R语言Poisson泊松回归的拟合优度检验 – 拓端tecdat |
您所在的位置:网站首页 › 拟合度计算公式是什么 › R语言Poisson泊松回归的拟合优度检验 – 拓端tecdat |
R语言Poisson泊松回归的拟合优度检验 – 拓端tecdat
|
在数据分析中,对于定类变量和低测度的定序变量,通常不能使用均值、T检验和方差分析等方法来处理。对于不符合正态分布的定类数据或低测度定序数据,其检验方法是利用交叉表技术分行分列计算交叉点的频数,利用卡方距离实施卡方检验,基于频数和数据分布形态分析不同类别的数据是否存在显著性差异,对于定类数据的对比检验,也叫独立性检验。 低测度数据对于定类变量,其数值大小和顺序并不代表什么意义,对于定类变量和低测度的定序变量,均值和方差都不能描述变量特征,故不能通过分析其平均值、方差等参数开展数据分析。在做统计分析时,对于这类变量通常需要借助中位数、频数、百分比以及不同分布情况,实现数据描述。对于低测度数据,比较典型的研究是关于结构成分的研究,实际上是一种借助频数来分析数据分布形态,并进而发现数据分布差异性的检验。 拟合及拟合优度由于低测度数据的特点,直接进行基于均值的检验显然是不行的,于是人们借助数学模型,提出了拟合的概念。所谓拟合,就是分析现有观测变量的分布形态,检查其分布能够与某一期望分布(或标准分布)很好地吻合起来。在数学上,拟合的过程就是寻找能很好地温和当前数据序列的数学模型的过程。为了评价拟合的程度,人们提出了判定拟合有效性的机制,这就是拟合优度。拟合优度也借助检验概率的概念来评价数据拟合的质量。 目前,对于低测度数据序列的处理最常见的分析方法是卡方检验。特别是基于交叉表的卡方检验在数据分析中具有重要的地位,它们都建立在拟合概念的基础上。另外,二项分布、游程检验等单样本检验也可以看做是数据拟合的重要应用。与此同时,对定距或定序变量的分布形态判定,也是数据拟合的应用之一,在分布形态判定过程中所获得的检验概率就是该序列与标准分布形态的拟合优度。 卡方检验卡方检验的目标就是检查观测值的频数与期望频数之间的差异显著性。由于卡方检验要求便于对个案进行分类并计算频数,因此卡方检验通常基于定类数据或低测度定序数据,并基于它们分类计算个案的实际频数,然后通过实际频数与期望频数的距离,来判定实际频数是否与预期目标存在差异。 卡方距离由于卡方检验的目标是检查观测频数与期望频数之间的差异性水平,因此卡方检验的核心内容就是计算出观测值的频数与期望频数总体差距的统计量,就是卡方距离。这个距离可以通过“观测值频数与期望频数差值的平方与期望频率之比的累积和”来体现: 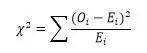
卡方值越大,表示距离越大,差异性越强。可以根据卡方值查表推导出卡方检验的概率值,然后根据概率值判定卡方检验的判断结论。 卡方检验的两种应用卡方检验有两种基本应用。其一,检验期望分布与实际观测值的差异性。其二,基于交叉表检验两个低测度变量在各自不同的因素水平上的卡方距离,从而实现两个低测度变量的关联性(独立性)检验。 面向期望分布的卡方检验对于低测度变量,如果从总体中抽取若干样本,构成k个互不相交的子集。这k个子集的观测频数应该服从一个多项分布。当k趋向于无穷时,这个分布应该接近于总体的分布规律。因此,对于变量X的总体分布,可以从观察样本在各个频段的频数入手。通过观察样本在各个频段的频数分布,可以掌握样本的分布形态。另外,对比它们与预期值的差距,可以掌握变量X是否与预期分布存在显著性差异。 对于检验观测值与期望值在频数上拟合程度的检验,也常常被称为卡方拟合优度检验。例如,现在已经统计出了2013年的招生情况,掌握了2013年学校在各个省份的招生人数。在2015年的招生工作刚刚完成,拿到了全体新生的基本信息后,现在需要分析2015年招生情况是否与2013年的各省招生情况有显著性差异。为此,需要由计算机自动计算出2015年分省招生个案数,并借助卡方公式计算出2015年的分省学生数与2013年分省学生数的卡方值,从而判定二者是否存在显著性差异。 基于K-S检验的分布形态判断就是这样一种用法。在SPSS中,通常使用K-S算法进行单样本的分布形态判断,可以对序列进行正态分布(即常规分布)、均匀分布(即相等分布)、泊松分布、指数分布等分布形态的判定。 基于交叉表的卡方检验对交叉表中的行变量和列变量之间的关系进行分析是交叉分组下频数分析的重要任务,对低测度的定序变量(或定类变量)交叉分组并计算频数后,可以分析行变量与列变量之间是否存在关系,或者说基于某个变量的不同水平,在另一个变量的不同水平上其频数是否有显著性的差异。基于这一思路,可以获取两个变量之间是否存在一定关联性,关联的紧密程度等更深层次的信息。例如,某公司统计旗下零食产品在超市不同位置的销售量,构造交叉表: 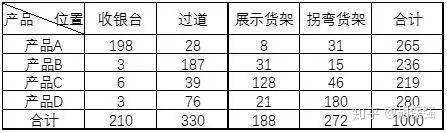
从上表来看,沿着“左上-右下”的对角线方向,数据的量比较大,表示产品的不同种类销量与展示位置之间还是有一定关联性的。 大多数交叉表中的数据不会像上表一样,能那么容易看出其中内在关系,必须借助数据分析的专业手段对交叉表中的频数进行计算,获取其卡方值和检验概率,然后以检验概率值为标准,做出检验结论。对交叉表的统计分析,卡方检验的统计量采用了Pearson卡方统计量标准,其数学定义式为: 
在对交叉表的卡方检验中,当获得了交叉表之后,可以根据卡方计算公式计算出整个交叉表的卡方值,然后依据卡方值查相应的统计表,得到此卡方值的检验概率值,进而判断两变量是否相互独立,没有任何关联。 游程检验与随机分布游程是指在变量序列当中,连续出现相同的值的次数。对于序列“111222223331123333”可以认为有6个游程,依次为“111”、“22222”、“333”、“11”、“2”和“3333”。 游程检验的思路与用途游程检验是指依据某种规则对数据序列中的个案分组,并记录每个个案的组好;然后,对数据序列按照升序排序,把得到的组号排列起来就构成一个游程序列。对于一个数据序列,如果游程个数达到一定的规模,就认为序列的分布是随机分布。游程检验的目标是检验两种样本的分布是否具有随机性,游程的价值就是判别分布规律的随机程度。 单样本变量值的随机测验中,利用游程数构造检验统计量,分析这个统计量的分布情况,从而能够反映样本所代表的总体的分布是否满足随机性。单样本变量值的随机性检验中,SPSS将利用游程构造Z统计量,并依据正态分布表给出对于的相伴概率值。如果相伴概率值大于显著性水平,则不能拒绝零假设,认为变量值的出现是随机的。 二项分布检验在现实生活中,很多变量的取值只有两种状态,被称之为二分变量或二项变量。比如,人类性别的取值是男或女,职位应聘结果为成功或失败,投掷硬币的实验结果可以是正面或者反面。凡是只有两种取值状态的变量,都被称为二值变量。对这种变量来说,如果随机变量X的取值为1的概率为p,那么X取值为0的概率为1-p。如果让上述变量出现n次并把其取值记录下来,就构成一个数据序列,这个序列所服从的分布被称为二项分布。 二项分布检验正是通过检查样本数据的形态来验证总体数据是否符合二项分布,其零假设是样本来自的总体与预设的二项分布没有显著差异。二项分布检验,对于小样本数据应该采用精确检验方法,而对大样本数据则主要采用近似检验方法。 二项分布检验的应用二项分布检验主要用于判断某种观点是否正确,通常用在基于样品的产品总体合格率检验、或对基于部分学生成绩估算出全体学生及格百分比实施判断。比如,在高考中,总体样本3百万名,在评阅了10000名考生的试卷后,可以做出初步预测:600分以上的学生占10%,那么就可以借助二项分布,检验600分以下的学生占90%的可能性有多大。若这种可能性很大,就可以认为600分以上的学生占10%,否则,则不可以做出此结论。 以产品合格率检验为例,如果需要通过抽样判断产品合格率是否达到90%,其基本思路是:可先假设产品的合格率在90%左右,然后以产品合格作为分割点,把所有样品分为两种状态,判断产品合格率在90%左右的可能性有多大。实施二项分布检验后,若检验合格率>0.05,则接受零假设,认为产品的总体合格率应在90%左右。
|
【本文地址】
今日新闻 |
推荐新闻 |