高阶JAVA篇 |
您所在的位置:网站首页 › 最小字符集编码原则 › 高阶JAVA篇 |
高阶JAVA篇
|
🔥博客主页: 小扳_-CSDN博客 ❤感谢大家点赞👍收藏⭐评论✍
文章目录 1.0 字符集的说明 1.1 ASCII 字符集 1.2 GBK 字符集 1.3 UTF-8字符集 2.0 字符集的编码与解码 2.1 编码提供了常见的方法 2.2 解码提供了常见的方法 1.0 字符集的说明字符集是一组字符的集合,字符集包括所有可用的字符,包括字母、数字、标点符号、特殊字符和控制字符等。常见的字符集有 ASCII 字符集、UTF-8 字符集、 GBK 字符集等。 1.1 ASCII 字符集它由128个字符组成,包括大写和小写字母、数字、标点符号、特殊字符和控制字符等。ASCII 字符集使用7位二进制数表示每个字符,范围从0到127。 只用一个字节大小的容量来“装”下这些每一个英文、数字、符号,需要注意的是首位必须为0。 1.2 GBK 字符集GBK 字符集广泛用于中文环境下的计算机系统和软件,包括操作系统、文字处理软件、网页等。GBK 字符集是一种中文字符集,是在 ASCII 字符集基础上或者兼容的前提下,进行扩展的。 需要重点了解的是,每一个英文和数字、字符都是可以用一个字节大小的容量来“装”下,首位必须为0,对于中文汉字来说,需要每一个字符需要两个字节大小的容量来“装”下这超过21000个汉字和符号,包括繁体字、生僻字和部分其他语种的字符。需要重点注意的是,首位必须为1。 1.3 UTF-8字符集UTF-8 字符集是一种全球通用的字符编码标准,它包含了几乎所有已知的字符,涵盖了世界上所有的语言和符号。UTF-8 字符集的目标是为每个字符提供一个唯一的编码,以便在不同的计算机系统和软件中进行字符的交换和处理。 UTF-8是一种变长编码方案,使用1到4个字节来表示不同的字符,适用于在互联网上传输和存储文本数据。每个中文的汉字、字符等占三个字节,每个英文、数字、符号等占一个字节,在编码或者解码为了区分这些字符不混淆,就会有一定的规则。占一个字节的,首位必须为0;占两个字节的,第一个字节首位三个必须为110,第二个字节的首位两个必须为10;占三个字节的,首位四个必须为1110,第二个字节首位两个为10,第三个字节首位两个也为10;占四个字节的,首位五个必须为11110,第二个字节首位两个为10,第三个字节首位两个也为10,第四个字节首位两个也为10。 小结一下:
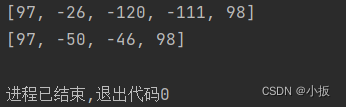
字符集的编码和解码是将字符转换为对应的编码值,或将编码值转换为对应的字符的过程。简单地来说,编码就是将字符转变为编号,这里的编号就是字符集中对应的编码值,而解码就是逆过程,将编号转变为字符。 2.1 编码提供了常见的方法使用 getBytes() :默认系统提供的编码集。 使用 getBytes( String charsetName) :选择自己想要的编码集。 代码如下: import java.util.Arrays; public class characterSet { public static void main(String[] args) throws Exception{ //编码 String name = new String("a我b"); //默认系统的提供的字符集进行编码 byte[] num = name.getBytes(); System.out.println(Arrays.toString(num)); //自选的字符集进行编码 byte[] num1 = name.getBytes("GBK"); System.out.println(Arrays.toString(num1)); } }运行结果如下:
就是用字符串类的构造器,将字节数组放到有参构造器中,就可以得到了相应的字符串了。 使用:String pass = new String( byte bytes[]),默认系统提供的编码集。 使用:String pass = new String( byte bytes[], String charsetName),自选编码集。 代码如下: import java.util.Arrays; public class characterSet { public static void main(String[] args) throws Exception{ //编码 String name = new String("a我b"); //默认系统的提供的字符集进行编码 byte[] num = name.getBytes(); System.out.println(Arrays.toString(num)); //自选的字符集进行编码 byte[] num1 = name.getBytes("GBK"); System.out.println(Arrays.toString(num1)); //解码 //用系统提供的默认字符集 String pass = new String(num); System.out.println(pass); //自己选用想要的字符集 String pass1 = new String(num1,"GBk"); System.out.println(pass1); } }运行结果如下:
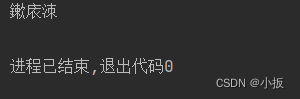
需要重点注意的是,使用了某一套字符集进行编码,那么必须要使用跟编码使用的相同的一套字符集进行解码。 代码如下: import java.io.UnsupportedEncodingException; public class characterSet { public static void main(String[] args) throws UnsupportedEncodingException { String name = "李四"; //这里使用了 UTF-8 这一套字符集进行编码 byte[] passName = name.getBytes(); //如果使用 GBK 这一套字符集进行解码的时候会很很大问题 String newName = new String(passName,"GBK"); System.out.println(newName); } }运行结果:
这里就出现了我不认识的字了,总之,编码与解码都要使用同一套字符集,不然会出现问题。
|




【本文地址】