什么是CSV文件,如何使用 |
您所在的位置:网站首页 › 拼音里的o怎么读音组词 › 什么是CSV文件,如何使用 |
什么是CSV文件,如何使用
|
前提条件 通过主账号登录阿里云 Databricks控制台。 已创建集群,具体请参见创建集群。 已使用OSS管理控制台创建非系统目录存储空间,详情请参见创建存储空间。 警告首次使用DDI产品创建的Bucket为系统目录Bucket,不建议存放数据,您需要再创建一个Bucket来读写数据。 说明DDI访问OSS路径结构:oss://BucketName/Object BucketName为您的存储空间名称。 Object为上传到OSS上的文件的访问路径。 例:读取在存储空间名称为databricks-demo-hangzhou文件路径为demo/The_Sorrows_of_Young_Werther.txt的文件 // 从oss地址读取文本文档 val dataRDD = sc.textFile("oss://databricks-demo-hangzhou/demo/The_Sorrows_of_Young_Werther.txt"csv读取程序的可选项说明实际应用场景中遇到的数据内容或结构并不是那么规范,所以CSV读取程序包含大量选项(option),通过这些选项可以帮助解决例如忽略特定字符等问题 read/write Key 取值范围 默认值 说明 Both sep 任意单个字符串字符 , 用作每个字段和值的分隔符的单个字符 Both header true,false false 一个布尔标记符,用于声明文件中的第一行是否为列的名称 Both escape 任意字符窜 \ 用于转译的字符 Both inferSchema true,false false 指定在读取文件时spark是否推断列类型 Both ignoreLeadingWhiteSpace true,false false 声明是否应跳过读取中的前导空格 Both ignoreTrailingWhiteSpace true,false false 声明是否应跳过读取中的尾部 空格 Both nullValue 任意字符串字符 "" 声明在文件中什么字符表示null值 Both nanValue 任意字符串字符 NaN 声明什么字符表示CSV文件中的NaN或缺失字符 Both positiveInf 任意字符串字符 Inf 声明什么字符表示正无穷大 Both negativeInf 任意字符串字符 -Inf 声明什么字符表示负无穷大 Both Compression 或Code None,Uncompressed,bzip2,deflate,gzip,lz4,snappy none 声明spark应该用什么压缩解码器来读取或写入文件 Both dataFormat 任何符合Java的SimpleDataFormat的字符串或字符 yyyy-MM-dd 日期类型的日期格式 Both timestampFormat 任何符合Java的SimpleDataFormat的字符串或字符 MMdd 'T' HH:mm ss.SSSZZ 时间戳类型,时间戳格式 Read maxColumn 任意整数 20480 声明文件中的最大列数 Read maxCharsPerColumn 任意整数 1000000 声明列中最大字符数 Read escapeQuote true,false true 声明spark是否应该转义在行中找到的引号 Read maxMalformadLogPerPartition 任意整数 10 设置spark将为每个分区记录错误格式的行的最大数目,超出此数目的格式错误的记录将被忽略 Write QuoteAll true,false false 指定是否将所有值括在引号中,而不是仅转义具有引号字符窜的值 Read multiline true,false false 此选项用于读取多行CSV文件,其中CSV文件中的每个逻辑行可能跨越文件本身的多行 实例说明本实例展示了如何使用notebook读取文件的多种方式。 重要与读取其他格式一样,要读取CSV文件必须首先为该特定格式创建一个DataFrameReader这里我们将格式指定为CSV; %spark spark.read.format("csv")1.hearder 选项 默认header = false %spark val path="oss://databricks-data-source/datas/input.csv" val dtDF = spark.read.format("csv") .option("mode", "FAILFAST") .load(path) dtDF.show(5)数据展示
数据展示 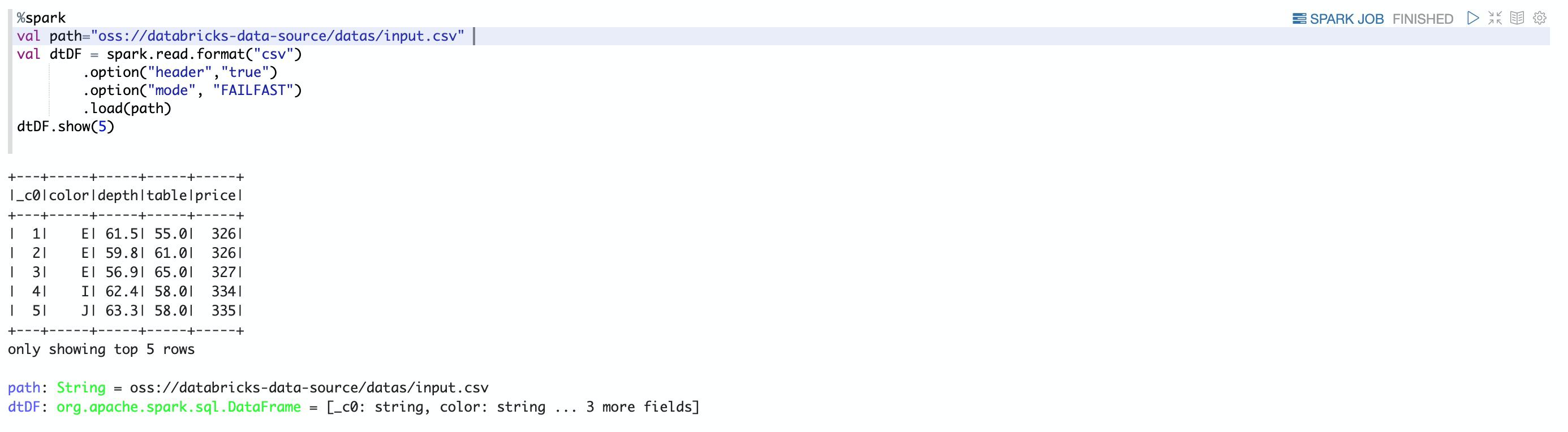 2.inferSchema选项 默认inferSchema = false %spark val path="oss://databricks-data-source/datas/input.csv" val dtDF = spark.read.format("csv") .option("header","true") .option("mode", "FAILFAST") .load(path) dtDF.show(5) dtDF.printSchema() 当inferSchema = true %spark val path="oss://databricks-data-source/datas/input.csv" val dtDF = spark.read.format("csv") .option("header","true") .option("mode", "FAILFAST") .option("inferSchema","true") .load(path) dtDF.show(5) dtDF.printSchema() 当深度类型转换不是我们希望的类型是,我们可以通过自定义Schema %spark import org.apache.spark.sql.types._ val path="oss://databricks-data-source/datas/input.csv" val schema = new StructType() .add("_c0",IntegerType,true) .add("color",StringType,true) .add("depth",DoubleType,true) .add("table",DoubleType,true) .add("price",IntegerType,true) val data_with_schema = spark.read.format("csv") .option("header", "true") .schema(schema) .load(path) data_with_schema.show(5,false) data_with_schema.printSchema() ⚠️自定义schema里面包含一个特殊的列_corrupt_record,该列在数据类型解析不正确时捕获没有正确解析的行,方便查看 %spark val path="oss://databricks-data-source/datas/input.csv" val schema = new StructType() .add("_c0",IntegerType,true) .add("color",StringType,true) .add("depth",IntegerType,true) //将字段自定义成整数型 .add("table",DoubleType,true) .add("price",IntegerType,true) .add("_corrupt_record", StringType, true) //特殊列_corrupt_record,追踪没有解析成功的列 val data_with_schema = spark.read.format("csv") .option("header", "true") .schema(schema) .load(path) data_with_schema.show(5,false) data_with_schema.printSchema() 3.mode 选项 说明mode主要有三个值,分别是PERMISSIVE(遇到解析不了,使用系统自带转换,实在不行就转换成null)、DROPMALFORMED(遇到解析不了,就放弃该记录)和FAILFAST(遇到解析不了,就报错,终止代码执行) CSV数据集 1,a,10000,11-03-2019,pune 2,b,10020,14-03-2019,pune 3,a,34567,15-03-2019,pune tyui,a,fgh-03-2019,pune 4,b,10020,14-03-2019,pune%spark import org.apache.spark.sql.types._ val path="oss://databricks-data-source/datas/dataTest.csv" val schema = StructType( List( StructField("id", DataTypes.IntegerType, false,Metadata.empty), StructField("name", DataTypes.StringType, false,Metadata.empty), StructField("salary", DataTypes.DoubleType, false,Metadata.empty), StructField("dob", DataTypes.StringType, false,Metadata.empty), StructField("loc", DataTypes.StringType, false,Metadata.empty) ) ) val dtDF = spark.read.format("csv") .schema(schema) .option("mode", "DROPMALFORMED") .load(path) dtDF.show() 下面是注解以后的结果 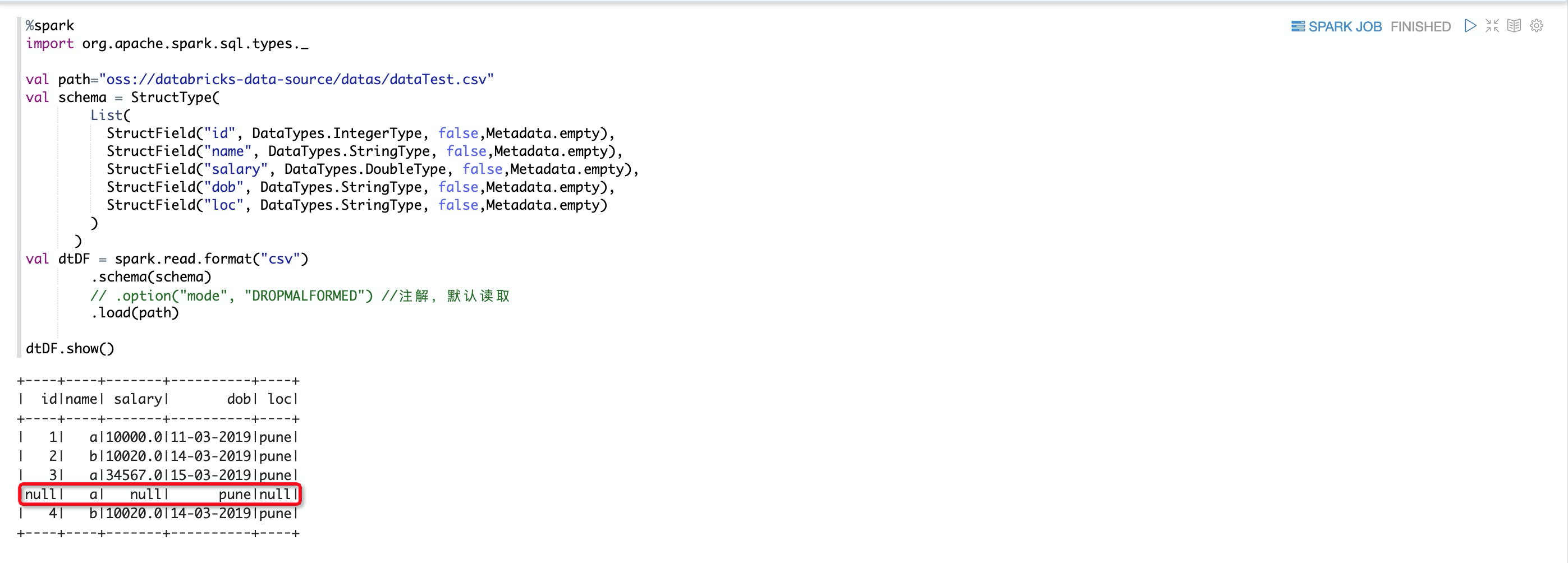 如果使用FAILFAST %spark import org.apache.spark.sql.types._ val path="oss://databricks-data-source/datas/dataTest.csv" val schema = StructType( List( StructField("id", DataTypes.IntegerType, false,Metadata.empty), StructField("name", DataTypes.StringType, false,Metadata.empty), StructField("salary", DataTypes.DoubleType, false,Metadata.empty), StructField("dob", DataTypes.StringType, false,Metadata.empty), StructField("loc", DataTypes.StringType, false,Metadata.empty) ) ) val dtDF = spark.read.format("csv") .schema(schema) .option("mode", "FAILFAST") .load(path) dtDF.show() 写CSV文件 %spark val path="oss://databricks-data-source/datas/input.csv" val dtDF = spark.read.format("csv") .option("header","true") .option("mode", "FAILFAST") .load(path) val writeDF=dtDF.withColumnRenamed("_c0","id").filter($"depth">60) writeDF.show(5) //写入CSV数据到oss writeDF.coalesce(1).write.format("csv").mode("overwrite").save("oss://databricks-data-source/datas/out")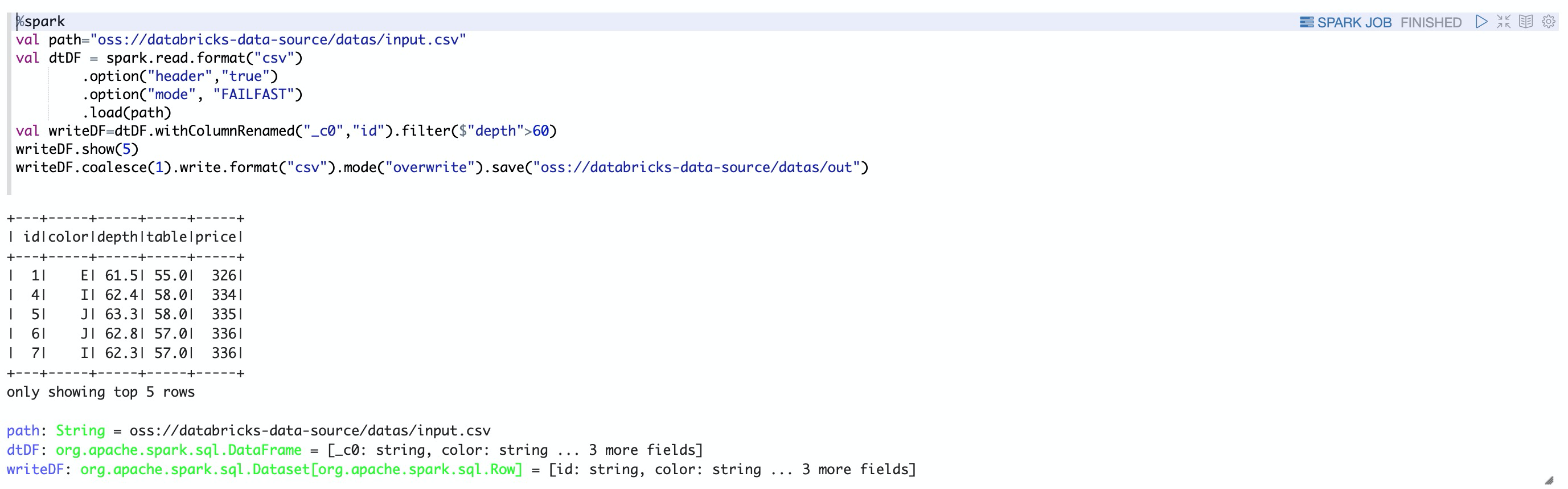
|
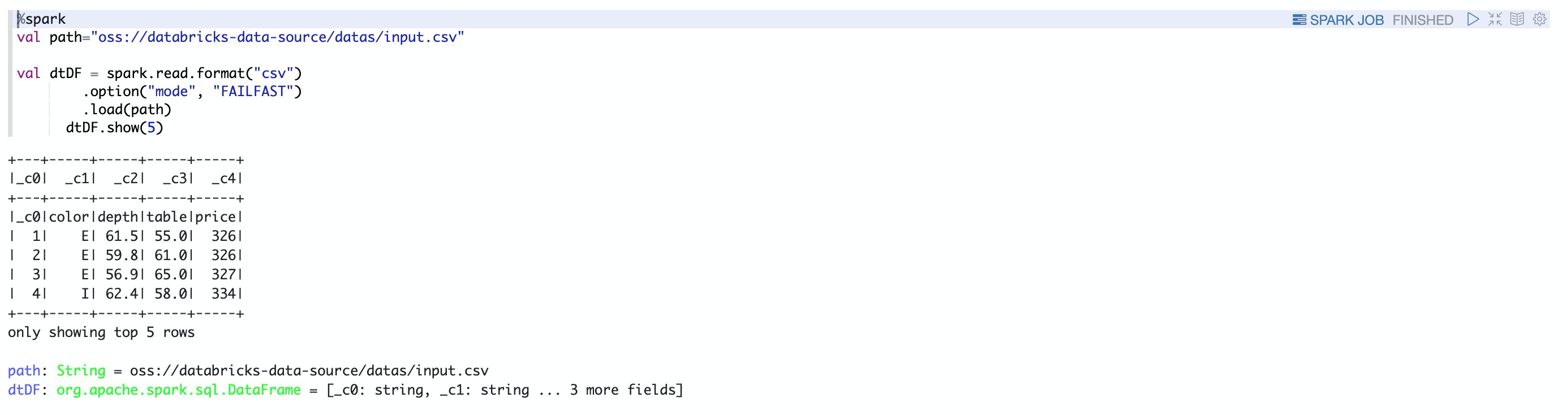 header = true
header = true【本文地址】