Class 08 |
您所在的位置:网站首页 › 查看rstudio自带数据集 › Class 08 |
Class 08
|
Class 08 - 数据的读取和保存 & R语言中的管道(pip)功能
数据的读取和保存data() - 加载R中的数据集readr 功能包介绍readr 包中读取文件的函数read_csv() 读取 .csv 文件
readxl 包读取Excel文件read_excel() - 读取Excel文件excel_sheets() - 读取Excel中sheet名称
R语言中的管道(pipe)功能
数据的读取和保存
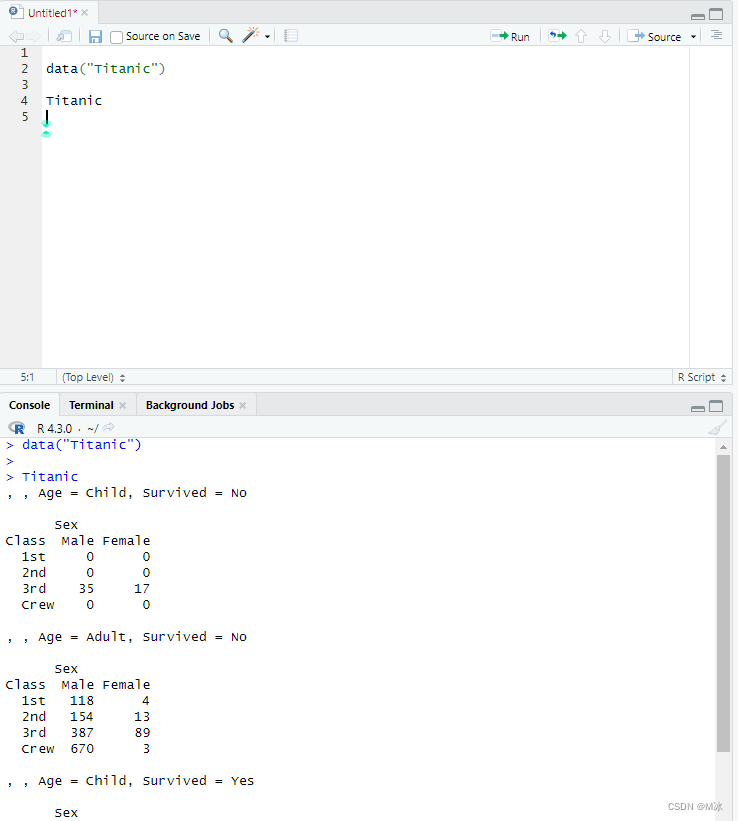
这部分用来介绍在R语言中一些常用文件的读取和保存,如最常见的csv文件、Excel文件。 还会介绍如何加载R语言中集成的数据集。 data() - 加载R中的数据集R语言本身会集成一些数据集,可以用来联系R语言,比如“Titanic”(泰坦尼克数据)、“iris”(鸢尾花数据)等在许多数据分析或者机器学习中用到的数据集。 在R语言中可以直接使用 data() ,在括号中输入对应的数据集名称,加载这些数据集。 例如:data(Titanic) 加载Titanic(泰坦尼克数据集)。 data(Titanic)
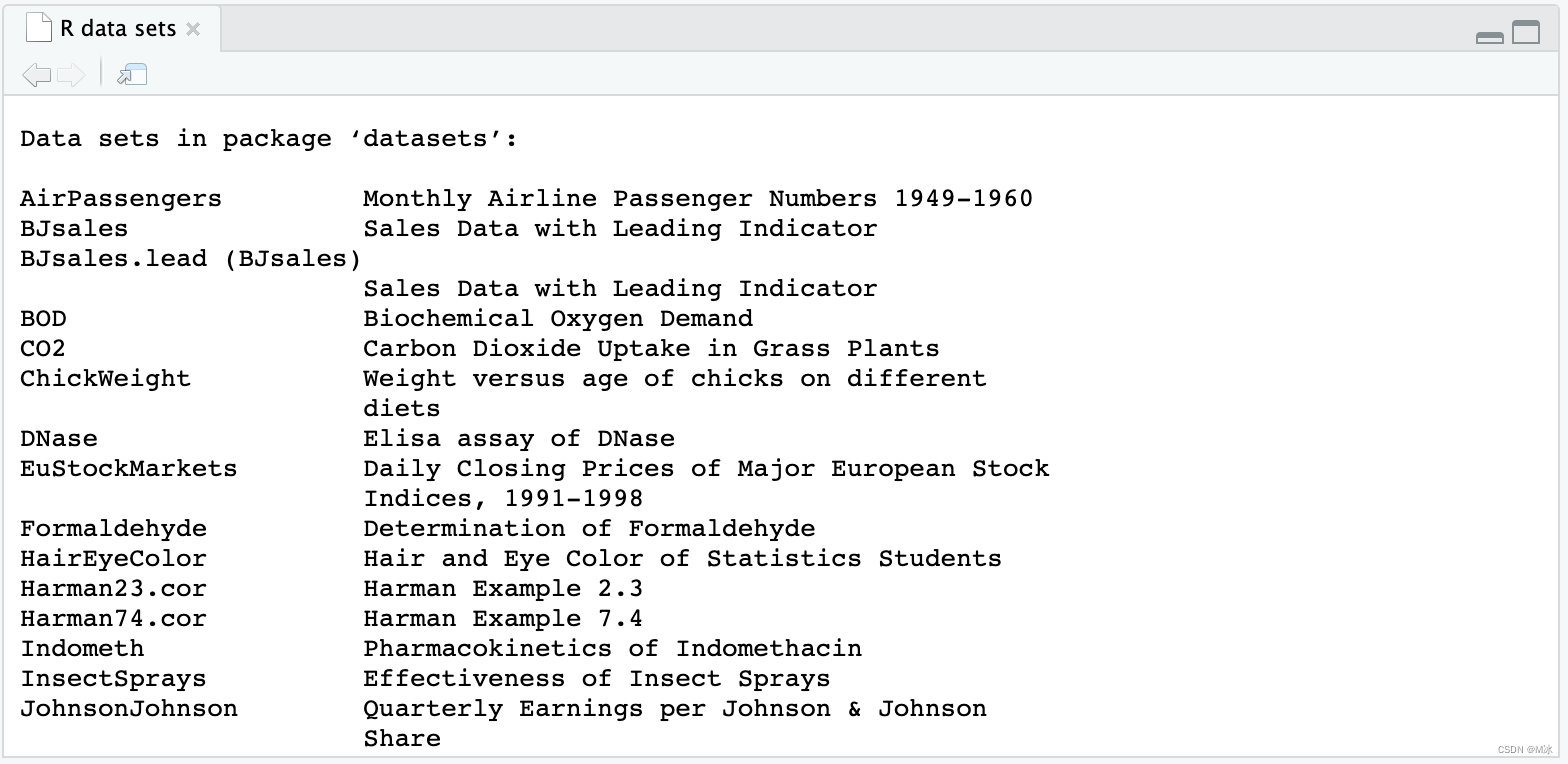
现在数据集已加载,您可以在 R 控制台窗格中预览它。 只需输入它的名字 Titanic然后运行,在下面控制台区域就会显示数据集的数据信息。 如果直接运行data()函数本身,不在括号中指定数据集,R 将显示可用数据集的列表。 data()输出如下:
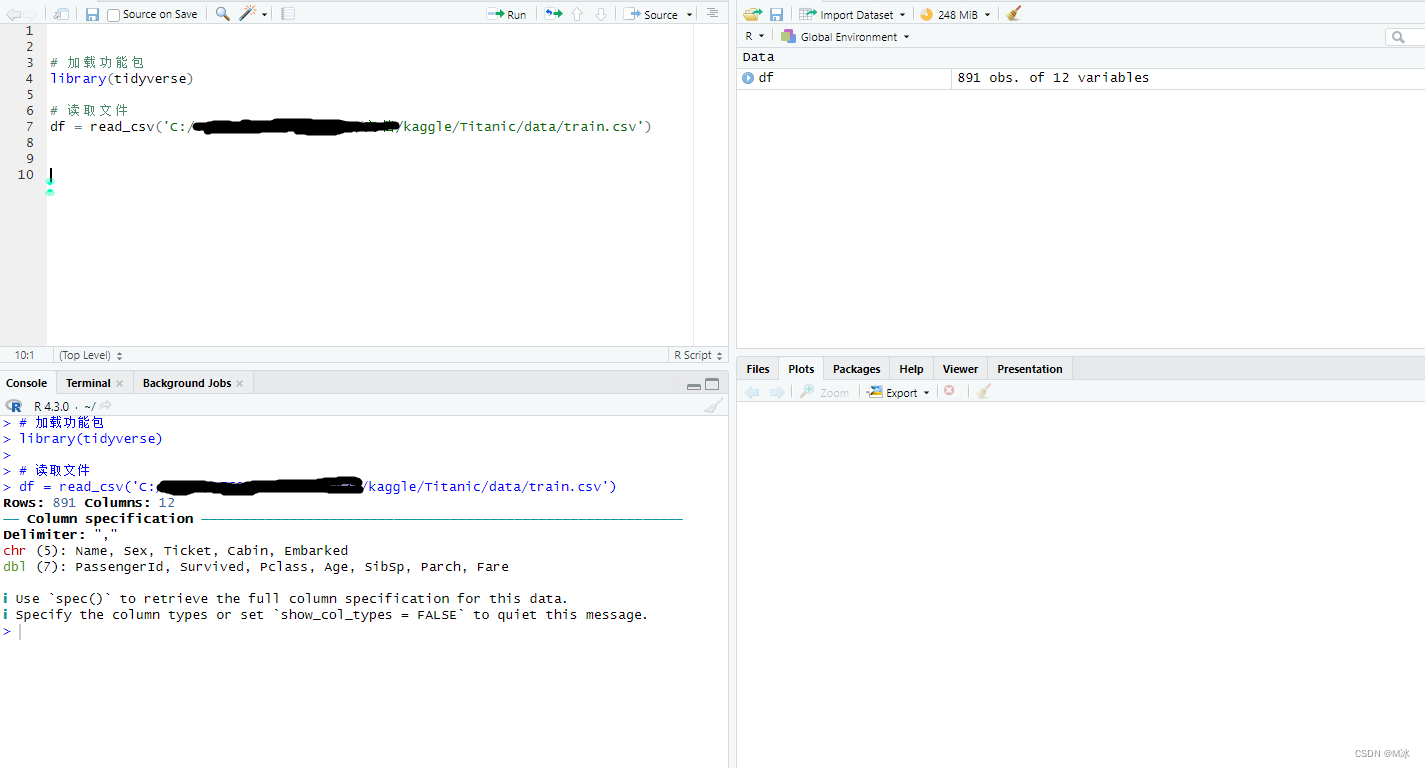
可以尝试使用列表中的其他数据集来进行不同的练习和测试。 readr 功能包介绍上面介绍了如何加载R语言内置的数据集,这些内置的数据集一般都是用来做数据分析的练习来使用的。 在实际工作中,分析的数据都是从数据库或者其他地方整理过的数据,大部分都是需要从本地电脑中导入的,那么下面就介绍如何使用readr功能包来读取文件。 readr 功能包是 tidyverse 功能包 的一个核心功能包。 如果你已经安装了 tidyverse,就可以直接开始使用 readr 中的功能函数了。 如果没有安装,可以参考前面文章来安装 tidyverse。 readr 包中读取文件的函数readr 的目标是提供一种快速且友好的方式来读取数据。 readr 支持多种 read_ 函数。 每个函数都指定读取特定的文件格式。 read_csv():逗号分隔值 (.csv) 文件 read_tsv():制表符分隔值文件 read_delim():一般分隔文件 read_fwf():固定宽度的文件 read_table():表格文件,其中列由空格分隔 read_log():网络日志文件 这些函数的使用方法都比较相似,所以只要学会了如何使用其中的一个,就可以将其的应用到其他类似的函数中。 我们重点了解read_csv()函数,因为 .csv 文件是工作和学习中最常见的数据存储形式之一,尤其在数据分析工作中,将经常使用它们。 read_csv() 读取 .csv 文件首先我们准备一个需要读取的csv文件,比如在 kaggle 网站中下载的 Titanic 数据集。 首先我们来加载library(tidyverse) 功能包(不加载就会找不到read_csv() 这个函数),然后就可以使用 read_csv() 函数去读取文件了。 我们可以把读取的数据指定一个名称,这样方便在后续的代码中去调用。 举个例子: 先输入read_csv(),然后在括号中,您需要提供文件的路径(需要注意此处文件路径使用/来分割,不是用\来分割的)。 # 加载功能包 library(tidyverse) # 读取文件 df = read_csv('C:/kaggle/Titanic/data/train.csv')当运行该函数时,R 会打印出一个说明,并且右边环境中也有了设置好的函数。
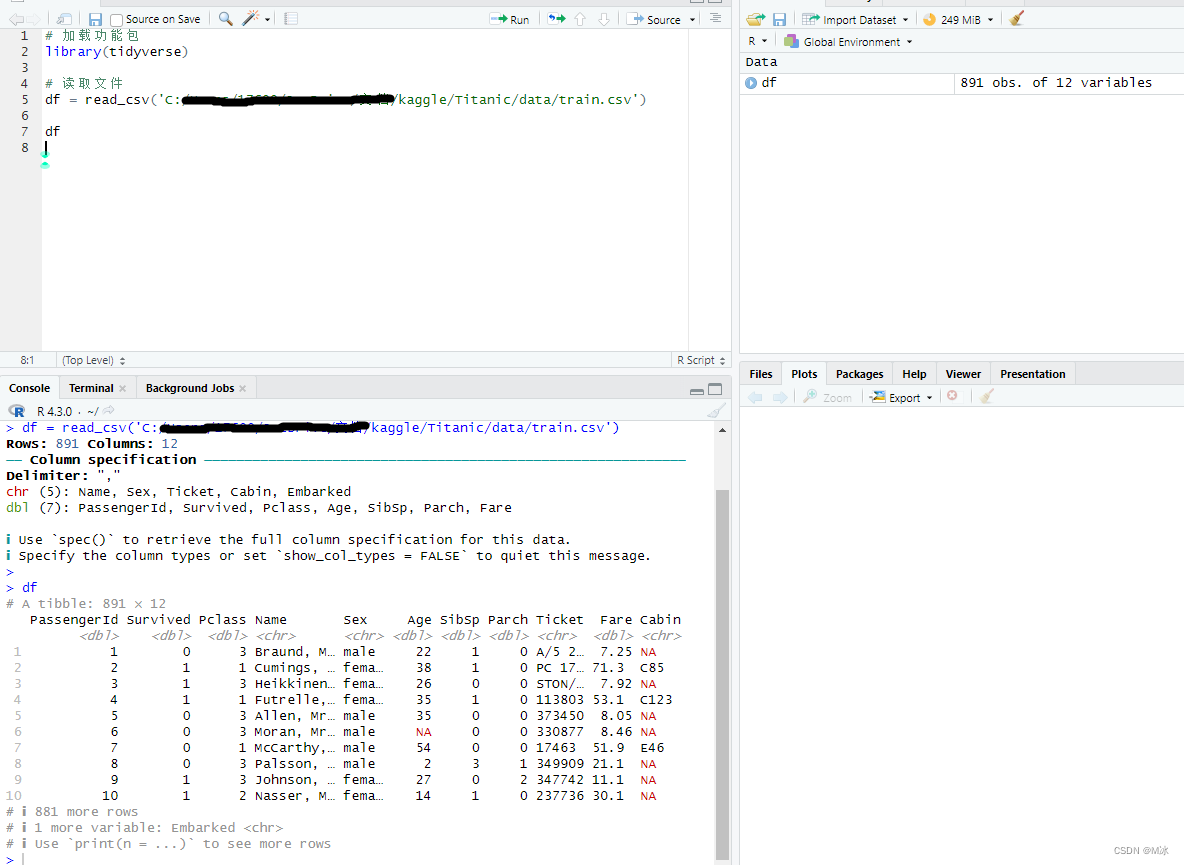
之后我们只需要输入设置好的名称就可以显示数据集信息了。 如,直接输入df,然后运行。 # 加载功能包 library(tidyverse) # 读取文件 df = read_csv('C:/Users/17600/OneDrive/文档/kaggle/Titanic/data/train.csv') df输出结果: 在工作中,除了csv文件以外,最常见的可能就是Excel文件了,在R语言中要把Excel文件中的数据读取到程序中,可以使用 readxl 包。 readxl 包可以轻松地将数据从 Excel 读取到 R中。 readxl 支持传统的 .xls 文件格式和基于 xml 的 .xlsx 文件格式。 readxl 包是 tidyverse 的一部分,但不是核心 tidyverse 包,因此需要先使用 library() 函数在 R语言 中加载 readxl。 library(readxl) read_excel() - 读取Excel文件读取Excel文件和读取csv文件时有些区别的,因为csv文件是一个单独的文件,其中没有sheet来对数据分区,直接读取就可以的。但是Excel文件中很多时候是包含多个sheet的。 下面我们先使用read_excel()来读取Excel文件,然后产看数据信息。就像使用read_csv()那样。 下面为Excel表中的数据,其中包含一月,二月,三月,三个sheet,我们只读取到了第一个sheet (一月) 的数据,并没有其他两个sheet的数据。
那么该怎么读取全部的数据呢?这时需要在·read_excel()·函数中,添加sheet= 参数,指定读取sheet的名称。 举个例子: # 加载功能包 library(readxl) # 读取文件 df = read_excel('C:/kaggle/Titanic/data/这是一个Excel文件.xlsx', sheet = '二月') df输出如下:
如何通过R来获取Excel中的sheet名称呢个?这时候会需要用到·excel_sheets()·函数 excel_sheets() - 读取Excel中sheet名称·excel_sheets()·函数,可以用来读取Excel中的sheet名称。 # 加载功能包 library(readxl) # 读取文件 excel_sheets('C:/kaggle/Titanic/data/这是一个Excel文件.xlsx')输出结果:
R语言中有一种叫做 管道(pipe) 的功能。用%>%来表示 管道是 R 中的一种工具,可帮助使代码更高效、更易于阅读和理解。 管道是 R 中用于表达多个操作序列的工具。 换句话说,它接受上一个语句的输出,并使其成为下一个语句的输入。 比如在需要套用多个函数在执行计算的时候,可以使用 管道(pipe) 功能来执行相同的工作。 我们将使用 ToothGrowth 数据集,这个数据集是R语言中内置的数据集。 该数据集包含有关维生素C对豚鼠牙齿生长影响的数据。 通过使用这个数据集中的数据来演示,帮助我们了解管道的工作原理。 先使用data()函数加载数据集ToothGrowth。 # 加载数据 data("ToothGrowth")然后我们可以使用 View 函数查看数据集ToothGrowth中的数据。 # 加载数据 data("ToothGrowth") #查看数据 view(ToothGrowth)
view()函数会在脚本中显示一个新选项卡,显示数据集的内容。 下面我们对数据进行过滤,筛选dose=0.5的数据,之后再对数据进行排序。 # 加载数据 data("ToothGrowth") #查看数据 view(ToothGrowth) # 过滤数据 df % arrange(len) df
Tips: 在管道(pipe)操作的每一行的末尾添加管道操作符(%>%)非常重要,最后一行除外。在 RStudio 会自动缩进属于管道(pipe)的代码行。如果代码中的某行未缩进,这可能会导致错误语句。 |
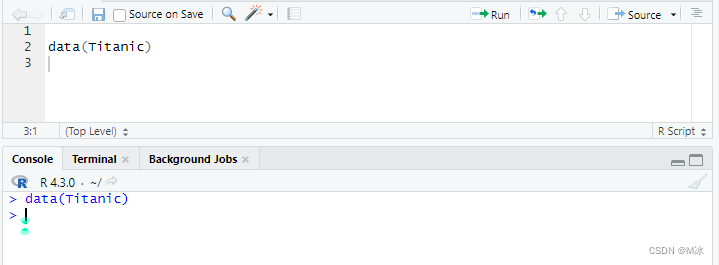 当您运行该函数时,R 将加载数据集。 数据集还将出现在 RStudio 的环境面板中。
当您运行该函数时,R 将加载数据集。 数据集还将出现在 RStudio 的环境面板中。
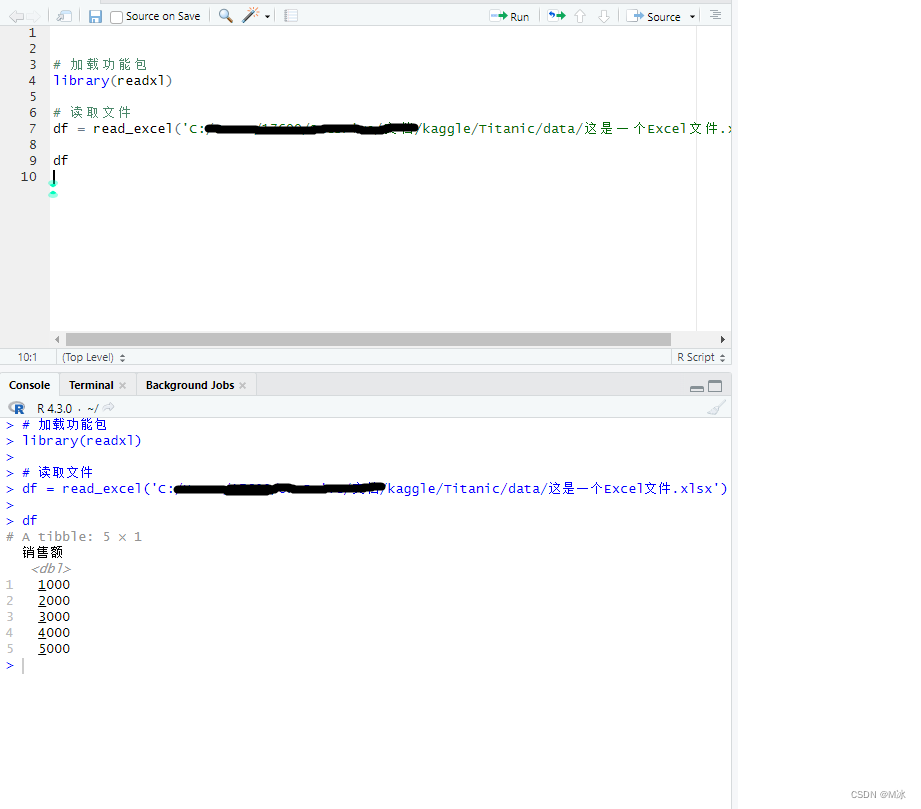 我们看到确实读取到了数据,但是只读取了一部分,并不是Excel表中的全部数据。
我们看到确实读取到了数据,但是只读取了一部分,并不是Excel表中的全部数据。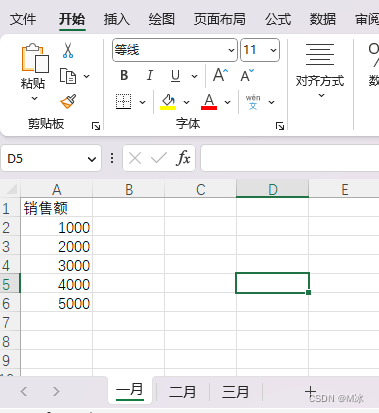
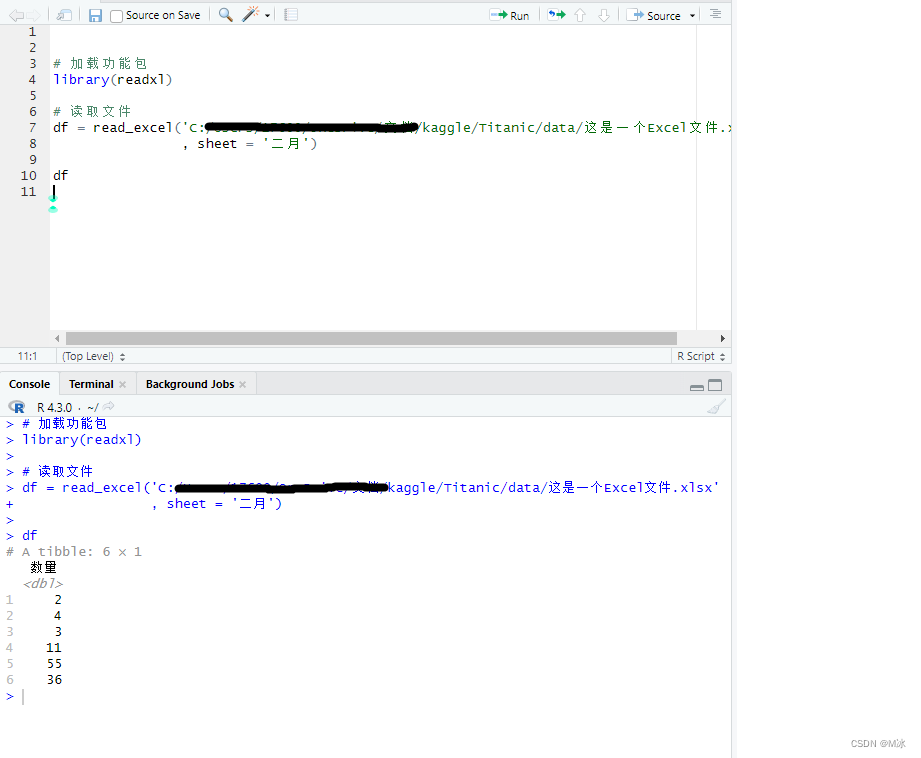 这样就读取到不同的sheet中的数据了。
这样就读取到不同的sheet中的数据了。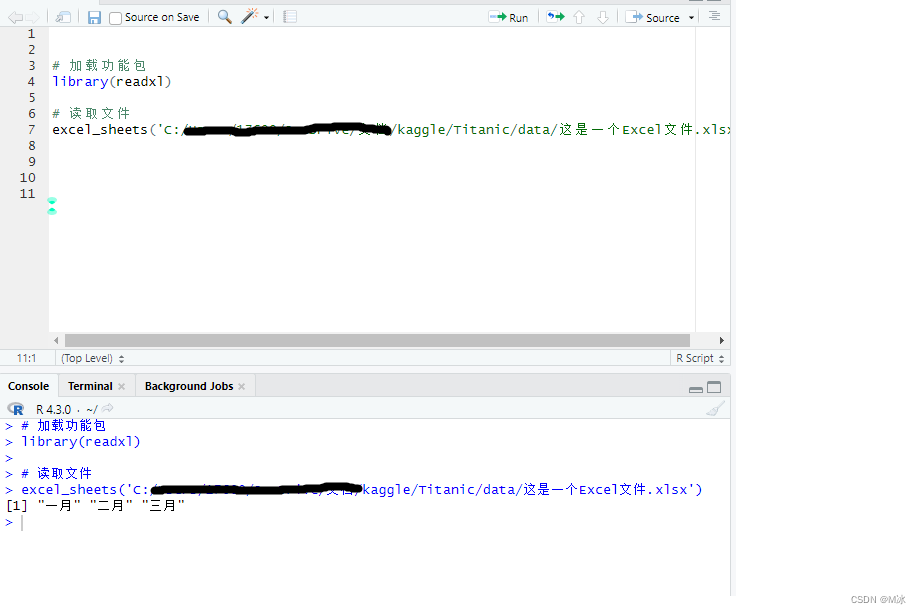 可以看到,Excel中的sheet名称都读取到了。
可以看到,Excel中的sheet名称都读取到了。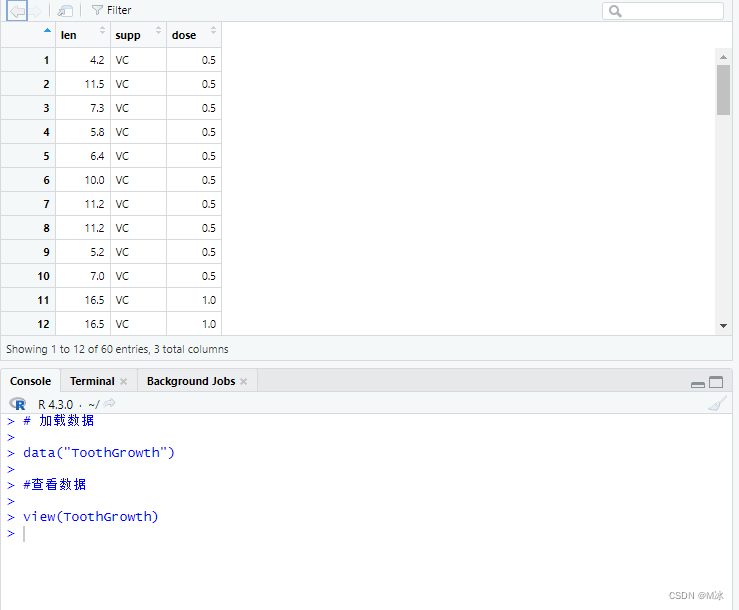
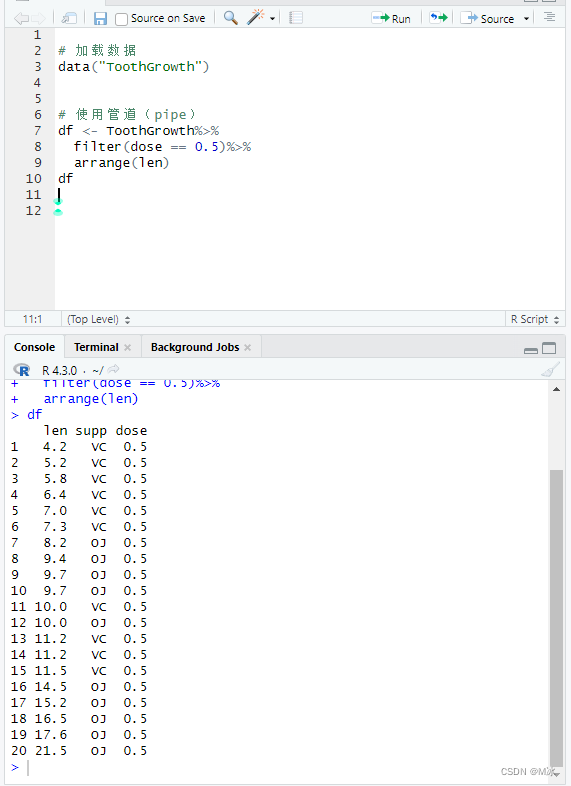 得到的结果是一样的,但是使用 管道(pipe) 会让代码的执行过程更清晰,每一步先执行什么然后再执行什么一步了然。
得到的结果是一样的,但是使用 管道(pipe) 会让代码的执行过程更清晰,每一步先执行什么然后再执行什么一步了然。【本文地址】
今日新闻 |
推荐新闻 |