使用深度学习自动给图片生成文字描述 |
您所在的位置:网站首页 › 昙花开花前的征兆图片和文字描述 › 使用深度学习自动给图片生成文字描述 |
使用深度学习自动给图片生成文字描述
|
给图像加文字描述,涉及在给定的图像(例如照片)的情况下生成人类可读的文本描述。 对于人类而言,这是一个容易解决的问题,但对于机器而言却非常具有挑战性,因为它既需要理解图像的内容,又需要将这种理解转化为自然语言。 近年来,深度学习方法已经取代了传统方法,并针对自动生成图像描述(称为“字幕”)的问题取得了最新技术成果。 在本文中,你将发现如何使用深度神经网络模型来自动生成图像描述。 完成这篇文章后,你将了解: 关于为图像生成文本描述所面临的挑战以及将计算机视觉和自然语言处理方面的突破相结合的需求。关于组成神经特征字幕模型的元素,即特征提取器和语言模型。可能使用注意力机制,如何将模型的元素安排到编码解码器中。 一.用文字描述图像描述图像是生成图像的人类可读文本描述的关键,例如对象或场景的照片。 这个技术有时称为“自动图像注释”或“图像标记”。 对于人类来说这是一个容易解决的问题,但是对于机器而言却是非常具有挑战性的。 快速浏览图像就足以使人们指出并描述有关视觉场景的大量细节。但是,对于我们的视觉识别模型来说,这种非凡的能力已被证明是一项艰巨的任务。一种解决方案既需要理解图像的内容,又要用单词的术语将其翻译成含义,并且单词必须串在一起才能理解。它结合了计算机视觉和自然语言处理功能,并在更广泛的人工智能领域标志着一个真正的挑战性问题。 自动描述图像的内容是连接计算机视觉和自然语言处理的人工智能的基本问题。此外,这些问题的难度范围很大,让我们用实例来看一下这个问题的三种不同变化。 1.图像分类为图像分配数百或数千个已知类别之一的类别标签。  将图像分类为已知类别的示例
2.描述图片
将图像分类为已知类别的示例
2.描述图片
生成图像的文字描述。  为照片生成文字描述的示例
3.注释图像
为照片生成文字描述的示例
3.注释图像
生成图像上特定区域的文字描述。 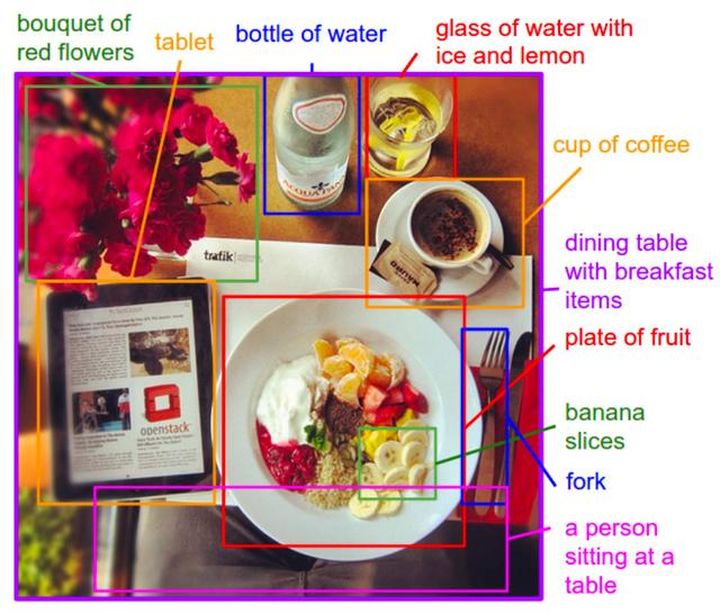 带有说明的图像注释区域示例
带有说明的图像注释区域示例
一般问题也可以扩展为描述视频中随时间变化的图像。 在这篇文章中,我们将专注于描述图像,我们将其描述为“图像标题”。 二.神经字幕模型神经网络模型已经成为自动生成图片文字描述领域的主导技术。 在端到端神经网络模型生成图像描述之前,两种主要方法是基于模板的方法和基于最近邻居的方法以及修改现有描述的方法。 在使用神经网络生成文字描述之前,主要采用两种主要方法。首先涉及生成文字模板,这些模板根据对象检测和属性发现的结果进行填充。第二种方法是基于首先从大型数据库中检索相似的文字描述图像,然后修改这些检索到的字幕以适合查询。[…]自那以后,这两种方法都不再受到目前占主导地位的神经网络方法的青睐。用于生成图像文字描述的神经网络模型涉及两个主要元素: 1.特征提取模型特征提取模型是一个神经网络,给定图像能够提取显著特征,通常采用固定长度矢量的形式。 提取的特征是图像的内部表示,而不是直接可理解的东西。 深度卷积神经网络或CNN用作特征提取子模型。可以直接在图像字幕数据集中的图像上训练该网络。 或者,可以使用预训练模型,例如用于图像分类的最新模型,也可以使用某些混合模型,其中使用了预训练模型并对问题进行了微调。 在针对ILSVRC挑战而开发的ImageNet数据集中使用性能最高的模型是很流行的,例如牛津视觉几何集团模型,简称为VGG。 […]我们探索了几种解决过度拟合的技术。避免过度拟合的最明显方法是将系统的CNN组件的权重初始化为预先训练的模型(例如,在ImageNet上)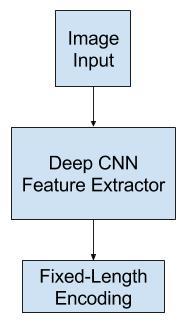 特征提取器
2.语言模型
特征提取器
2.语言模型
通常,语言模型会根据序列中已存在的单词来预测序列中下一个单词的概率。 对于图像字幕,语言模型是一个神经网络,该神经网络从网络中提取的特征能够预测描述中单词的顺序,并以已经生成的单词为条件建立描述。 经常使用递归神经网络(例如长短期记忆网络或LSTM)作为语言模型,每个输出时间步长都会在序列中生成一个新词。 然后,使用单词嵌入(例如word2vec)对生成的每个单词进行编码,并将其作为输入传递给解码器,以生成后续单词。 对模型的改进涉及收集单词在整个输出词汇表中的概率分布,并对其进行搜索以生成多个可能的描述。这些描述可以通过可能性进行评分和排名,通常使用波束搜索进行此搜索。 可以使用从图像数据集中提取的预先计算的特征来独立训练语言模型;它可以与特征提取网络联合训练,也可以组合使用。 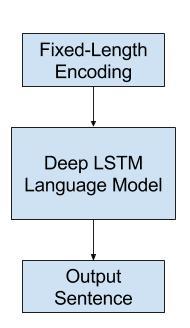 语言模型
语言模型
三.编码器-解码器架构 构造子模型的一种流行方法是使用编码器-解码器体系结构,其中两个模型都经过联合训练。 [模型]基于将图像编码为紧凑表示的卷积神经网络,然后是生成相应句子的递归神经网络。训练模型以使给定图像的句子的可能性最大化。这是为机器翻译而开发的体系结构,其中输入序列(例如法语)由编码器网络编码为固定长度的向量。然后,一个单独的解码器网络读取编码并以新语言(例如英语)生成输出序列。 除了该方法令人印象深刻的技能外,此方法的好处是可以针对该问题训练单个端到端模型。 当适用于图像字幕时,编码器网络是深度卷积神经网络,而解码器网络是LSTM层的堆栈。 [在机器翻译中]“编码器” RNN读取源语句并将其转换为丰富的固定长度向量表示形式,然后将其用作生成目标语句的“解码器” RNN的初始隐藏状态。在这里,我们建议遵循这种优雅的方法,用深度卷积神经网络(CNN)代替编码器RNN。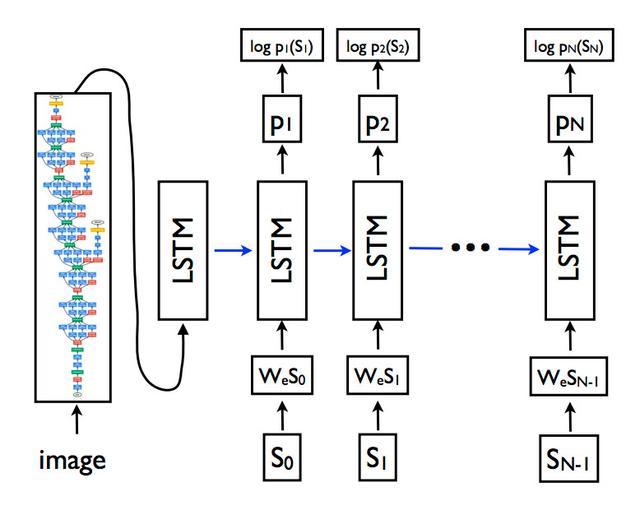 CNN和LSTM体系结构的示例
1.文字模型中的注意力机制
CNN和LSTM体系结构的示例
1.文字模型中的注意力机制
编码器-解码器体系结构的局限性在于,使用单个固定长度表示形式来保存提取的特征。 通过在更丰富的编码中发展注意力,可以在机器翻译中解决此问题,使解码器可以在生成翻译中的每个单词时学习将注意力放在何处。 通过允许解码器了解在生成描述中的每个单词时在图像中的关注位置,还可以将注意力方法用于改善用于图像字幕的编码器-解码器体系结构的性能。 受图像文字生成的最新技术的进步,以及受近期在机器翻译和对象识别中吸引注意力的成功所启发,我们研究了可在生成字幕时关注图像显著部分的模型。这种方法的好处是,在生成描述中的每个单词时,可以准确地可视化注意力的位置。 我们还通过可视化展示了模型如何能够自动学习将注视固定在显著对象上,同时在输出序列中生成相应的单词。通过以下示例更容易理解。  带有注释的图像文字说明示例
带有注释的图像文字说明示例
|
【本文地址】
今日新闻 |
推荐新闻 |