决策树算法原理+例题练习 |
您所在的位置:网站首页 › 数据模型与决策例题及答案详解 › 决策树算法原理+例题练习 |
决策树算法原理+例题练习
|
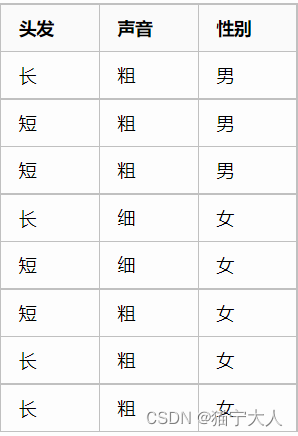
一、决策树的优缺点 优点:计算复杂度不高,输出结果易于理解,对中间值的缺失值不敏感,可以处理不相关特征数据。缺点:可能会产生过度匹配的问题。使用数据类型:数值型和标称型。二、一个实例 一天,老师问了个问题,只根据头发和声音怎么判断一位同学的性别。 为了解决这个问题,同学们马上简单的统计了7位同学的相关特征,数据如下:
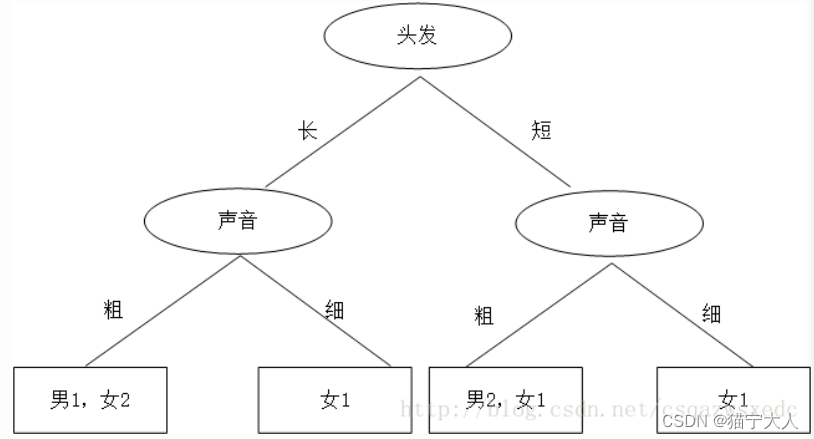
A同学思路,先按照头发判断,若判断不出,再按照声音判断,如下:
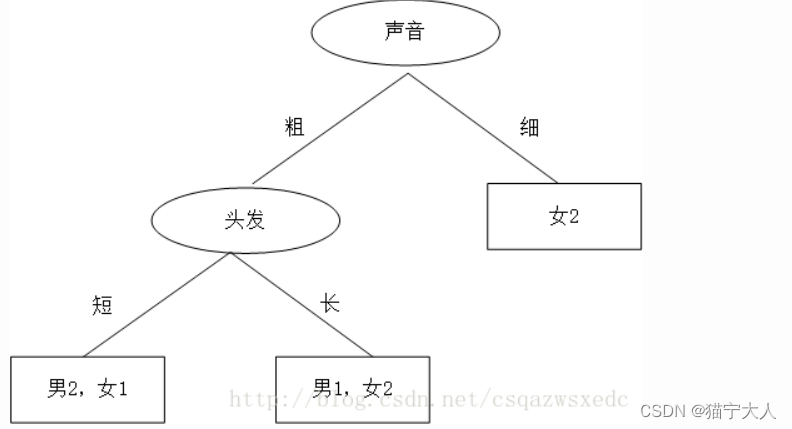
由此决策树判断结果可知:头发+长声音粗是男生;头发长+声音细是女生;头发短+声音粗是男生;头发短+声音细是女生 同学B的思路,先根据声音判断,然后再根据头发判断,如下:
此决策树的判断结果:声音细为女生,声音粗+短头发是男生;声音粗+头发长是女生。 这两个决策树,谁的更好呢?当我们有多个特征,该如何选哪个特征为最佳划分点? 三、数据集的划分原则 将无需的数据变得有序 我们可以使用多种方法划分数据集,但是每种方法都有各自的优缺点。于是我们这么想,如果我们能测量数据的复杂度,对比按不同特征分类后的数据复杂度,若按某一特征分类后复杂度减少的更多,那么这个特征即为最佳分类特征。 Claude Shannon 定义了熵(entropy)和信息增益(information gain)。 用熵来表示信息的复杂度,熵越大,则信息越复杂。公式如下: 信息增益(information gain),表示两个信息熵的差值。 首先计算未分类前的熵,总共有8位同学,男生3位,女生5位。 熵(总)=-3/8*log2(3/8)-5/8*log2(5/8)=0.9544 接着分别计算同学A和同学B分类后信息熵。 同学A首先按头发分类,分类后的结果为:长头发中有1男3女。短头发中有2男2女。 熵(同学A长发)=-1/4*log2(1/4)-3/4*log2(3/4)=0.8113 熵(同学A短发)=-2/4*log2(2/4)-2/4*log2(2/4)=1 熵(同学A)=4/8*0.8113+4/8*1=0.9057 信息增益(同学A)=熵(总)-熵(同学A)=0.9544-0.9057=0.0487 同理,按同学B的方法,首先按声音特征来分,分类后的结果为:声音粗中有3男3女。声音细中有0男2女。 熵(同学B声音粗)=-3/6*log2(3/6)-3/6*log2(3/6)=1 熵(同学B声音粗)=-2/2*log2(2/2)=0 熵(同学B)=6/8*1+2/8*0=0.75 信息增益(同学B)=熵(总)-熵(同学A)=0.9544-0.75=0.2087 按同学B的方法,先按声音特征分类,信息增益更大,区分样本的能力更强,更具有代表性。 以上就是决策树ID3算法的核心思想。 from math import log import operator def calcShannonEnt(dataSet): # 计算数据的熵(entropy) numEntries=len(dataSet) # 数据条数 labelCounts={} for featVec in dataSet: currentLabel=featVec[-1] # 每行数据的最后一个字(类别) if currentLabel not in labelCounts.keys(): labelCounts[currentLabel]=0 labelCounts[currentLabel]+=1 # 统计有多少个类以及每个类的数量 shannonEnt=0 for key in labelCounts: prob=float(labelCounts[key])/numEntries # 计算单个类的熵值 shannonEnt-=prob*log(prob,2) # 累加每个类的熵值 return shannonEnt def createDataSet1(): # 创造示例数据 dataSet = [['长', '粗', '男'], ['短', '粗', '男'], ['短', '粗', '男'], ['长', '细', '女'], ['短', '细', '女'], ['短', '粗', '女'], ['长', '粗', '女'], ['长', '粗', '女']] labels = ['头发','声音'] #两个特征 return dataSet,labels def splitDataSet(dataSet,axis,value): # 按某个特征分类后的数据 retDataSet=[] for featVec in dataSet: if featVec[axis]==value: reducedFeatVec =featVec[:axis] reducedFeatVec.extend(featVec[axis+1:]) retDataSet.append(reducedFeatVec) return retDataSet def chooseBestFeatureToSplit(dataSet): # 选择最优的分类特征 numFeatures = len(dataSet[0])-1 baseEntropy = calcShannonEnt(dataSet) # 原始的熵 bestInfoGain = 0 bestFeature = -1 for i in range(numFeatures): featList = [example[i] for example in dataSet] uniqueVals = set(featList) newEntropy = 0 for value in uniqueVals: subDataSet = splitDataSet(dataSet,i,value) prob =len(subDataSet)/float(len(dataSet)) newEntropy +=prob*calcShannonEnt(subDataSet) # 按特征分类后的熵 infoGain = baseEntropy - newEntropy # 原始熵与按特征分类后的熵的差值 if (infoGain>bestInfoGain): # 若按某特征划分后,熵值减少的最大,则次特征为最优分类特征 bestInfoGain=infoGain bestFeature = i return bestFeature def majorityCnt(classList): #按分类后类别数量排序,比如:最后分类为2男1女,则判定为男; classCount={} for vote in classList: if vote not in classCount.keys(): classCount[vote]=0 classCount[vote]+=1 sortedClassCount = sorted(classCount.items(),key=operator.itemgetter(1),reverse=True) return sortedClassCount[0][0] def createTree(dataSet,labels): classList=[example[-1] for example in dataSet] # 类别:男或女 if classList.count(classList[0])==len(classList): return classList[0] if len(dataSet[0])==1: return majorityCnt(classList) bestFeat=chooseBestFeatureToSplit(dataSet) #选择最优特征 bestFeatLabel=labels[bestFeat] myTree={bestFeatLabel:{}} #分类结果以字典形式保存 del(labels[bestFeat]) featValues=[example[bestFeat] for example in dataSet] uniqueVals=set(featValues) for value in uniqueVals: subLabels=labels[:] myTree[bestFeatLabel][value]=createTree(splitDataSet\ (dataSet,bestFeat,value),subLabels) return myTree if __name__=='__main__': dataSet, labels=createDataSet1() # 创造示列数据 print(createTree(dataSet, labels)) # 输出决策树模型结果 输出结果:{'声音': {'细': '女', '粗': {'头发': {'短': '男', '长': '女'}}}} |

【本文地址】
今日新闻 |
推荐新闻 |