python中利用Sklearn和Scipy分别实现核密度估计 |
您所在的位置:网站首页 › 核函数表达式 › python中利用Sklearn和Scipy分别实现核密度估计 |
python中利用Sklearn和Scipy分别实现核密度估计
|
密度估计问题
由给定样本集合求解随机变量的分布密度函数问题是概率统计学的基本问题之一。解决这一问题的方法有参数估计和非参数估计。非参数估计包含核密度估计。 离散型随机变量概率函数:就是用函数的形式来表达概率; 概率分布: 概率分布函数(简称分布函数):就是概率函数取值的累加结果,所以它又叫累积概率函数、累积概率分布、累积分布函数。 连续型随机变量概率函数又称为概率密度函数,某点的概率密度即为概率在该点的变化率; 概率密度函数是分布函数的导函数。 Sklearn实现核密度估计Sklearn中实现核密度估计的方法:均匀核函数、三角核函数、伽马核函数、高斯核函数等。 以高斯核密度估计为例画出概率密度函数曲线(连续变量): import numpy as np import matplotlib.pyplot as plt from sklearn.neighbors.kde import KernelDensity # 导入核密度估计 X = X.reshape(-1, 1) # 转换成2D array X_plot = np.linspace(0, 0.1, 1000)[:, np.newaxis] # [:,np.newaxis] # 也能转换成2D array kde = KernelDensity(kernel='gaussian', bandwidth=0.75).fit(X) # 高斯核密度估计 log_dens = kde.score_samples(X_plot) # 返回的是点x对应概率密度的log值,需要使用exp求指数还原 ##params=kde.get_params() plt.figure(figsize = (10, 8)) # 设置画布大小 plt.plot(X_plot, np.exp(log_dens), marker='.', linewidth=1, c="b", label='核密度值') plt.tick_params(labelsize = 20) # 设置坐标刻度值的大小 font = {'size': 20} # 设置横纵坐标的名称以及对应字体格式、大小 plt.xlabel('变量', font) plt.ylabel('概率密度函数', font) plt.legend(fontsize = 15) # 显示图例,设置图例字体大小 plt.show() Scipy实现核密度估计以高斯核密度估计为例画出概率密度函数曲线(连续变量): import numpy as np import matplotlib.pyplot as plt import scipy.stats as st plt.figure(figsize = (10, 8)) X = np.array(X) # 转化为1D array scipy_kde = st.gaussian_kde(X) # 高斯核密度估计 X.sort() '''这三种方法都可以得到估计的概率密度''' dens = scipy_kde.evaluate(X) #dens1=scipy_kde.pdf(X) # pdf求概率密度 #dens2=scipy_kde(X) plt.plot(X, dens, c='green', label='核密度值') plt.tick_params(labelsize = 20) # 设置坐标刻度值的大小 font = {'size': 20} # 设置横纵坐标的名称以及对应字体格式、大小 plt.xlabel('变量', font) plt.ylabel('概率密度函数', font) plt.legend(fontsize = 15) # 显示图例,设置图例字体大小 plt.show() '''画累积概率分布曲线''' plt.figure(figsize = (10, 8)) X_integrate = [] # 存放所有点的累积概率 X_integrate.append(0) # 第一个值是0 point = 0 # 存放单个累积概率 for i in range(1, len(X)): point = point + scipy_kde.integrate_box_1d(X[i-1], X[i]) # scipy_kde.integrate_box_1d()函数的作用是计算两个边界之间的一维概率密度函数的积分,实质上得到的是概率值 X_integrate.append(point) plt.plot(X, X_integrate, c='blue', label='累积概率') plt.tick_params(labelsize = 20) font = {'size': 20} plt.xlabel('变量', font) plt.ylabel('概率分布函数', font) plt.legend(fontsize = 15) plt.show() |
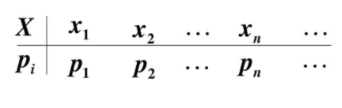
【本文地址】