概率和统计是一回事么? |
您所在的位置:网站首页 › 概率和统计的关系 › 概率和统计是一回事么? |
概率和统计是一回事么?
|
文章福利:Python学习精选书籍10本 统计、概率傻傻分不清?其实从下图中就应该知道概率、统计是有区别的
本话题主要是为了后续讨论与理解最大似然估计(MLE)、最大后验概率估计(MAP)贝叶斯公式做基础。本篇我们只讨论概率与统计之间的区别。 为了更通俗的理解,先来讨论统计,为什么呢?因为概率可以理解为在统计基础上衍生出来的。 什么是统计(statistics) 先来看个问题:有一种动物,请问这是什么动物(答案唯一)? 这...没人能猜得对吧。我也猜不出来,即便是天王老子来了也猜不出来。加个条件,它一天24小时只干两件事(干饭、睡觉),请问这是什么动物? 咦,这不是你女朋友么?(开玩笑)
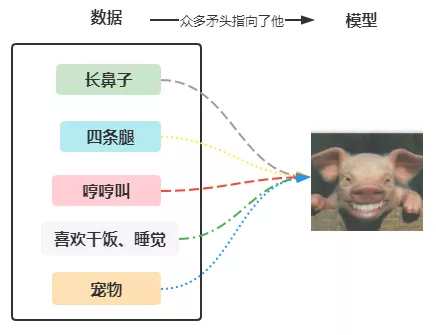
嘘,别瞎猜,要不然狗命不保。 那么再加些条件:四条腿、还会哼哼哼的叫,鼻子长长的,有的还可以当宠物。 嗯,模型基本可以确定了,对,就是他
我们仔细想想这个过程,你是怎么猜出它来的。 我们有一堆数据,动物、四条腿、鼻子(长长的)、叫声(哼哼哼)、行为(干饭、睡觉),通过判断与观察这些数据,大伙一致的认为并且确定这个模型是猪。
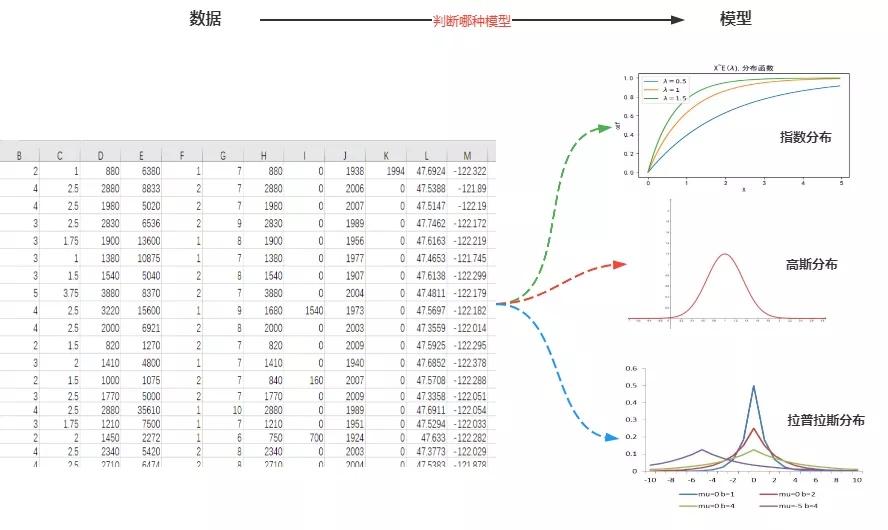
这个游戏和统计有什么关系呢?在实际的统计研究中,我们也是通过观察数据来初步推测模型的。 就像文章 建立回归模型的完整步骤 中提到的,我们通过数据的散点图走势分布来判断是否使用线性回归模型,当然通过数据还可以判断出其他分布模型:像指数分布、高斯分布、拉普拉斯分布。
当然,如果上述游戏的模型参数、数据量再给多点我们甚至可以研究归纳出:判定猪的品种模型,究竟是圈养猪呢还是松辽黑猪呢还是乌克兰小乳猪。 (此模型只做演示说明使用,并非真正的模型)
其中,y 是猪的种类,x1为产地 ,x2为大小,x3为可爱程度... 再举一个更加实际的栗子:当我们去医院看病的时候,医生通过询问你的症状(饮食、不良行为....)来判断归纳(建立病症模型)出什么病,最后才对症下药。 以上案例都是建立在人们熟知的模型上去做判断,若是一种新的物种、病情呢?通过数据无法从已有模型中挑选出对应模型怎么办,这个时候就进入了统计的原始阶段,需要大量数据、案例做支撑,然后发明一个新的模型,不断演化直到成熟被公认。 一句话总结:统计是在已知数据的前提下,进行模型的归纳与推断。 什么是概率(probabilty) 概率研究的问题恰好与统计相反,概率是在已知模型的基础上去预测这个模型产生的结果(方差、均值等)。如:现在我们有一个已知模型(判断猪的种类模型)
其中,y 是猪的种类,x1为产地, x2为大小 ,x3为可爱程度,.... 故事线:现在有一个人在山间上发现一只猪,但又不确定是什么猪,万一是只野猪(凶猛)那就不好了,正巧他想起外甥是养猪协会的,他急忙给外甥打电话,并告知外甥这个猪的一些特征,balabala.....,外甥经过他多年悦猪无数的职场经验(脑海已模型自现),立马就判断出这只猪的品种,原来是只乌克兰小乳猪啊,很可爱不用担心,真是虚惊一场。 这个过程我们可以简化为:通过种类模型我们预测出来了符合条件的样本数据(猪的特征)属于哪一种猪 【极大概率上】 注:对于已成熟的模型(已通过模型有效性检验:R方、F检验)预测结果在极大概率上是可靠的。 一句话总结:概率是在已知模型的基础上,对其他样本数据进行预测。 还记得在讨论回归话题时的这幅图么
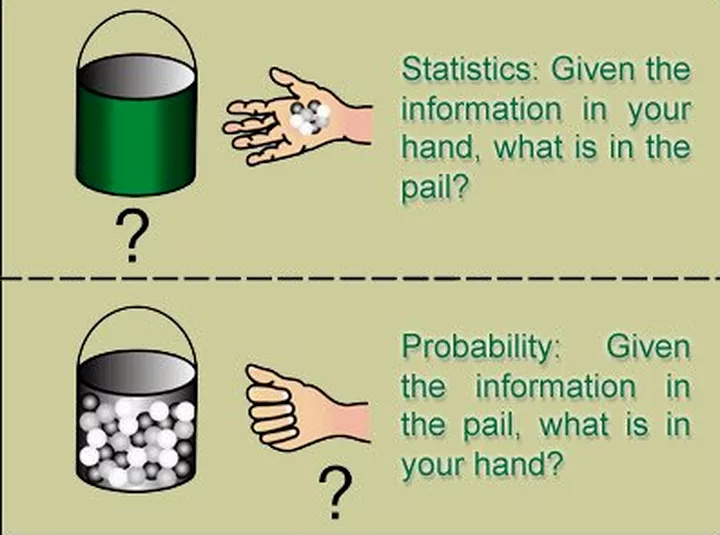
在统计学里,任一现存的技术手段都是经历了统计与概率的考验才留下来,最终形成一个闭环(仅个人见解)。 最后借用专家的话来解释总结下: Lary Wasserman 在 《All of Statistics》 的序言里有说过概率论和统计推断的区别:
大意: 统计学:根据手中信息,猜猜桶里有啥?(样本归纳总结出总体) 概率论:根据桶中信息,猜猜手里有啥?(总体对样本进行预测) 更多精彩内容请关注 公众号:数据与编程之美 原文地址:概率和统计是一回事么? |


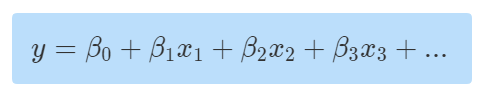
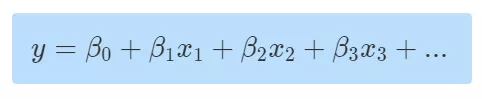

【本文地址】
今日新闻 |
推荐新闻 |