数据科学理论基础知识汇总 |
您所在的位置:网站首页 › 数据科学基础实践教程223章答案解析大全 › 数据科学理论基础知识汇总 |
数据科学理论基础知识汇总
|
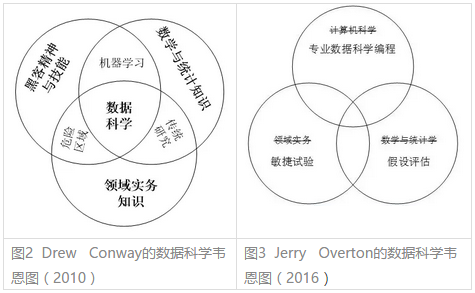
目录 前言 一、数据科学的学科地位 二、统计学 2.1 统计学与数据科学 2.2 数据科学中常用的统计学知识 2.3 数据科学视角下的统计学 三、机器学习 3.1 机器学习与数据科学 3.2 数据科学中常用的机器学习知识 3.3 数据科学视角下的机器学习 四、数据可视化 五、总结 前言数据科学不是以一个特定理论(如统计学、机器学习和数据可视化)为基础发展起来的,而是包括数学与统计学、特定学科领域理论在内相互融合后形成的新兴学科。本文将对数据科学的理论基础(统计学、机器学习、数据可视化、某一领域实务知识与经验)作一个简要介绍。 一、数据科学的学科地位从学科定位看,数据科学处于数学与统计知识、黑客精神与技能和领域实务知识三大区域的重叠之处,如图2所示。图2是Drew Conway首次提出数据科学韦恩图。图3是后来Jerry Overton提出的另一个版本。
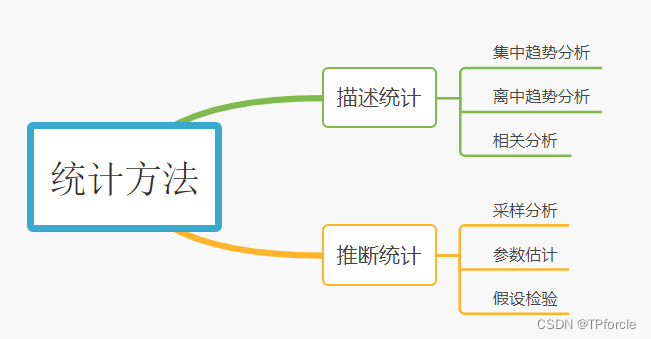
"数据与统计知识"是数据科学的主要理论基础之一,但数据科学与(传统)数学和统计学是有区别的。其主要区别如下: 数据学科中的“数据” != “数值” and “数据” != “数值” 数据科学中的“计算” != “加、减、乘、除等数学运算”,还包括数据的查询、挖掘、洞见、分析、可视化等更多类型 数据科学的问题 != “单一学科”的问题,还涉及到多个学科的研究范畴,它强调的是跨学科视角 数据学科 != 纯理论研究 and 数据学科 != 领域实务知识,它关注和强调的是二者的结合。“黑客精神与技能”是数据科学家的主要精神追求和技能要求 --- 大胆创新、喜欢挑战、追求完美和不断改进。 Tips : 此处涉及到黑客道德准则,感兴趣的朋友可以查阅史蒂夫 · 利维的代表作《黑客---计算机革命的英雄》。 “领域实务知识”是对数据科学家的特殊要求 --- 不仅需要掌握数学与统计知识以及具备黑客精神与技能,而且还需要精通某一个特定领域的实务知识与经验。 二、统计学 2.1 统计学与数据科学数据科学的理论、方法、技术和工具往往来源于统计学。统计学是数据科学的主要理论基础之一。 2.2 数据科学中常用的统计学知识从行为目的与思维方式看,数据统计方法可以分为两大类---描述统计和推断统计。
其中参数估计与假设检验的主要区别如下:
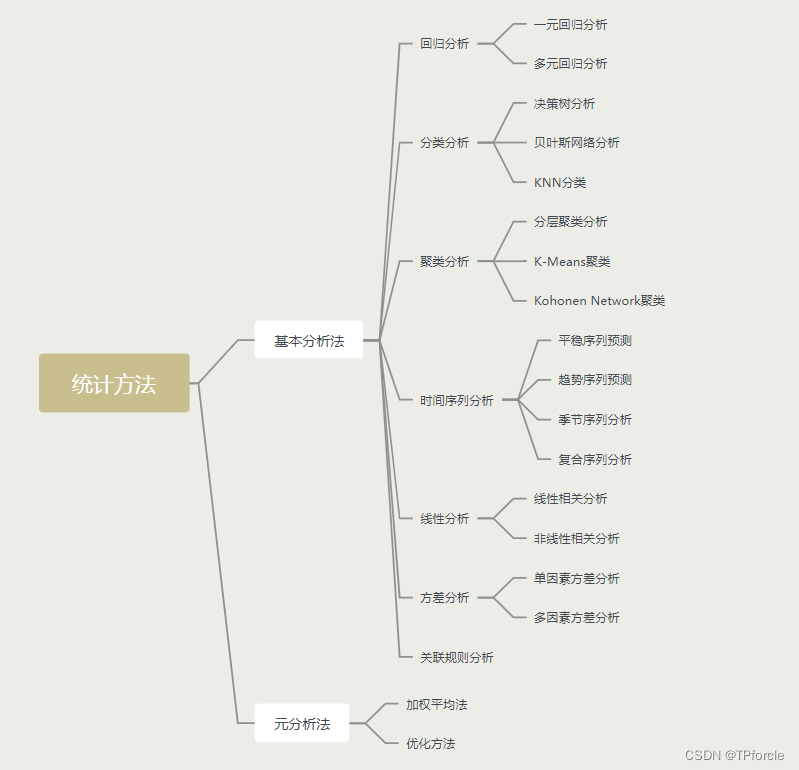
从方法论角度看,基于统计的数据分析方法又可分为两个不同层次---基本分析法和元分析方法,如下图所示:
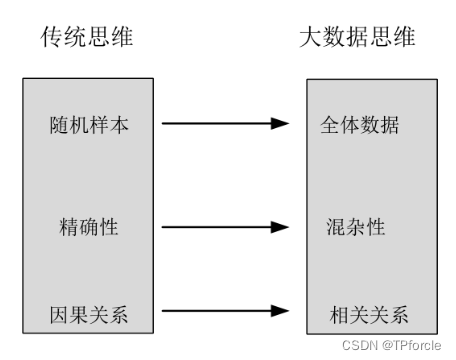
1.不是随机样本,而是全体数据 2.不是精确性,而是混杂性 3.不是因果关系,而是相关关系
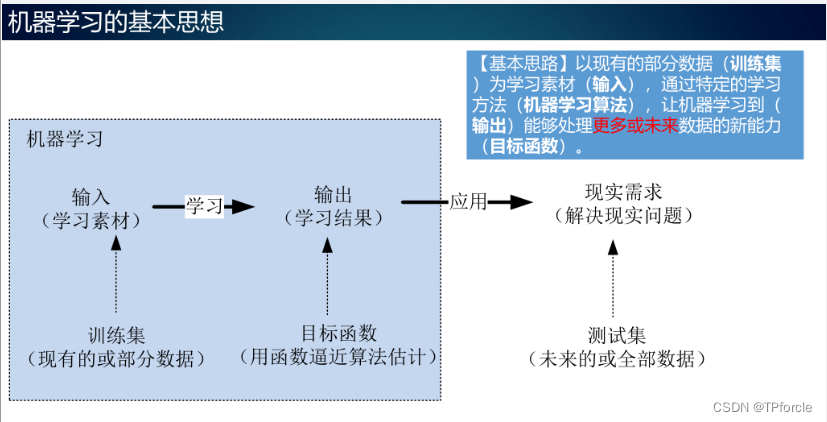
机器学习为数据科学中充分发挥计算机的自动数据处理能力,拓展人的数据处理能力以及实现人机协同数据处理提供了重要手段。 基本思路:以现有的部分数据(称为训练集)为学习素材(输入),通过特定的学习方法(机器学习算法),让机器学习到(输出)能够处理更多或未来数据的新能力(称为目标函数)。
1)基于实例学习 基本思路:事先将训练样本存储下来,然后每当遇到一个新增查询实例时,学习系统分析此新增实例与以前存储的实例之间的关系,并据此把一个目标函数赋给一个新增实例。 常用方法:K近邻方法、局部加权回归法、基于案例的推理。 2)概念学习 本质:从有关某个布尔函数的输入输出训练样本中推算出该布尔函数。 具体方法:Find-S算法、候选消除算法等。 3)决策树学习 本质:一种逼近离散值目标函数的过程。它代表的是一种分类过程。 其中: 根节点:代表分类的开始 叶节点:代表一个实例的结束 中间节点:代表相应实例的某一属性 节点之间的边:代表某一个属性的属性值 从根节点到叶节点的每条路径:代表一个具体的实例,同一个路径上的所有所有属性之间是“逻辑与”关系。 核心算法:ID3算法 (4)人工神经网络学习 人工神经元是人工神经网络的最基本的组成部分。 根据连接方式的不同,通常把人工神经网络分为无反馈的向前神经网络和相互连接型网络(反馈网络)。在人工神经网络中,实现人工神经元的方法有很多种,如感知器、线性单元和Sigmoid单元等。 特征学习方法:深度学习 (5)贝叶斯学习 定义:它是一种以贝叶斯法则为基础的,并通过概率手段进行学习的方法。 常用方法:朴素贝叶斯分类器 (6)遗传算法 本质:主要研究“从候选假设空间中搜索出最佳假设”。此处,“最佳假设”指“适应度”指标为最优的假设。 遗传算法借鉴的生物进化的三个基本原则:适者生存、两性繁衍及突变,分别对应遗传算法的三个基本算子:选择、交叉和突变。 遗传算法:GA算法 (7)分析学习 特点:使用先验知识来分析或解释每个训练样本,以推理出样本的哪些特征与目标函数相关或不相关。因此,这些假设能使机器学习系统比单独依靠数据进行泛化有更高的精度。 (8)增强学习 本质:主要研究的是如何协助自治Agent(机器人)的学习活动,进而达到选择最优动作的目的。 基本思路:当Agent在其环境中做出某个动作时,施教者会提供奖赏或惩罚信息,以表示结果状态的正确与否。 根据学习任务的不同,机器学习算法分为:有监督学习、无监督学习和半监督学习。 3.3 数据科学视角下的机器学习机器学习领域所面临的主要挑战有: 过拟合维度灾难特征工程算法的可扩展性模型集成 四、数据可视化数据可视化在数据科学中的地位: (1)视觉是人类获得信息的最主要的途径。 视觉感知是人类大脑的最主要的功能之一。 眼睛是感知信息能力最强的人体器官之一。(2)相对于统计分析,数据可视化的主要优势为: 数据可视化处理可以洞察统计分析无法发现的结构和细节。 数据可视化处理结果的解读对用户知识水平的要求较低。(3)可视化能够帮助人们提高理解与处理数据的效率。 五、总结通过完成本章的学习,我对数据科学有了一定的了解,对统计学、机器学习、数据可视化有了一定的认识,后面还将花时间进行更加深入的学习。 |

【本文地址】
今日新闻 |
推荐新闻 |