南邮MySQL实验报告一 |
您所在的位置:网站首页 › 数据库制作表格实验总结 › 南邮MySQL实验报告一 |
南邮MySQL实验报告一
|
创建数据库模式与SQL查询
一、实验目的和要求
1. 通过上机实践,熟悉MySQL的操作环境及使用方法。
2. 掌握数据表的创建以及表的操作。
3. 熟练掌握Select-SQL命令,进行数据的查询。
二、实验环境(实验设备)
硬件:微机
软件:Windows xp/Windows 10和MySQL
素材:实验数据
三、实验内容
1.采用CREATE DATABASE语句创建产品数据库products;
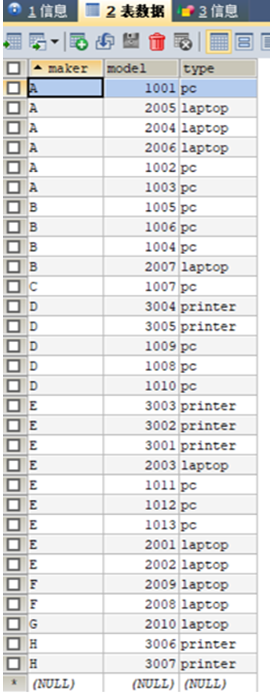
使用语句: CREATE DATABASE products; 2.采用CREATE TABLE语句创建产品数据库数据库products的关系模式;Product (maker, model, type) 使用语句: CREATE TABLE product( maker VARCHAR(20), model INT PRIMARY KEY, TYPE VARCHAR(20) );PC (model, speed, ram, hd, price) 使用语句: CREATE TABLE PC( model INT PRIMARY KEY, speed DOUBLE, ram INT, hd INT, price INT );Laptop (model, speed, ram, hd, screen, price) 使用语句: CREATE TABLE Laptop( model INT PRIMARY KEY, speed DOUBLE, ram INT, hd INT, screen DOUBLE, price INT );Printer (model, color, type, price) 使用语句: CREATE TABLE Printer( model INT PRIMARY KEY, color BOOLEAN, TYPE VARCHAR(20), price INT ); 3.采用COPY…FROM…语句将数据装入产品数据库;COPY_FROM说明: COPY_FROM (file,table,sep =‘\ t’,null =‘\ N’,size = 8192,columns = None)从类似文件的目标文件中读取数据,将它们附加到名为table的表中。 - file - 从中读取数据的类文件对象。它必须具有 read()和readline()方法。 - table - 要将数据复制到的表的名称。 - sep - 文件中预期的列分隔符。默认为选项卡。 - null - NULL文件中的文本表示。默认为两个字符串\N。 - size - 用于从文件中读取的缓冲区的大小。 - columns - 可以使用要导入的列的名称进行迭代。长度和类型应与要读取的文件的内容相匹配。如果未指定,则假定整个表与文件结构匹配。 MySQL读取数据语句如下(将数据添加到product表中): INSERT INTO product VALUES('A',1001,'pc'); INSERT INTO product VALUES('A',1002,'pc'); INSERT INTO product VALUES('A',1003,'pc'); INSERT INTO product VALUES('A',2004,'laptop'); INSERT INTO product VALUES('A',2005,'laptop'); INSERT INTO product VALUES('A',2006,'laptop'); INSERT INTO product VALUES('B',1004,'pc'); INSERT INTO product VALUES('B',1005,'pc'); INSERT INTO product VALUES('B',1006,'pc'); INSERT INTO product VALUES('B',2007,'laptop'); INSERT INTO product VALUES('C',1007,'pc'); INSERT INTO product VALUES('D',1008,'pc'); INSERT INTO product VALUES('D',1009,'pc'); INSERT INTO product VALUES('D',1010,'pc'); INSERT INTO product VALUES('D',3004,'printer'); INSERT INTO product VALUES('D',3005,'printer'); INSERT INTO product VALUES('E',1011,'pc'); INSERT INTO product VALUES('E',1012,'pc'); INSERT INTO product VALUES('E',1013,'pc'); INSERT INTO product VALUES('E',2001,'laptop'); INSERT INTO product VALUES('E',2002,'laptop'); INSERT INTO product VALUES('E',2003,'laptop'); INSERT INTO product VALUES('E',3001,'printer'); INSERT INTO product VALUES('E',3002,'printer'); INSERT INTO product VALUES('E',3003,'printer'); INSERT INTO product VALUES('F',2008,'laptop'); INSERT INTO product VALUES('F',2009,'laptop'); INSERT INTO product VALUES('G',2010,'laptop'); INSERT INTO product VALUES('H',3006,'printer'); INSERT INTO product VALUES('H',3007,'printer');插入数据后,表product的内容如图1所示。
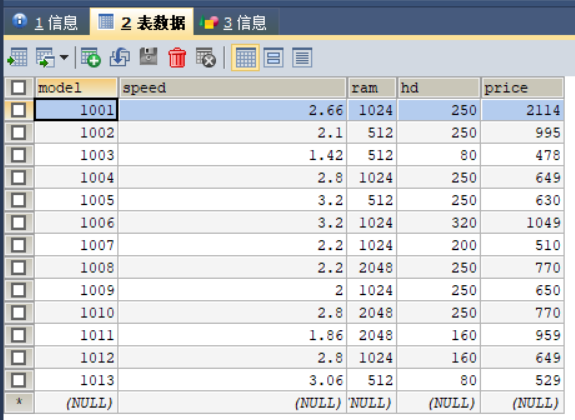
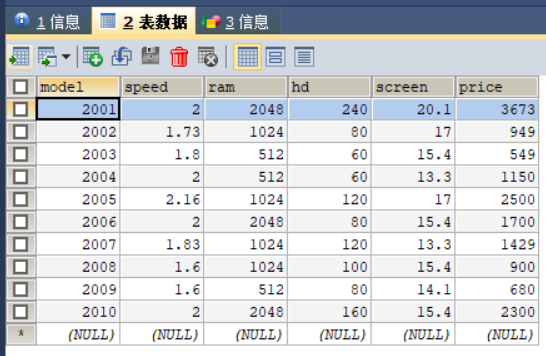
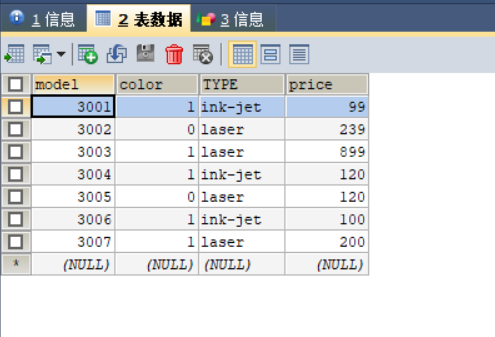
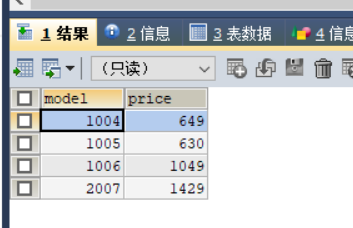
其他表数据的填充过程与表product填充过程类似,此处不再赘述。数据填充结果如图2,3,4所示。
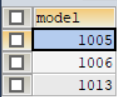
使用语句: SELECT model FROM pc WHERE speed>=3.00;查询结果如图5所示。
使用语句: SELECT DISTINCT(product.maker) FROM laptop,product WHERE laptop.model=product.model AND hd>100 AND TYPE='laptop';查询结果如图6所示。
使用语句: (SELECT product.model,pc.price FROM product,pc WHERE product.maker='B' AND product.model=pc.model) UNION( SELECT product.model,laptop.price FROM product,laptop WHERE product.maker='B' AND product.model=laptop.model) UNION( SELECT product.model,printer.price FROM product, printer WHERE product.maker='B' AND product.model=printer.model);查询结果如图7所示。
使用语句: SELECT model FROM printer WHERE color=TRUE AND TYPE='laser';查询结果如图8所示。
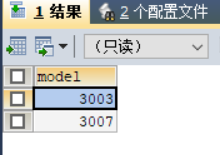
使用语句: SELECT DISTINCT(maker) FROM product WHERE maker IN (SELECT maker FROM ( SELECT DISTINCT maker FROM product t1 WHERE TYPE='laptop' UNION ALL SELECT DISTINCT maker FROM product t2 WHERE TYPE='pc' )t3 GROUP BY maker HAVING COUNT(maker)=1) AND TYPE='laptop';查询结果如图9所示。
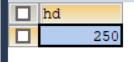
使用语句: SELECT hd FROM pc GROUP BY hd HAVING COUNT(hd)>2;查询结果如图10所示。
|


【本文地址】
今日新闻 |
推荐新闻 |