【论文必用】模糊C均值聚类的简单介绍、复现及Python代码详解、聚类可视化图的绘制过程详解! |
您所在的位置:网站首页 › 模糊聚类原理 › 【论文必用】模糊C均值聚类的简单介绍、复现及Python代码详解、聚类可视化图的绘制过程详解! |
【论文必用】模糊C均值聚类的简单介绍、复现及Python代码详解、聚类可视化图的绘制过程详解!
|
详解模糊C均值聚类
一、聚类二、模糊C均值聚类三、模糊C均值聚类的Python实现四、参考链接
一、聚类
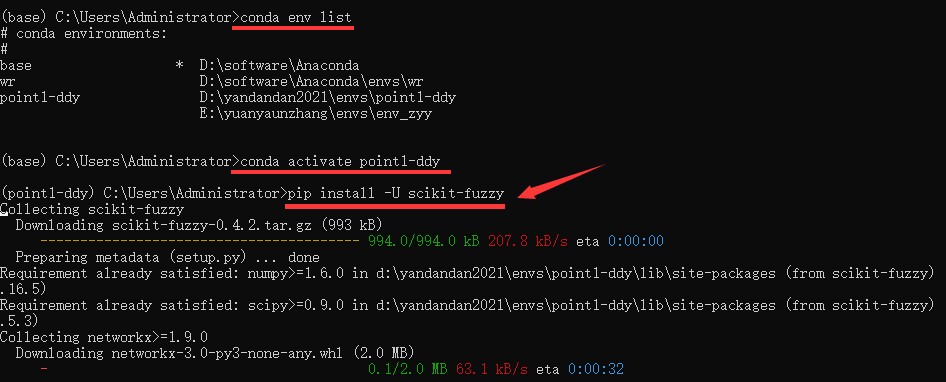
聚类的定义: 将物理或抽象对象的集合分成由类似的对象组成的多个类的过程被称为聚类。由聚类所生成的簇是一组数据对象的集合,这些对象与同一个簇中的对象彼此相似,与其它簇中的对象相异。聚类分析起源于分类学,但是聚类不等于分类。聚类与分类的不同在于,聚类所要求划分的类是未知的。 聚类可以是硬聚类,也可以是软聚类。 在硬聚类中,每个对象被确定地归入一个簇;在软聚类中,每个对象与每个簇都存在一定的从属程度(隶属度),只不过该程度有大有小。 本博客主要为大家讲解软聚类中的模糊C均值聚类(Fuzzy C-means Clustering, FCM)。 二、模糊C均值聚类模糊C均值聚类(Fuzzy C-means Clustering, FCM),是一种引入模糊理论的聚类算法。在该算法中,用隶属度来表示一个样本属于某一类的概率,因为在许多情况下,多个类别的界限并不绝对。相比于如K-means的硬聚类,FCM得到的聚类结果更加灵活。 FCM通过最小化如下目标函数来实现聚类。 其中,N表示样本个数,C表示聚类中心个数,m是一个隶属度因子,可以取2,3等的值,表示样本属不属于某类的重要程度,uij表示样本i对于类j的隶属度。 由第一个公式可知,目标函数由相应样本的隶属度与该样本到各个类中心的距离相乘组成。第二个公式主要在说,样本对各个类的隶属度之和要为1。 具体地,目标函数的优化过程可点这里查看。不过,如果你的目的是“会用就行”,那么也可以不看这个优化推导过程,直接看本博客第三部分吧。 三、模糊C均值聚类的Python实现1.首先安装【scikit-fuzzy】包,具体命令如下:(注,笔者先进入自己的虚拟环境,然后安装的该包。)
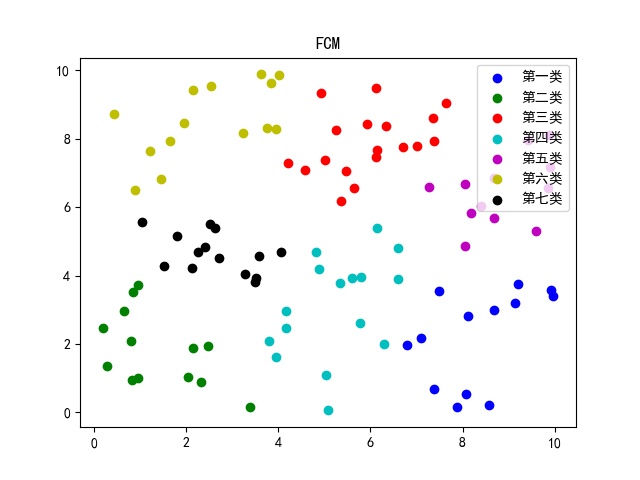
2.调用模糊C均值函数cmeans对100个样本点进行模糊聚类,代码如下: import numpy as np import matplotlib; matplotlib.use('TkAgg') from skfuzzy.cluster import cmeans from sklearn.metrics import silhouette_score import matplotlib.pyplot as plt color = ['b', 'g', 'r', 'c', 'm', 'y', 'k'] # 为7个类别设置了7种颜色 x = 10 * np.random.rand(100, 2) # (100, 2) 100个二维坐标 即100个样本点 # 调用模糊C均值聚类函数cmeans center, u, u0, d, jm, p, fpc = cmeans(x.T, m=2, c=7, error=0.5, maxiter=10000) """ 输入信息: x.T为待聚类样本。这里需要注意格式,其形状是类似于(特征数目,样本个数),与很多训练样本数据的形状正好是相反的。 m为隶属度指数,是一个加权指数。 c为待指定的聚类个数。 error指当隶属度的变化小于此时提前迭代结束。 maxiter表示最大迭代次数 """ """ 输出信息: center为聚类的中心 7*2 u为隶属度矩阵 7*100 u0为初始化的隶属度矩阵 7*100 d为每个数据点到各个中心的欧氏距离矩阵 7*100 jm是目标函数的优化历史 p是迭代的次数 fpc全称是fuzzy partition coefficient,是一个评价分类好坏的指标。它的范围是0到1,1是效果最好,后面可以通过它来选择聚类的个数。 """ label = np.argmax(u,axis=0) # 根据最大隶属度来确定所属类别 plt.rcParams['font.sans-serif']=['SimHei'] # 使得plt可以显示中文 ex = ['第一类','第二类','第三类','第四类','第五类','第六类','第七类'] for i,col in enumerate(list('bgrcmyk')): plt.scatter([],[],c=col,label=ex[i]) # 绘制散点 plt.legend(loc='upper right') # 在右上角创建图例 for i in range(100): # 100为样本数 plt.plot(x[i, 0], x[i, -1], color[label[i]] + 'o') # 关于plt.xticks和plt.yticks的用法可参考 # https://blog.csdn.net/weixin_50345615/article/details/126193271 # 总之,plt绘制图像默认坐标轴仅显示偶数刻度及其对应的文本标签 # plt.xticks(range(-20,20,1)) # 修改横坐标刻度 # plt.yticks(range(-20,20,1)) # 修改纵坐标刻度 # plt.xlabel('x') # 设置横坐标的标签 # plt.ylabel('y') # 设置纵坐标的标签 plt.title('FCM') # 设置图像的标题 plt.savefig(r'.\fcm.jpg',format='jpg') # 保存聚类结果图 plt.show() # 展示图像 # 如果plt.show()不显示图像,则参考网址https://blog.csdn.net/qq_28019591/article/details/89404773进行解决3.结果展示 4.相关说明 上面这个代码,主要是 随机创建了100个二维样本点,然后使用FCM将这100个样本点分为7类,并绘制可视化图。笔者在代码里详细注释了cmeans函数的输入、输出参数,及绘制可视化图过程中的各个语句含义。希望大家动手实践一下,真的很容易理解! 四、参考链接▶模糊C均值聚类的介绍1:https://blog.csdn.net/coolyuan/article/details/107515224 ▶模糊C均值聚类的介绍2:https://blog.csdn.net/weixin_48241292/article/details/110291536 ▶cmeans函数介绍:https://blog.csdn.net/FrankieHello/article/details/79581315 ▶cmeans函数实战:https://blog.csdn.net/qq_39709813/article/details/106895486 最后,如果本文对您有所帮助,欢迎关注博主主页,并订阅本专栏。本专栏主要记录笔者在写论文过程中编写的各种可视化代码,例如聚类可视化、混淆矩阵的可视化等,欢迎大家订阅! |
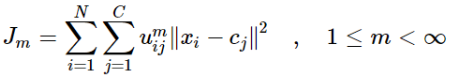
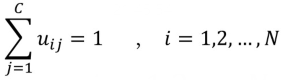
【本文地址】
今日新闻 |
推荐新闻 |