|
前言
本文中,将通过爬取搜狗图片为例,分析Ajax请求来抓取网页数据 (通过传入关键字,已达到爬取不同类型图片的目的) AJAX引擎其实是一个JavaScript对象,全写是 window.XMLHttpRequest对象,由于浏览器的版本不同,特别是老版本的IE浏览器,虽然也支持AJAX引擎,但是写法上有区别,在IE低版本中通常用 ActiveXObject对象来创建AJAX引擎。 AJAX 来自英文“Asynchronous Javascript And XML” 的缩写,也称为异步JavaScript和XML。 简言之,就是一个JS对象,可以实现在网页加载完成以后,不用刷新的情况下与服务器交互。产生极好的用户体验效果。
1.抓取分析
爬取之前,先分析爬取逻辑。我们打开搜狗图片首页:[https://pic.sogou.com/]
如下
在搜索栏中输入关键字(例如美女,手动狗头haah)回车后跳转到详情页 然后打开开发者工具,查看所有网络请求,点击xhr,再点击全部
 我们点击新出现的Ajax请求,看看里面是否有我们需要的内容 点击preview选项卡,点击data字段展开,再点击items展开,点击第0个元素 如下 我们点击新出现的Ajax请求,看看里面是否有我们需要的内容 点击preview选项卡,点击data字段展开,再点击items展开,点击第0个元素 如下  发现picUrl就是我们要找的图片地址,而name可作为保存的path路径 点击下一个元素也是如此 发现picUrl就是我们要找的图片地址,而name可作为保存的path路径 点击下一个元素也是如此  因此,我们可以通过获取items列表,在遍历提取每张图片对应的网址和名称。 因此,我们可以通过获取items列表,在遍历提取每张图片对应的网址和名称。
2.使用python模拟Ajax请求
切换回headers选项卡,观察下url构成的规律
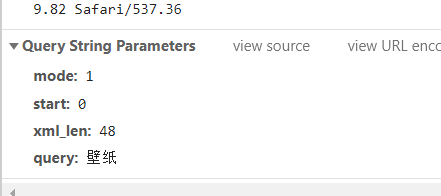 可以看到,这是一个get请求,请求url参数有mode,start,xml_len,query 只要我们找出规律,就可以方便的将程序构造出来 显而易见,query是我们输入的关键字,猜测start控制页数,xml_len为图片数量,我们回到之前的previe选项卡,发现items列表下元素数量真好是48,接下来,我们可以滑动页面,多加载一些Ajax请求出来 可以看到,这是一个get请求,请求url参数有mode,start,xml_len,query 只要我们找出规律,就可以方便的将程序构造出来 显而易见,query是我们输入的关键字,猜测start控制页数,xml_len为图片数量,我们回到之前的previe选项卡,发现items列表下元素数量真好是48,接下来,我们可以滑动页面,多加载一些Ajax请求出来  发现start增加了48,其他参数没有改变,所以我们可以通过改变参数start的值来达到爬取不同页数据的目的。 点击页面上高清,或最新按钮后,观察headers发现mode改变,最新 mode为20,高清为1。 发现start增加了48,其他参数没有改变,所以我们可以通过改变参数start的值来达到爬取不同页数据的目的。 点击页面上高清,或最新按钮后,观察headers发现mode改变,最新 mode为20,高清为1。 cwidith和cheight控制图片大小 cwidith和cheight控制图片大小
3.代码实现
已经分析好Ajax请求逻辑,下面就可以使用程序将图片下载并保存下来。
相关代码如下:
import requests,time,os
from multiprocessing.pool import Pool
from urllib.parse import urlencode
class sogoupic():
def __init__(self,keyword,mode=1):
#mode=1默认爬取全部,可通过更改mode的值爬取其他类型的图片
self.keyword=keyword
self.mode=mode #以便后续函数调用
self.header={
'Host':'pic.sogou.com',
'Referer':'https://pic.sogou.com/pics?query=%s&mode=%s'%(keyword.encode('gbk'),str(mode)),
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36'
} #伪装请求头
#不知道为啥直接传keyword会报错,希望有大佬能为我解答
def get_json(self,url):
#传入参数url
try:
res=requests.get(url=url,headers=self.header)
if res.status_code==200:
return res.json() #返回json格式的数据
except requests.ConnectionError:
return None #如果访问失败返回None
def get_img(self,page):
#传入参数page控制爬取页数
params={
'mode':self.mode,
'start':page,
'xml_len':48,
'query':self.keyword
}
url='https://pic.sogou.com/napi/pc/searchList?'+urlencode(params)
#拼接网址 使用urlencode()将params编码为我们在浏览器地址栏看得到的那样
json=self.get_json(url)
if json:
imgurls=json['data']['items']
#json数据就像python中的字典,同时里面嵌套了字典和列表
#也可使用pythonjson模块解析 可参考https://blog.csdn.net/suipingsp/article/details/39480341
for img in imgurls:
picurl=img['picUrl']#图片网址
name=img['name']#图片名称.后面用作图片保存的path
yeild{
'name':name,
'picurl':picurl
} #相当于返回了一个生成器,以节约内存
else:
return None #若获取json数据失败则返回none
def down_pic(self,name,url):
if not os.path.exists(r'D:\pyfiles\picture'):
os.makedirs(r'D:\pyfiles\picture')#如果不存在,就创建文件夹
path=r'D:\pyfiles\picture\%s'%name
try:
res=requests.get(url=url)
if res.status_code==200:
with open(path,'wb') as f:
f.write(res.content)
print('下载成功!')
except requests.ConnectionError:
print('下载失败!')
crawler=sogoupic('风景') #实例化对象,传入所需要的爬取图片的关键字
def main(page):
imgs=crawler.get_img(page) #调用get_img()方法,获取图片网址和名称
if imgs:
for img in imgs:
crawler.down_pic(img['name'],img['picurl']) #传入名称和网址
#调用爬取图片并保存
else:
print('爬取失败!')
if __name__=='__main__':
page=int(input('请输入爬取页数:'))
pool=Pool() #调用mutiprocessing 中的进程池方法进行多进程下载
groups=range(page+1)
pool.map(main,groups)
#用map()获取结果,在map()中需要放入函数和需要迭代运算的值,然后它会自动分配给CPU核,返回结果
pool.close()
pool.join()
加了多进程还是有点慢,可能是我学校的网太烂了
python多进程可参考:[https://blog.csdn.net/weixin_38611497/article/details/81490960?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.control&dist_request_id=&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.control] 小弟第一次写博客,请大佬们手下留情,也请大佬们多指点。 
|