尾的情况下,比如案例中的用户4和用户5,不知道事件将在什么时候发生,但仍然使用这些数据来估计生存的可能性。如果选择剔除截尾数据,那么估计结果很有可能有较大偏差并且被低估。与其他许多统计技术相比,包含截尾数据来计算估计值,使得生存分析非常强大。知识KM曲线的计算和解释: 创建KM曲线所做的计算(见下图)。在图中,Kaplan Meier估计曲线,x轴为事件发生的时间,y轴是估计的生存概率。 从t=0到t |
 简单来说,
简单来说,【本文地址】