【论文简述】Learning Inverse Depth Regression for Multi |
您所在的位置:网站首页 › 期刊volume是什么意思中文翻译 › 【论文简述】Learning Inverse Depth Regression for Multi |
【论文简述】Learning Inverse Depth Regression for Multi
|
一、论文简述
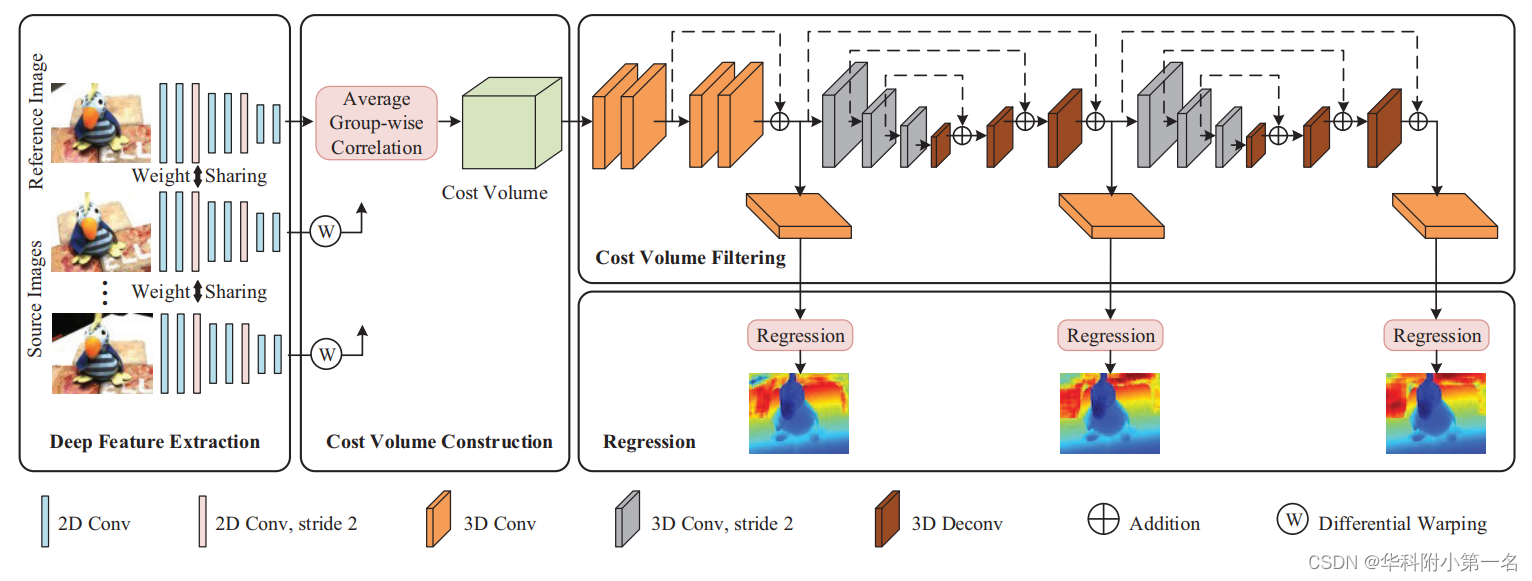
1. 第一作者:Qingshan Xu 2. 发表年份:2020 3. 发表期刊:AAAI 4. 关键词:MVS、深度学习、相关体、逆深度、沙漏模型 5. 探索动机: MVSNet代价体构建和正则化内存开销过大,极大地限制了这些在大规模和高分辨率场景中的使用。R-MVSNet没有3D U-Ne,因此不能包含足够的上下文信息。结果,网络的性能退化,需要传统的变分改进。将深度推断看作深度回归问题,在深度空间均匀采样深度平面,但其在成像平面级线上所对应的点并非均匀分,因此存在的不鲁棒问题。As for the depth regression, this strategy uniformly samples depth hypotheses in depth space and achieves sub-pixel estimation. However, it is not robust. Although the sampled depth hypotheses are uniformly distributed in depth space, their projected 2D points in a source image are not distributed uniformly along the epipolar line. Consequently, the true depth hypothesis near the camera center may not be captured by the deep features in a source image. On the other hand, when the true depth hypothesis is far away from the camera center, some depth hypotheses around it will correspond to multiple similar deep features in a source image because these deep features may be sampled from almost. 6. 工作目标:可扩展性和准确性仍然是一个悬而未决的问题,正是由于消耗内存的代价体表示和不适当的深度推断。这两个问题是否可以解决? 7. 核心思想:受立体匹配中的组相关的启发,提出了一个平均组相关相似度度量来构建一个轻量级的代价体。这不仅可以减少内存的消耗,而且可以减少成本体积过滤中的计算负担。 提出了一个平均的组相关相似度量来构建一个轻量级的代价体。这极大地减小了网络的内存。提出了一个级联的3D U-Net,以融合更多的上下文信息来提高我们的网络性能。将多视图深度推断问题视为逆深度回归任务,并证明逆深度回归可以在大范围场景中获得更鲁棒和准确的结果。8. 实验结果:具有相关代价体和反向深度回归的CIDER的网络达到了最先进的结果,证明了其在可扩展性和准确性方面的卓越性能。 9. 论文下载: https://arxiv.org/pdf/1912.11746.pdf 这篇巧妙借鉴了GWC-Net的大部分idea,也可以发文章,牛! 【论文简述及翻译】GWCNet:Group-wise Correlation Stereo Network(CVPR 2019) 二、实现过程 1. CIDER概述CIDER的网络架构。通过权重共享深度特征提取模块提取参考图像和源图像的特征图。将源图像的特征图通过微分变化的方法转换到参考图像的坐标。所有特征输入到平均组相关模块,构建一个轻量级的代价体。通过对代价体进行滤波和回归,得到预测深度图。
与MVSNet一样,采用权重共享的深度网络提取特征,大小为32× H/4 × W/4。 3. 相关代价体构建先前的实验发现32通道和8通道的代价体可达到相似精度,因此放弃构建32通道代价体再压缩为8通道的思路,而是直接构建8通道代价体减少计算量和内存消耗。 3.1. 单应变换 与MVSNet一样,原文讲述很详细。 3.2. 平均组相关度量 首先,将参考视图和源视图的32通道维度均匀划分为G组(g=1,2,…,G),Frefg代表在第g组参考视图的特征,Fi,jg‘代表源视图下对应的组特征,i代表第i张源视图,j代表深度,代表内积操作,因此对参考视图的每个假设深度j下,其第g组参考视图和源视图i可计算组相似性图Si,jg:
3.3. 代价体生成 对于每个深度j下的每张源视图i可构建G张相似性图Si,jg,沿通道维度相加表示为Si,j,则对于D个深度的Si,j最终构成代价体Vi为 [G, H/4, W/4, D];为了适应任意数量的输入源图像,将N-1张源视图代价体进行平均,获取最终的代价体[G, H/4, W/4, D],G为8,即
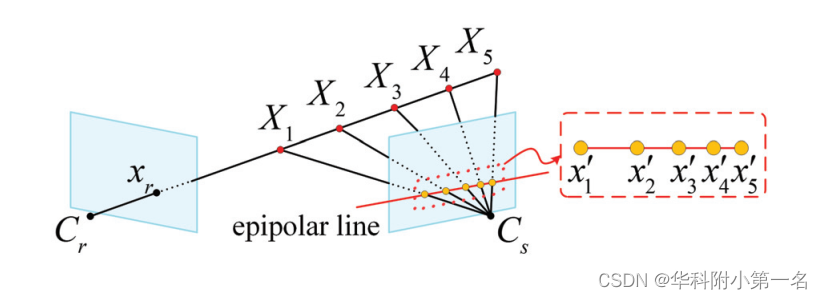
使用一个级联的3D Unet网络来正则化代价体以获取概率体。在级联3D U-Net之前,先有一个残差模块和回归模块来学习更好的特征表示。接着,两个级联的Unet,通过自顶向下/自底向上的重复处理结构学习更多的上下文信息,处理一些模糊区域的深度估计。 论文强调,由于代价体表示带来的巨大内存消耗,之前的MVSNet和R-MVSNet都没有用过这样的结构,因而使得他们聚合的上下文信息有限。由于本文轻量级的代价体表示,因此可以在网络中进行渐进的代价体过滤。 5. 逆深度回归5.1 均匀深度假设的问题 代价体构建中,采样的深度假设将被投影到相邻的图像上,以获得一系列2D点。MVSNet在深度空间中对深度假设进行统一采样,实现亚像素估计。然而,它并不鲁棒。虽然采样深度假设在深度空间中均匀分布,但它们在源图像中的投影2D点沿极线分布并不均匀。因此,源图像的深层特征可能无法捕捉到靠近相机中心的真实深度假设。另一方面,当真深度假设离相机中心较远时,所对应的源图像特征可能是同一个非常相似的,因为距离越远采样点逐渐逼近,如下图所示:
5.2 逆深度采样 为了使位于同一极线上的二维点尽可能均匀分布,论文在逆深度空间中进行均匀采样,获得离散深度假设,如下所示:
其中dmin和dmax分别是参考图像的最小深度值和最大深度值。通过这样选取的深度值与原来相比,最小最大深度不变,深度样本数不变,改变的是当中每一个深度假设的值——原来可能是在【1,100】上均匀采样得到【1,2,3…100】,但这种采样结果可能为【1,3,5.5,8…100】,虽然深度间隔不一致了,但是这些深度对应到源视图上各点的像素距离是逼近均匀分布的,这种采样方式就称为“逆深度设置”(inverse depth setting)。 参考:https://blog.csdn.net/qq_41794040/article/details/128064576 5.3 逆深度回归 通过逆深度方式对深度假设值进行采样,进行单应变换以及组相关代价体的构建,接着使用级联的3D Unet进行滤波,网络中有三个输出分支。在每个分支中,过滤后的代价体通过三维卷积运算得到1通道的代价体。为了获得最终的连续深度图,我们首先从代价体中回归亚像素序数k(代表最终的期望深度层),如下所示:
其中,pj是深度值dj处的概率,它是通过softmax函数从预测的代价体计算出来的。然后再利用该序数k代入逆深度采样的公式来求得最终的深度值。每个像素的最终预测深度值计算为:
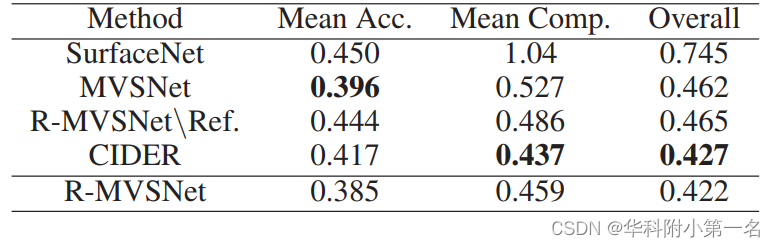
其中λ q表示第q个预测深度图的权重,l(·,·)是平均绝对差值。训练阶段,计算推测深度图和真实深度图平均绝对差值,对3个阶段输出的深度图损失进行加权。 7. 实验7.1. 数据集 DTU Dataset、Tanks and Temples Benchmark 7.2 评估指标 Evaluation Metrics.the accuracy and the completeness of the distance metric are used for DTU dataset while the accuracy and the completeness of the percentage metric for Tanks and Temple dataset.In order to obtain a summary measure for the accuracy and the completeness, the mean value of them is employed for the distance metric and the F1 score is utilized for the percentage metric. 7.3. 实现 训练:使用DTU数据集训练。深度图尺寸为160×128。输入视图数N = 3,图像大小裁剪到640 × 512,输入图像的总数设置为N = 3,深度值的样本总数设置为D = 192。三个输出的权重分别设置为λ0 = 0.5,λ1 = 0.5和λ2 = 0.7。Dmin和dmax分别固定为425mm和935mm。通过PyTorch实现,RMSprop为优化器。 滤波与融合:与MVSNet一致,使用光度一致性、几何一致性。 7.4. 结果 DTU数据集基准比较:好点吧
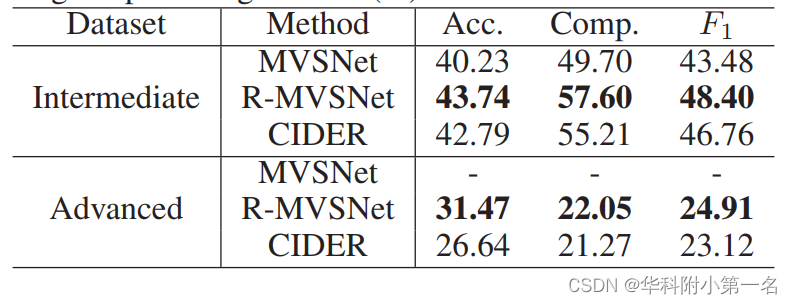
泛化性:一般
7.5. 消融实验 时间和内存上有优势
|
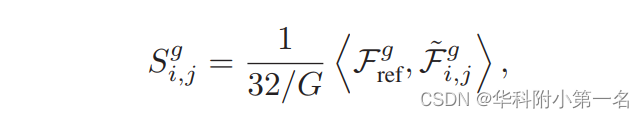
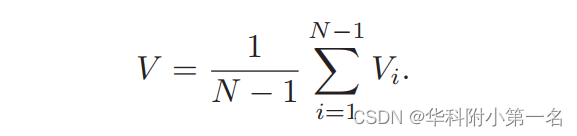
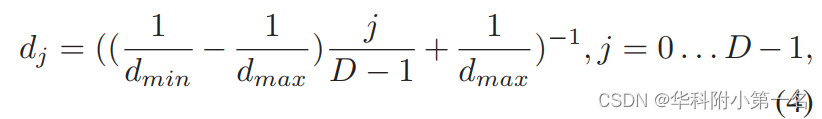
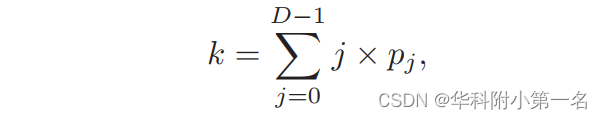
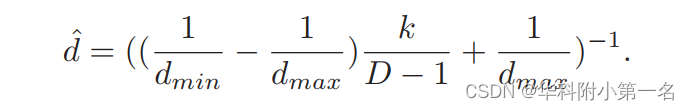


【本文地址】
今日新闻 |
推荐新闻 |