python课程设计 |
您所在的位置:网站首页 › 数据预处理实训目的是什么呢 › python课程设计 |
python课程设计
|
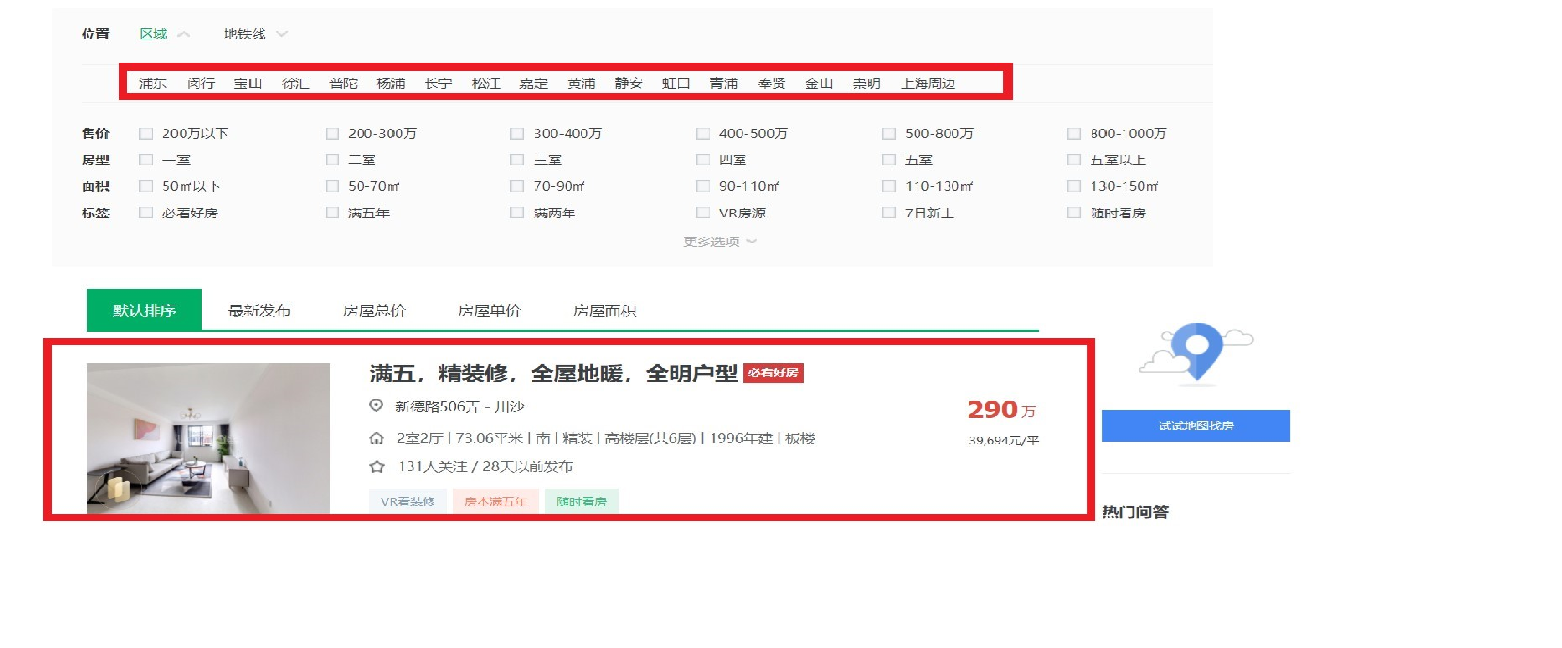
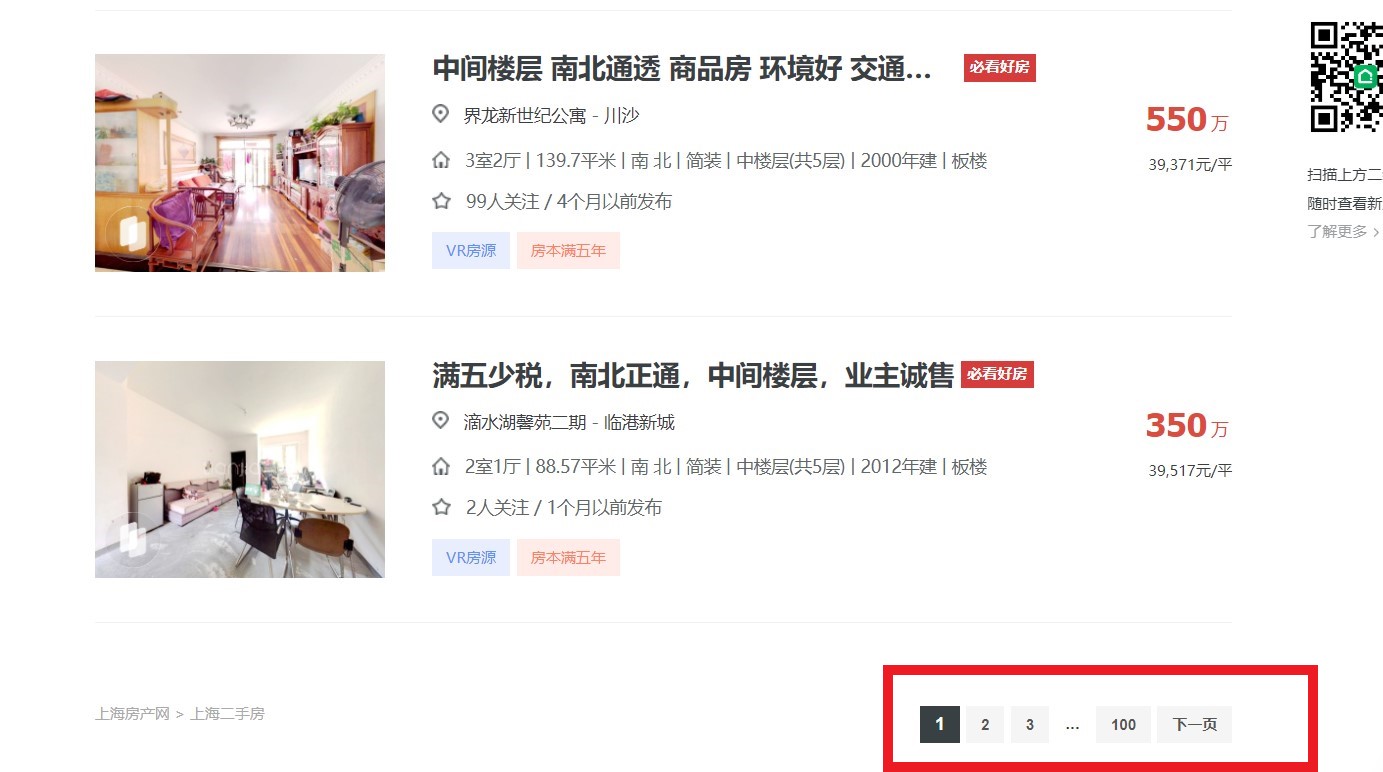
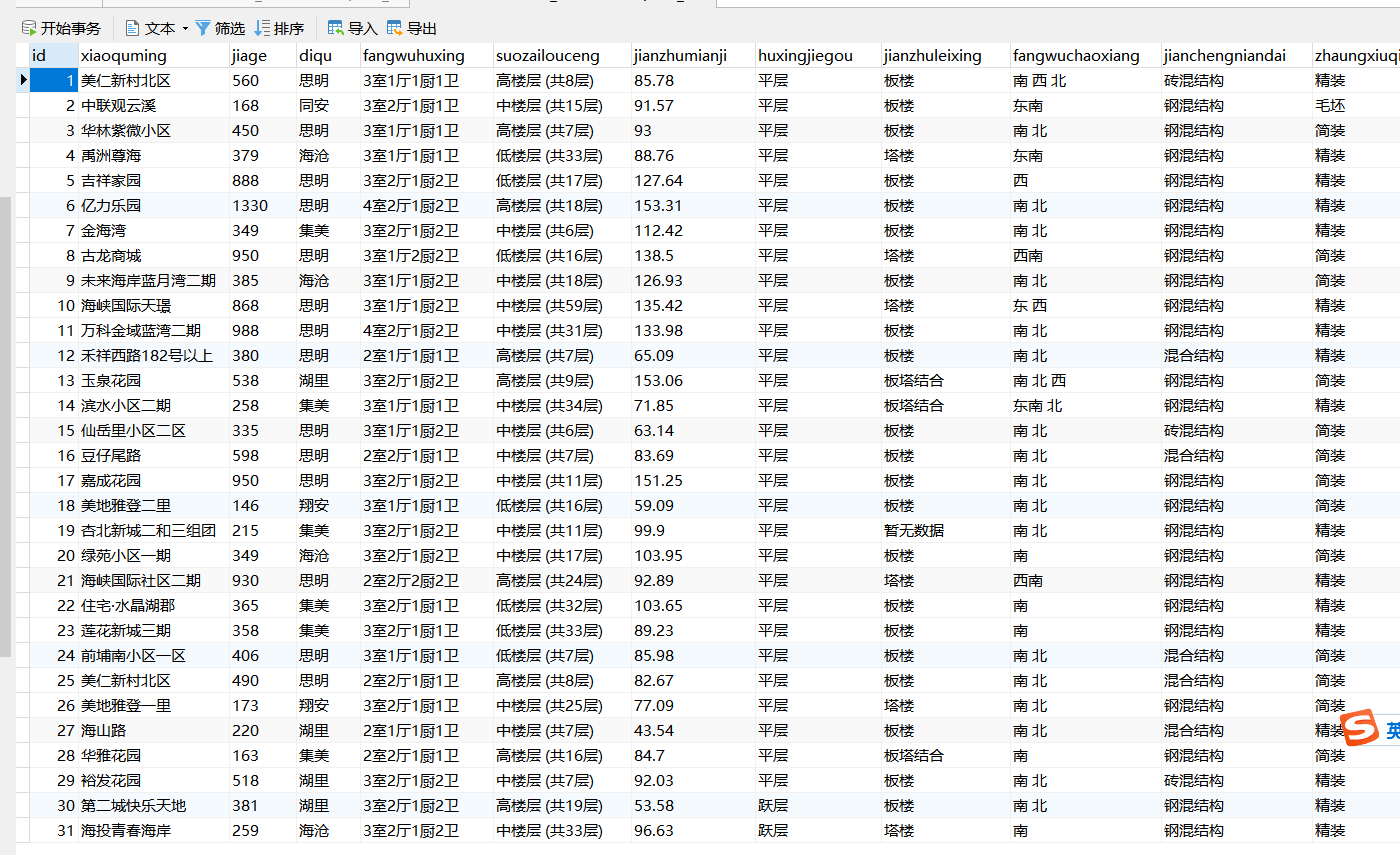
一.选题的背景 我本次的主题是厦门二手房房价的调查分析。 房价飞涨,年轻的我们刚毕业走出校门,又遇到令人喘不过气的房价。处于尴尬时期的我们,只能望楼兴叹,但是除此之外我们还可以房价分析。利用科学的技术手段,洞察房价的趋势。我们不买房,不炒房,但可以做到心中有个底。 房主在决议卖房时起初需要考虑的即是一定房子的出售价钱。假如房价太高,买房的人群就会削减甚至房屋长期没法售出。假如房价太低,房主即使可以很快卖房,但是却发生很多的经济损失。尤其是二手房,房子因为不合房主的入住会发生不合,从而招致房价的不合。那么二手房房价若何评介?现在大多采取房产价钱评介的商场对照法,经过对同一楼盘的在售房源的挂牌价钱,和同典型楼盘的近期实际成交价钱进行专业措置,换算出具体某个楼盘的平均单价,而后联络待评介房屋的实际情形,包罗面积、楼层、朝向、装修情形、其余特征原因等等,计较出该房屋相对科学合理的商场参照价。 通过本次实训可以大概了解到厦门二手房的整体情况。 二、项目构建 2.1 需求分析随着越来越多的城市二手住房成交量超越新房,诸多一、二线城市迎来“存量”住宅交易时代,承接绝大多数购房需求释放。另一方面,自去年上半年以来,新房供应持续短缺也给二手住房交易不断“复苏”创造空间,更多购房需求主动“转移”至存量市场。数据表现为今年以来重点城市挂牌量的持续小幅减少,二手房住宅成交量的触底回升以及重点城市如广州、重庆、武汉等,一、二手房住宅价格持续“倒挂”,都预示二手房市场正以卖方为主导。 2.2可行性分析在此背景下,研究当前二手住房市场的整体情况变得尤为重要:第一,可以反映市场真实的需求状况,不得不说人为“限价”主导的新房供应、成交难免“失真”,相较而言,二手市场成交结构的变化可以客观反映出当前购房者真是需求状态以及这种变化,到底是什么样的人才买房?这些购房者真正需要什么样的产品?第二,二手存量市场作为核心而一线城市市场重要部分,对其发展变化总结也可以合理预判未来不同城市的购房偏好。 三、数据分析步骤(70 分) 3.1 数据采集该部分通过网络爬虫程序抓取链家网上所有上海二手房的数据,收集原始数据,作为整个数据分析的基石。通过导入requests库,pandas库获取数据,通过url到指定的网站进行数据爬取,设置了id,小区名(xiaoquming),价格(jiage),地区(diqu),房屋户型(fangwuhuxing),所在楼层(suozailouceng),建筑面积(jianzhumianji),户型结构(huxingjiegou),建筑类型(jianzuleixing),房屋朝向(fangwuchaoxiang),建成年代(jianchengniandai),装修时间(zhuangxiuqingkuang),建筑结构(jianzhujiegou),供暖方式(gongnuanfangshi),单价(danjia)等15个字段,最后通过save_data()将爬取的数据进行保存。 #爬取的关键代码 1 import requests,time,csv 2 import pandas as pd 3 from lxml import etree 4 5 #获取每一页的url 6 def Get_url(url): 7 all_url=[] 8 for i in range(1,101): 9 all_url.append(url+'pg'+str(i)+'/') #储存每一个页面的url 10 return all_url 11 12 #获取每套房详情信息的url 13 def Get_house_url(all_url,headers): 14 num=0 15 #简单统计页数 16 for i in all_url: 17 r=requests.get(i,headers=headers) 18 html=etree.HTML(r.text) 19 url_ls=html.xpath("//ul[@class='sellListContent']/li/a/@href") #获取房子的url 20 Analysis_html(url_ls,headers) 21 time.sleep(4) 22 print("第%s页爬完了"%i) 23 num+=1 24 25 #获取每套房的详情信息 26 def Analysis_html(url_ls,headers): 27 for i in url_ls: #num记录爬取成功的索引值 28 r=requests.get(i,headers=headers) 29 html=etree.HTML(r.text) 30 name=(html.xpath("//div[@class='communityName']/a/text()"))[0].split() #获取房名 31 money = html.xpath("//span[@class='total']/text()" )# 获取价格 32 area = html.xpath("//span[@class='info']/a[1]/text()") # 获取地区 33 data = html.xpath("//div[@class='content']/ul/li/text()")# 获取房子基本属性 34 35 Save_data(name,money,area,data) 36 37 #把爬取的信息存入文件 38 def Save_data(name, money, area, data): 39 result=[name[0]]+money+[area]+data #把详细信息合为一个列表 40 with open(r'raw_data.csv','a',encoding='utf_8_sig',newline='')as f: 41 wt=csv.writer(f) 42 wt.writerow(result) 43 print('已写入') 44 f.close() 45 46 if __name__=='__main__': 47 url='https://xm.lianjia.com/ershoufang/' 48 headers={ 49 "Upgrade-Insecure-Requests":"1", 50 "User-Agent":"Mozilla/5.0(Windows NT 10.0;Win64;x64) AppleWebKit/537.36(KHTML,like Gecko)Chrome" 51 "/72.0.3626.121 Safari/537.36" 52 } 53 all_url=Get_url(url) 54 with open(r'raw_data.csv', 'a', encoding='utf_8_sig', newline='') as f: 55 #首先加入表格头 56 table_label=['小区名','价格/万','地区','房屋户型','所在楼层','建筑面积','户型结构','套内面积','建筑类型','房屋朝向' 57 ,'建成年代','装修情况','建筑结构','供暖方式'] 58 wt=csv.writer(f) 59 wt.writerow(table_label) 60 Get_house_url(all_url,headers)3.1.1 链家网站结构分析 链家网二手房主页界面如图4-1、图4-2,主页上面红色方框位置显示目前上海二手房在售房源的各区域位置名称,中间红色方框位置显示了房源的总数量,下面红色方框显示了二手房房源信息缩略图,该红色方框区域包含了二手房房源页面的URL地址标签。图4-2下面红色方框显示了二手房主页上房源的页数。 链家网二手房主页截图上半部分:
图3-1 链家网二手房主页
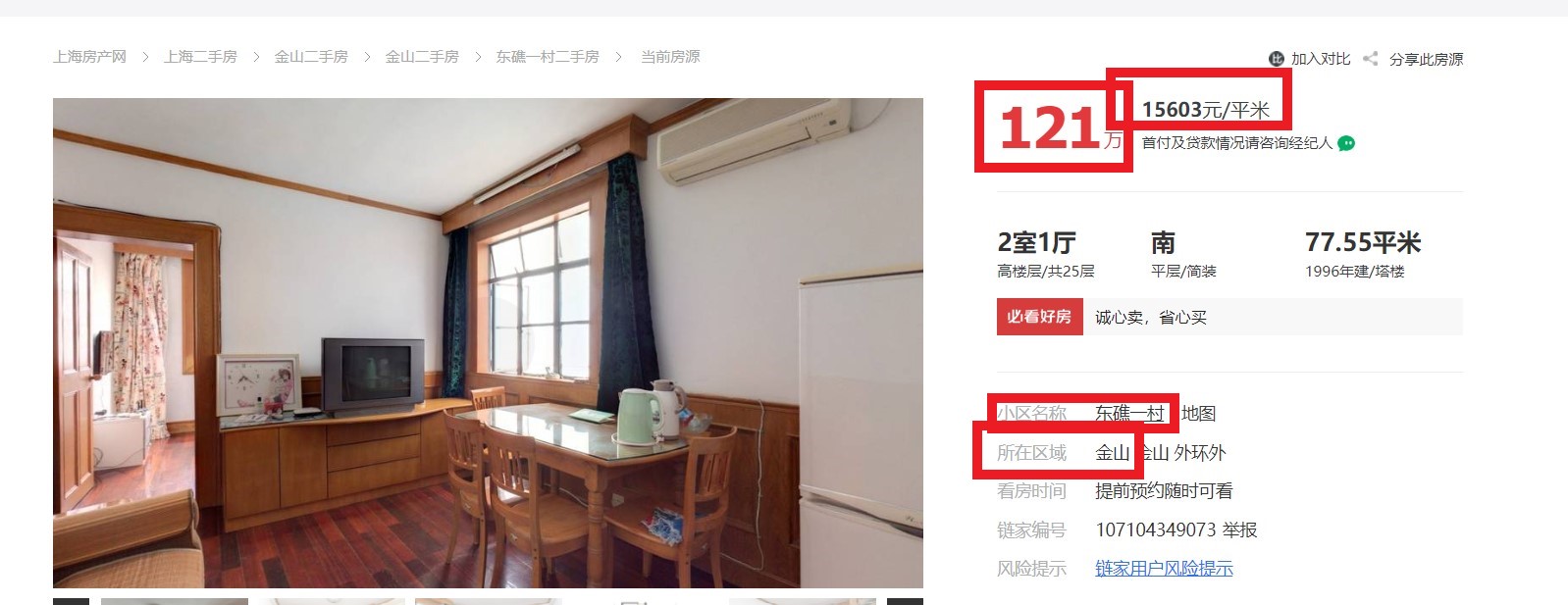
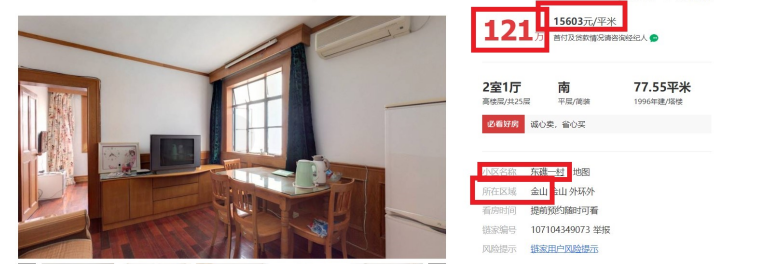
图3-2 链家网二手房主页 二手房房源信息页面如图4-3、图4-4。我们需要采集的目标数据就在该页面,包括基本信息、房屋属性和交易属性三大类。各类信息包括的数据项如下: 1)基本信息:小区名称、所在区域、总价、单价。 2)房屋属性:房屋户型、所在楼层、建筑面积、户型结构、面积、建筑类型、房屋朝向、建筑结构、装修情况 3)交易属性:挂牌时间、交易权属、上次交易、房屋用途、房屋年限、产权所属、抵押信息、房本备件。
图3-3 二手房房源信息页面
图3-4 二手房房源信息页面 3.1.2 网络爬虫程序关键问题说明1)问题1:链家网二手房主页最多只显示100页的房源数据,所以在收集二手房房源信息页面URL地址时会收集不全,导致最后只能采集到部分数据。 解决措施:将所有厦门二手房数据分区域地进行爬取,100页最多能够显示3000套房,该区域房源少于3000套时可以直接爬取,如果该区域房源超过3000套可以再分成更小的区域。 2)问题2:爬虫程序如果运行过快,会在采集到两、三千条数据时触发链家网的反爬虫机制,所有的请求会被重定向到链家的人机鉴定页面,从而会导致后面的爬取失败。 解决措施:①为程序中每次http请求构造header并且每次变换http请求header信息头中USER_AGENTS数据项的值,让请求信息看起来像是从不同浏览器发出的访问请求。②爬虫程序每处理完一次http请求和响应后,随机睡眠1-3秒,每请求2500次后,程序睡眠20分钟,控制程序的请求速度。 3.2 数据清洗对于爬虫程序采集得到的数据并不能直接分析,需要先去掉一些“脏”数据,修正一些错误数据,统一所有数据字段的格式,将这些零散的数据规整成统一的结构化数据。 4.2.1 原始数据主要需要清洗的部分 通过pandas库中的DataFrame对象进行数据清洗,通过语句df = df.dropna()来去除存在缺失值的交易记录,通过duplicated()函数删除重复值。结果如图4-5所示 主要需要清洗的数据部分如下: 1)将杂乱的记录的数据项对齐 2)清洗一些数据项格式 3)缺失值处理 1 # 数据清洗 2 def clean_data(data): 3 data = data.dropna(axis=1, how='all') # 删除全是空行列 4 # data.index = data['小区名'] 5 # del data['小区名'] 6 7 # 2.查看表格数据,一共有23677条数据。 8 print(data.describe()) 9 10 # 3.查看是否缺失 11 print(data.isnull().sum()) 12 13 # 删除重复数据 14 data = data.drop_duplicates(subset=None, keep='first', inplace=None) 15 # 删除‘暂无数据’大于一半数据的列 16 if ((data['套内面积'].isin(['暂无数据'])).sum()) > (len(data.index)) / 2: 17 del data['套内面积'] 18 19 # 把建筑面积列的单位去掉并转换成float类型 20 data['建筑面积'] = data['建筑面积'].apply(lambda x: float(x.replace('㎡', ''))) 21 22 # 提取地区 23 data['地区'] = data['地区'].apply(lambda x: x[2:-2]) 24 25 # 计算单价 26 data['单价'] = round(data['价格/万'] * 10000 / data['建筑面积'], 2) 27 data.to_excel('pure_data.xlsx', encoding='utf-8') 28 29 30 if __name__ == '__main__': 31 get_data()
3.2.2 数据清洗结果 清洗后的数据如图4-6,可以看出清洗后数据已经规整了许多。
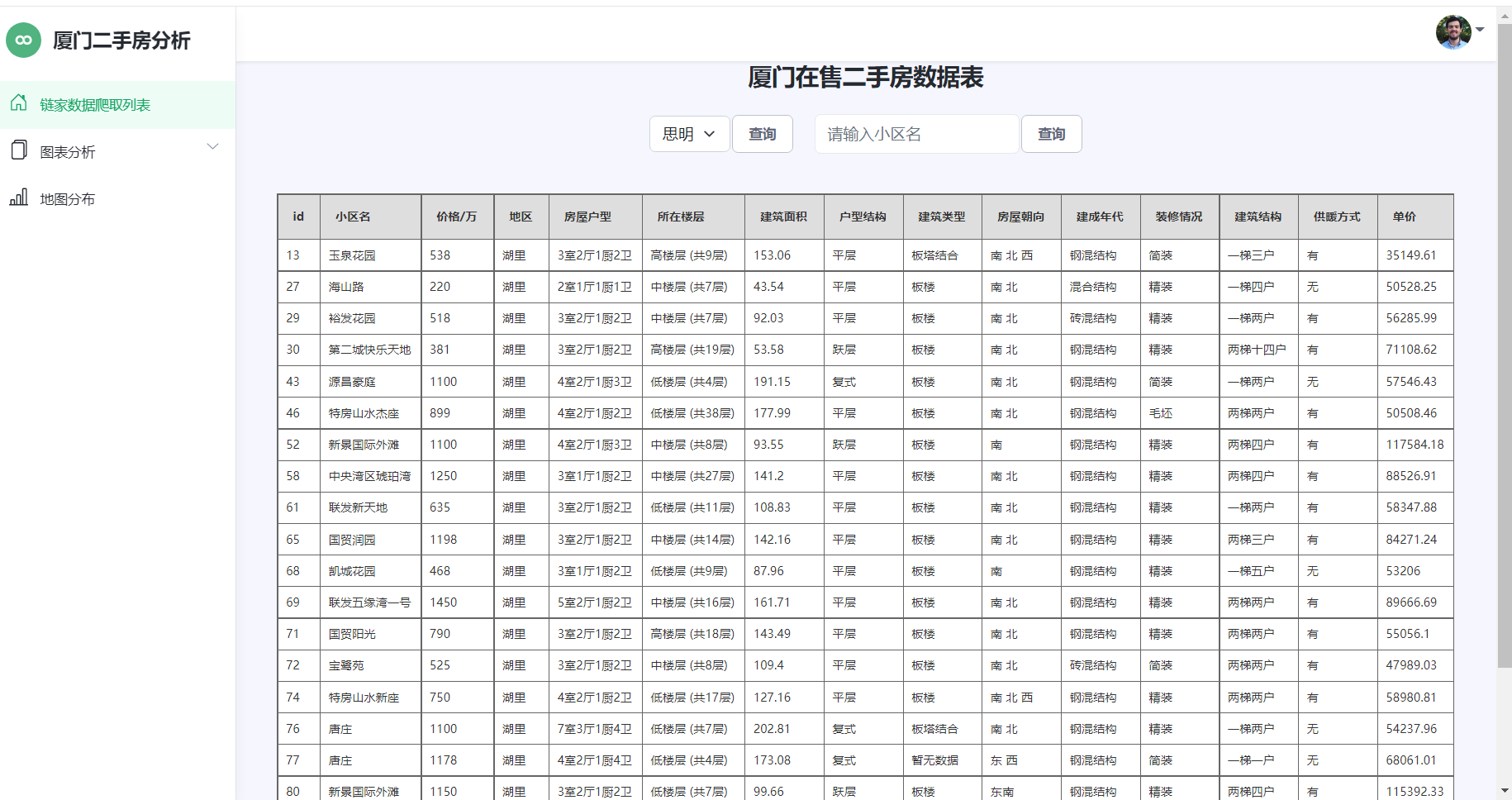
在数据清洗完成后,我们就可以开始对数据进行可视化分析。该阶段主要是对数据做一个探索性分析并将结果可视化呈现,更好、更直观的认识数据,把隐藏在大量数据背后的信息集中和提炼出来。主要对二手房房源的总价、单价、面积、户型、地区等属性进行了分析。 4.1房源信息数据展示 房源信息如下4-1所示: 1 house_list = House.objects.all().order_by('id') 2 3 input_1 = request.GET.get("searchorders") 4 5 input_2 = request.GET.get("dqchaxun") 6 7 if input_1: 8 9 house_list = House.objects.filter(xiaoquming=input_1) 10 11 paginator = Paginator(house_list, 20) 12 13 page = request.GET.get('page') 14 15 try: 16 17 data_1 = paginator.page(page) 18 19 except PageNotAnInteger: 20 21 data_1 = paginator.page(1) # 输入不是整数返回第一页 22 23 except InvalidPage: 24 25 # 找不到就重定向 26 27 return render(request, 'index.html', {'house_list': data_1, 'name': input_1}) 28 29 except EmptyPage: # 不在合法范围就返回最后一页 30 31 data_1 = paginator.page(paginator.num_pages) 32 33 return render(request, 'index.html', {'house_list': data_1, 'name': input_1})
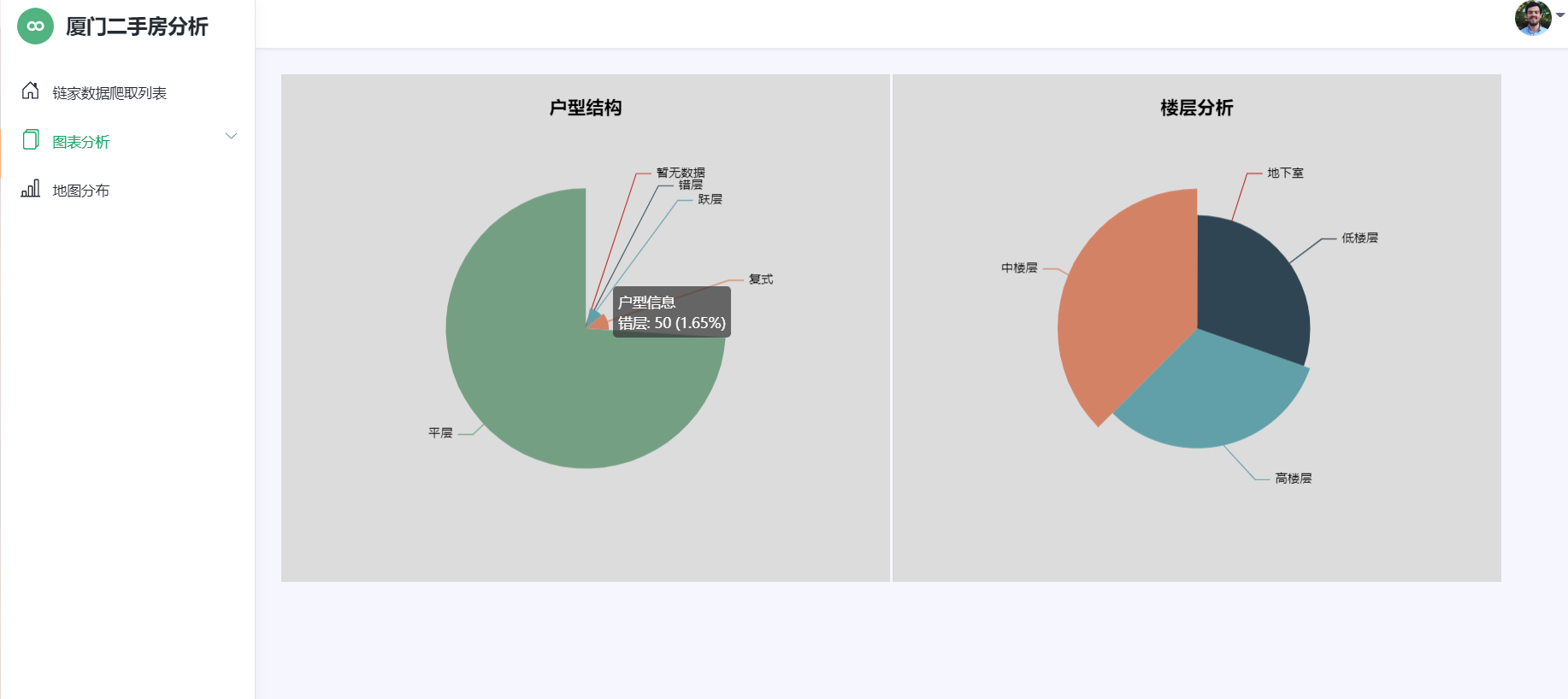
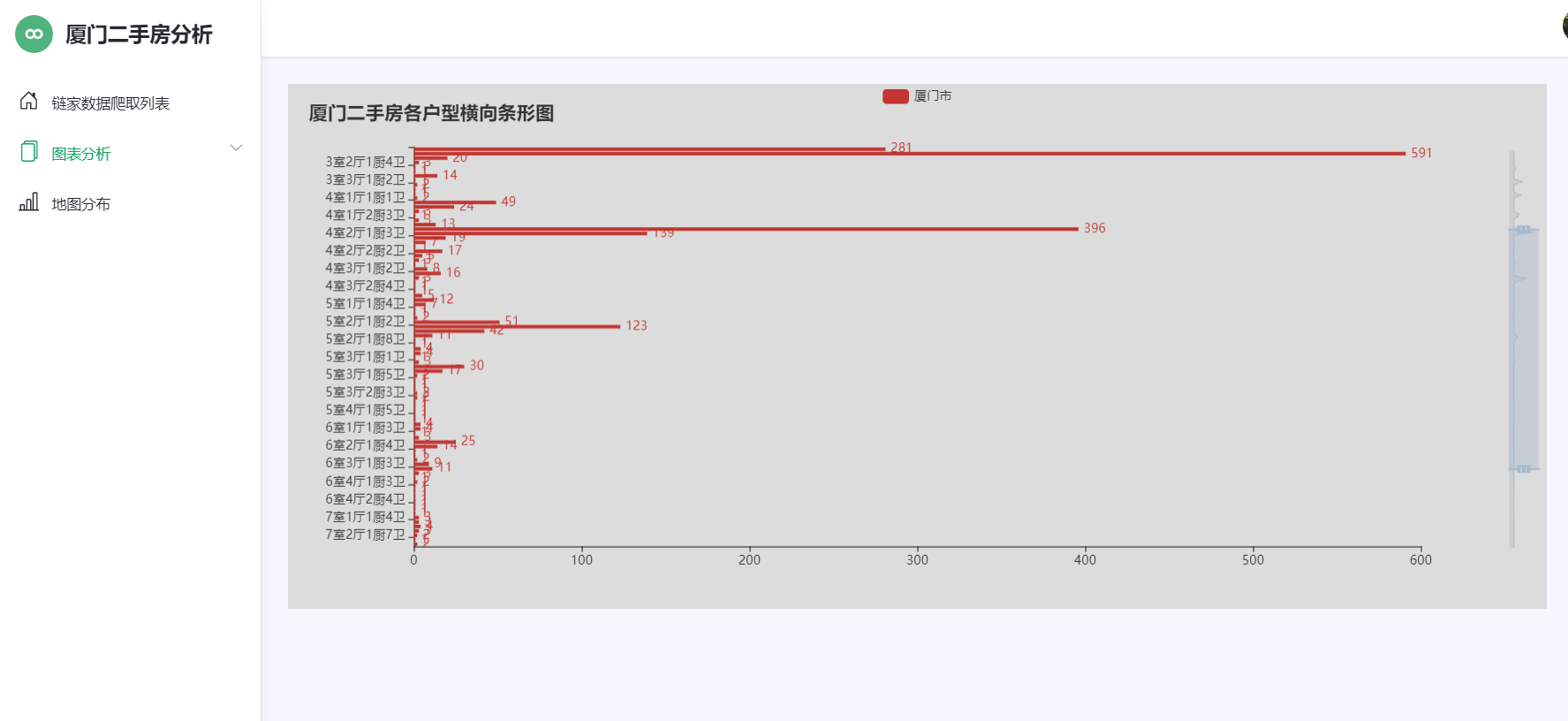
图4-1房源信息展示 4.2房源的户型结构分析 房源户型结构分析如下图5-2所示: 1 #户型分析 2 3 series = df['fangwuhuxing'].value_counts() 4 5 series.sort_index(ascending=False, inplace=True) 6 7 house_type_list = series.index.tolist() 8 9 count_list = series.values.tolist() 10 11 c = Bar(init_opts=opts.InitOpts(theme=ThemeType.CHALK)) 12 13 c.add_xaxis(house_type_list) 14 15 c.add_yaxis("厦门市", count_list) 16 17 c.reversal_axis() 18 19 c.set_series_opts(label_opts=opts.LabelOpts(position="right")) 20 21 c.set_global_opts(title_opts=opts.TitleOpts(title="厦门二手房各户型横向条形图"), 22 23 datazoom_opts=[opts.DataZoomOpts(yaxis_index=0, type_="slider", orient="vertical")], ) 24 25 c.render("户型分析-条形图.html") 26 27 #楼层分析 28 29 Pie(init_opts=opts.InitOpts(width="1600px", height="800px", bg_color="#2c343c")) 30 31 .add( 32 33 series_name="层段信息", 34 35 data_pair=data_pair, 36 37 rosetype="radius", 38 39 radius="55%", 40 41 center=["50%", "50%"], 42 43 label_opts=opts.LabelOpts(is_show=False, position="center"), 44 45 ) 46 47 .set_global_opts( 48 49 title_opts=opts.TitleOpts( 50 51 title="Customized Pie", 52 53 pos_left="center", 54 55 pos_top="20", 56 57 title_textstyle_opts=opts.TextStyleOpts(color="#fff"), 58 59 ), 60 61 legend_opts=opts.LegendOpts(is_show=False), 62 63 ) 64 65 .set_series_opts( 66 67 tooltip_opts=opts.TooltipOpts( 68 69 trigger="item", formatter="{a} {b}: {c} ({d}%)" 70 71 ), 72 73 label_opts=opts.LabelOpts(color="rgba(255, 255, 255, 0.3)"), 74 75 )
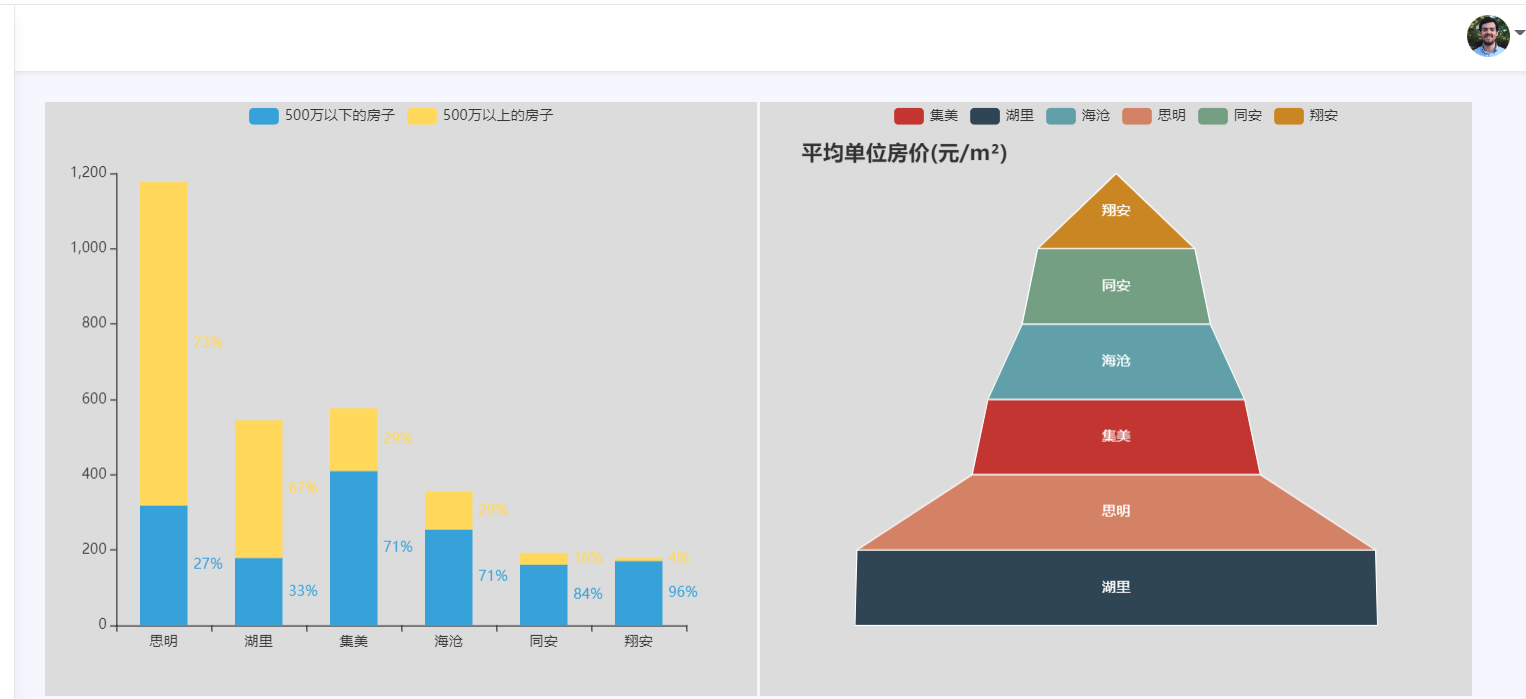
图4-2房源户型结构分析 4.4房源的平均单价分析 房源平均单价如4-3所示: 1 #房源的平均单价分析 2 3 city = [] 4 5 unit_price = [] 6 7 for index in df['diqu']: 8 9 city.append(index) 10 11 for index in df['jiage']: 12 13 unit_price.append(index) 14 15 last_city = list(set(city)) 16 17 new_unit_price = [[] for i in range(len(last_city))] 18 19 last_unit_price = [] 20 21 for i in range(len(unit_price)): 22 23 for j in range(len(last_city)): 24 25 if city[i] == last_city[j]: 26 27 new_unit_price[j].append(int(unit_price[i])) 28 29 for index in new_unit_price: 30 31 result = sum(index)/len(index) 32 33 last_unit_price.append('%.2f' % result) 34 35 c = ( 36 37 Funnel() 38 39 .add( 40 41 "平均单价", 42 43 [list(z) for z in zip(last_city, last_unit_price)], 44 45 sort_="ascending", 46 47 label_opts=opts.LabelOpts(position="inside"), 48 49 ) 50 51 .set_global_opts(title_opts=opts.TitleOpts(title="平均单位房价(元/m²)")) 52 53 .render("平均单位房价-漏斗图.html") 54 55 )
图4-3房源平均单价 4.5房源各户型横向图分析 房源各户型分析如4-5: 1 # 2 3 series = df['fangwuhuxing'].value_counts() 4 5 series.sort_index(ascending=False, inplace=True) 6 7 house_type_list = series.index.tolist() 8 9 count_list = series.values.tolist() 10 11 c = Bar(init_opts=opts.InitOpts(theme=ThemeType.CHALK)) 12 13 c.add_xaxis(house_type_list) 14 15 c.add_yaxis("厦门市", count_list) 16 17 c.reversal_axis() 18 19 c.set_series_opts(label_opts=opts.LabelOpts(position="right")) 20 21 c.set_global_opts(title_opts=opts.TitleOpts(title="厦门二手房各户型横向条形图"), 22 23 datazoom_opts=[opts.DataZoomOpts(yaxis_index=0, type_="slider", orient="vertical")], ) 24 25 c.render("户型分析-条形图.html")
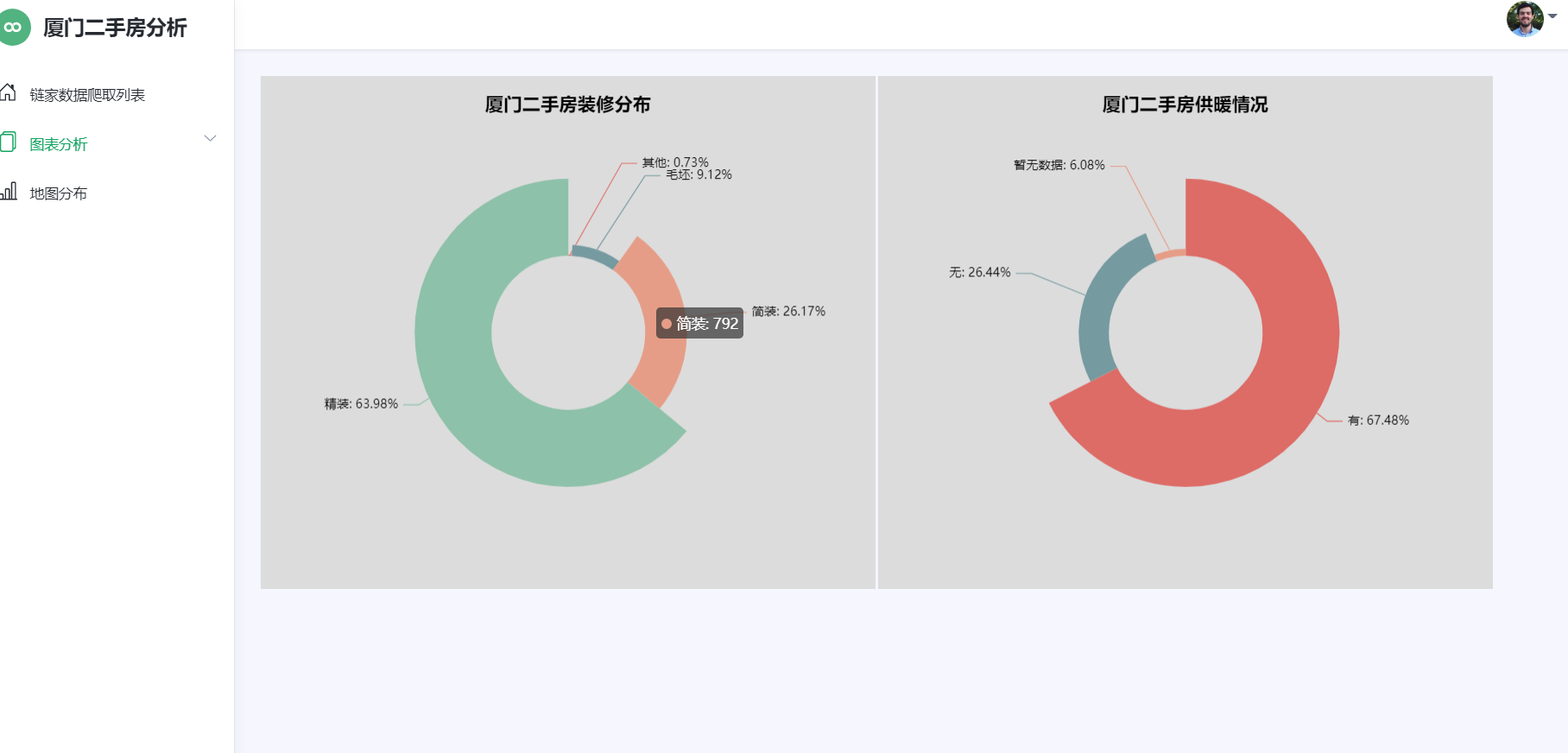
图4-5房源各户型图 4.6房源装修程度分析 房源装修程度如下如4-6所示: 1 # 2 3 series = df['fangwuhuxing'].value_counts() 4 5 series.sort_index(ascending=False, inplace=True) 6 7 house_type_list = series.index.tolist() 8 9 count_list = series.values.tolist() 10 11 c = Bar(init_opts=opts.InitOpts(theme=ThemeType.CHALK)) 12 13 c.add_xaxis(house_type_list) 14 15 c.add_yaxis("厦门市", count_list) 16 17 c.reversal_axis() 18 19 c.set_series_opts(label_opts=opts.LabelOpts(position="right")) 20 21 c.set_global_opts(title_opts=opts.TitleOpts(title="厦门二手房各户型横向条形图"), 22 23 datazoom_opts=[opts.DataZoomOpts(yaxis_index=0, type_="slider", orient="vertical")], ) 24 25 c.render("户型分析-条形图.html")
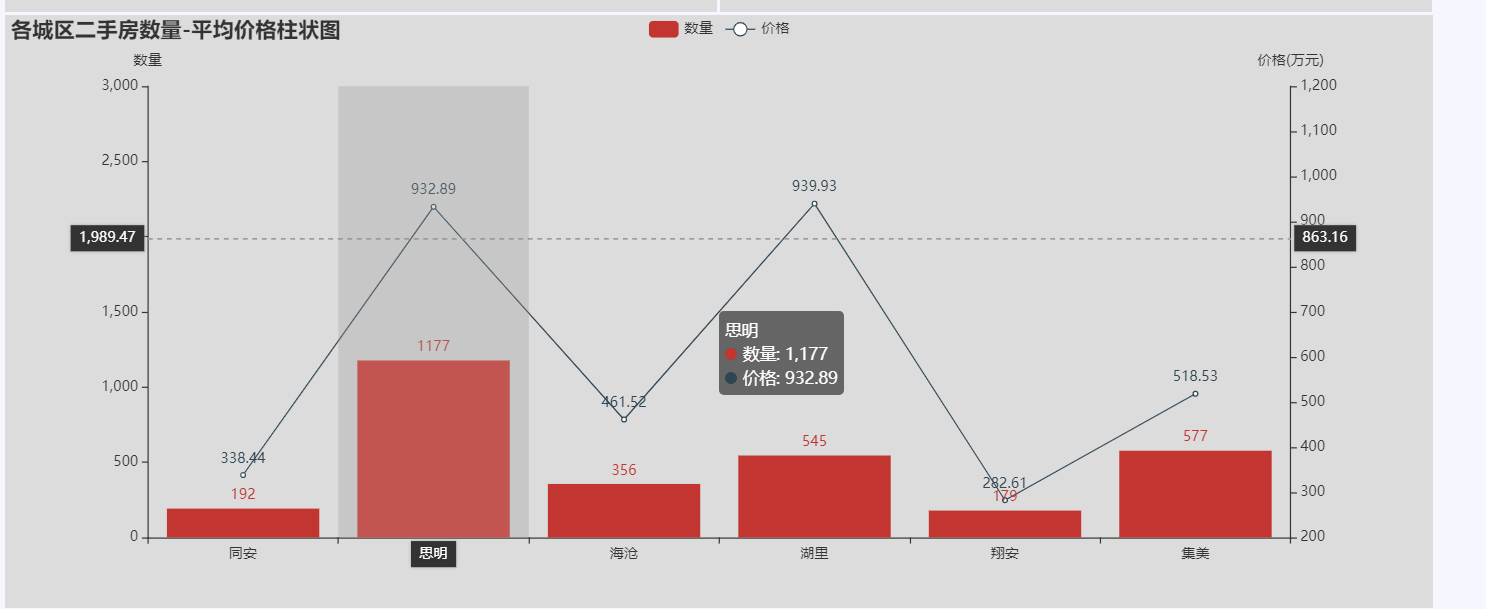
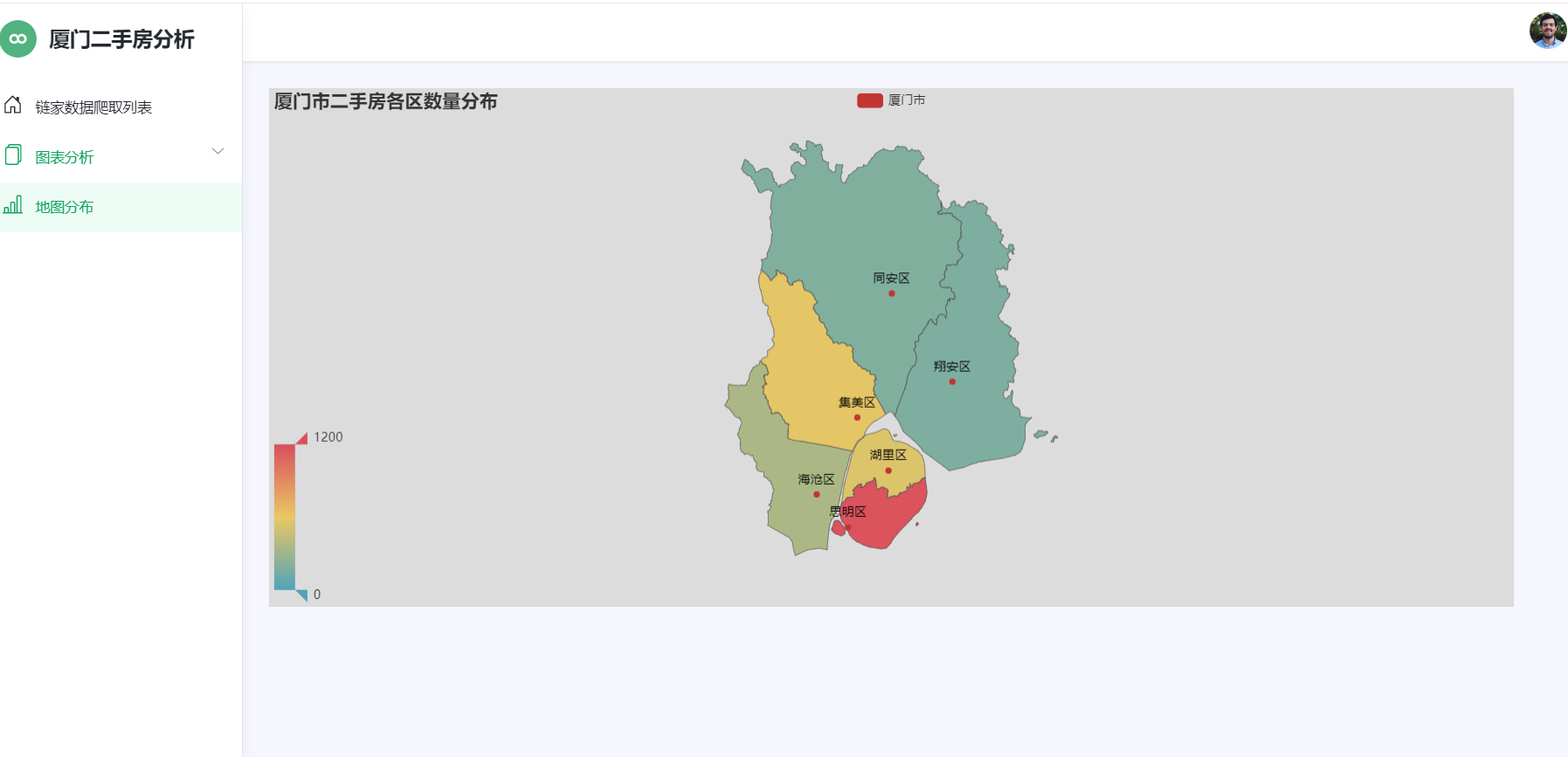
图4-6房源装修程度分析图 4.7厦门各区域房源分布 各区域房源分布如图4-7所示: 1 # 5.统计各城区二手房数量 2 3 df = pd.read_excel(r'pure_data.xlsx') 4 5 g = df.groupby('diqu') 6 7 df_region = g['xiaoquming'].count() 8 9 region = df_region.index.tolist() 10 11 list_region = [] 12 13 for row in region: 14 15 list_region.append(row + '区') 16 17 count = df_region.values.tolist() 18 19 print(df_region) 20 21 map = ( 22 23 Map() 24 25 .add(series_name='厦门市', data_pair=[list(z) for z in zip(list_region, count)], maptype='厦门') 26 27 .set_global_opts( 28 29 title_opts=opts.TitleOpts(title='厦门市二手房各区数量分布'), 30 31 visualmap_opts=opts.VisualMapOpts(is_show=True, min_=0, max_=1200) 32 33 ) 34 35 ) 36 37 map.render('地图-二手房数量分布地图.html')
图4-7各区域房源分布图 附完整代码 1 import requests,time,csv 2 import pandas as pd 3 from lxml import etree 4 5 #获取每一页的url 6 def Get_url(url): 7 all_url=[] 8 for i in range(1,101): 9 all_url.append(url+'pg'+str(i)+'/') #储存每一个页面的url 10 return all_url 11 12 #获取每套房详情信息的url 13 def Get_house_url(all_url,headers): 14 num=0 15 #简单统计页数 16 for i in all_url: 17 r=requests.get(i,headers=headers) 18 html=etree.HTML(r.text) 19 url_ls=html.xpath("//ul[@class='sellListContent']/li/a/@href") #获取房子的url 20 Analysis_html(url_ls,headers) 21 time.sleep(4) 22 print("第%s页爬完了"%i) 23 num+=1 24 25 #获取每套房的详情信息 26 def Analysis_html(url_ls,headers): 27 for i in url_ls: #num记录爬取成功的索引值 28 r=requests.get(i,headers=headers) 29 html=etree.HTML(r.text) 30 name=(html.xpath("//div[@class='communityName']/a/text()"))[0].split() #获取房名 31 money = html.xpath("//span[@class='total']/text()" )# 获取价格 32 area = html.xpath("//span[@class='info']/a[1]/text()") # 获取地区 33 data = html.xpath("//div[@class='content']/ul/li/text()")# 获取房子基本属性 34 35 Save_data(name,money,area,data) 36 37 #把爬取的信息存入文件 38 def Save_data(name, money, area, data): 39 result=[name[0]]+money+[area]+data #把详细信息合为一个列表 40 with open(r'raw_data.csv','a',encoding='utf_8_sig',newline='')as f: 41 wt=csv.writer(f) 42 wt.writerow(result) 43 print('已写入') 44 f.close() 45 46 if __name__=='__main__': 47 url='https://xm.lianjia.com/ershoufang/' 48 headers={ 49 "Upgrade-Insecure-Requests":"1", 50 "User-Agent":"Mozilla/5.0(Windows NT 10.0;Win64;x64) AppleWebKit/537.36(KHTML,like Gecko)Chrome" 51 "/72.0.3626.121 Safari/537.36" 52 } 53 all_url=Get_url(url) 54 with open(r'raw_data.csv', 'a', encoding='utf_8_sig', newline='') as f: 55 #首先加入表格头 56 table_label=['小区名','价格/万','地区','房屋户型','所在楼层','建筑面积','户型结构','套内面积','建筑类型','房屋朝向' 57 ,'建成年代','装修情况','建筑结构','供暖方式'] 58 wt=csv.writer(f) 59 wt.writerow(table_label) 60 Get_house_url(all_url,headers) 61 62 # encoding: utf-8 63 64 import pandas as pd 65 66 67 # 从保存的文本中获取数据 68 def get_data(): 69 raw_data = pd.DataFrame(pd.read_excel('raw_data.xlsx')) 70 print("数据清洗前共有%s条数据" % raw_data.size) 71 clean_data(raw_data) 72 73 74 # 数据清洗 75 def clean_data(data): 76 data = data.dropna(axis=1, how='all') # 删除全是空行列 77 # data.index = data['小区名'] 78 # del data['小区名'] 79 80 # 2.查看表格数据,一共有23677条数据。 81 print(data.describe()) 82 83 # 3.查看是否缺失 84 print(data.isnull().sum()) 85 86 # 删除重复数据 87 data = data.drop_duplicates(subset=None, keep='first', inplace=None) 88 # 删除‘暂无数据’大于一半数据的列 89 if ((data['套内面积'].isin(['暂无数据'])).sum()) > (len(data.index)) / 2: 90 del data['套内面积'] 91 92 # 把建筑面积列的单位去掉并转换成float类型 93 data['建筑面积'] = data['建筑面积'].apply(lambda x: float(x.replace('㎡', ''))) 94 95 # 提取地区 96 data['地区'] = data['地区'].apply(lambda x: x[2:-2]) 97 98 # 计算单价 99 data['单价'] = round(data['价格/万'] * 10000 / data['建筑面积'], 2) 100 data.to_excel('pure_data.xlsx', encoding='utf-8') 101 102 103 if __name__ == '__main__': 104 get_data() 105 106 import pandas as pd 107 from pyecharts.charts import Map 108 from pyecharts import options as opts 109 110 if __name__ == '__main__': 111 # 5.统计各城区二手房数量 112 df = pd.read_excel(r'pure_data.xlsx') 113 g = df.groupby('diqu') 114 df_region = g['xiaoquming'].count() 115 region = df_region.index.tolist() 116 list_region = [] 117 for row in region: 118 list_region.append(row + '区') 119 count = df_region.values.tolist() 120 print(df_region) 121 map = ( 122 Map() 123 .add(series_name='厦门市', data_pair=[list(z) for z in zip(list_region, count)], maptype='厦门') 124 .set_global_opts( 125 title_opts=opts.TitleOpts(title='厦门市二手房各区数量分布'), 126 visualmap_opts=opts.VisualMapOpts(is_show=True, min_=0, max_=1200) 127 ) 128 ) 129 map.render('地图-二手房数量分布地图.html') 130 131 from pyecharts import options as opts 132 from pyecharts.charts import Bar 133 from pyecharts.commons.utils import JsCode 134 from pyecharts.globals import ThemeType 135 import pandas as pd 136 137 try: 138 df = pd.read_excel(r'pure_data.xlsx') 139 except: 140 df = pd.read_excel(r'pure_data.xlsx') 141 city_lst = ['思明', '湖里', '集美', '海沧', '同安', '翔安'] # 地区 142 city = [] # 城市 143 # buildTime = [] # 建房时期 144 vules = [] # 价格 145 # new_buildTime = [[[], []] for i in range(6)] 146 new_vules=[[[], []] for i in range(6)] 147 data1 = [] 148 data2 = [] 149 for index in df['diqu']: 150 city.append(index) 151 for index in df['jiage']: 152 # buildTime.append(index) 153 vules.append(index) 154 for index in range(len(city)): 155 for num in range(len(city_lst)): 156 if city[index] == city_lst[num]: 157 if int(vules[index]) >= 500: 158 new_vules[num][1].append(vules[index]) 159 else: 160 new_vules[num][0].append(vules[index]) 161 for g in range(len(new_vules)): 162 value1 = len(new_vules[g][0]) 163 value2 = len(new_vules[g][1]) 164 result1 = {'value': value1, 'percent': '%.2f' % (value1 / (value1 + value2))} 165 result2 = {'value': value2, 'percent': '%.2f' % (value2 / (value1 + value2))} 166 data1.append(result1) 167 data2.append(result2) 168 print(data1) 169 print(data2) 170 171 c = ( 172 Bar(init_opts=opts.InitOpts(theme=ThemeType.LIGHT)) 173 .add_xaxis(city_lst) 174 .add_yaxis("500万以下的房子", data1, stack="stack1", category_gap="50%") 175 .add_yaxis("500万以上的房子", data2, stack="stack1", category_gap="50%") 176 .set_series_opts( 177 label_opts=opts.LabelOpts( 178 position="right", 179 formatter=JsCode( 180 "function(x){return Number(x.data.percent * 100).toFixed() + '%';}" 181 ), 182 ) 183 ) 184 .render("价格分析-堆叠柱状图.html") 185 ) 186 187 188 import pandas as pd 189 from pyecharts.charts import Bar 190 from pyecharts.globals import ThemeType 191 import pyecharts.options as opts 192 193 try: 194 df = pd.read_excel(r'pure_data.xlsx') 195 except: 196 df = pd.read_excel(r'pure_data.xlsx', encoding='gbk') 197 198 series = df['fangwuhuxing'].value_counts() 199 series.sort_index(ascending=False, inplace=True) 200 house_type_list = series.index.tolist() 201 count_list = series.values.tolist() 202 203 c = Bar(init_opts=opts.InitOpts(theme=ThemeType.CHALK)) 204 c.add_xaxis(house_type_list) 205 c.add_yaxis("厦门市", count_list) 206 c.reversal_axis() 207 c.set_series_opts(label_opts=opts.LabelOpts(position="right")) 208 c.set_global_opts(title_opts=opts.TitleOpts(title="厦门二手房各户型横向条形图"), 209 datazoom_opts=[opts.DataZoomOpts(yaxis_index=0, type_="slider", orient="vertical")], ) 210 211 c.render("户型分析-条形图.html") 212 c.render_notebook() 213 214 import pandas as pd 215 from pyecharts import options as opts 216 from pyecharts.charts import Funnel 217 218 try: 219 df = pd.read_excel(r'pure_data.xlsx') 220 except: 221 df = pd.read_excel(r'pure_data.xlsx', encoding='gbk') 222 df.drop_duplicates(subset=None, keep='first', inplace=True) 223 city = [] 224 unit_price = [] 225 for index in df['diqu']: 226 city.append(index) 227 for index in df['jiage']: 228 unit_price.append(index) 229 last_city = list(set(city)) 230 new_unit_price = [[] for i in range(len(last_city))] 231 last_unit_price = [] 232 for i in range(len(unit_price)): 233 for j in range(len(last_city)): 234 if city[i] == last_city[j]: 235 new_unit_price[j].append(int(unit_price[i])) 236 for index in new_unit_price: 237 result = sum(index)/len(index) 238 last_unit_price.append('%.2f' % result) 239 240 c = ( 241 Funnel() 242 .add( 243 "平均单价", 244 [list(z) for z in zip(last_city, last_unit_price)], 245 sort_="ascending", 246 label_opts=opts.LabelOpts(position="inside"), 247 ) 248 .set_global_opts(title_opts=opts.TitleOpts(title="平均单位房价(元/m²)")) 249 .render("平均单位房价-漏斗图.html") 250 ) 251 252 253 import pandas as pd 254 from pyecharts.charts import * 255 from pyecharts import options as opts 256 257 try: 258 df = pd.read_excel(r'pure_data.xlsx') 259 except: 260 df = pd.read_excel(r'pure_data.xlsx', encoding='gbk') 261 262 Elevator_num = df.groupby(['gongnuanfangshi'])['diqu'].count().reset_index() 263 data_pair = sorted([(row['gongnuanfangshi'], row['diqu']) 264 for _, row in Elevator_num.iterrows()], key=lambda x: x[1], reverse=True) 265 pie = Pie(init_opts=opts.InitOpts(theme='dark')) 266 pie.add('', data_pair, radius=["30%", "75%"], rosetype="radius") 267 pie.set_global_opts(title_opts=opts.TitleOpts(title="厦门二手房供暖情况", pos_left="center", 268 title_textstyle_opts=opts.TextStyleOpts(color="#000"), ), 269 legend_opts=opts.LegendOpts(is_show=False), ) 270 pie.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {d}%")) 271 272 pie.render_notebook() 273 pie.render("玫瑰饼图-有无供暖.html") 274 275 276 import pandas as pd 277 from pyecharts.charts import * 278 from pyecharts import options as opts 279 280 281 try: 282 df = pd.read_excel(r'pure_data.xlsx') 283 except: 284 df = pd.read_excel(r'pure_data.xlsx', encoding='gbk') 285 286 Renovation_num = df.groupby(['zhaungxiuqingkuang'])['diqu'].count().reset_index() 287 data_pair_num = sorted([(row['zhaungxiuqingkuang'], row['diqu']) 288 for _, row in Renovation_num.iterrows()], key=lambda x: x[0], reverse=False) 289 290 pie = Pie(init_opts=opts.InitOpts(theme='dark')) 291 pie.add('', data_pair_num,radius=["30%", "75%"],rosetype="radius") 292 pie.set_global_opts(title_opts=opts.TitleOpts(title="厦门二手房装修分布",pos_left="center",title_textstyle_opts=opts.TextStyleOpts(color="#fff"),), 293 legend_opts=opts.LegendOpts(is_show=False),) 294 pie.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {d}%")) 295 296 pie.render("玫瑰饼图-房屋装修情况.html") 297 pie.render_notebook() 298 299 import pandas as pd 300 from pyecharts.charts import Bar 301 from pyecharts.charts import Line 302 from pyecharts.charts import Grid 303 from pyecharts import options as opts 304 305 if __name__ == '__main__': 306 df = pd.read_excel(r'pure_data.xlsx') 307 # 6.可视化展示-北京各城区二手房数量-平均价格柱状图 308 g = df.groupby('diqu') 309 df_region = g['xiaoquming'].count() 310 region = df_region.index.tolist() 311 list_region = [] 312 for row in region: 313 list_region.append(row + '区') 314 count = df_region.values.tolist() 315 print(df_region) 316 mean = g.mean() 317 price = round(mean['jiage'], 2) 318 mean_price = price.values.tolist() 319 print(mean_price) 320 321 # 实例化一个柱形图对象 322 bar = (Bar().add_xaxis(xaxis_data=region)) 323 bar.add_yaxis(series_name='数量', y_axis=count) 324 bar.extend_axis(yaxis=opts.AxisOpts(name='价格(万元)', max_=1200, min_=200, interval=100)) 325 bar.set_global_opts(title_opts=opts.TitleOpts(title='各城区二手房数量-平均价格柱状图'), 326 yaxis_opts=opts.AxisOpts(name='数量', max_=3000, min_=0), 327 tooltip_opts=opts.TooltipOpts(trigger='axis', axis_pointer_type='cross'), 328 xaxis_opts=opts.AxisOpts(axispointer_opts=opts.AxisPointerOpts(is_show=True, type_='shadow')), ) 329 # 实例化一个折线图 330 line = (Line().add_xaxis(xaxis_data=region)) 331 line.add_yaxis(series_name='价格', y_axis=mean_price, yaxis_index=1) 332 333 # 组合图 334 bar.overlap(line) 335 grid = Grid() 336 grid.add(bar, grid_opts=opts.GridOpts(), is_control_axis_index=True) 337 grid.render('二手房数量-平均价格柱状图.html') 338 339 340 import pandas as pd 341 import pyecharts.options as opts 342 from pyecharts.charts import Pie 343 344 df = pd.read_excel(r'pure_data.xlsx') 345 df.drop(df[df['suozailouceng'].str.contains('suozailouceng')].index, inplace=True) 346 data_heigh = df['suozailouceng'] 347 lst_height_value = data_heigh.value_counts().keys().tolist() 348 lst_counts = data_heigh.value_counts().tolist() 349 350 351 def get_pie(): 352 x_data = lst_height_value 353 y_data = lst_counts 354 data_pair = [list(z) for z in zip(x_data, y_data)] 355 data_pair.sort(key=lambda x: x[1]) 356 357 c = ( 358 Pie(init_opts=opts.InitOpts(width="1600px", height="800px", bg_color="#2c343c")) 359 .add( 360 series_name="层段信息", 361 data_pair=data_pair, 362 rosetype="radius", 363 radius="55%", 364 center=["50%", "50%"], 365 label_opts=opts.LabelOpts(is_show=False, position="center"), 366 ) 367 .set_global_opts( 368 title_opts=opts.TitleOpts( 369 title="Customized Pie", 370 pos_left="center", 371 pos_top="20", 372 title_textstyle_opts=opts.TextStyleOpts(color="#fff"), 373 ), 374 legend_opts=opts.LegendOpts(is_show=False), 375 ) 376 .set_series_opts( 377 tooltip_opts=opts.TooltipOpts( 378 trigger="item", formatter="{a} {b}: {c} ({d}%)" 379 ), 380 label_opts=opts.LabelOpts(color="rgba(255, 255, 255, 0.3)"), 381 ) 382 383 ) 384 return c 385 386 387 if __name__ == '__main__': 388 get_pie().render('楼层分析-饼状图.html') 389 390 391 import pandas as pd 392 import pyecharts.options as opts 393 from pyecharts.charts import Pie 394 395 df = pd.read_excel(r'pure_data.xlsx') 396 df.drop(df[df['huxingjiegou'].str.contains('huxingjiegou')].index, inplace=True) 397 data_heigh = df['huxingjiegou'] 398 lst_height_value = data_heigh.value_counts().keys().tolist() 399 lst_counts = data_heigh.value_counts().tolist() 400 401 402 def get_pie(): 403 x_data = lst_height_value 404 y_data = lst_counts 405 data_pair = [list(z) for z in zip(x_data, y_data)] 406 data_pair.sort(key=lambda x: x[1]) 407 408 c = ( 409 Pie(init_opts=opts.InitOpts(width="1600px", height="800px", bg_color="#2c343c")) 410 .add( 411 series_name="户型信息", 412 data_pair=data_pair, 413 rosetype="radius", 414 radius="55%", 415 center=["50%", "50%"], 416 label_opts=opts.LabelOpts(is_show=False, position="center"), 417 ) 418 .set_global_opts( 419 title_opts=opts.TitleOpts( 420 title="Customized Pie", 421 pos_left="center", 422 pos_top="20", 423 title_textstyle_opts=opts.TextStyleOpts(color="#fff"), 424 ), 425 legend_opts=opts.LegendOpts(is_show=False), 426 ) 427 .set_series_opts( 428 tooltip_opts=opts.TooltipOpts( 429 trigger="item", formatter="{a} {b}: {c} ({d}%)" 430 ), 431 label_opts=opts.LabelOpts(color="rgba(255, 255, 255, 0.3)"), 432 ) 433 434 ) 435 return c 436 437 438 if __name__ == '__main__': 439 get_pie().render('户型结构-饼状图.html')五、总结(10 分) 感谢我们专业课老师的悉心教导,是他在我们感到困惑的时候一遍又一遍给我们耐心的讲解,这让我们学到很多专业知识。 此次我的项目收集了厦门市二手房信息,在收集数据的时候我采用了python网络爬虫技术、python数据分析技术。数据分析的流程是需求分析,然后是数据获取,对获取的数据进行数据预处理。首先我采用统计分析的方法对数据进行初步分析,大致了解整体二手房的情况,交易量分析,区域特征分析,户型分析,装修方面分析,房屋朝向分析,房价分布及其影响因素;随后调用百度地图API,编程实现数据地图可视化,并获取了具体的地址和重要的距离数据。 我们要的不是数据,而是数据告诉我们的事实。大多数人面临这样一个挑战:我们认识到数据可视化的必要性,但缺乏数据可视化方面的专业技能。部分原因可以归结于,数据可视化只是数据分析过程中的一个环节,数据分析师可能将精力花在获取数据、清洗整理数据、分析数据、建立模型。 大多数时候我们汇报工作就是要做好解释性分析的工作。一个完整的数据可视化过程,主要包括以下4个步骤:确定数据可视化的主题;提炼可视化主题的数据;根据数据关系确定图表;进行可视化布局及设计。 通过本次课程设计让我通过所学到的专业知识完成数据分析,在遇到困难时我通过网络查询资料以及向老师请教和同学们讨论解决了困难,比如在爬取数据时;问题1:链家网二手房主页最多只显示100页的房源数据,所以在收集二手房房源信息页面URL地址时会收集不全,导致最后只能采集到部分数据。解决措施:将所有上海二手房数据分区域地进行爬取,100页最多能够显示3000套房,该区域房源少于3000套时可以直接爬取,如果该区域房源超过3000套可以再分成更小的区域。问题2:爬虫程序如果运行过快,会在采集到两、三千条数据时触发链家网的反爬虫机制,所有的请求会被重定向到链家的人机鉴定页面,从而会导致后面的爬取失败。解决措施:①为程序中每次http请求构造header并且每次变换http请求header信息头中USER_AGENTS数据项的值,让请求信息看起来像是从不同浏览器发出的访问请求。②爬虫程序每处理完一次http请求和响应后,随机睡眠1-3秒,每请求2500次后,程序睡眠20分钟,控制程序的请求速度。在绘制图形时;图形有时候不能显示,因此我们需要添加这个语句“plt.rcParams['font.sans-serif']=['SimHei']”才能将图形显示出来。同时此次的实训还存在很多不足的地方,希望老师可以帮我指出问题,让我学到更多的知识 |

【本文地址】
今日新闻 |
推荐新闻 |