数学建模专栏 |
您所在的位置:网站首页 › 数据模型论文怎么建的 › 数学建模专栏 |
数学建模专栏
|
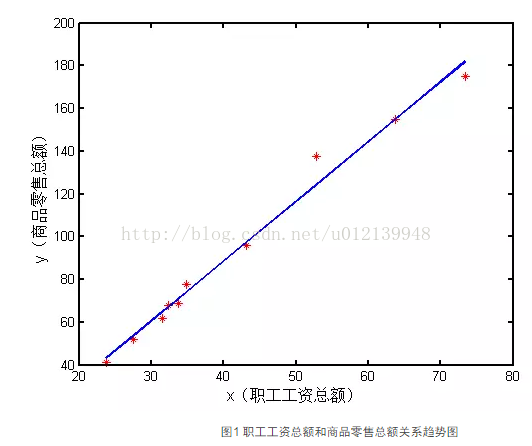
以数据为基础而建立数学模型的方法称为数据建模方法, 包括回归、统计、机器学习、深度学习、灰色预测、主成分分析、神经网络、时间序列分析等方法, 其中最常用的方法还是回归方法。 本讲主要介绍在数学建模中常用几种回归方法的 MATLAB 实现过程。 根据回归方法中因变量的个数和回归函数的类型(线性或非线性)可将回归方法分为:一元线性、一元非线性、多元回归。另外还有两种特殊的回归方式,一种在回归过程中可以调整变量数的回归方法,称为逐步回归,另一种是以指数结构函数作为回归模型的回归方法,称为 Logistic 回归。本讲将逐一介绍这几个回归方法。 1. 一元回归 1.1 一元线性回归 [ 例1 ] 近 10 年来,某市社会商品零售总额与职工工资总额(单位:亿元)的数据见表3-1,请建立社会商品零售总额与职工工资总额数据的回归模型。 表1 商品零售总额与职工工资总额
该问题是典型的一元回归问题,但先要确定是线性还是非线性,然后就可以利用对应的回归方法建立他们之间的回归模型了,具体实现的 MATLAB 代码如下: (1)输入数据 clc, clear all, close all x=[23.80,27.60,31.60,32.40,33.70,34.90,43.20,52.80,63.80,73.40]; y=[41.4,51.8,61.70,67.90,68.70,77.50,95.90,137.40,155.0,175.0]; (2)采用最小二乘回归 Figure plot(x,y,'r*') %作散点图 xlabel('x(职工工资总额)','fontsize', 12) %横坐标名 ylabel('y(商品零售总额)', 'fontsize',12) %纵坐标名 set(gca,'linewidth',2); % 采用最小二乘拟合 Lxx=sum((x-mean(x)).^2); Lxy=sum((x-mean(x)).*(y-mean(y))); b1=Lxy/Lxx; b0=mean(y)-b1*mean(x); y1=b1*x+b0; hold on
plot(x, y1,'linewidth',2); 运行本节程序,会得到如图 1 所示的回归图形。在用最小二乘回归之前,先绘制了数据的散点图,这样就可以从图形上判断这些数据是否近似成线性关系。当发现它们的确近似在一条线上后,再用线性回归的方法进行回归,这样也更符合我们分析数据的一般思路。 图1 职工工资总额和商品零售总额关系趋势图 (3)采用 LinearModel.fit 函数进行线性回归 m2 = LinearModel.fit(x,y) 运行结果如下: m2 = Linear regression model: y ~ 1 + x1 Estimated Coefficients: Estimate SE tStat pValue (Intercept) -23.549 5.1028 -4.615 0.0017215 x1 2.7991 0.11456 24.435 8.4014e-09 R-squared: 0.987, Adjusted R-Squared 0.985 F-statistic vs. constant model: 597, p-value = 8.4e-09 (4)采用 regress 函数进行回归 Y=y'; X=[ones(size(x,2),1),x']; [b, bint, r, rint, s] = regress(Y, X) 运行结果如下: b = -23.5493 2.7991 在以上回归程序中,使用了两个回归函数 LinearModel.fit 和 regress。在实际使用中,只要根据自己的需要选用一种就可以了。函数 LinearModel.fit 输出的内容为典型的线性回归的参数。关于 regress,其用法多样,MATLAB 帮助中关于 regress 的用法,有以下几种: b = regress(y,X) [b,bint] = regress(y,X) [b,bint,r] = regress(y,X) [b,bint,r,rint] = regress(y,X) [b,bint,r,rint,stats] = regress(y,X) [...] = regress(y,X,alpha) 输入 y(因变量,列向量),X(1与自变量组成的矩阵)和(alpha,是显著性水平, 缺省时默认0.05)。 输出 bint 是 β0,β1 的置信区间,r 是残差(列向量),rint是残差的置信区间,s包含4个统计量:决定系数 R^2(相关系数为R),F 值,F(1,n-2) 分布大于 F 值的概率 p,剩余方差 s^2 的值。也可由程序 sum(r^2)/(n-2) 计算。其意义和用法如下:R^2 的值越接近 1,变量的线性相关性越强,说明模型有效;如果满足 则认为变量y与x显著地有线性关系,其中 F1-α(1,n-2) 的值可查F分布表,或直接用 MATLAB 命令 finv(1-α,1, n-2) 计算得到;如果 p F1-α(m,n-m-1) ,即认为因变量 y 与自变量 x1,x2,...,xm 之间有显著的线性相关关系;否则认为因变量 y 与自变量 x1,x2,...,xm 之间线性相关关系不显著。本例 F=67.919 > F1-0.05( 3,20 ) = 3.10。 3)p 值检验:若 p < α(α 为预定显著水平),则说明因变量 y 与自变量 x1,x2,...,xm之间显著地有线性相关关系。本例输出结果,p |

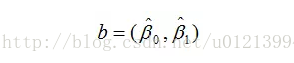
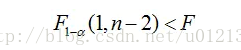
【本文地址】
今日新闻 |
推荐新闻 |