【数据库原理与应用 |
您所在的位置:网站首页 › 数据库原理系统及应用教程第五版课后答案 › 【数据库原理与应用 |
【数据库原理与应用
|
数据库设计的步骤
需求分析阶段概念模型设计阶段 —— E-R图逻辑模型设计阶段 —— 关系模型物理结构设计阶段 数据库实施阶段数据库运行和维护阶段
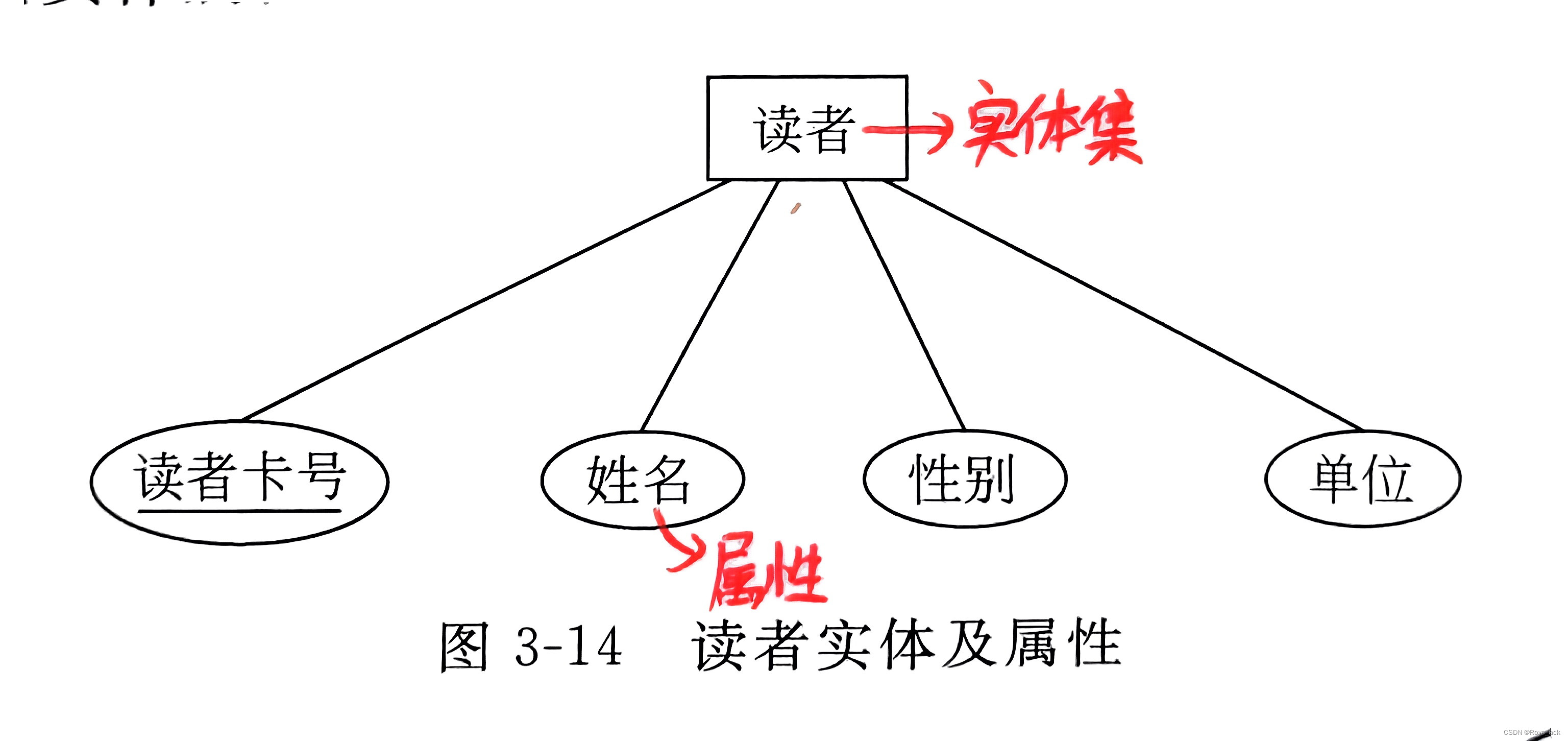
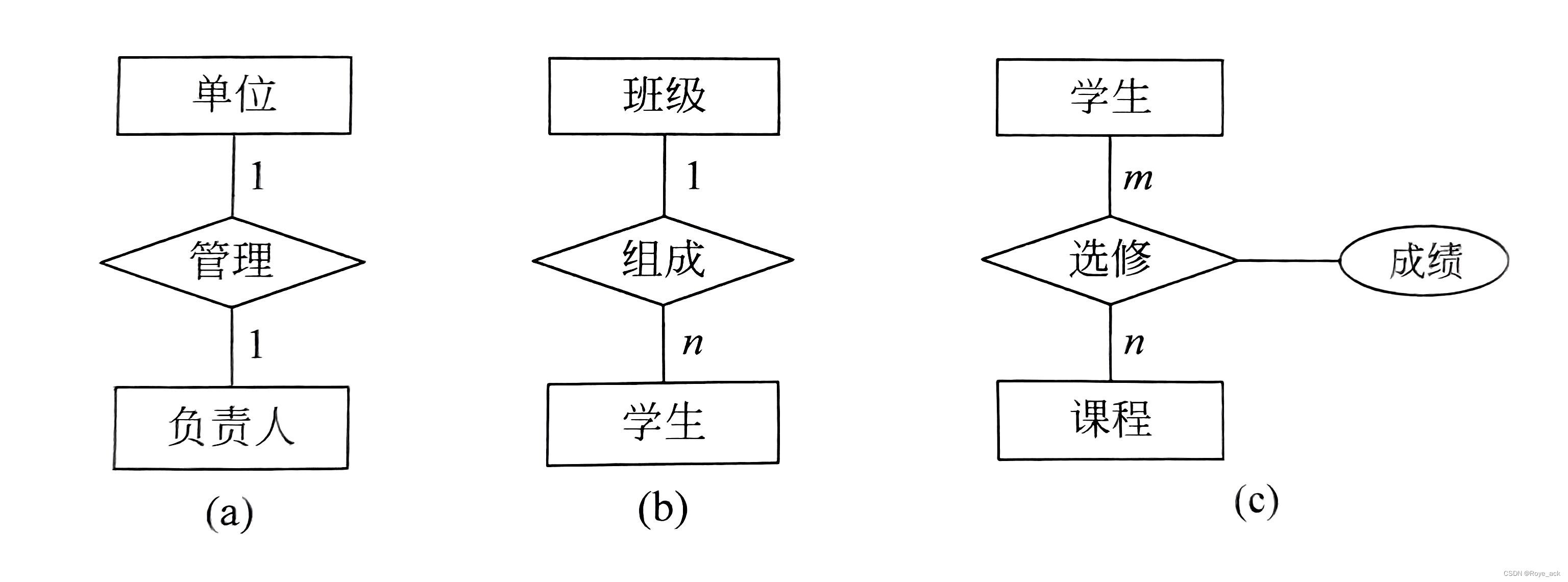
目录 数据库设计的步骤 一、需求分析 1、主要任务 2、对象模型 二、数据库概念结构设计 1、概念数据模型 E-R图 1、概念模型的表示 2、实体联系类型 3、E-R图 2、其他问题 (1)弱实体集和强实体集 (2)依赖实体集 (3)子类型和超类型 三、数据库逻辑结构设计 1、概念模型转换为关系模型的方法 (1)实体集的转换规则 (2)实体集之间联系集的转换规则 2、逻辑结构设计实例 四、数据库物理结构设计 1、关系模式存取方法的选择 (1)索引 (2)聚簇 (3)散列hash 2、确定数据库的存储结构 3、物理结构设计样例 一、需求分析 1、主要任务 获取需求确定对象及对象之间的关系 2、对象模型
(1)二元联系——两个实体集间的联系 一对一(1:1):对于实体集A的每一个实体,在实体集B中至多有一个实体与之联系一对多(1:n):对于实体集A的每一个实体,在实体集B中有一个或多个实体与之联系多对多(m:n):对于实体集A的每一个实体,在实体集B中有任意多个实体与之联系
(2)多元联系——多个实体集间的联系
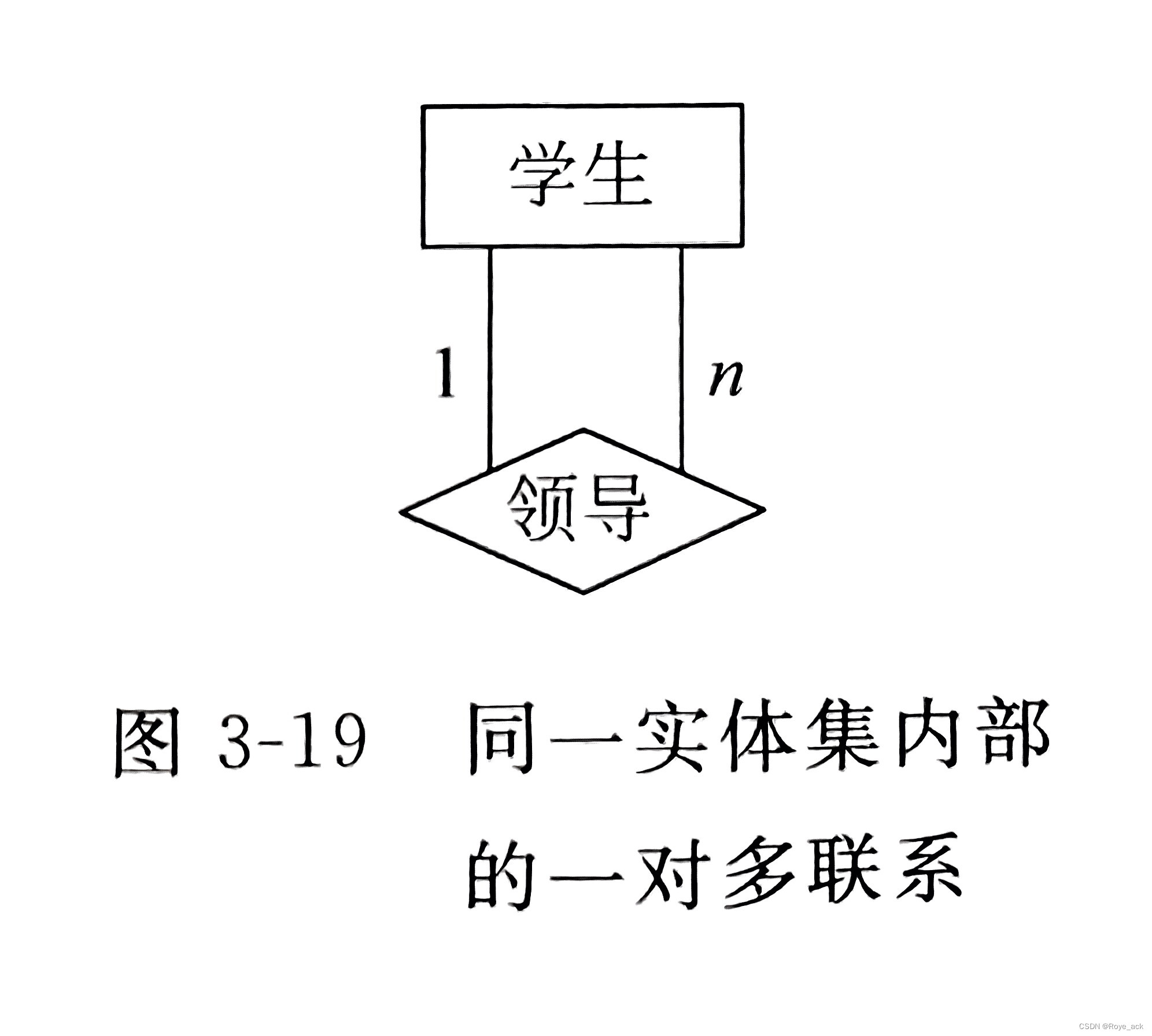
(3)递归联系 指实体集内部的联系,通常指用于组成实体的各元组间的联系,也成为自身联系 比如:学生是一个实体集,学生中有班长,班长自己也是学生。一个班长领导若干名学生,一个学生仅被一个班长管理
多个二元联系 ≠ 多元联系 3、E-R图(1)局部E-R图之间的冲突 属性冲突:包括属性域冲突和属性取值单位冲突属性域冲突:属性值的类型、取值范围、取值集合的不同都属于属性域冲突 属性取值单位冲突:采用不同的度量单位 命名冲突:同名异义冲突和异义同名冲突结构冲突:① 同一对象在不同的应用中具有不同的抽象。例如,高校的人事管理局部应用中,工资作为属性对待,而在财务管理局部应用中,为了描述工资各方面的细节,如基本工资、补贴、实发工资等特性,则把工资作为实体对待。这也就是抽象冲突。 ② 同一实体在不同局部E-R图中的属性组成不一致,即所包含的属性个数和属性排列次序不完全相同,解决这类冲突的方法是使该实体的属性取各局部E-R图中属性的并集,再适当调整属性的次序,兼顾到各种应用。 ③ 实体之间的联系在不同的局部E-R图中呈现不同的类型,此类冲突的解决方法是根据应用的语义对实体联系的类型进行综合或调整。 (2)E-R图实例
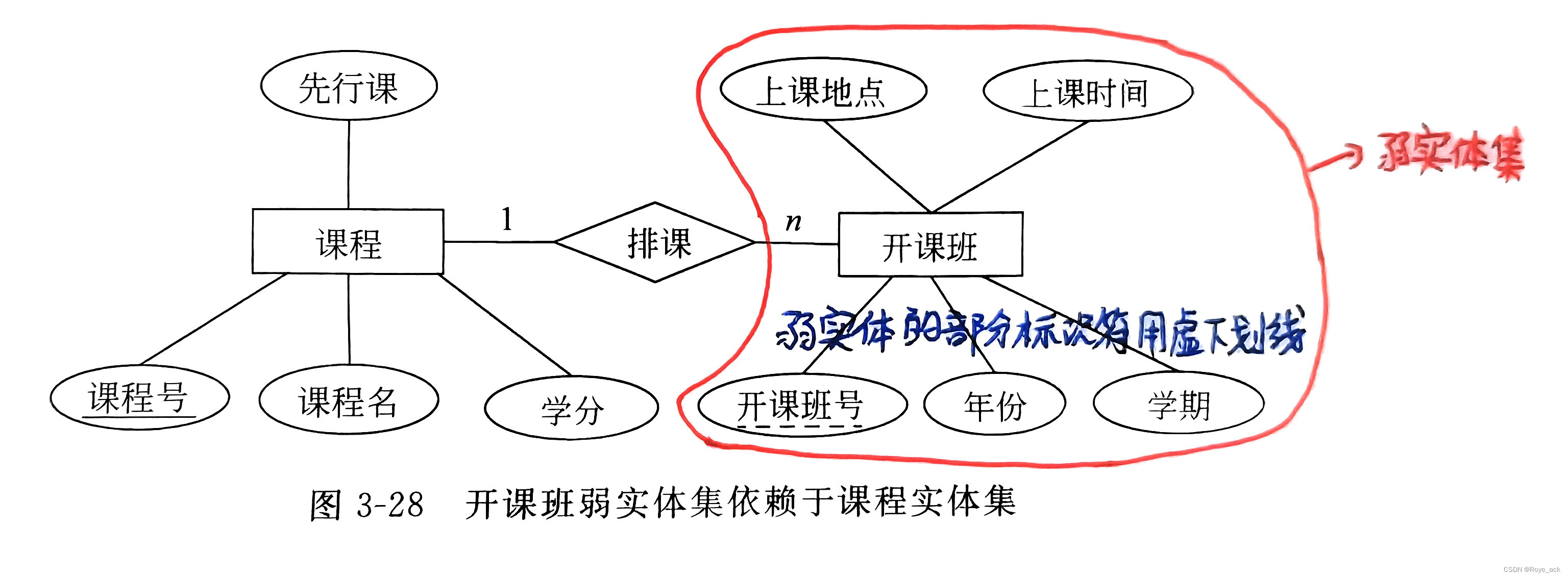
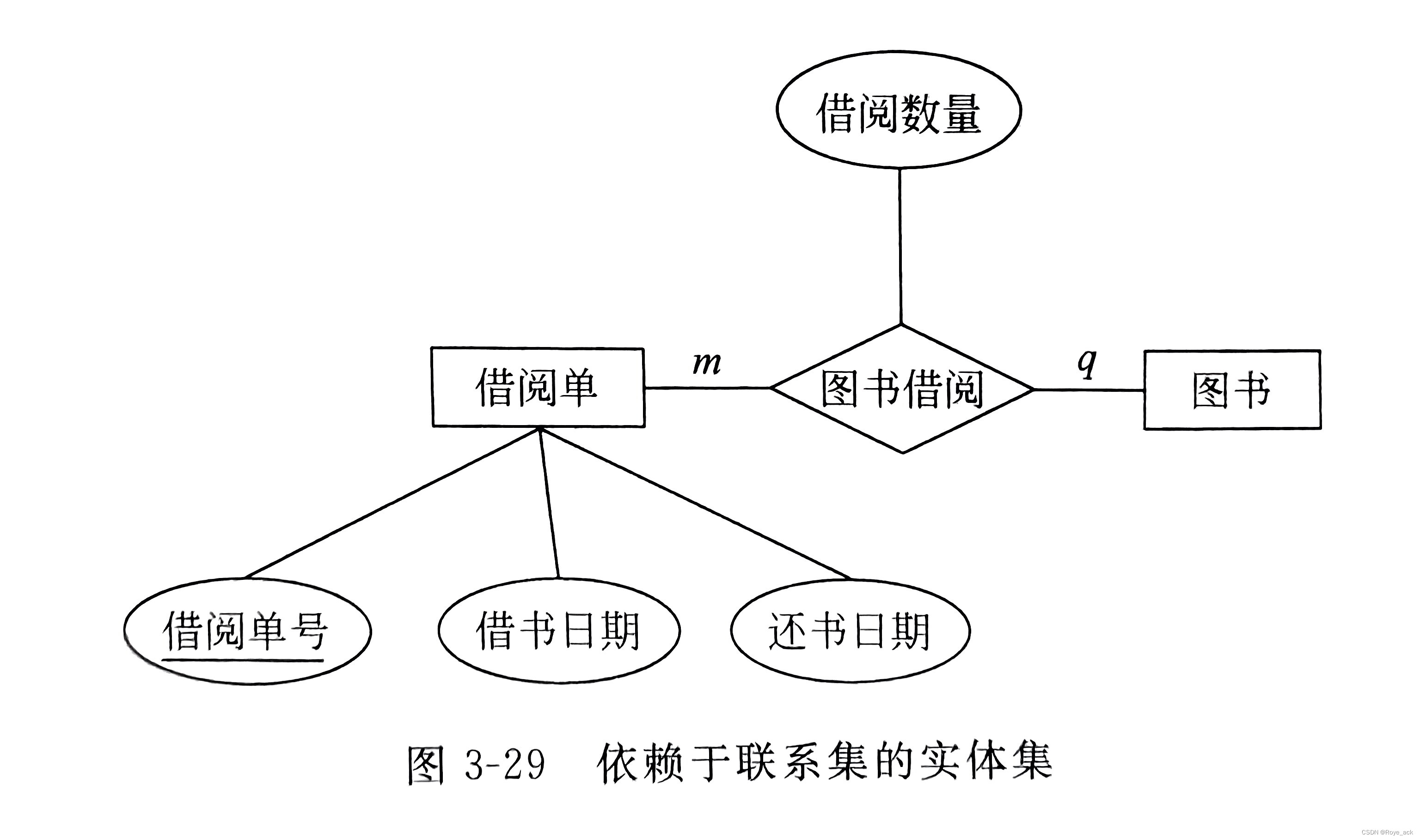
eg:医院是强实体集,病房是弱实体集,有医院才有病房,如果删除医院信息,病房信息也会被全删
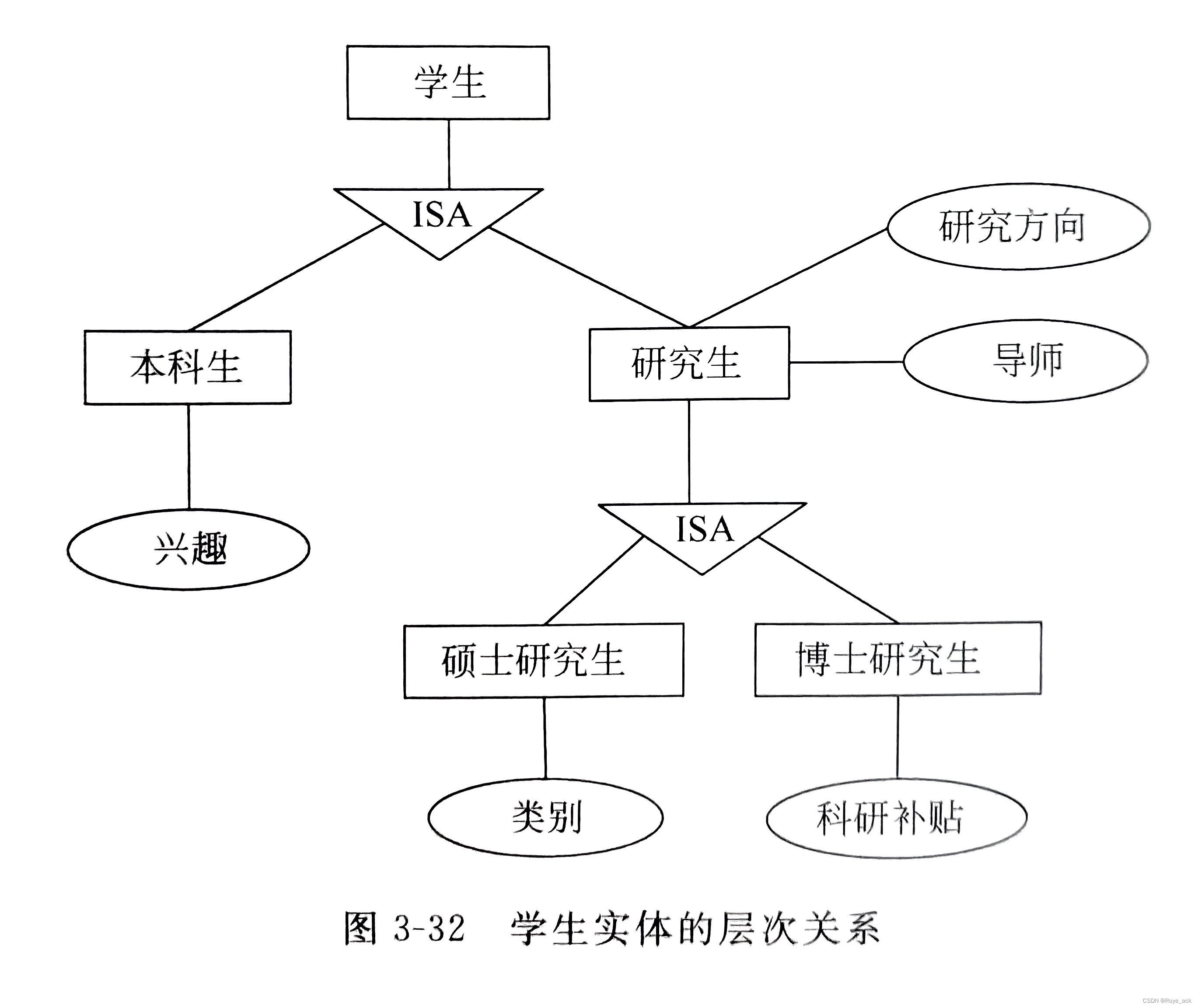
(3)子类型和超类型 实体的子类型和超类型存在着继承性的联系如果一个实体类型的全部实体也属于另一个实体类型,并具有自己的特征,称前者为子类,后者为超类子类自动继承超类的属性
① 强实体集转换方法 关系模式名称 —— 强实体集的名称属性 —— 实体集的属性关系模式的码 —— 原实体集的标识符② 弱实体集转换方法 关系模式名称 —— 弱实体集的名称属性 —— 弱实体集属性 + 强实体集主标识符关系模式的码 —— 强实体集的主标识符 + 弱实体集部分标识符 (2)实体集之间联系集的转换规则① 联系类型1:1的转换方法 方法一:将1:1联系转换为一个独立的关系 关系名 —— 联系名属性 —— 联系的属性 + 各实体集的标识符码 —— 每个实体集的标识符方法二:将1:1联系与某一端实体集对应的关系合并 关系名 —— 合并的实体集名属性 —— 联系的属性 + 合并的实体集的属性 + 与联系相关的另一实体集的标识符码 —— 合并的实体集的标识符【例1】 如图3所示为某国内旅游管理信息系统数据库的E-R图,两实体的联系类型为一对一联系,将E-R图转换为关系模式
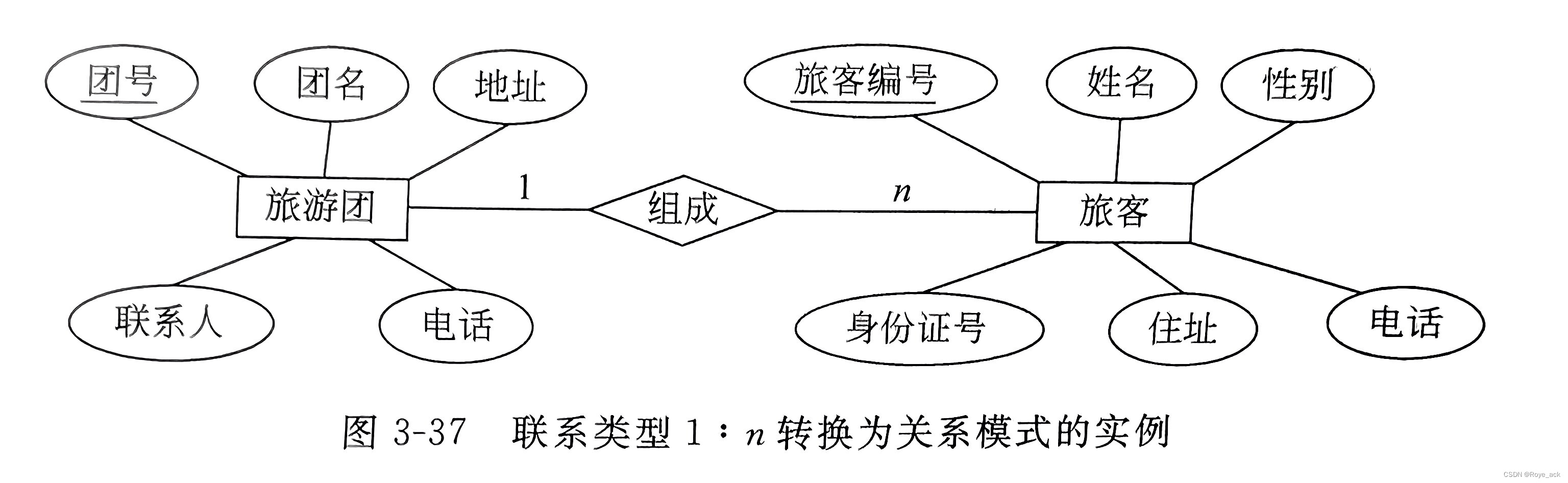
(1)首先将两个实体集转换为两个关系模式,分别是旅游团关系模式和保险关系模式,其中关系模式中标有下划线的属性为候选码。 旅游团(团号,团名,地址,联系人,电话)保险(保险单号,投保日期,保险费)(2)再将联系转换为关系模式,有三种方案。 方案1 将联系形成一个独立的关系模式:参加(团号,保险单号,人数) 方案2 将参加与旅游团两个关系模式进行合并,则关系模式为:旅游团(团号,团名,地址,联系人,电话,人数,保险单号) 方案3 将参加与保险两个关系模式进行合并,则关系模式为:保险(保险单号,投保日期,保险费,人数,团号)方案一:关系多,增加系统复杂性 方案二:并不是每个旅行团都参加保险,会导致保险单号null值过多 方案三:较合理 最终转换的关系模式集合为: 旅游团(团号,团名,地址,联系人,电话)保险(保险单号,投保日期,保险费,人数,团号)② 联系类型1:n的转换方法 把联系的属性与n端合并! 方法一:将1:n联系转换为一个独立的关系 关系名 —— 联系名属性 —— 联系的属性 + 各实体集的标识符码 —— n端实体集的标识符方法二:合并 关系名 —— 合并的实体集名属性 —— 联系的属性 + 合并的实体集的属性 + 与联系相关的另一实体集的标识符码 —— 合并的实体集的标识符【例2】 图给出了国内旅游管理信息系统数据库的E-R 图,两实体的联系类型为一对多联系,将E-R图转换为关系模式。
(1)首先将两个实体转换为两个关系模式,分别是旅游团关系模式和旅客关系模式,其中关系模式中标有下划线的属性为候选码。 旅游团(团号,团名,地址,联系人,电话)旅客(旅客编号,姓名,性别,身份证号,地址,电话)(2)再将联系转换为关系模式,有两种方案。 方案1 将联系形成一个独立的关系模式:组成(旅客编号,团号) 方案2 将联系“组成”形成的关系和旅客关系模式进行合并,则关系模式为:旅客(旅客编号,姓名,性别,身份证号,地址,电话,团号)最终转换的关系模式集合为: 旅游团(团号,团名,地址,联系人,电话);旅客(旅客编号,姓名,性别,身份证号,地址,电话,团号)。同样,两个关系模式的联系是通过旅客关系模式的外码“团号”联系起来的。因此,如果两个实体之间是1对多的联系,且联系没有自身的属性,则联系不必转换为一个独立的关系模式,只需要将1方实体集的标识符加入到多方实体集转换的关系模式中。
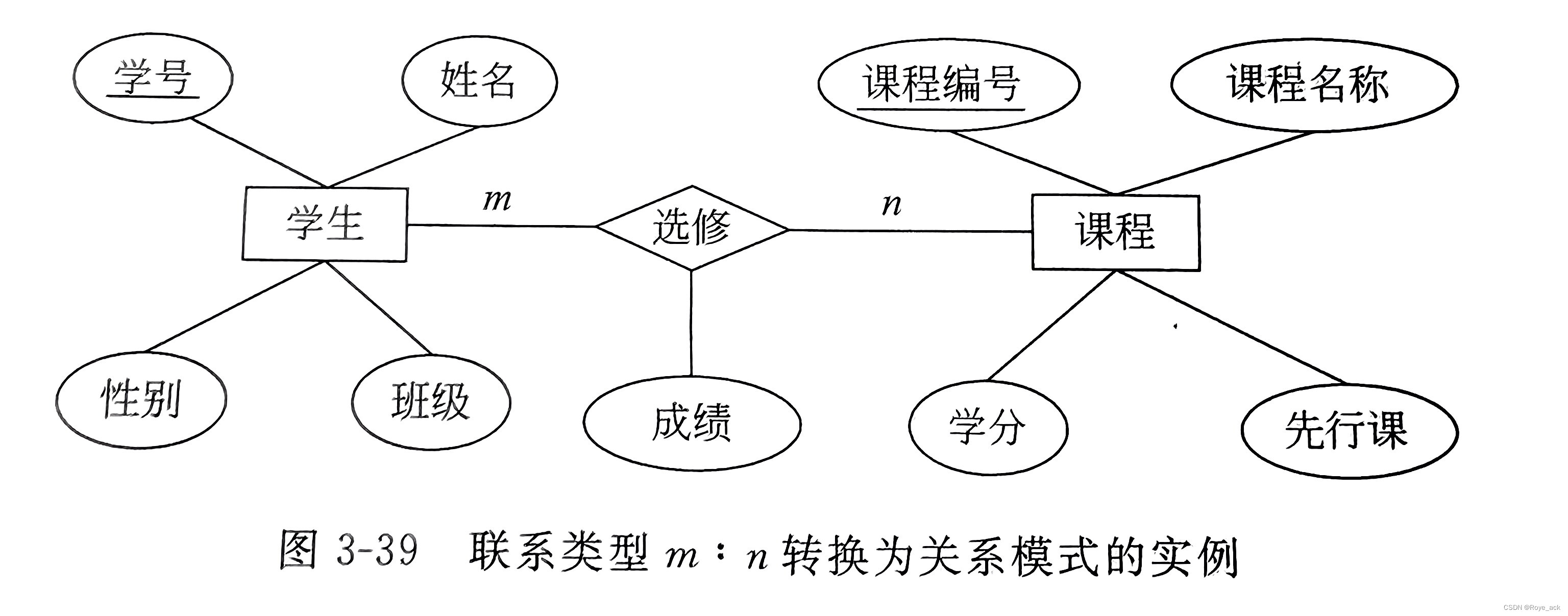
③ 联系类型m:n的转换方法 联系必须转换成一个独立的关系模式! 【例3】 图给出了高校学生选课系统数据库所涉及的学生和课程的E-R图,两实体的联系类型为多对多联系,将E-R图转换为关系模式。
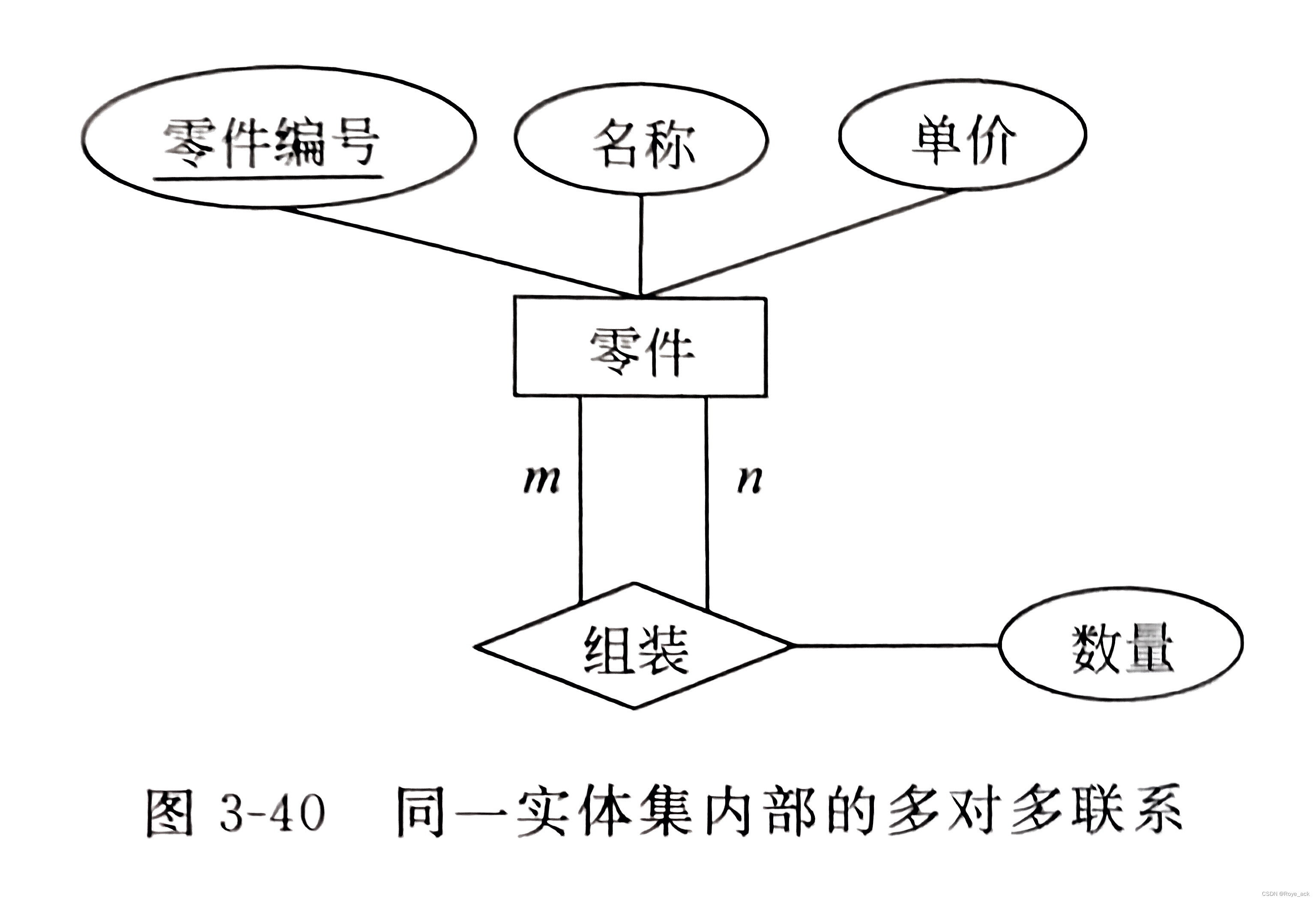
根据实体间多对多的转换规则,转换的关系模式为: 学生(学号,姓名,性别,班级)课程(课程编号,课程名称,学分,先行课)选修(学号,课程编号,成绩)假如对联系选修不建立独立的关系模式,而是和学生或课程关系进行合并,则转换的关系模式为: 学生(学号,姓名,性别,班级)课程(课程编号,课程名称,学分,先行课,学号,成绩)或学生(学号,姓名,性别,班级,课程编号,成绩)课程(课程编号,课程名称,学分,先行课)这样,对于多个学生选修相同的课程,或一个学生选修多门课程,分别存在相同课程、同一学生的信息重复存储多次,造成数据存储冗余太大,给维护带来不便的情形。 由此可以看出,对实体之间m:n的联系类型,联系必须转换为一个独立的关系模式。 【例4】 图是同一实体集内部的多对多联系,将其转换为关系模式。
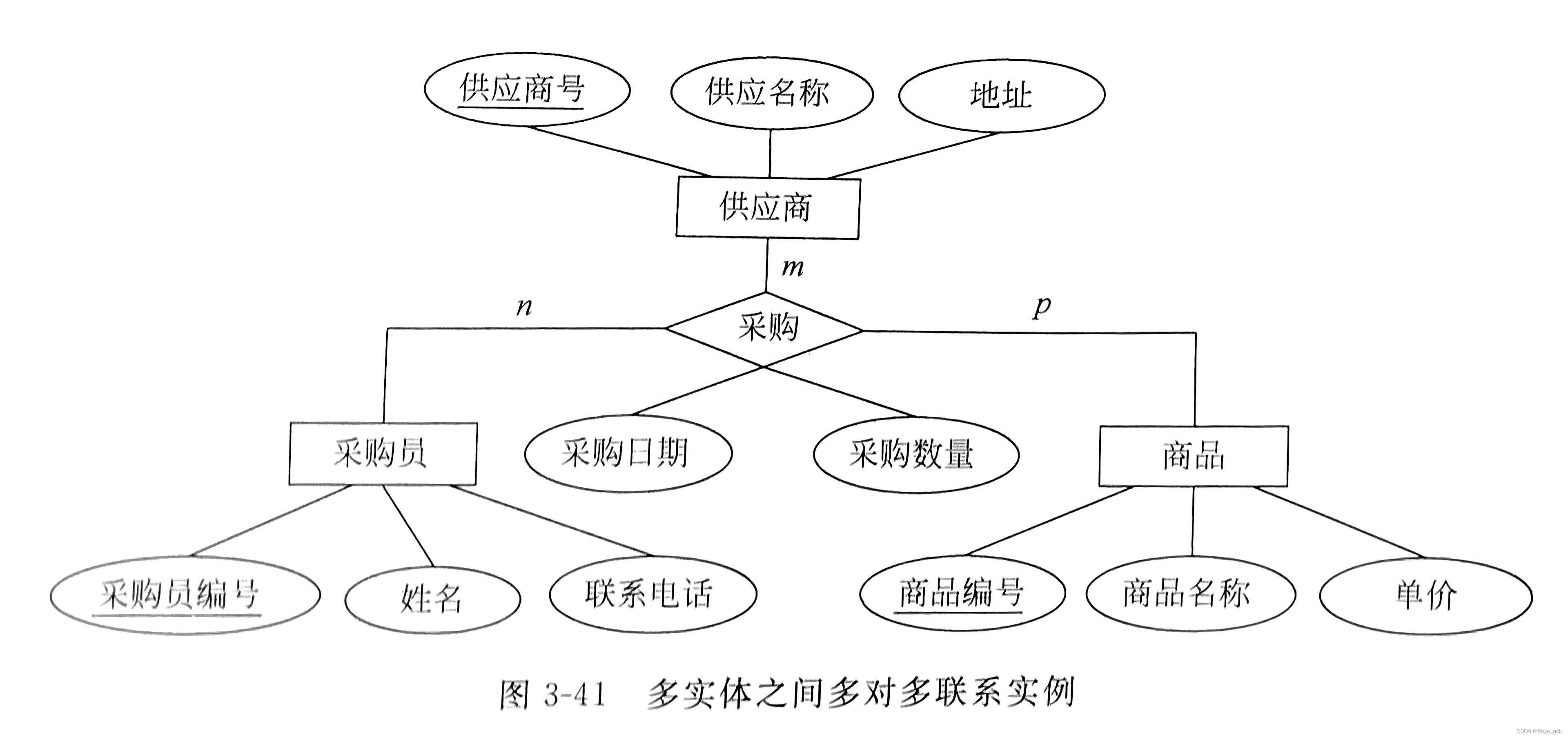
根据实体间多对多的转换规则,转换的关系模式为: 零件(零件编号,名称,单价)组装(组装件号,零件号,数量)其中,组装件号为组装后的复杂零件号。由于同一个关系中不允许存在相同的属性名,因此取名为组装件号。 【例5】 如图3所示的E-R 图给出了某公司网上采购系统数据库所涉及的供应商、商品和采购员的三个实体之间的多对多的多元联系,将其E-R 图转换为关系模式。
根据多实体间联系的转换规则,三个实体转换为三个关系模式,联系转换为一个独立的关系模式: 采购员(采购员编号,姓名,联系电话)供应商(供应商号,供应商名,地址)商品(商品编号,商品名称,单价)采购(采购员编号,供应商号,商品编号,采购日期,采购数量) 2、逻辑结构设计实例
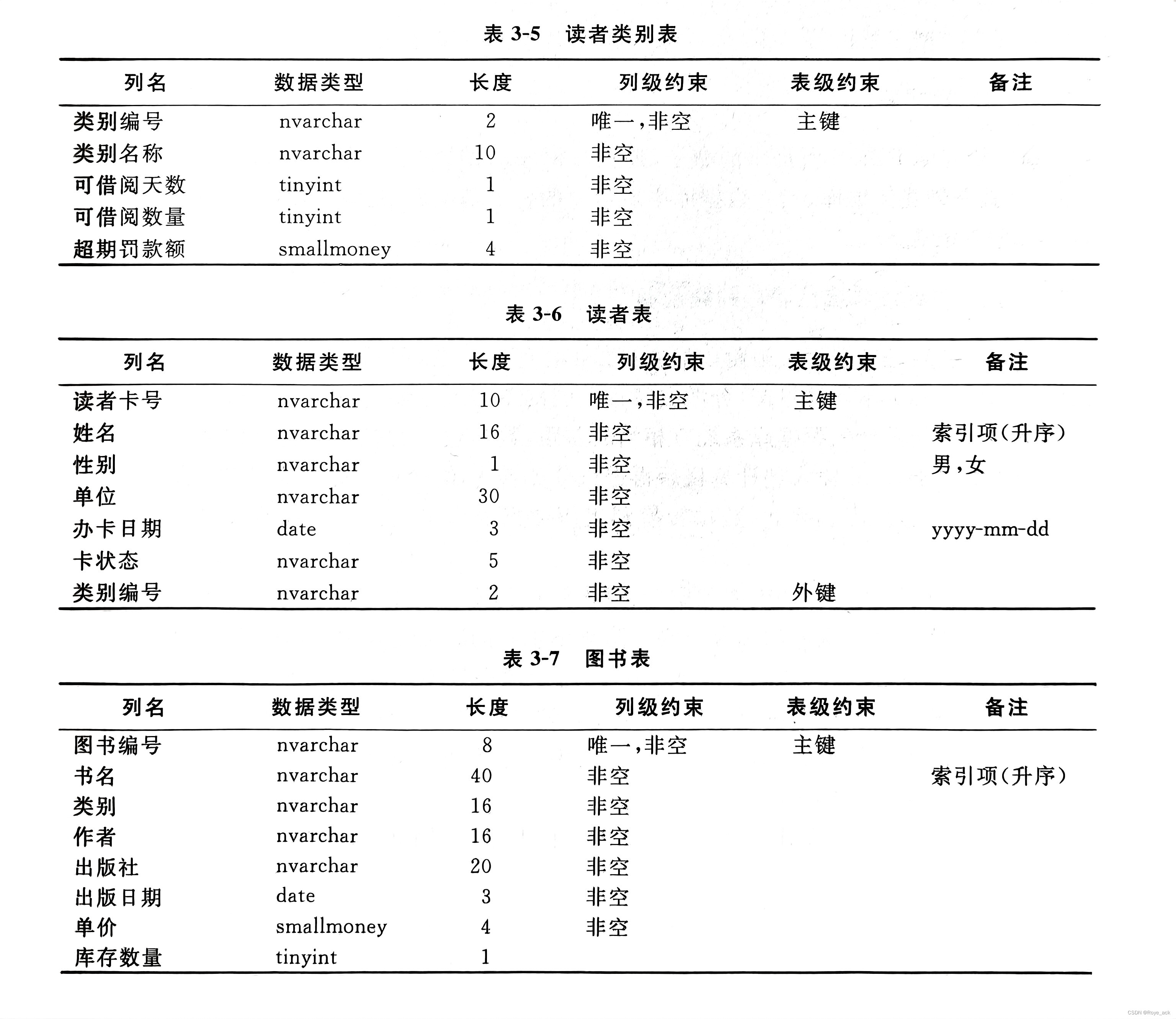
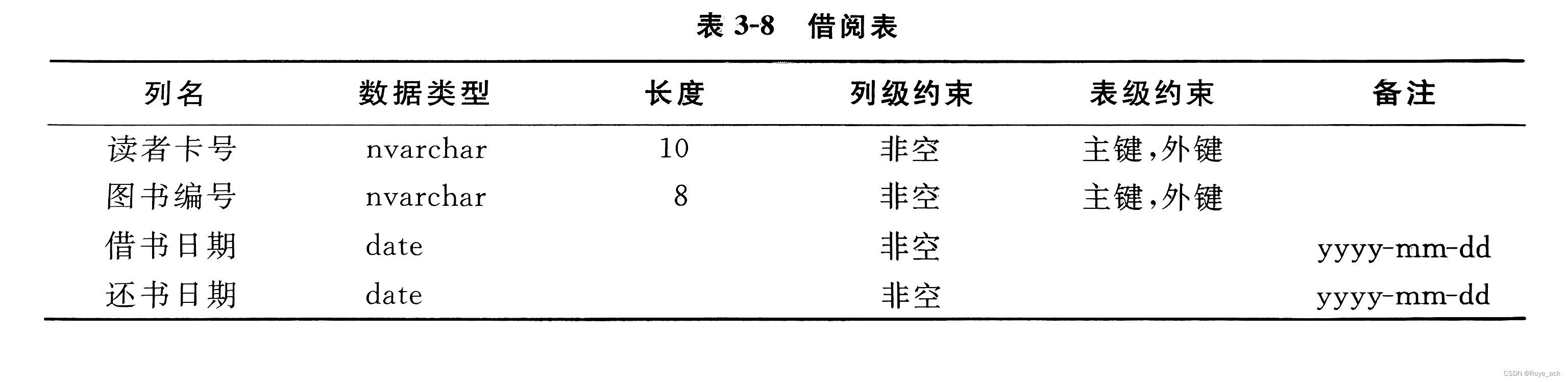
在查询时,先在索引文件中找到查询元组在数据表中的地址,再根据该地址,在数据表中直接取出元组数据。这种先查询索引文件,再从数据表中取值的检索机制称为索引机制。 选择索引的基本原则: 如果一个属性经常在查询条件中出现,则考虑在这个属性上建立索引,如果一组属性经常在查询条件中出现,则考虑在这组属性上建立组合索引。如果一个属性经常作为最大值和最小值等聚集函数的参数,则考虑在这个属性上建立索引。如果一个属性经常在连接操作的连接条件中出现,则考虑在这个属性上建立索引;同理,如果一组属性经常在连接操作的连接条件中出现,则考虑在这组属性上建立索引。对经常需要执行查询、连接、统计操作而又记录较多的关系建立索引,对经常进行插入、删除、修改操作的或记录较少的关系,避免建立索引。关系上定义的索引数要适当,并不是越多越好,因为系统维护索引要付出代价,更重要的是随着关系中数据的变化,索引需要维护更新以反映数据的变化。 (2)聚簇 把该属性或属性组上具有相同值的元组集中存放在连续的物理块上的处理称为聚簇一个数据库可以有多个聚簇,一个关系只能加入一个聚簇,如果一个表含多个聚簇,新建的聚簇会使前一个聚簇失效① 设计候选聚簇原则: 对经常在一起进行连接操作的关系可以建立聚簇。如果一个关系的一组属性经常出现在相等、比较条件中,则该单个关系可建立聚簇。如果一个关系的一个(或一组)属性上的值重复率很高,则此单个关系可建立聚簇。如果关系的主要应用是通过聚簇码进行访问或连接的,而其他属性访问关系的操作很少时,可以使用聚簇。尤其当SQL语句中包含有与聚簇有关的ORDER BY、GROUPBY、UNION、DISTINCT等子句或短语时,使用聚簇特别有利,可以省去对结果集的排序操作。反之,当关系较少利用聚簇码操作时,最好不要使用聚簇。② 从候选聚簇去除不必要关系: 从聚簇中删除经常进行全表扫描的关系。从聚簇中删除更新操作远多于连接操作的关系。不同的聚簇中可能包含相同的关系,一个关系可以在某一个聚簇中,但不能同时加入多个聚簇。③ 建立聚簇应注意的问题: 聚簇虽然提高了某些应用的性能,但是建立与维护聚簇的开销是相当大的。对已有的关系建立聚簇,将导致关系中的元组移动其物理存储位置,这样会使关系上原有的索引无效,要想使用原索引就必须重建原有索引。当一个元组的聚簇码值改变时,该元组的存储位置也要做相应移动,所以聚簇码值应当相对稳定,以减少修改聚簇码值所引起的维护开销。需要注意的是:聚簇索引虽然可以提高某些应用的性能,但是会改变数据的物理存储位置,而且会导致数据表的原有索引失效,同时维护费用很大,因此需要谨慎使用。 (3)散列hash选择hash原则: 如果一个关系大小可以预知,而且大小不变关系大小动态改变,且dbms提供动态hash存取方法 2、确定数据库的存储结构 3、物理结构设计样例
|








【本文地址】
今日新闻 |
推荐新闻 |