《模式识别》期末考试考题汇总带答案 |
您所在的位置:网站首页 › 武汉理工大学期末考试试卷答案 › 《模式识别》期末考试考题汇总带答案 |
《模式识别》期末考试考题汇总带答案
|
目录 一、名词解释 二、填空题 三、简答题 四、计算题 一、名词解释样本(sample):所研究对象的一个个体。 样本集(sample set):若干样本的集合。 类或类别(class):在所有样本上定义的一个子集,处于同一类的样本在我们所关心的某种性质上是不可区分的,即具有相同的模式。 特征(features):指用于表征样本的观测。 已知样本(known samples):指事先知道类别标号的样本。 未知样本(unknown samples):指类别标号未知但特征已知的样本。 模式识别(pattern recognition):就是用计算的方法根据样本的特征将样本划分到一定的类别中去。 统计模式识别:用概率统计的观点和方法来解决模式识别问题。 贝叶斯决策(统计决策理论):是统计模式识别的基本方法和基础;是“最优分类器”:使平均错误率最小。 最小风险贝叶斯决策:最小错误率只考虑了错误,进一步可考虑不同错误所带来的损失(代价)。 Neyman-Pearson 决策规则:限定一类错误率为常数而使另一类错误率最小的决策。 参数估计(parametric estimation):已知概率密度函数的形式,只是其中几个参数未知,目标是根据样本估计这些参数的值。 非参数估计:在一些情况下我们无法实现判断数据的分布情况。 统计量(statistics):样本的某种函数,用来作为对某参数的估计 。 参数空间(parametric space):待估计参数的取值空间 。 估计量(estimation): 贝叶斯估计:思路与贝叶斯决策类似,只是离散的决策状态变成了连续的估计。 最优超平面:一个超平面,如果它能够将训练样本没有错误地分开,并且两类训练样本中离超平面最近的样本与超平面之间的距离是最大的,则我们把这个超平面称作最优分类超平面(Optimal Seperating Hyperplane),简称最优超平面(Optimal Hyperplane)。两类样本中离分类面最近的样本到分类面的距离称作分类间隔(margin),最优超平面也称作最大间隔超平面。 特征形成(特征获取、提取):直接观测到的或经过初步运算的特征——原始特征 。 特征选择 :从 特征提取(特征变换,特征压缩):将 特征的评价准则:特征选择与提取的任务是找出一组对分类最好的特征。 二、填空题1、解决模式识别的方法可以归纳为基于知识的方法和基于数据的方法两大类。 2、一个模式识别问题往往包括以下五个阶段:问题的提出和定义、数据获取和预处理、特征提取和选择、分类器设计和性能评估、分类及结果解释。 3、模式识别应用举例:语音识别、说话人识别、字符与文字识别、复杂图像中特定目标的识别、根据地震勘探数据对地下储层性质的识别、利用基因表达数据进行癌症分类。 4、统计决策基本原理:根据各类特征的概率模型来估算后验概率,通过比较后验概率进行决策。 5、第一类错误率(Type-I error rate) 6、ROC曲线(ROC Curve)纵坐标:真阳性率(灵敏度);横坐标:假阳性率(1-特异度)。 7、估计概率密度的两种基本方法:参数方法 (parametric methods)和非参数方法 (nonparametric methods)。 8、贝叶斯估计基本思想:把待估计参数 9、从基于概率密度(估计)的分类器设计到基于样本的直接分类器设计思路: 首先选定判别函数类和一定的目标(准则),利用样本集确定出函数类中的某些未知参数,使所选的准则最好。 10、基于样本直接设计分类器需要确定三个基本要素:一是分类器即判别函数的类型、二是分类器设计的目标或准则、三是在前两个要素明确后,如何设计算法利用样本数据搜索到最优的函数参数(即选择函数集中的函数)。 11、非线性分类器包括分段线性分类器、二次判别函数、神经网络和支持向量机等。 12、线性分类器包括Fisher线性判别器、感知器、最小平方误差判别器、最优分类超平面、线性支持向量机。 13、主成分分析目的:出发点是从一组特征中计算出一组按重要性从大到小排列的新特征,它们是原有特征的线性组合,并且相互之间是不相关的。 三、简答题1、简述模式识别系统的典型构成。 有已知样本情况:监督模式识别(supervised PR) :已知要划分的类别,并且能够获得一定数量的类别已知的训练样本, 这种情况下建立分类器的问题属于监督学习问题,程总做监督模式识别,因为我们有训练样本来作为学习过程的"导师"。
处理监督模式识别问题的一般步骤: · 分析问题:深入研究应用领域的问题,分析是否属于模式识别问题,把所研究的目标表示为一定的类别,分析给定数据或者可以观测的数据中哪些因素可能与分类有关。 · 原始特征获取:设计实验,得到已知样本,对样本实施观测和预处理,获取可能与样本分类有关的观测向量(原始特征)。 · 特征提取与选择:为了更好地进行分类,可能需要采用一定的算法对特征进行再次提取和选择。 · 分类器设计:选定一定的分类器方法,用已知样本进行分类器训练。 · 分类决策:利用一定的算法对分类器性能进行评价;对未知样本实施同样的观测、预处理和特征提取与选择,用所设计的分类器进行分类,必要时根据领域知识进行进一步的后处理。 无已知样本情况:非监督模式识别(unsupervised PR):非监督模式识别称作聚类,在很多非监督模式识别问题中,答案并不一定是唯一的,特点是由于没有类别已知的训练样本,在没有其他额外信息的情况下,采用不同的方法和不同的假定可能会导致不同的结果。 2、简述最大似然函数的假设条件和基本思想 假设条件: ① 参数 3、简述求贝叶斯估计的方法(平方误差损失下) (1)确定 4、简述概率密度估计的非参数方法 ①直方图方法 非参数概率密度估计的最简单方法 (1)把 5、简述Fisher 准则函数 把线性分类器的设计分为两步:一是确定最优的方向, 二是在这个方向,上确定分类阈值。 两类的线性判别问题可以看做是把所有样本都投影到一一个方向上,然后在这个一维空间中确定一个分类的阈值。过这个阈值点且与投影方向垂直的超平面就是两类的分类面。 思想:选择投影方向,使投影后两类相隔尽可能远,而同时每一-类内部的样本又尽可能聚集。 Flsher判别函数最优解本身只是给出了-一个投影方向, 并没有给出我们所要的分类面。要得到分类面,需要在投影后的方向(一维空间)上确定一个分类阈值 6、简述固定增量法 (1)初值 7、简述特征的评价准则 ①基于类内类间距离的可分性判据 特点: 直观,易于实现(用样本计算),较常用。 不能确切表明各类分布重叠情况,与错误率无直接联系。 当各类协差相差不大时,用此种判据较好。 ②基于概率分布的可分性判据 考查两类分布密度之间的交叠程度 考查联合分布密度 8、简述分支定界算法 从顶向下,有回溯 应用条件:准则函数有单调性
|


 处理非监督模式识别问题的一般步骤: · 分析问题:深入研究应用领域的问题,分析研究目标能否通过寻找适当的聚类来达到;如果可能,猜测可能的或希望的类别数目;分析给定数据或者可以观测的数据中哪些因素可能与聚类有关。 · 原始特征获取:设计实验,得到待分析的样本,对样本实施观测和预处理,获取可能与样本聚类有关的观测向量(原始特征)。 · 特征提取与选择:为了更好地进行聚类,可能需要采用一定的算法对特征进行再次提取和选择。 · 聚类分析:选定一定的非监督模式识别方法,用样本进行聚类分析。 · 结果解释:考察聚类结果的性能,分析所得聚类与研究目标之间的关系,根据领域知识分析结果的合理性,对聚类的含义给出解释;如果有新样本,把聚类结果用于新样本分类。
处理非监督模式识别问题的一般步骤: · 分析问题:深入研究应用领域的问题,分析研究目标能否通过寻找适当的聚类来达到;如果可能,猜测可能的或希望的类别数目;分析给定数据或者可以观测的数据中哪些因素可能与聚类有关。 · 原始特征获取:设计实验,得到待分析的样本,对样本实施观测和预处理,获取可能与样本聚类有关的观测向量(原始特征)。 · 特征提取与选择:为了更好地进行聚类,可能需要采用一定的算法对特征进行再次提取和选择。 · 聚类分析:选定一定的非监督模式识别方法,用样本进行聚类分析。 · 结果解释:考察聚类结果的性能,分析所得聚类与研究目标之间的关系,根据领域知识分析结果的合理性,对聚类的含义给出解释;如果有新样本,把聚类结果用于新样本分类。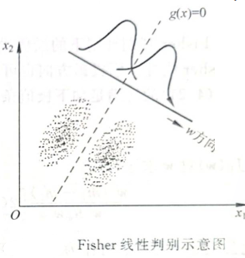
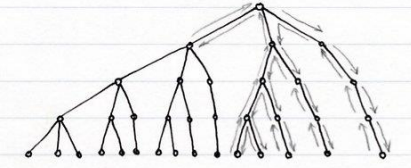 基本思想:按照一定的顺序将所有可能的组合排成一棵树,沿树进行搜索,避免一些不必要的计算,使找到最优解的机会最早。 特点: ① 最优搜索算法,所有可能的组合都被考虑到 ② 前提:准则函数单调性 (注:实际中可能不满足,因 是估计值) ③ 节约计算与存储 ④
基本思想:按照一定的顺序将所有可能的组合排成一棵树,沿树进行搜索,避免一些不必要的计算,使找到最优解的机会最早。 特点: ① 最优搜索算法,所有可能的组合都被考虑到 ② 前提:准则函数单调性 (注:实际中可能不满足,因 是估计值) ③ 节约计算与存储 ④ 


【本文地址】
今日新闻 |
推荐新闻 |