大内存时代 |
您所在的位置:网站首页 › 操作系统一页的大小怎么设置到桌面 › 大内存时代 |
大内存时代
|
“640K is enough for everybody”——比尔 盖茨 可惜有趣的历史几乎总是假的。 1996年,盖茨在接受媒体采访时澄清了有关“640K内存”的传闻:“我虽说过一些蠢话,做过一些傻事,可这句话绝对不是我说的。业界从没有人说某种容量的内存已经足够了的话。但竟然有人将640K内存已经足够这样无聊的话安在我的头上,经常有人问起我这件事。” 一、PageSize为什么不建议选择16KB或64KB目前手机的内存8GB已经算是低配,12GB,16GB在旗舰手机上都是常规的操作。事实上8GB的内存单价和12GB已经非常接近,所以很多手机厂商——实际上已经将12GB作为手机的最低配置。非常少的成本换来一个好名声,何乐而不为呢? 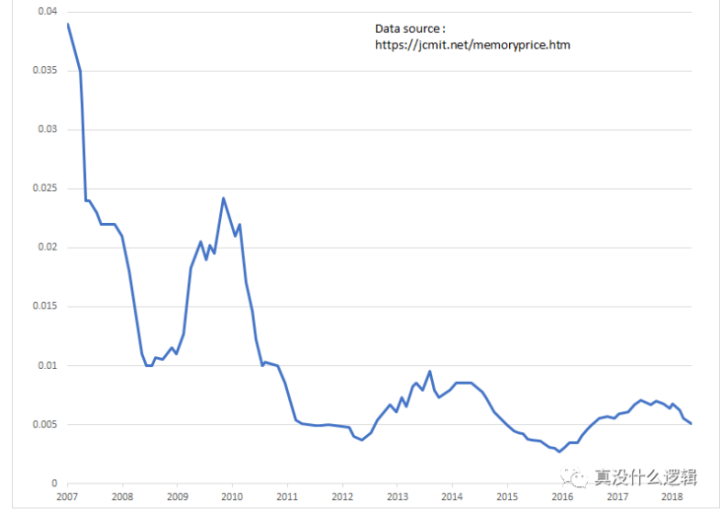 但如何利用好大内存是留给当前厂商的一个难题? 以前内存是紧巴着用,PageSize设置为4KB算是一个不错的方案。在任何一篇科普Linux中采用4KB配置的文章中,在文末总是说“4KB 的内存页是上个世纪决定的默认设置,随着内存越来越大,这很可能已经是错误的选择了”。 关键是这个大内存到底是多大?手机上的12GB算大吗? 阿里云上,大内存分配方式不再以4k为标准,而是1G,也不再使用页表的管理方式,这样的才算是大内存,手机上的12GB根本算不上大内存。 退一步讲,Kernel配置PageSize时,是否可以采用稍微大一点的值,比如16KB或者64KB。而这样的配置,ARM64架构早已经支持了。那为什么现在Linux系统的PageSize还是采用4KB,而没有哪个手机厂商说自己采用了16KB或者64KB呢? https://cateee.net/lkddb/web-lkddb/ARM64_64K_PAGES.htmlThis feature enables 64KB pages support (4KB by default) allowing only two levels of page tables and faster TLB look-up.事实上,我们几乎没法采用16KB或者64KB这样的配置。为了利用大内存,我们还有其他更好的方式。 为何linux最初选择4KB配置解答:x86架构下,页面大小为什么是4K?_Heron--Linux & ARM-CSDN博客 历史原因:32位逻辑地址空间的计算机系统,三级页表,每个页中每个条目占4Byte,即32位的数据。 设:页大小为X(byte)则:X/4就是每个页中可以存取的条目个数如果页面大小是8k,则第一级页表只能寻址2^8=256个entry,此时第一级页表就有2048-256=1792个entry不能使用。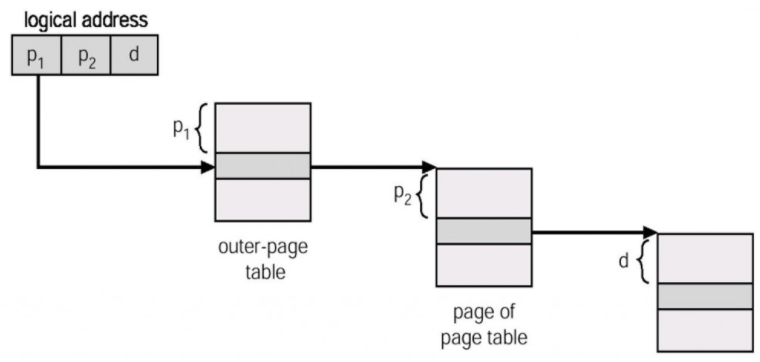 当然4KB不仅是历史的选择,也有实际的好处,是在实践中摸索出来的平衡的参数,如果16KB更好,那么也会重新设计页表大小和级数。 如今,无法台式机还是手机都是64位了,已经不是32位+3级页表,此时采用大页面似乎是非常合理的。 大页面的好处关于这个问题,早已是经典辩题,甚至linus本人也讲过自己的观点。但通常都是10年前的言论,下面这篇文章就是如此,很多技术其实已经不太一样了。 1 减小PageTable占用的内存 假设内存一定的话,页面大小越大,管理页面占用的内存也越小。现在内核中每个页面假设是4K的话,这4K不是全都可用,还有一部分用作struct page(大约是64bytes),所以页面比较大时,节省的内存比较多。但这个好处并不大,我在12G的机器测试,PageTable大小仅有128M 2 提高TLB的命中率 每次访问内存的时候,都要将虚拟地址转换为物理地址,如果每次都访问页表的话,消耗比较大。因此,通常使用TLB来加速这个过程。但是TLB的可以直接转换的地址范围是有限的(具体就是项数乘以页面大小),一旦出现TLB miss,这时就必须去页表中查找。所以,如果是大页面的话,同样TLB项数的情况下,可以跟踪更大的内存。其实还有一点没有提到,那就是64KB的页表是两级的,TLB查找更快 3 提高磁盘I/O 我们知道在访问磁盘时,最耗时的操作就是查找写入盘区的起始位置,也就是在磁盘盘片上将读写头置于正确的位置上(机械磁盘)。所以如果是大页面的话,可以减少写入磁盘的次数。比如要写入4M的缓存,页面大小是4M的话,只需写入1次,但是对于SSD是否有这样的优势还有待商榷。补充:如果磁盘的Sector大于4K;如果文件系统block大于4K,则大页面也会有些优势。 但是SSD磁盘secotor目前还是512byte,F2FS文件系统的所有块大小都是4KB,也就说这个优势用不上。 4 提供缓存利用率 如果是大页面的话,可以减少访问伙伴系统的次数。调用伙伴系统的操作队系统的数据和指令高速缓存有相当的影响。内核越浪费这些资源,这些资源对用户空间进程就越不可用。其实还有一个点需要补充。 5. 特供benchmark应用 这个对于用户无关紧要,但对于厂家还是非常有用。“如果我做一个东西出来,不能确切的说他哪里好,那么它就无意义”大页面的坏处1 内存浪费。 比如这时要分配的内存是4M+1byte,这时需要两个页面才能满足分配的需要,这个时候浪费的内存为4M-1byte。如果页面是4K的话,浪费的内存数量为4k-1byte。64KB的PageSize会好些,但我们知道随机读写占了应用的绝大部分,而随机读写通常小于4KB,申请内存也往往小于4KB,所以这种浪费仍然还是比较多的。 2 内存碎片 因为底层的内存管理是以页面为单位。如果系统运行了很长时间,空闲的内存很多,但是连续的内存块都小于要分配的页面数。这时可以通过移动内存块或者利用swap来获取可用内存,但是会导致分配内存的操作很慢,这种慢会形成恶性循环,严重影响系统的性能。如果是小页面的话,内存的利用会比较紧凑,分配页面时需要的连续内存块的大小不像大页面那样需要的那么大。3 Swap代价大 如果页面太大,在将内存页换出到swap分区时,需要换出的内存也就越大,会影响性能。目前一般将Zram作为swap分区,这个影响已经非常小了 4 不采用大页面的最主要原因还是兼容性问题 1)CMA分配的内存,很多都是在dts设定好的,迁移到伙伴系统是以PAGE_SIZE为单位。 这样的话你要对所有驱动重新配置;这样的话只是最好情况,很多时候你可能只能拿到ko,这样的话,你不能要求第三方重新编译一共这样的ko给你。 我们在将kernel的pagesize调整为64kb时,系统直接挂掉,就是存在这样的KO,CMA分配就失败了。 2)32位应用的兼容(流行游戏通常是32位的) config COMPAT1520 If you use a page size other than 4KB (i.e, 16KB or 64KB), please be aware1521 that you will only be able to execute AArch32 binaries that were compiled1522 with page size aligned segments. 同样遇到了这样的情况,你是否能让第三方应用专门给你出个对齐64KB的版本? 小结 kernel中调整pagesize大小——是为大内存准备的,但不是12GB,16GB。 对于手机而言,arm64位平台pagesize还只能是4KB,16KB,64KB这样的配置,由于存在兼容性问题,几乎无法使用。 但并不是说就不能利用好大内存了,其实还有更好的方式,那就是透明大页。 二、替代方案:透明大页另外一个可以利用大内存的方法是——透明大页,如果有更好的方式那就是——透明大页+madvise。 1 标准大页 与透明大页更早出现的概念是标准大页,通常是2MB作为一个页面大小。标准大页这个概念就是为了利用大内存而来的,服务于特定的应用。 相比将kernel的pagesize配置为64K或2M,标准大页只针对特定应用,一般用于大型数据库系统。对于其他大部分应用,则不受这个页面大小的影响,这就相当于将负面效果降低非常低的地步——兼容性问题不存在了。 不过标准大页有如下几个缺点:1) 大页必须在使用前就预留下来2) 应用程序代码必须显式使用大页3) 大页必须常驻物理内存中,不能给交换到交换分区中。4) 需要超级用户权限来挂载 hugetlbfs文件系统。5) 如果预留了大页内存但没有实际使用就会造成物理内存的浪费。2 透明大页 透明大页(Transparent Hugepage)正是发挥了大页的一些优点,又能避免了上述缺点。透明大页,如它的名词描述的一样,对所有应用程序都是透明的,应用程序不需要任何修改,即可享受透明大页带来的好处。 透明大页是不需要预留的,可以动态分配; 透明大页是可交换的,当需要交换到交换空间时,透明的大页被打碎为常规的 4KB 大小的内存页。而当系统内存较为充裕、有很多的大页面可用时,常规的页分配的物理内存可以通过 khugepaged 进程自动迁往透明大页内存。透明大页仅仅支持匿名内存的映射,对磁盘缓存和共享内存的透明大页支持看来还在进行。 kernel-4.19,手机上跑了下,shmem是空的。 AnonHugePages: 759808 kB ShmemHugePages: 0 kB ShmemPmdMapped: 0 kB透明大页分配有2种情况: 1)page fault: I. user space调用fadvise()/madvise()的时候设定advise/within_size (分配时使用),也就是说需要用户显示调用; II. 如果配置为always,则mmap的时候尽量使用大页分配; 透明大页存在大页的优势,也同样继承了大页的缺点——浪费空间在某些情况下,系统范围使用大页面,会导致应用分配更多的内存资源。例如应用程序mmap了一大块内存,但是只涉及1个字节,在这种情况下,2M页面代替4K页的分配没有任何好处,这就是为什么禁用全系统大页面,而只针对MADV_HUGEPAGE区使用的原因。但是我们指望应用主动调用madvise并不合理,第三方应用为了兼容性问题,不可能添加这样的接口,除非这个接口由Android推出。另外,除了大型应用有这个需求,一般应用也没有这个需求。 所以,我们如果想在手机平台上利用透明大页的优势,只能选择always模式? 那倒是没必要,你可以选择madvise,虽然无人响应,但是可以下面这种机制,也是一种帮助,虽然这个帮助非常小。 2)守护进程khugepaged 在后台将4k page转成2M等大页 需要详细了解该技术的可以看下参考链接 Kvm Thp 3 应用场景 尽管理论上,透明大页是能带来性能优势的,但是找到这样的场景同样是困难的。本着科学精神,分别找了五个场景。 场景一:自定义场景 简单测试——“分配1G内存,然后访问该内存”,参考[4] 结果如下:使用hugepage之后,性能提升2倍。 /data # time ./tmain time cost : 690868 /data # time ./tmain huge madvise time cost : 249367查看page fault,也不是一个数量级,说明这种场景效果Perfect! # simpleperf stat -e cache-references,cache-misses,page-faults -p 19251 Performance counter statistics: 723,991,492 cache-references # (100%) 5,214,705 cache-misses # 0.720272% miss rate (100%) 262,147 page-faults # (100%) Total test time: 5.000571 seconds. klein:/ # top | grep tmain 19662 root 20 0 33M 2.3M 1.9M S 0.0 0.0 0:00.00 grep tmain 19509 root 20 0 1.0G 2.5M 2.0M S 0.0 0.0 0:00.02 tmain huge # simpleperf stat -e cache-references,cache-misses,page-faults -p 19509 Performance counter statistics: 100,299,371 cache-references # (100%) 3,491,602 cache-misses # 3.481180% miss rate (100%) 514 page-faults # (100%) Total test time: 5.003025 seconds.但是指望应用主动调用madvise并不合理,而且手机应用,能一口气分配1G内存的程序员还没出现,我们还是找些更常用的场景。 场景二:应用启动——和平精英 Activity: com.tencent.tmgp.pubgmhd/com.epicgames.ue4.GameActivity TotalTime: 1431 WaitTime: 1432 Complete Performance counter statistics: 3,308,305,161 cache-references # (100%) 61,784,917 cache-misses # 1.867570% miss rate (100%) 78,231 page-faults # (100%) Total test time: 1.509417 seconds. ------------------------hugepage is under----------------------------- Activity: com.tencent.tmgp.pubgmhd/com.epicgames.ue4.GameActivity TotalTime: 1372 WaitTime: 1374 Complete Performance counter statistics: 3,341,940,142 cache-references # (100%) 62,638,357 cache-misses # 1.874311% miss rate (100%) 77,151 page-faults # (100%) Total test time: 1.469198 seconds.似乎使用hugepage配置有一些提升,包括page-fault也下降了一点,将时间拉长至15s,查看统计数据,这一优势仍然存在。 simpleperf stat -e cache-references,cache-misses,page-faults -p 28981 --duration 15 Performance counter statistics: 14,398,011,961 cache-references # (100%) 117,009,975 cache-misses # 0.812681% miss rate (100%) 139,252 page-faults ------------------------------------------------------------------- / # simpleperf stat -e cache-references,cache-misses,page-faults -p 31626 --duration 15 Performance counter statistics: 14,570,337,853 cache-references # (100%) 116,778,316 cache-misses # 0.801480% miss rate (100%) 137,092 page-faults # (100%)查看/proc/31626/smap,使用hugepages分配的内存并不多,下面是其中一段地址,这次一次性分配了10M。/dev/kgsl3d这样的GPU申请的内存并不在此列。 b9b2a000-ba6ec000 rw-p 00000000 00:00 0 Size: 12040 kB KernelPageSize: 4 kB MMUPageSize: 4 kB Rss: 12028 kB Pss: 12028 kB Shared_Clean: 0 kB Shared_Dirty: 0 kB Private_Clean: 0 kB Private_Dirty: 12028 kB Referenced: 12028 kB Anonymous: 12028 kB LazyFree: 0 kB AnonHugePages: 10240 kB ShmemPmdMapped: 0 kB场景三:应用加载——和平精英 Performance counter statistics: 16,688,484,429 cache-references # (100%) 347,252,184 cache-misses # 2.080789% miss rate (100%) 67,383 page-faults # (100%) Total test time: 15.000914 seconds. ------------------------huge page(below)----------------------------- Performance counter statistics: 16,275,554,594 cache-references # (100%) 368,516,010 cache-misses # 2.264230% miss rate (100%) 66,065 page-faults # (100%) Total test time: 15.000058 seconds.整体差异不大,此时查看AnonHugePages的大小在加载期间也基本没变。 场景四:Gralloc分配Buffer 如场景二中提到的,在绘图时,GPU分配的内存,比如用于texture的没有用到hugepage;对于GraphicBuffer来说,1080P大小为8M,理论上非常适合hugepage,然后我们基于这个来进行测试。 buffers[i] = new GraphicBuffer(1920, 1080, HAL_PIXEL_FORMAT_RGBA_8888, GRALLOC_USAGE_HW_TEXTURE | GRALLOC_USAGE_HW_RENDER);分配100次,发现Available急剧下降,AnonHugePages大小并没变,这说明根本没用到;2.分配1000次,Available内存由4GB下降到300K,而AnnoHugepages仍然未变,随后串口卡住,看来内存耗尽,最后死机重启。 看来这个场景仍然无法利用HugePage。 场景五:Benchmark Benchmark跑起来波动不小,特别是温控的影响。所以也没指望有多大的体现,说不准,有些玄学的东西就突然出现。比如像是同样的芯片,多核跑分有些就高很多,只是碰巧找到了一个牛逼的参数。 结果证明,玄学的东西没有出现,hugepage对于Benchmark没有帮助。 透明大页小结 主动调用madvise帮助巨大,但需要应用适配;应用启动也有些优化;其他场景优化不明显,理论上在系统运行期间也是有帮助的,我很想测试一下,但似乎很难验证,测试误差往往大于收益。而如果不明显,又何必要上项目的,毕竟任何的改动都是有风险的。 此时此刻,我又想起某些厂家““流畅度提升15%”的营销口号了,我真纳闷他们是怎么量化出来的,佩服!如果真有这样的营销团队,那么hugepage自然是非常有用了。 参考: 1.为什么linux kernel默认的页面大小是4K,而不是4M或8M? 2.解答:x86架构下,页面大小为什么是4K?_Heron--Linux & ARM-CSDN博客 3.为什么 Linux 默认页大小是 4KB 4.Linux虚拟内存管理_喜欢恋着风-CSDN博客 5.https://cloud.tencent.com/developer/article/1087455 6.透明大页_jason的笔记-CSDN博客 7. Kvm Thp |
【本文地址】
今日新闻 |
推荐新闻 |