3D目标检测数据集 KITTI(标签格式解析、3D框可视化、点云转图像、BEV鸟瞰图) |
您所在的位置:网站首页 › 数据标注3d教程图片 › 3D目标检测数据集 KITTI(标签格式解析、3D框可视化、点云转图像、BEV鸟瞰图) |
3D目标检测数据集 KITTI(标签格式解析、3D框可视化、点云转图像、BEV鸟瞰图)
|
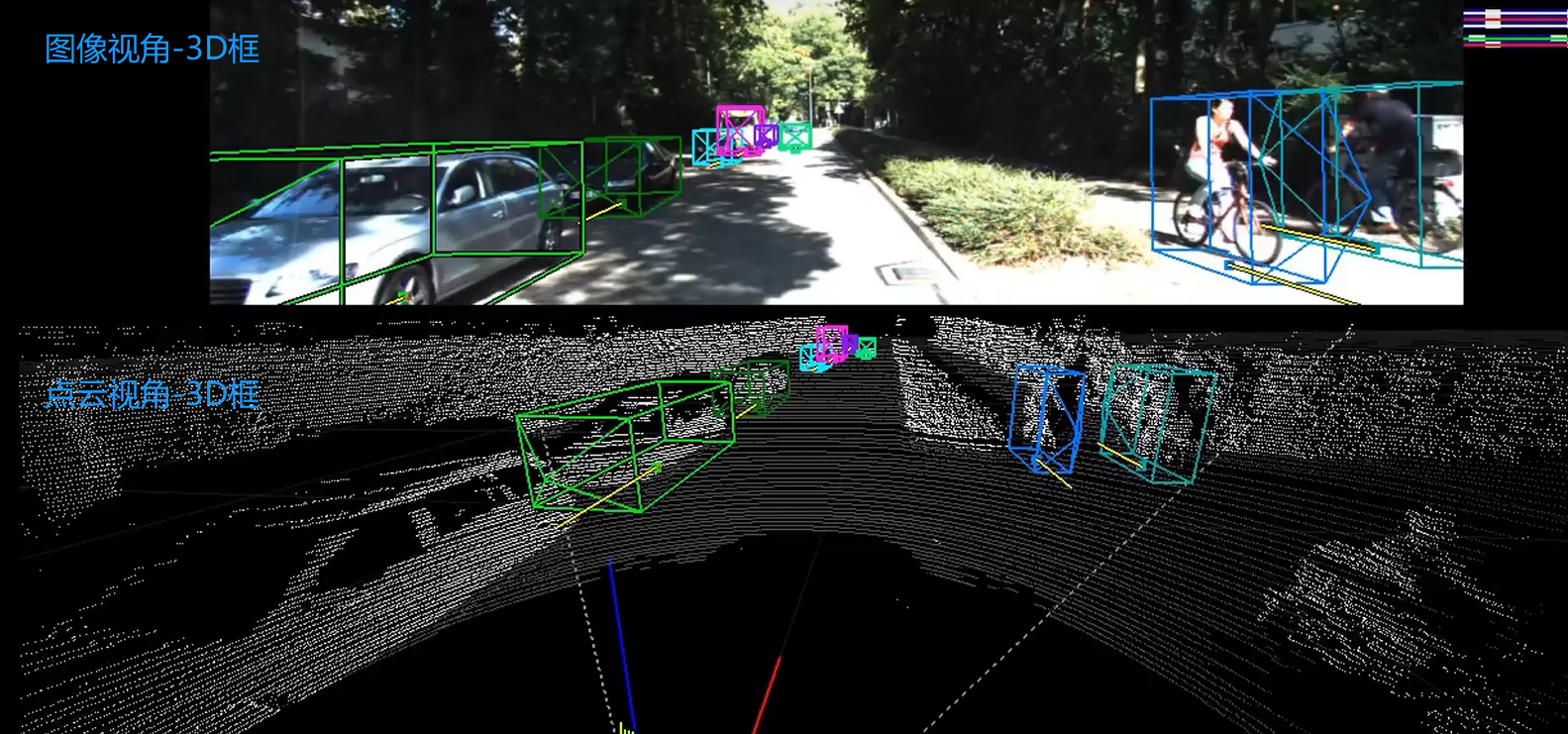
本文介绍在3D目标检测中,理解和使用KITTI 数据集,包括KITTI 的基本情况、下载数据集、标签格式解析、3D框可视化、点云转图像、画BEV鸟瞰图等,并配有实现代码。 目录 1、KITTI数据集3D框可视化 2、KITTI 3D数据集 3、下载数据集 4、标签格式 5、标定参数解析 6、点云数据-->投影到图像 7、图像数据-->投影到点云 8、可视化图像2D结果、3D结果 9、点云3D结果-->图像BEV鸟瞰图结果(坐标系转换) 10、绘制BEV鸟瞰图 11、BEV鸟瞰图画2d框 12、完整工程代码 1、KITTI数据集3D框可视化
kitti 3D数据集的基本情况:
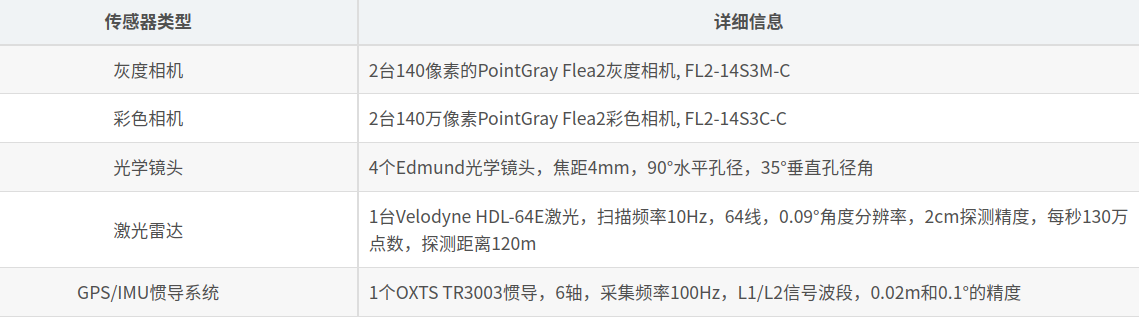
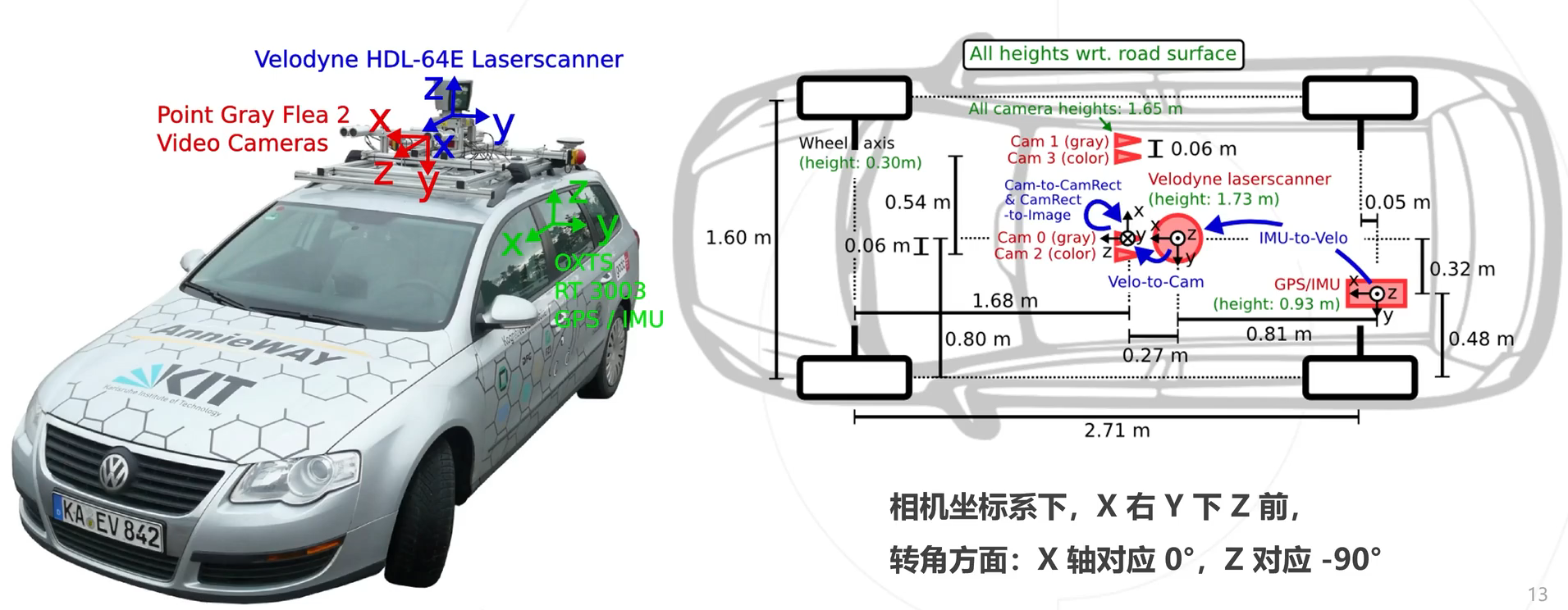
KITTI整个数据集是在德国卡尔斯鲁厄采集的,采集时长6小时。KITTI官网放出的数据大约占采集全部的25%,去除了测试集中相关的数据片段,按场景可以分为“道路”、“城市”、“住宅区”、“校园”和“行人”5类。 传感器配置:
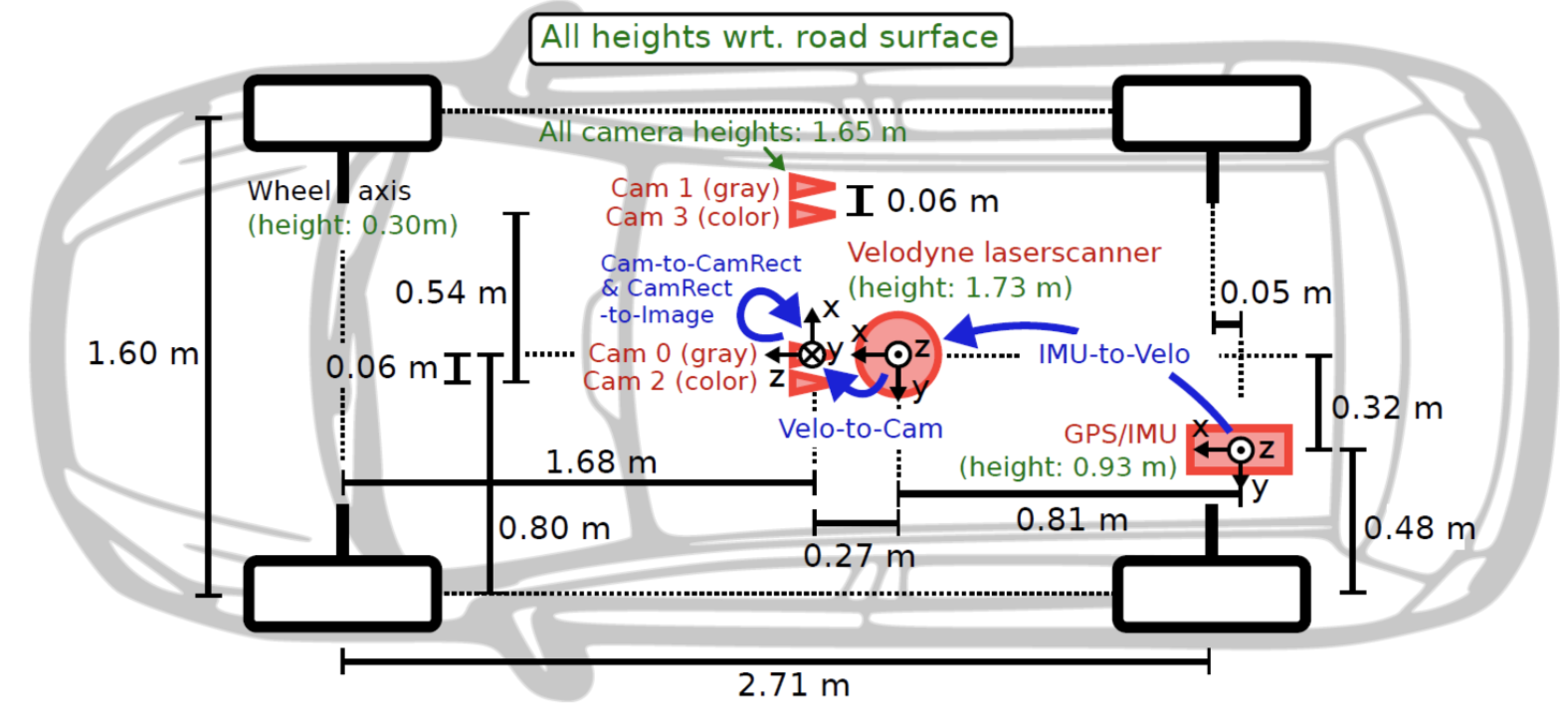
传感器安装位置:
The KITTI Vision Benchmark Suite (cvlibs.net)
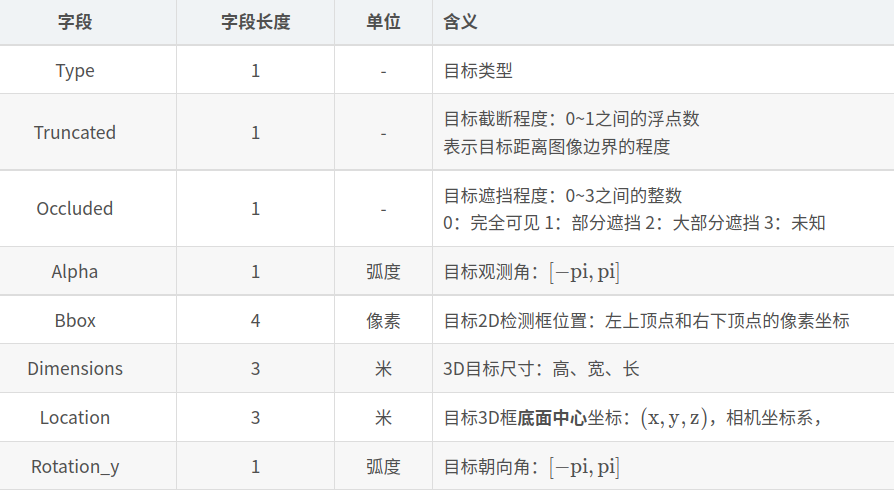
下载数据需要注册账号的,获取取百度网盘下载;文件的格式如下所示 图片格式:xxx.jpg 点云格式:xxx.bin(点云是以bin二进制的方式存储的) 标定参数:xxx.txt(一个文件中包括各个相机的内参、畸变校正矩阵、激光雷达坐标转到相机坐标的矩阵、IMU坐标转到激光雷达坐标的矩阵) 标签格式:xxx.txt(包含类别、截断情况、遮挡情况、观测角度、2D框左上角坐标、2D框右下角坐标、3D物体的尺寸-高宽长、3D物体的中心坐标-xyz、置信度) 4、标签格式示例标签:Pedestrian 0.00 0 -0.20 712.40 143.00 810.73 307.92 1.89 0.48 1.20 1.84 1.47 8.41 0.01
这时可以看看这个视频: Nuscenes、KITTI等多个BEV开源数据集介绍 5、标定参数解析然后看一下标定参数: P0-P3:是各个相机的内参矩阵;3×4的相机投影矩阵,0~3分别对应左侧灰度相机、右侧灰度相机、左侧彩色相机、右侧彩色相机。 R0_rect: 是左相机的畸变矫正矩阵;3×3的旋转修正矩阵。 Tr_velo_to_cam:是激光雷达坐标系 转到 相机坐标系矩阵;3×4的激光坐标系到Cam 0坐标系的变换矩阵。 Tr_imu_to_velo: 是IMU坐标转到激光雷达坐标的矩阵;3×4的IMU坐标系到激光坐标系的变换矩阵。
当有了点云数据信息,如何投影到图像中呢?本质上是一个坐标系转换的问题,流程思路如下: 已知点云坐标(x,y,z),当前是处于激光雷达坐标系激光雷达坐标系 转到 相机坐标系,需要用到标定参数中的Tr_velo_to_cam矩阵,此时得到相机坐标(x1,y1,z1)相机坐标系进行畸变矫正,需要用到标定参数中的R0_rect矩阵,此时得到相机坐标(x2,y2,z2)相机坐标系转为图像坐标系,需要用到标定参数中的P0矩阵,即相机内存矩阵,此时得到图像坐标(u,v)
看一下示例效果:
接口代码: ''' 将点云数据投影到图像 ''' def show_lidar_on_image(pc_velo, img, calib, img_width, img_height): ''' Project LiDAR points to image ''' imgfov_pc_velo, pts_2d, fov_inds = get_lidar_in_image_fov(pc_velo, calib, 0, 0, img_width, img_height, True) imgfov_pts_2d = pts_2d[fov_inds,:] imgfov_pc_rect = calib.project_velo_to_rect(imgfov_pc_velo) import matplotlib.pyplot as plt cmap = plt.cm.get_cmap('hsv', 256) cmap = np.array([cmap(i) for i in range(256)])[:,:3]*255 for i in range(imgfov_pts_2d.shape[0]): depth = imgfov_pc_rect[i,2] color = cmap[int(640.0/depth),:] cv2.circle(img, (int(np.round(imgfov_pts_2d[i,0])), int(np.round(imgfov_pts_2d[i,1]))), 2, color=tuple(color), thickness=-1) Image.fromarray(img).save('save_output/lidar_on_image.png') Image.fromarray(img).show() return img核心代码: ''' 将点云数据投影到相机坐标系 ''' def get_lidar_in_image_fov(pc_velo, calib, xmin, ymin, xmax, ymax, return_more=False, clip_distance=2.0): ''' Filter lidar points, keep those in image FOV ''' pts_2d = calib.project_velo_to_image(pc_velo) fov_inds = (pts_2d[:,0]=xmin) & \ (pts_2d[:,1]=ymin) fov_inds = fov_inds & (pc_velo[:,0]>clip_distance) imgfov_pc_velo = pc_velo[fov_inds,:] if return_more: return imgfov_pc_velo, pts_2d, fov_inds else: return imgfov_pc_velo 7、图像数据-->投影到点云当有了图像RGB信息,如何投影到点云中呢?本质上是一个坐标系转换的问题,和上面的是逆过程,流程思路如下: 已知图像坐标(u,v),当前是处于图像坐标系图像坐标系 转 相机坐标系,需要用到标定参数中的P0逆矩阵,即相机内存矩阵,得到相机坐标(x,y,z)相机坐标系进行畸变矫正,需要用到标定参数中的R0_rect逆矩阵,得到相机坐标(x1,y1,z1)矫正后相机坐标系 转 激光雷达坐标系,需要用到标定参数中的Tr_velo_to_cam逆矩阵,此时得到激光雷达坐标(x2,y2,z2) 8、可视化图像2D结果、3D结果先看一下2D框的效果:
3D框的效果:
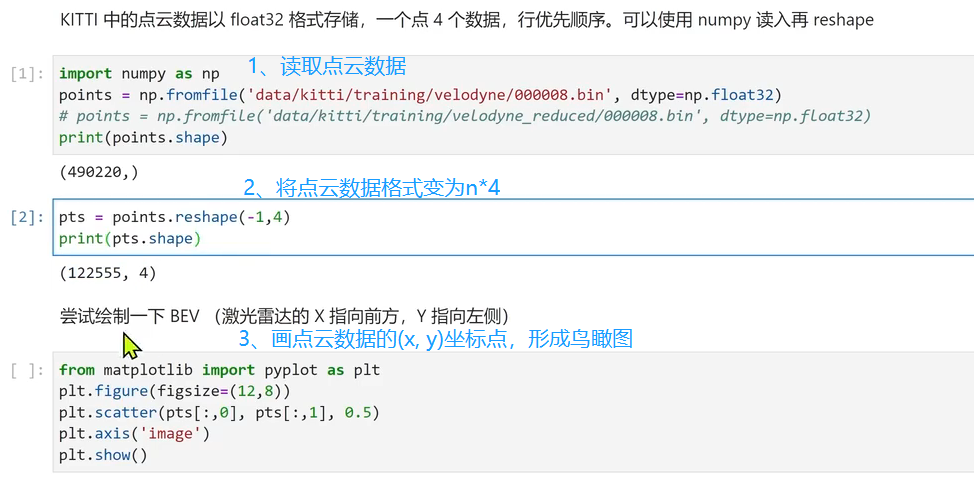
接口代码: ''' 在图像中画2D框、3D框 ''' def show_image_with_boxes(img, objects, calib, show3d=True): img1 = np.copy(img) # for 2d bbox img2 = np.copy(img) # for 3d bbox for obj in objects: if obj.type=='DontCare':continue cv2.rectangle(img1, (int(obj.xmin),int(obj.ymin)), (int(obj.xmax),int(obj.ymax)), (0,255,0), 2) # 画2D框 box3d_pts_2d, box3d_pts_3d = utils.compute_box_3d(obj, calib.P) # 获取图像3D框(8*2)、相机坐标系3D框(8*3) img2 = utils.draw_projected_box3d(img2, box3d_pts_2d) # 在图像上画3D框 if show3d: Image.fromarray(img2).save('save_output/image_with_3Dboxes.png') Image.fromarray(img2).show() else: Image.fromarray(img1).save('save_output/image_with_2Dboxes.png') Image.fromarray(img1).show()核心代码: def compute_box_3d(obj, P): ''' 计算对象的3D边界框在图像平面上的投影 输入: obj代表一个物体标签信息, P代表相机的投影矩阵-内参。 输出: 返回两个值, corners_3d表示3D边界框在 相机坐标系 的8个角点的坐标-3D坐标。 corners_2d表示3D边界框在 图像上 的8个角点的坐标-2D坐标。 ''' # 计算一个绕Y轴旋转的旋转矩阵R,用于将3D坐标从世界坐标系转换到相机坐标系。obj.ry是对象的偏航角 R = roty(obj.ry) # 物体实际的长、宽、高 l = obj.l; w = obj.w; h = obj.h; # 存储了3D边界框的8个角点相对于对象中心的坐标。这些坐标定义了3D边界框的形状。 x_corners = [l/2,l/2,-l/2,-l/2,l/2,l/2,-l/2,-l/2]; y_corners = [0,0,0,0,-h,-h,-h,-h]; z_corners = [w/2,-w/2,-w/2,w/2,w/2,-w/2,-w/2,w/2]; # 1、将3D边界框的角点坐标从对象坐标系转换到相机坐标系。它使用了旋转矩阵R corners_3d = np.dot(R, np.vstack([x_corners,y_corners,z_corners])) # 3D边界框的坐标进行平移 corners_3d[0,:] = corners_3d[0,:] + obj.t[0]; corners_3d[1,:] = corners_3d[1,:] + obj.t[1]; corners_3d[2,:] = corners_3d[2,:] + obj.t[2]; # 2、检查对象是否在相机前方,因为只有在相机前方的对象才会被绘制。 # 如果对象的Z坐标(深度)小于0.1,就意味着对象在相机后方,那么corners_2d将被设置为None,函数将返回None。 if np.any(corners_3d[2,:]图像BEV鸟瞰图结果(坐标系转换)思路流程: 读取点云数据,点云得存储格式是n*4,n是指当前文件点云的数量,4分别表示(x,y,z,intensity),即点云的空间三维坐标、反射强度我们只需读取前两行即可,得到坐标点(x,y)然后将坐标点(x,y),画散点图
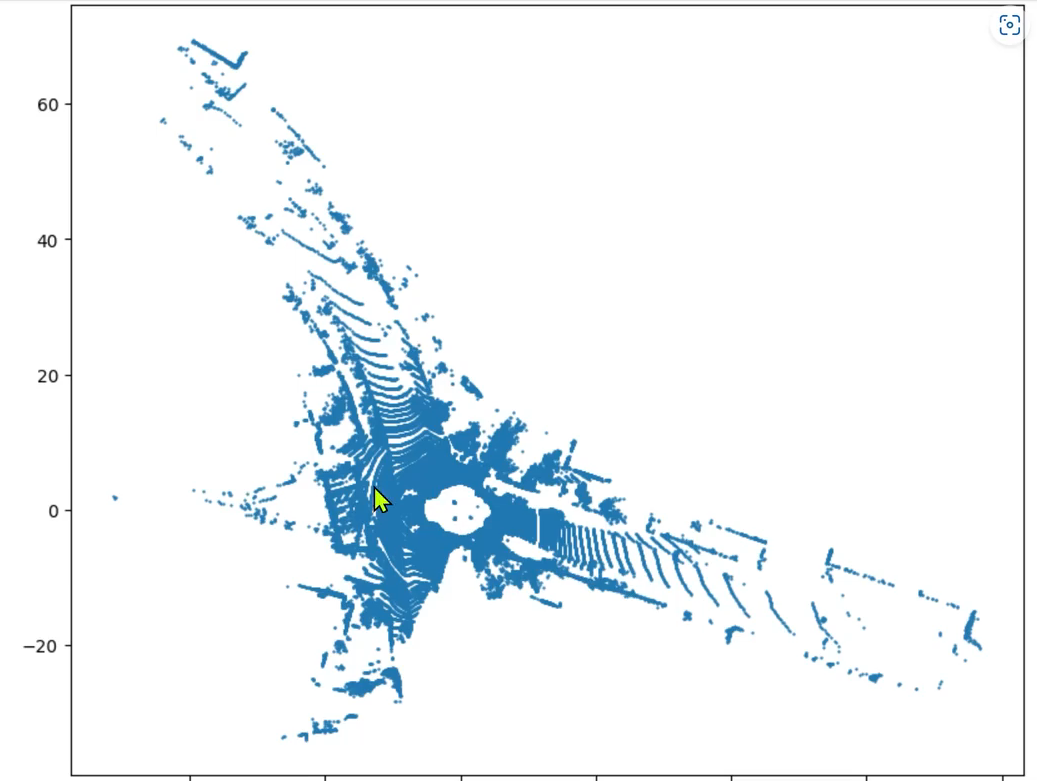
BEV鸟瞰图效果如下:
BEV图像示例效果:
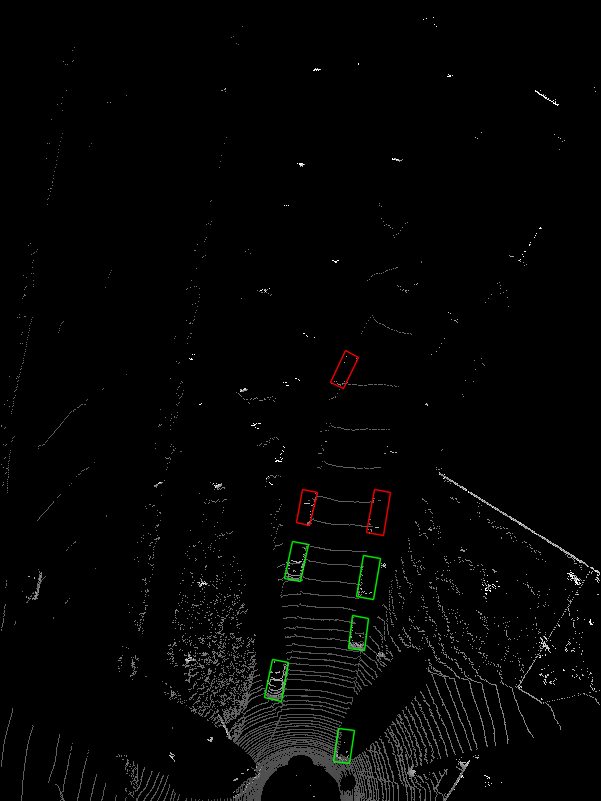
核心代码: ''' 可视化BEV鸟瞰图 ''' def show_lidar_topview(pc_velo, objects, calib): # 1-设置鸟瞰图范围 side_range = (-30, 30) # 左右距离 fwd_range = (0, 80) # 后前距离 x_points = pc_velo[:, 0] y_points = pc_velo[:, 1] z_points = pc_velo[:, 2] # 2-获得区域内的点 f_filt = np.logical_and(x_points > fwd_range[0], x_points < fwd_range[1]) s_filt = np.logical_and(y_points > side_range[0], y_points < side_range[1]) filter = np.logical_and(f_filt, s_filt) indices = np.argwhere(filter).flatten() x_points = x_points[indices] y_points = y_points[indices] z_points = z_points[indices] # 定义了鸟瞰图中每个像素代表的距离 res = 0.1 # 3-1将点云坐标系 转到 BEV坐标系 x_img = (-y_points / res).astype(np.int32) y_img = (-x_points / res).astype(np.int32) # 3-2调整坐标原点 x_img -= int(np.floor(side_range[0]) / res) y_img += int(np.floor(fwd_range[1]) / res) print(x_img.min(), x_img.max(), y_img.min(), y_img.max()) # 4-填充像素值, 将点云数据的高度信息(Z坐标)映射到像素值 height_range = (-3, 1.0) pixel_value = np.clip(a=z_points, a_max=height_range[1], a_min=height_range[0]) def scale_to_255(a, min, max, dtype=np.uint8): return ((a - min) / float(max - min) * 255).astype(dtype) pixel_value = scale_to_255(pixel_value, height_range[0], height_range[1]) # 创建图像数组 x_max = 1 + int((side_range[1] - side_range[0]) / res) y_max = 1 + int((fwd_range[1] - fwd_range[0]) / res) im = np.zeros([y_max, x_max], dtype=np.uint8) im[y_img, x_img] = pixel_value im2 = Image.fromarray(im) im2.save('save_output/BEV.png') im2.show() 11、BEV鸟瞰图画2d框在BEV视图中画框,可视化结果:
接口代码: ''' 将点云数据3D框投影到BEV ''' def show_lidar_topview_with_boxes(img, objects, calib): def bbox3d(obj): box3d_pts_2d, box3d_pts_3d = utils.compute_box_3d(obj, calib.P) # 获取3D框-图像、3D框-相机坐标系 box3d_pts_3d_velo = calib.project_rect_to_velo(box3d_pts_3d) # 将相机坐标系的框 转到 激光雷达坐标系 return box3d_pts_3d_velo # 返回nx3的点 boxes3d = [bbox3d(obj) for obj in objects if obj.type == "Car"] gt = np.array(boxes3d) im2 = utils.draw_box3d_label_on_bev(img, gt, scores=None, thickness=1) # 获取激光雷达坐标系的3D点,选择x, y两维,画到BEV平面坐标系上 im2 = Image.fromarray(im2) im2.save('save_output/BEV with boxes.png') im2.show()核心代码: # 设置BEV鸟瞰图参数 side_range = (-30, 30) # 左右距离 fwd_range = (0, 80) # 后前距离 res = 0.1 # 分辨率0.05m def compute_box_3d(obj, P): ''' 计算对象的3D边界框在图像平面上的投影 输入: obj代表一个物体标签信息, P代表相机的投影矩阵-内参。 输出: 返回两个值, corners_3d表示3D边界框在 相机坐标系 的8个角点的坐标-3D坐标。 corners_2d表示3D边界框在 图像上 的8个角点的坐标-2D坐标。 ''' # 计算一个绕Y轴旋转的旋转矩阵R,用于将3D坐标从世界坐标系转换到相机坐标系。obj.ry是对象的偏航角 R = roty(obj.ry) # 物体实际的长、宽、高 l = obj.l; w = obj.w; h = obj.h; # 存储了3D边界框的8个角点相对于对象中心的坐标。这些坐标定义了3D边界框的形状。 x_corners = [l/2,l/2,-l/2,-l/2,l/2,l/2,-l/2,-l/2]; y_corners = [0,0,0,0,-h,-h,-h,-h]; z_corners = [w/2,-w/2,-w/2,w/2,w/2,-w/2,-w/2,w/2]; # 1、将3D边界框的角点坐标从对象坐标系转换到相机坐标系。它使用了旋转矩阵R corners_3d = np.dot(R, np.vstack([x_corners,y_corners,z_corners])) # 3D边界框的坐标进行平移 corners_3d[0,:] = corners_3d[0,:] + obj.t[0]; corners_3d[1,:] = corners_3d[1,:] + obj.t[1]; corners_3d[2,:] = corners_3d[2,:] + obj.t[2]; # 2、检查对象是否在相机前方,因为只有在相机前方的对象才会被绘制。 # 如果对象的Z坐标(深度)小于0.1,就意味着对象在相机后方,那么corners_2d将被设置为None,函数将返回None。 if np.any(corners_3d[2,:] normalize projected_pts_2d(nx2) ''' n = pts_3d.shape[0] # 获取3D点的数量 pts_3d_extend = np.hstack((pts_3d, np.ones((n,1)))) # 将每个3D点的坐标扩展为齐次坐标形式(4D),通过在每个点的末尾添加1,创建了一个nx4的矩阵。 pts_2d = np.dot(pts_3d_extend, np.transpose(P)) # 将扩展的3D坐标点矩阵与投影矩阵P相乘,得到一个nx3的矩阵,其中每一行包含了3D点在图像平面上的投影坐标。每个点的坐标表示为[x, y, z]。 pts_2d[:,0] /= pts_2d[:,2] # 将投影坐标中的x坐标除以z坐标,从而获得2D图像上的x坐标。 pts_2d[:,1] /= pts_2d[:,2] # 将投影坐标中的y坐标除以z坐标,从而获得2D图像上的y坐标。 return pts_2d[:,0:2] # 返回一个nx2的矩阵,其中包含了每个3D点在2D图像上的坐标。 def draw_projected_box3d(image, qs, color=(0,60,255), thickness=2): ''' qs: 包含8个3D边界框角点坐标的数组, 形状为(8, 2)。图像坐标下的3D框, 8个顶点坐标。 ''' ''' Draw 3d bounding box in image qs: (8,2) array of vertices for the 3d box in following order: 1 -------- 0 /| /| 2 -------- 3 . | | | | . 5 -------- 4 |/ |/ 6 -------- 7 ''' qs = qs.astype(np.int32) # 将输入的顶点坐标转换为整数类型,以便在图像上绘制。 # 这个循环迭代4次,每次处理一个边界框的一条边。 for k in range(0,4): # Ref: http://docs.enthought.com/mayavi/mayavi/auto/mlab_helper_functions.html # 定义了要绘制的边的起始点和结束点的索引。在这个循环中,它用于绘制边界框的前四条边。 i,j=k,(k+1)%4 cv2.line(image, (qs[i,0],qs[i,1]), (qs[j,0],qs[j,1]), color, thickness) # 定义了要绘制的边的起始点和结束点的索引。在这个循环中,它用于绘制边界框的后四条边,与前四条边平行 i,j=k+4,(k+1)%4 + 4 cv2.line(image, (qs[i,0],qs[i,1]), (qs[j,0],qs[j,1]), color, thickness) # 定义了要绘制的边的起始点和结束点的索引。在这个循环中,它用于绘制连接前四条边和后四条边的边界框的边。 i,j=k,k+4 cv2.line(image, (qs[i,0],qs[i,1]), (qs[j,0],qs[j,1]), color, thickness) return image def draw_box3d_label_on_bev(image, boxes3d, thickness=1, scores=None): # if scores is not None and scores.shape[0] >0: img = image.copy() num = len(boxes3d) for n in range(num): b = boxes3d[n] x0 = b[0, 0] y0 = b[0, 1] x1 = b[1, 0] y1 = b[1, 1] x2 = b[2, 0] y2 = b[2, 1] x3 = b[3, 0] y3 = b[3, 1] if (x0 |








【本文地址】
今日新闻 |
推荐新闻 |