深度学习常用损失MSE、RMSE、MAE和MAPE |
您所在的位置:网站首页 › 损失函数和代价函数一样吗为什么 › 深度学习常用损失MSE、RMSE、MAE和MAPE |
深度学习常用损失MSE、RMSE、MAE和MAPE
|
MSE 均方差损失( Mean Squared Error Loss)
MSE是深度学习任务中最常用的一种损失函数,也称为 L2 Loss MSE是真实值与预测值的差值的平方然后求和平均 范围[0,+∞),当预测值与真实值完全相同时为0,误差越大,该值越大
平方误差有个特性,就是当 yi 与 f(xi) 的差值大于 1 时,会增大其误差;当 yi 与 f(xi) 的差值小于 1 时,会减小其误差。这是由平方的特性决定的。也就是说, MSE 会对误差较大(>1)的情况给予更大的惩罚,对误差较小(1 还是 y-f(x) |
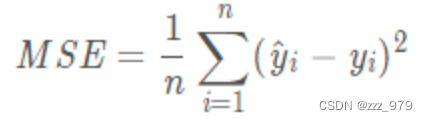
 MSE 曲线的特点是光滑连续、可导,便于使用梯度下降算法,是比较常用的一种损失函数。而且,MSE 随着误差的减小,梯度也在减小,这有利于函数的收敛,即使固定学习因子,函数也能较快取得最小值。
MSE 曲线的特点是光滑连续、可导,便于使用梯度下降算法,是比较常用的一种损失函数。而且,MSE 随着误差的减小,梯度也在减小,这有利于函数的收敛,即使固定学习因子,函数也能较快取得最小值。【本文地址】
今日新闻 |
推荐新闻 |