神经网络的计算步骤 |
您所在的位置:网站首页 › 损失函数的计算是针对神经网络整体的吗 › 神经网络的计算步骤 |
神经网络的计算步骤
|
神经网络的计算步骤
输入层1、数据输入
隐藏层正向传播:输入端向输出端传递信息2、得到输出值:直线方程进行预测
误差反向传播:输出端向输入端传递信息3、得到误差:损失函数计算误差4、得到偏导数:计算图高效计算偏导数5、更新权重偏置:梯度下降法学习,最小化误差6、反向传播完整流程
输出层
一个神经网络分为输入层、隐藏层、输出层。 输入层:输入数据隐藏层:负责计算输出层:计算和输出结果
比如图像数据,世界上的所有颜色都可以通过,红绿蓝三种颜色调配出来。 计算机保存一张图片,要保存三个独立矩阵,分别对应红、绿、蓝三个颜色通道。 假设图片是 64x64 像素的,就有 3 个 64x64 的矩阵,分别对应红绿蓝三个像素的亮度。 为了方便计算,我们会把 3 个矩阵转化为 1 个列向量(特征向量)。
隐藏层 正向传播:输入端向输出端传递信息 2、得到输出值:直线方程进行预测 将待预测数据,这些特征 x 1 ⋅ ⋅ ⋅ x 1288 x_{1}···x_{1288} x1⋅⋅⋅x1288 输入到神经网络中:
单层神经元的计算,就是一个直线方程: y i ^ = σ ( W T x i + b ) \hat{y_{i}}=\sigma(W^{T}x_{i}+b) yi^=σ(WTxi+b)前置知识:为什么是一个直线方程,请猛击《神经元的计算》。 现在我们来看多层神经元:
如果第 i + 1 i+1 i+1 层神经元有 n n n 个,则第 i + 1 i+1 i+1 层神经元共有 m*n 个权重。 我们会用一个 m*n 矩阵来存储:
再计算激活函数,如 s i g m o d sigmod sigmod 函数: def sigmod(x): return 1 / (1 + e.exp(-x)) y = sigmod(u)得到当前层输出 y y y,再把 y y y 当成下一层的输入。 我们以一个三层神经网络举例: 这是处理回归问题的正向传播过程,还有一类问题是分类。 比如处理二分类任务,输出层需要俩个神经元:
除了输出层的激活函数使用 s o f t m a x softmax softmax 函数外,其他地方都不变。 def output_layer( x , w, b ): # 输出层,输入 x、权重 w、偏置 b u = np.dot( x, w ) + b # 直线方程 return np.exp( u ) / np.sum( np.exp( u ) ) # softmax 函数输出层输出的是一个概率值,我们比较俩个神经元的概率值,取最大值。
误差反向传播:输出端向输入端传递信息 比如识别猫,对输出层的判断为猫的神经元来说,调整方向就是要让TA的输出值变大; 对其他神经元,调整方向则是让输出值变小。 误差反向传播就是调整网络中每个神经元的权重,使得网络的总体误差减少的一个过程。 这个过程在中间层(隐藏层)的神经元中尤为复杂,因为调整一个中间层神经元的参数会同时影响所有输出层神经元的输入值。 因此,我们需要考虑一个神经元对最终输出误差的整体影响。 在这个过程中,我们寻找一个叫做“误差梯度”的方向来调整参数。 这个梯度告诉我们如何调整网络的权重才能有效地减少总体误差。 因为梯度本身代表了误差对网络各权重的变换比例。 当我们微小地改变某个输入(比如 B B B)时,输出(比如 C C C)会发生多大的变化。反向传播过程: 前向传播过程:直线方程计算权重参数把输入值相加,再加入偏移值得到一个处理结果,加上激活函数形成一个输出值。 反向传播过程:损失函数计算误差,通过计算图先计算第 N 层的偏导数(变化比例),再计算第 N-1 层的,输出层反向往前推,直到输入层;再通过梯度下降法学习,最小化误差。 这样来回不停的进行前向传播、反向传播,来训练(更新)参数使损失函数越来越小(预测越来越准确)。 原理:每次新的训练数据进来,就根据正确答案对参数进行一次参数微调,使得神经网络输出数值更接近正确答案。 首先把数据,分为:输入数据、正确答案。 正向传播输出与正确答案对比: 3、得到误差:损失函数计算误差 对预测的输出和正确答案的误差,进行定义的就是损失函数。 在上篇,激活函数的作用是在神经网络的每一层引入非线性,帮助网络学习复杂的数据模式。常见的激活函数包括ReLU, Sigmoid, Tanh等。损失函数(如交叉熵)用于训练过程中,衡量模型的预测输出与实际标签之间的差距。 目的是指导网络调整参数以减少预测误差。
这是对单个训练样本(一张图)的损失函数,但我们输入都神经网络的通常是一个训练集(大量的图片)。 我们需要累加单个训练样本的结果,再求平均值: 1 m ∑ i = 1 m L ( y i ^ , y i ) \frac{1}{m}\sum_{i=1}^{m}L(\hat{y_{i}}, y_{i}) m1∑i=1mL(yi^,yi)为什么使用【交叉熵】损失函数呢? 这个损失函数的函数图像是一个向下凸的图形。
也就是在这个函数图像的底部找到一组 w w w 和 b b b。 这个损失函数没有局部最优解,只存在唯一的全局最优解。 为什么交叉熵损失函数,能确保找到最优解的原因,请猛击: 【零基础入门】凸优化1:怎么培养研究能力,从模型 + 优化开始!我们要做的,是求出损失函数的梯度,而后运用梯度下降法求出损失最小的一组 w 和 b。 4、得到偏导数:计算图高效计算偏导数我们用函数 J ( a , b , c ) = 3 ( a + b c ) J(a,~b,~c) = 3(a+bc) J(a, b, c)=3(a+bc) 来演示传播过程。 为了让神经网络计算,函数 J J J 以计算图的形式计算:
反向传播用于计算函数
C
C
C 关于各个参数的偏导数(变化比例),而后对参数进行梯度下降。 偏导数、斜率就是变化比例,即 B B B 变化一点后 C C C 会相应的变化多少。 所以,为了计算 B B B 的偏导数,我们假设让 B B B 变化一点点,比如 B B B 加上 0.001 0.001 0.001(11.001),而后看 C C C 改变了多少, C C C 从 33 33 33 变成了 33.003 33.003 33.003。 C C C 的变化量除以 B B B 的变化量(0.003 / 0.001 = 3),即偏导数(变化比例)为 3 3 3。 同理, B B B 关于 A A A 的偏导数为 d B d A = 1 \frac{dB}{dA} = 1 dAdB=1。 同理, A A A 关于 b b b 的偏导数为 d A d b = 2 \frac{dA}{db} = 2 dbdA=2。 那么, C C C 关于 A A A 的偏导数是多少呢? 我们让 A A A 改变一点点,从 6 6 6 变成 6.001 6.001 6.001,这会导致 B B B 从 11 11 11 变成 11.001 11.001 11.001,而 B B B 的改变会导致 C C C 从 33 33 33 变成 33.003 33.003 33.003, C C C 的改变量除以 A A A 的改变量等于 3 3 3(0.003/0.001=3),即偏导数 d C d A \frac{dC}{dA} dAdC 为 3 3 3。其实间接传导的计算,我们用链式法则求导: C C C 关于 A A A 的偏导数 = C C C 关于 B B B 的偏导数 * B B B 关于 A A A 的偏导数,即 d C d A = d C d B ∗ d B d A = 3 ∗ 1 = 3 \frac{dC}{dA} = \frac{dC}{dB}*\frac{dB}{dA}=3*1=3 dAdC=dBdC∗dAdB=3∗1=3同理, C C C 关于参数 b b b 的偏导数 d C d b = d C d B ∗ d B d A ∗ d A d b = 3 ∗ 1 ∗ 2 = 6 \frac{dC}{db}=\frac{dC}{dB}*\frac{dB}{dA}*\frac{dA}{db}=3*1*2=6 dbdC=dBdC∗dAdB∗dbdA=3∗1∗2=6。 d C d b \frac{dC}{db} dbdC 这个偏导数才是我们最终需要的,我们需要的是函数 C C C 关于参数 a 、 b 、 c a、b、c a、b、c 的偏导数。 为了得到这三个偏导数,我们需要先计算出关于 B B B 的偏导数,而后再计算出关于 A A A 的偏导数,最后计算出关于参数 a 、 b 、 c a、b、c a、b、c 的偏导数。 d a = d C d a = d C d B ∗ d B d a = 3 ∗ 1 = 3 da=\frac{dC}{da}=\frac{dC}{dB}*\frac{dB}{da}=3*1=3 da=dadC=dBdC∗dadB=3∗1=3 d b = d C d b = d C d B ∗ d B d A ∗ d A d b = 3 ∗ 1 ∗ 2 = 6 db=\frac{dC}{db}=\frac{dC}{dB}*\frac{dB}{dA}*\frac{dA}{db}=3*1*2=6 db=dbdC=dBdC∗dAdB∗dbdA=3∗1∗2=6 d c = d C d c = d C d B ∗ d B d A ∗ d A d c = 3 ∗ 1 ∗ 3 = 9 dc=\frac{dC}{dc}=\frac{dC}{dB}*\frac{dB}{dA}*\frac{dA}{dc}=3*1*3=9 dc=dcdC=dBdC∗dAdB∗dcdA=3∗1∗3=9反向传播后更新 d a 、 d b 、 d c da、db、dc da、db、dc 的值是通过: a ′ = a − r ∗ d a a'=a -r*da a′=a−r∗da b ′ = b − r ∗ d b b'=b -r*db b′=b−r∗db c ′ = c − r ∗ d c c'=c -r*dc c′=c−r∗dc计算得到新的 a 、 b 、 c a、b、c a、b、c 的值,然后再进行前向传播的到新的 J J J 函数,再进行反向传播,直到寻到最小误差。 人工神经网络就是一个多层的复合函数。这种复合函数求偏导时是不能直接对 a 、 b 、 c a、b、c a、b、c 求偏导,只能对中间函数求依次求偏导从而得出 a 、 b 、 c a、b、c a、b、c 的偏导数,即链式法则。 5、更新权重偏置:梯度下降法学习,最小化误差所谓学习,就是最小化误差的处理。 以最小的神经网络举例,给定一个样本(1, 0) 训练。 单样本的误差平方函数: J = 1 2 ( a − y ) 2 J=\frac{1}{2}(a-y)^{2} J=21(a−y)2损失函数为: J ( w ) = 1 2 ( w x − y ) 2 = 1 2 ( w 1 − 0 ) 2 = 1 2 w 2 J(w)=\frac{1}{2}(wx-y)^{2}=\frac{1}{2}(w1-0)^{2}=\frac{1}{2}w^{2} J(w)=21(wx−y)2=21(w1−0)2=21w2损失函数图像: 一开始有一个初始值(左边的红点),我们需要找到最合适的w(谷底的w),使J最小。 那如何自动找到这个谷底呢?
梯度下降公式: w = w − a d J d w w=w-a\frac{dJ}{dw} w=w−adwdJ d J d w \frac{dJ}{dw} dwdJ:变化比例,w变化时,J相应变化多少w − d J d w w-\frac{dJ}{dw} w−dwdJ 中间是负号: 点在左边时,梯度是负的,负负得正,w会增加,体现在图中是在 x 轴向右方向走点在右边时,梯度是正的,w会减少,体现在图中是在 x 轴上向左方向走最终都会向谷底靠拢除此之外,还有一个参数 a,代表学习率: 梯度下降法的寻找思路是:粗调 + 精调。 首先粗调:迭代步长要大,很快确定大致范围其次精调:迭代步长要小,速度很慢,确定精度就好像用显微镜一样,粗调可以看到大致图像,精调可以看清楚图像。
具体步骤就是,先随机在曲线上找一个点,然后求出该点的斜率,也称为梯度。 顺着这个梯度的方向往下走一步,到达一个新的点之后,重复以上步骤,直到到达最低点(或达到我们满足的某个条件)。 如,对 w w w 进行梯度下降,则就是重复一下步骤(重复一次称为一个迭代): w = w − r ( d J d w ) w = w - r(\frac{dJ}{dw}) w=w−r(dwdJ) b = b − r ( d J d b ) b = b - r(\frac{dJ}{db}) b=b−r(dbdJ)其中 = = = 代表 “用后面的值更新”, r r r 代表学习率(learning rate), d J d w \frac{dJ}{dw} dwdJ 就是 J J J 对 w w w 求偏导。 梯度下降法完整内容:《梯度下降法》。 6、反向传播完整流程反向传播 3 个组件: 损失函数:损失函数(如交叉熵损失)衡量了神经网络的预测结果与实际结果之间的差异。它是一个关键指标,表明了网络当前的性能。在训练过程中,目标是最小化这个损失函数,这意味着我们想让网络的预测尽可能接近真实标签。 计算图:计算图是神经网络中所有计算的图形表示。它包括节点(代表操作,如加法、乘法、激活函数)和边(代表数据流,如权重、偏置、激活值)。在反向传播中,计算图用于有效地计算每个参数(权重和偏置)的梯度。 梯度下降:这是一个优化算法,用于更新神经网络中的参数(权重和偏置),以便最小化损失函数。梯度本身是损失函数关于每个参数的偏导数,指出了损失最快减少的方向。 流程图: 在反向传播中,这三个组件是这样协作的: 前向传播:数据通过网络的计算图从输入层流向输出层。每个节点都执行特定的计算,如权重与输入的乘积、加法操作和激活函数。最终,输出层给出预测结果。 计算损失:损失函数计算预测结果和真实结果之间的差距。这个损失值是优化过程的基础。 反向传播:在计算了损失之后,反向传播过程开始。在这个阶段,使用链式法则沿着计算图反向传递,计算损失函数相对于每个参数的梯度。这个过程利用了计算图的结构,有效地计算这些梯度。 参数更新(梯度下降):一旦获得了损失函数相对于所有参数的梯度,就使用梯度下降算法来更新这些参数。这通常涉及从每个参数中减去其梯度乘以一个学习率。 通过这个循环过程,神经网络逐渐调整其参数,以最小化损失函数,从而提高其在任务(如分类、回归等)上的表现。 这个过程是神经网络学习和优化的核心。 输出层 项目驱动:《识别猫的项目》。 |

 这个向量的总维数就是 64*64*3,结果是 12288 个特征。
这个向量的总维数就是 64*64*3,结果是 12288 个特征。
 如果第
i
i
i 层神经元有
m
m
m 个,那第
i
+
1
i+1
i+1 层的每个神经元都得存储
m
m
m 个权重。
如果第
i
i
i 层神经元有
m
m
m 个,那第
i
+
1
i+1
i+1 层的每个神经元都得存储
m
m
m 个权重。 当前层的神经网络计算:
当前层的神经网络计算:  编程实现:
编程实现:





 理论上我们可以用平方,但是在工程中,我们一般会用【交叉熵】损失函数:
理论上我们可以用平方,但是在工程中,我们一般会用【交叉熵】损失函数: 因为学习,就是找到一组
w
w
w 和
b
b
b,使这个损失函数最小。
因为学习,就是找到一组
w
w
w 和
b
b
b,使这个损失函数最小。 一开始,我们随机初始化
a
、
b
、
c
a、b、c
a、b、c 分别为
5
、
3
、
2
5、3、2
5、3、2,前向传播过程如下图:
一开始,我们随机初始化
a
、
b
、
c
a、b、c
a、b、c 分别为
5
、
3
、
2
5、3、2
5、3、2,前向传播过程如下图: 前向传播得到输出值。
前向传播得到输出值。 我们先计算
C
C
C 关于
B
B
B 的偏导数,记为
d
C
d
B
\frac{dC}{dB}
dBdC。
我们先计算
C
C
C 关于
B
B
B 的偏导数,记为
d
C
d
B
\frac{dC}{dB}
dBdC。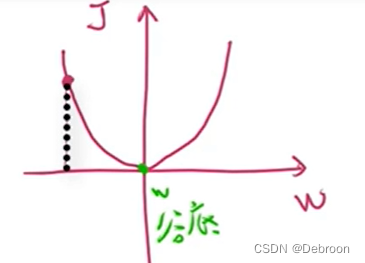
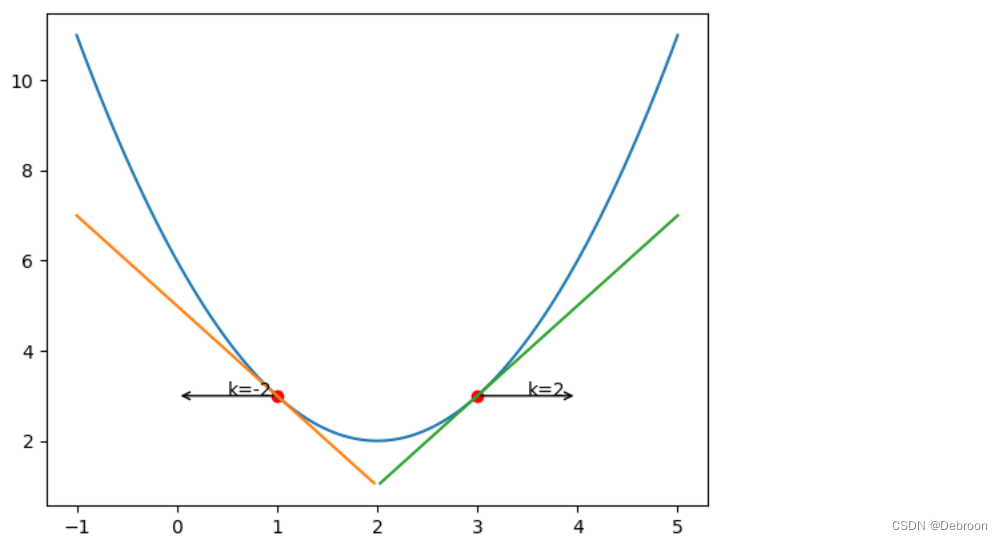 当寻找点在左边时,梯度是负数,在右边时,梯度是正数。
当寻找点在左边时,梯度是负数,在右边时,梯度是正数。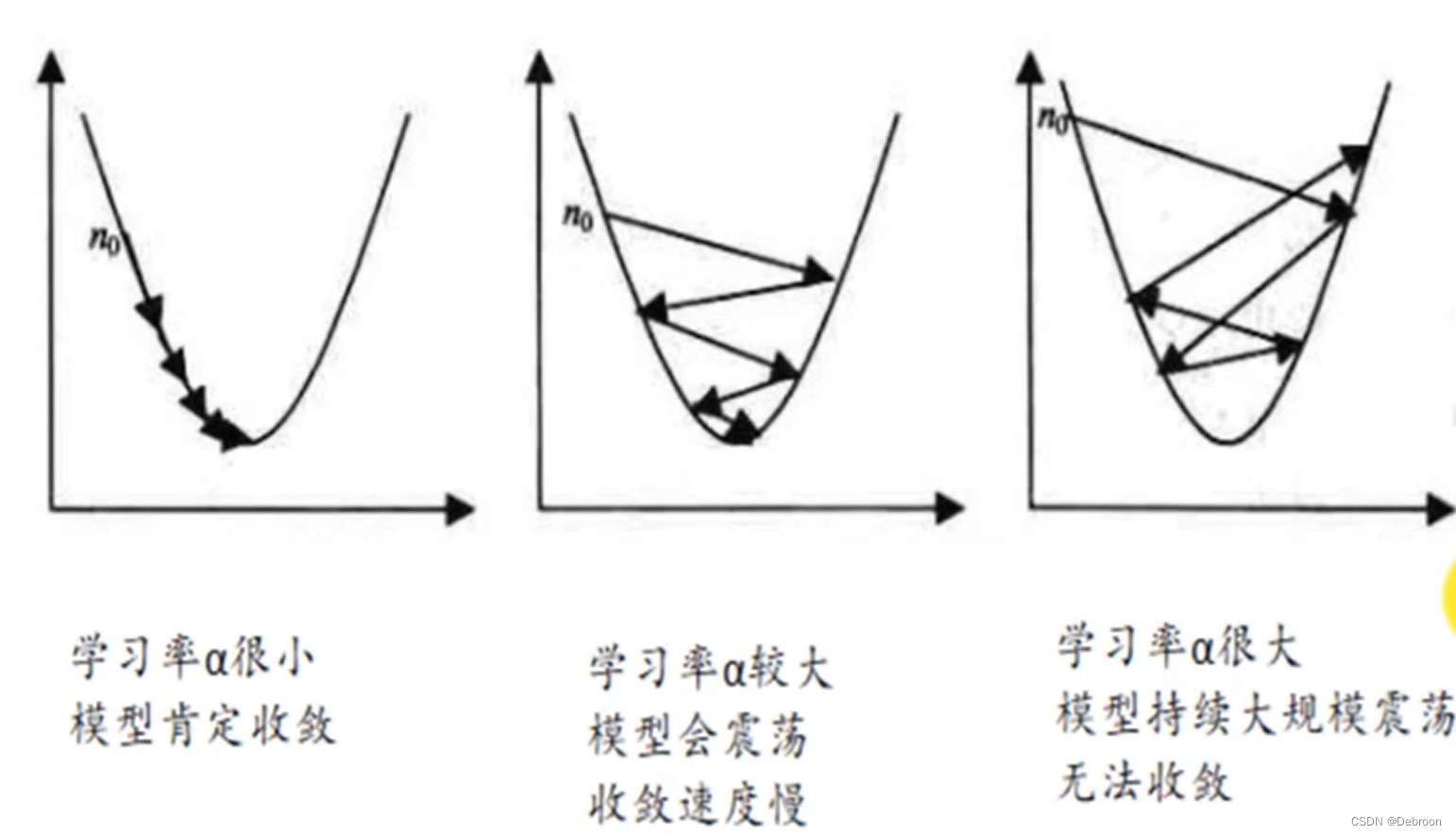 一般 a = 0.01,太高会造成震荡,在俩边跳来跳去;太小下降很慢。
一般 a = 0.01,太高会造成震荡,在俩边跳来跳去;太小下降很慢。

【本文地址】
今日新闻 |
推荐新闻 |