深度学习基础之GFLOPS(2) |
您所在的位置:网站首页 › 模拟器cpu越高越好吗 › 深度学习基础之GFLOPS(2) |
深度学习基础之GFLOPS(2)
|
什么是GFLOPS
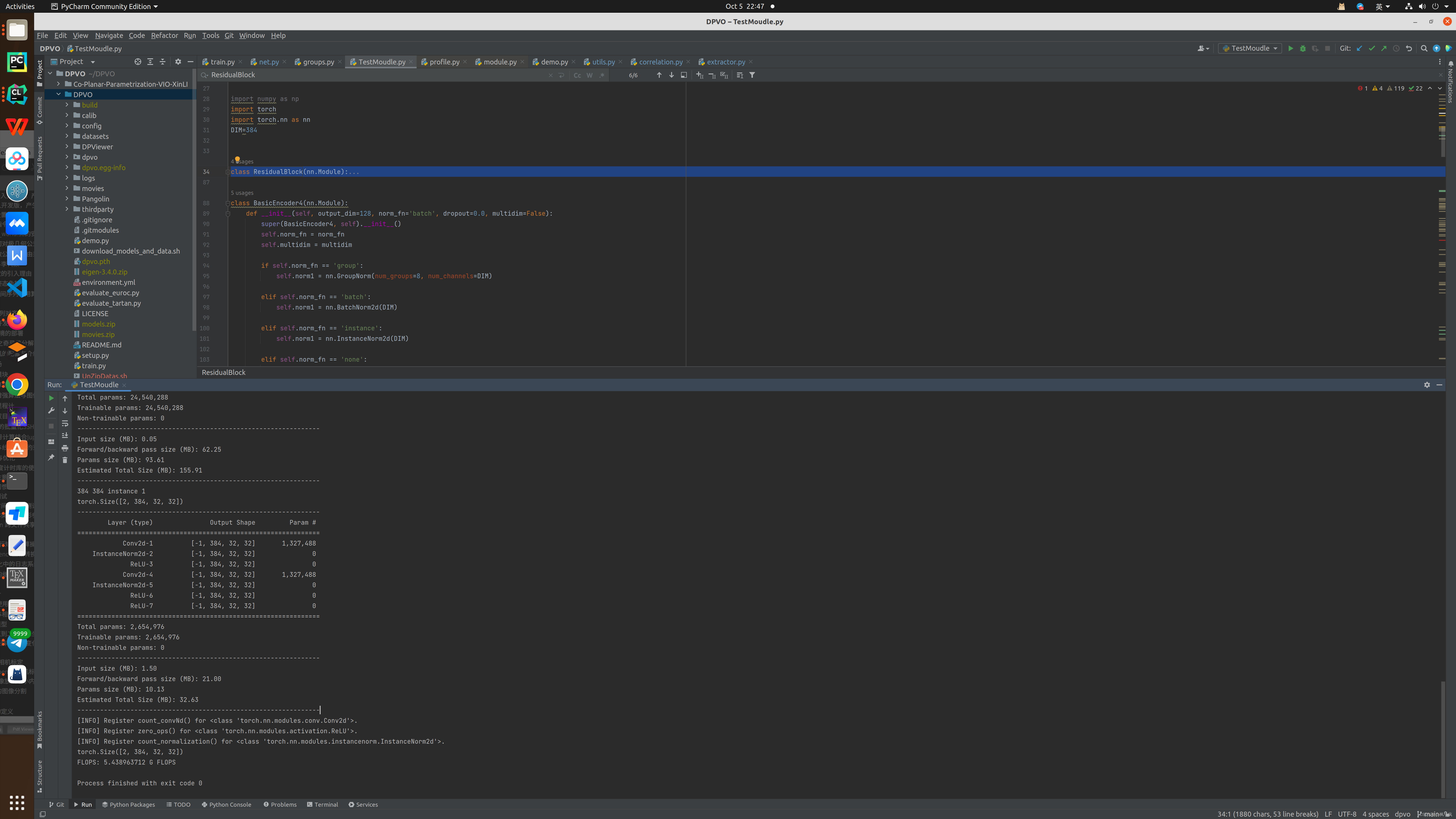
神经网络的GFLOPS(Giga FLoating-Point Operations Per Second)代表了神经网络模型执行计算的速度和计算能力。这可以用一个类比来解释: GFLOPS就像神经网络模型的"运算速度"标签。 想象你有两个数学家,他们都能够解决复杂的数学问题,但一个速度非常快,另一个速度较慢。GFLOPS就像用来衡量他们速度的标尺。 数学家A的GFLOPS是10,这意味着他每秒钟可以解决10亿个数学问题。 数学家B的GFLOPS是100,这意味着他每秒钟可以解决100亿个数学问题,比数学家A更快。 在神经网络中,GFLOPS告诉我们模型在执行训练或推理任务时,每秒可以进行多少次复杂的数学计算。较高的GFLOPS值通常表示模型能够更快地处理数据,因此在训练和推理任务中更高效。 总之,GFLOPS是用来衡量神经网络模型计算速度和能力的指标,就像速度标尺一样,它告诉我们模型有多快。 相同神经网络在不同的机器上的GFLOPS差异同一个神经网络在不同的英伟达(NVIDIA)GPU上的GFLOPS值通常会有一定差异,因为不同型号的GPU具有不同的硬件架构和计算单元配置。这些因素会影响计算能力和速度,从而导致GFLOPS值的差异。 主要影响GFLOPS值差异的因素包括: GPU型号:不同型号的英伟达GPU具有不同的硬件特性和计算单元配置。较新的GPU型号通常具有更多的计算单元和更高的时钟速度,因此其GFLOPS值可能更高。 核心数量:GPU的核心数量是一个关键因素。较高端的GPU通常具有更多的计算核心,因此可以执行更多的并行计算,从而获得更高的GFLOPS值。 时钟速度:GPU的时钟速度也影响计算速度。较高的时钟速度可以加速计算过程,提高GFLOPS值。 架构改进:不同GPU架构可能会引入不同的改进,如更高效的计算单元或存储层次结构,从而影响GFLOPS值。 因此,即使是同一家制造商的不同GPU型号,也会在GFLOPS值上有所不同。这对于选择适合特定任务的GPU或进行性能优化非常重要。如果你需要确定特定GPU的GFLOPS值,可以查找该GPU型号的技术规格或使用NVIDIA的官方工具来获取详细信息。 GFLOPS代码示例与计算结果 class ResidualBlock(nn.Module): def __init__(self, in_planes, planes, norm_fn='group', stride=1): super(ResidualBlock, self).__init__() print(in_planes, planes, norm_fn, stride) self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=3, padding=1, stride=stride) self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, padding=1) self.relu = nn.ReLU(inplace=True) num_groups = planes // 8 if norm_fn == 'group': self.norm1 = nn.GroupNorm(num_groups=num_groups, num_channels=planes) self.norm2 = nn.GroupNorm(num_groups=num_groups, num_channels=planes) if not stride == 1: self.norm3 = nn.GroupNorm(num_groups=num_groups, num_channels=planes) elif norm_fn == 'batch': self.norm1 = nn.BatchNorm2d(planes) self.norm2 = nn.BatchNorm2d(planes) if not stride == 1: self.norm3 = nn.BatchNorm2d(planes) elif norm_fn == 'instance': self.norm1 = nn.InstanceNorm2d(planes) self.norm2 = nn.InstanceNorm2d(planes) if not stride == 1: self.norm3 = nn.InstanceNorm2d(planes) elif norm_fn == 'none': self.norm1 = nn.Sequential() self.norm2 = nn.Sequential() if not stride == 1: self.norm3 = nn.Sequential() if stride == 1: self.downsample = None else: self.downsample = nn.Sequential( nn.Conv2d(in_planes, planes, kernel_size=1, stride=stride), self.norm3) def forward(self, x): print(x.shape) #exit() y = x y = self.relu(self.norm1(self.conv1(y))) y = self.relu(self.norm2(self.conv2(y))) if self.downsample is not None: x = self.downsample(x) return self.relu(x + y) R=ResidualBlock(384, 384, norm_fn='instance', stride=1) summary(R.to("cuda" if torch.cuda.is_available() else "cpu"), (384, 32, 32)) import torch from thop import profile # 定义示例输入数据形状,符合模型的期望形状 batch_size = 2 num_channels = 384 height = 32 width = 32 # 生成示例输入数据,注意将其形状调整为符合模型要求的形状,并将其移到相同设备上 input_data = torch.randn(batch_size, num_channels, height, width).to("cuda" if torch.cuda.is_available() else "cpu") # 使用thop进行FLOPS估算 flops, params = profile(R.to(input_data.device), inputs=(input_data,)) print(f"FLOPS: {flops / 1e9} G FLOPS") # 打印FLOPS,以十亿FLOPS(GFLOPS)为单位 GFLOPS 的结果
|
【本文地址】
今日新闻 |
推荐新闻 |