CTF杂项之总结(一) |
您所在的位置:网站首页 › 杩埚厕灏斾箶涓筶ogo › CTF杂项之总结(一) |
CTF杂项之总结(一)
|
最近准备CTF比赛,刷题有感,故作总结。 题1:打开压缩包,得到名为key的exe文件。第一猜想可能是小程序逆向,所以尝试打开运行。系统提示:无法打开的可执行文件。 好的,右键选择属性,查看是否有猫腻。没有任何信息。 右键选择010或者notepad++打开。得到如下信息: 总结: 1.拿到题目时,应当首先查看是否可以打开、查看属性栏是否有隐藏信息、查看文件类型。以上三方面的信息可以大致确定题目的考点。 2.对文件头要保持一定的敏感度,常见文件头如下: 打开压缩包,得到一张图片和一个名为music的压缩包。 图面中最大的特征就是图片下方的黑灰小点。必定是需要将其解码。根据盲文对照表将其解码得到密码为kmdonowg。将音频文件解压。打开试听,得到“滴滴滴”的摩斯密码。 如果纯人工听取可能会有偏差。故使用音频分析文件打开: 代码(python2.7可用)如下: #!/usr/bin/python import pprint import re chars = "ABCDEFGHIJKLMNOPQRSTUVWXYZ1234567890" codes = """.- -... -.-. -.. . ..-. --. .... .. .--- -.- .-.. -- -. --- .--. --.- .-. ... - ..- ...- .-- -..- -.-- --.. .---- ..--- ...-- ....- ..... -.... --... ---.. ----. -----""" dd = dict(zip(chars.lower(),codes.split())) DD = dict(zip(codes.split(),chars.lower())) #pprint.pprint(DD) def chars2morse(char): return dd.get(char.lower(),' ') def morse2chars(morse): return DD.get(morse,' ') while True: str = raw_input() x = str.split(' ') ccc = ''.join(x) if re.match('^[0-9a-zA-Z]+$',ccc): print ' '.join(chars2morse(c) for c in ccc) else: cc = str.split() print ' '.join(morse2chars(c) for c in cc)总结: 最初拿到题目时,我还以为黑灰密文为三行8列的01代码。后来才想到海伦凯勒是一位盲人。所以这个密文是盲文。 在此附上盲文对照表: 打开压缩包,只有一个名为flag的jpg文件 经过大佬提示——这是三明治,两片面包夹肉,找到肉就找到flag。 好的,010打开二进制代码,查询jpg文件头FFD8FF,得到两个结果,在第二个文件头前有一串可疑的字符串—— MZWGCZ33GZTDCNZZG5SDIMBYGBRDEOLCGY2GIYJVHA4TONZYGA2DMM3FGMYH2 观察应该是base加密。尝试base64解码,无果。尝试base32解码,得到flag。 总结: 1.如上题一样。要深入挖掘图片给出的信息。当没有提示的时候,图片隐藏的含义就是提示。 2.dd命令相关知识拓展 dd:用指定大小的块拷贝一个文件,并在拷贝的同时进行指定的转换。 注意:指定数字的地方若以下列字符结尾,则乘以相应的数字:b=512;c=1;k=1024;w=2 参数注释: if=文件名:输入文件名,缺省为标准输入。即指定源文件。< if=input file > of=文件名:输出文件名,缺省为标准输出。即指定目的文件。< of=output file > ibs=bytes:一次读入bytes个字节,即指定一个块大小为bytes个字节。 obs=bytes:一次输出bytes个字节,即指定一个块大小为bytes个字节。 bs=bytes:同时设置读入/输出的块大小为bytes个字节。 cbs=bytes:一次转换bytes个字节,即指定转换缓冲区大小。 skip=blocks:从输入文件开头跳过blocks个块后再开始复制。 seek=blocks:从输出文件开头跳过blocks个块后再开始复制。 注意:通常只用当输出文件是磁盘或磁带时才有效,即备份到磁盘或磁带时才有效。 count=blocks:仅拷贝blocks个块,块大小等于ibs指定的字节数。 conv=conversion:用指定的参数转换文件。 ascii:转换ebcdic为ascii ebcdic:转换ascii为ebcdic ibm:转换ascii为alternate ebcdic block:把每一行转换为长度为cbs,不足部分用空格填充 unblock:使每一行的长度都为cbs,不足部分用空格填充 lcase:把大写字符转换为小写字符 ucase:把小写字符转换为大写字符 swab:交换输入的每对字节 noerror:出错时不停止 notrunc:不截短输出文件 sync:将每个输入块填充到ibs个字节,不足部分用空(NUL)字符补齐。 题4打开题目,得到两个压缩包。其中一个压缩包,解压得到名为misc2的jpg图片,是爱因斯坦照片: 总结: 实际上我在解题时并没有上述那么顺利。我跳过了查看属性这一步骤,直接查看010代码。由于信息繁杂,并没有找到password的信息。还通过stagsolve查看各个通道等操作。 这真的提示我们需要按照步骤,从简到繁,层层排查,才能找到信息。 题5打开压缩包,是一个未知格式的文件。文件名为What kind of document is this_ 所以出题人是想考察文件格式。让我们猜测这个文件到底是什么文件。 用010打开,查看文件头: 总结 1.文件头D0CF11E0实际对应的文件是MS Office文件,而MS Office文件包括MS Word/Excel/PPT。而office暴力破解软件需要在文件格式正确时才能够正确爆破密码。 2.遇到文件中文件时——如本题ppt中存在信息。也应当按照从简到繁的步骤去分析——先查看每张幻灯片中的状态,查找对比文本框及文本信息,再分析图片等信息。 总结以上题目多多少少都与图片有关,总结一下解题步骤: 原则:从简到繁—— 查看属性信息; 查看010二进制文件信息——文件头,文件尾 若存在密文,且藏于图片,思索图片是否表达了某些含义。含义即为提示。 若不存在密文文件,则需要考虑是否通过爆破来解决了。 一层一层剥开谜题,每层的思路都要坚持从简到繁的原则,不然,很可能会错过很多关键信息。 意会图片含义也相当重要。 |
 看到文件头的关键信息—— data:image/jpg;base64 这是jpg图片base64隐写的关键字。在网售搜寻图片base64转码工具,转码得到原图片。是一张二维码。扫码得到flag。
看到文件头的关键信息—— data:image/jpg;base64 这是jpg图片base64隐写的关键字。在网售搜寻图片base64转码工具,转码得到原图片。是一张二维码。扫码得到flag。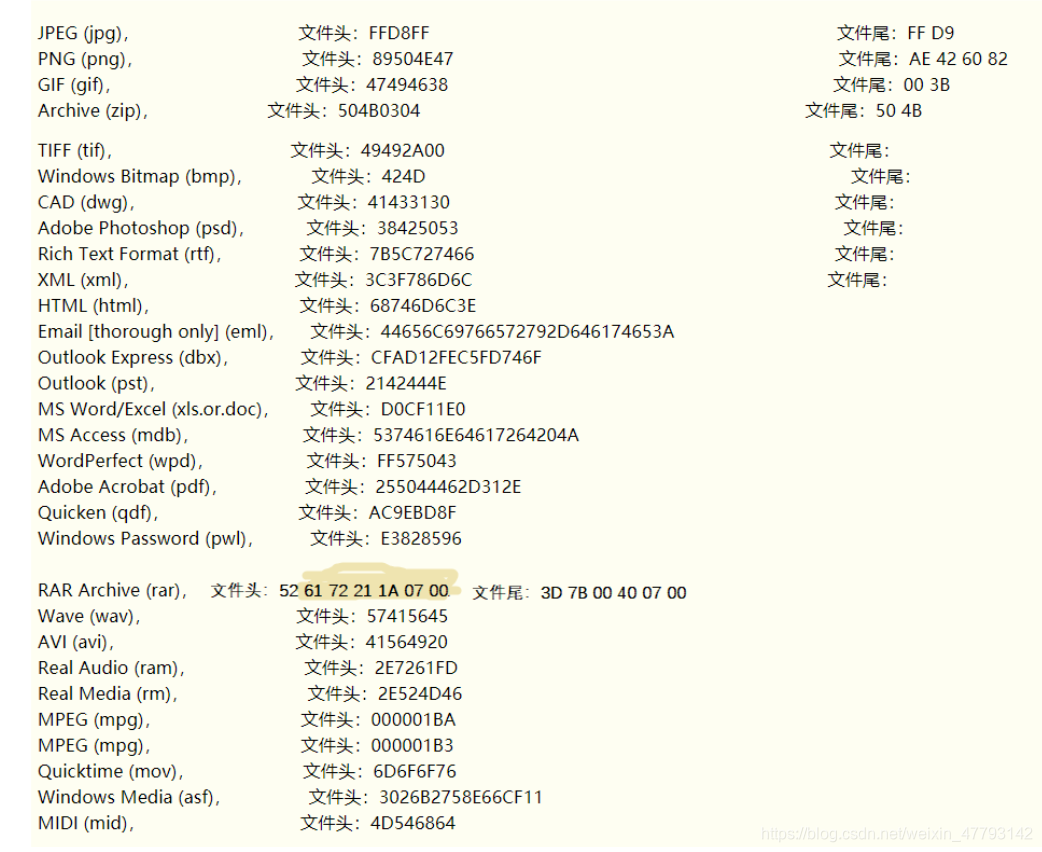 如果无法从文件头确定文件类型的话,对解题将是一大阻碍(比如此题如果不知道图片的base64隐写的话,便不知道考题的考察方向了。)同时,暂时没有找到离线解析图片base64隐写的工具。
如果无法从文件头确定文件类型的话,对解题将是一大阻碍(比如此题如果不知道图片的base64隐写的话,便不知道考题的考察方向了。)同时,暂时没有找到离线解析图片base64隐写的工具。 图片打开如下:
图片打开如下:  压缩包打开如下:
压缩包打开如下:  压缩包中的音频文件解压需要密码。考虑,密码藏于这张图片之中。
压缩包中的音频文件解压需要密码。考虑,密码藏于这张图片之中。 粗条纹为(-),细条纹为(.),大间隔为每个莫斯码的分格。人工将其转码得到如下莫斯密码: -.-. - …-. .-- .–. . … ----- —… --… …-- …— …–… …— …-- -… --… 在kali中,采用py脚本将其转码为字符串 c t f w p e i 0 8 7 3 2 2 3 d z
粗条纹为(-),细条纹为(.),大间隔为每个莫斯码的分格。人工将其转码得到如下莫斯密码: -.-. - …-. .-- .–. . … ----- —… --… …-- …— …–… …— …-- -… --… 在kali中,采用py脚本将其转码为字符串 c t f w p e i 0 8 7 3 2 2 3 d z 实际上,所谓杂项的脑洞在于挖掘题目给出的信息。而这些信息往往出现在意想不到的地方。有些明显有些隐晦。
实际上,所谓杂项的脑洞在于挖掘题目给出的信息。而这些信息往往出现在意想不到的地方。有些明显有些隐晦。 一如往常,右键查看属性,010查看文件头。 并没有什么异常。 尝试kali下binwalk分析。分析得到,这个图片文件还藏着一张图。dd命令分离得到——
一如往常,右键查看属性,010查看文件头。 并没有什么异常。 尝试kali下binwalk分析。分析得到,这个图片文件还藏着一张图。dd命令分离得到——  接下来便无疾而终…… 是的,没有任何的信息。两张图表示的内容是一样的。同时使用图片分析工具stegsolve查看各类通道也没有任何信息。
接下来便无疾而终…… 是的,没有任何的信息。两张图表示的内容是一样的。同时使用图片分析工具stegsolve查看各类通道也没有任何信息。 另一个压缩包打开,是名为flag的txt文件,需密码才能进解压。 那么,密码应该藏在图片之中。右键属性查看,照片备注中出现一行诡异的信息——
另一个压缩包打开,是名为flag的txt文件,需密码才能进解压。 那么,密码应该藏在图片之中。右键属性查看,照片备注中出现一行诡异的信息——  尝试将其作为密码,解压flag.txt。 解压成功。
尝试将其作为密码,解压flag.txt。 解压成功。 这里再次贴上常见文件头列表:
这里再次贴上常见文件头列表:  文件头D0CF11E0,所以这是一个MS Word/Excel文件。修改后缀为.doc。打开提示需要密码。 由于题目只有一个文件,即What kind of document is this_ 所以猜测没有密码提示,尝试暴力破解。使用office暴力破解软件PassFab for Office,破解无果。 大佬给出提示:文件头D0CF11E0实际对应的文件是MS Office文件,而MS Office文件包括MS Word/Excel/PPT。而office暴力破解软件需要在文件格式正确时才能够正确爆破密码。 所以依次尝试Excel/PPT,发现ppt才是正确的文件格式。爆破密码得到——9919 打开ppt,发现一共8张幻灯片,第一张幻灯片存有一张图片:
文件头D0CF11E0,所以这是一个MS Word/Excel文件。修改后缀为.doc。打开提示需要密码。 由于题目只有一个文件,即What kind of document is this_ 所以猜测没有密码提示,尝试暴力破解。使用office暴力破解软件PassFab for Office,破解无果。 大佬给出提示:文件头D0CF11E0实际对应的文件是MS Office文件,而MS Office文件包括MS Word/Excel/PPT。而office暴力破解软件需要在文件格式正确时才能够正确爆破密码。 所以依次尝试Excel/PPT,发现ppt才是正确的文件格式。爆破密码得到——9919 打开ppt,发现一共8张幻灯片,第一张幻灯片存有一张图片: 另外7张没有加入信息。尝试将图片导出另存,然后分析…… 但是并没有结果。 随后,观察其他ppt,发现一张空白ppt与其他ppt有所不同——
另外7张没有加入信息。尝试将图片导出另存,然后分析…… 但是并没有结果。 随后,观察其他ppt,发现一张空白ppt与其他ppt有所不同—— 
 只有副标题文本框。尝试找到主标题文本框,发现——
只有副标题文本框。尝试找到主标题文本框,发现——
 至此解题完毕。
至此解题完毕。【本文地址】