(图文详细)云计算与大数据实训作业答案(之篇二大数据系统及应用 |
您所在的位置:网站首页 › 抗的四字成语有哪些成语 › (图文详细)云计算与大数据实训作业答案(之篇二大数据系统及应用 |
(图文详细)云计算与大数据实训作业答案(之篇二大数据系统及应用
|
大数据系统及应用-HDFS实训
第1关:HDFS Java API编程 ——文件读写第2关:HDFS Java API编程——文件上传第3关:HDFS Java API编程 ——文件下载第4关:HDFS Java API编程 ——使用字符流读取数据第5关:HDFS Java API编程 ——删除文件第6关:HDFS Java API编程 ——删除文件夹第7关:HDFS Java API编程 ——自定义数据输入流
大数据系统及应用-HDFS实训
Hadoop是一个由Apache基金会所开发的分布式系统基础架构,可以在不了解分布式底层细节的情况下,开发分布式程序,以满足在低性能的集群上实现对高容错,高并发的大数据集的高速运算和存储的需要。Hadoop支持超大文件(可达PB级),能够检测和快速应对硬件故障、支持流式数据访问、同时在简化的一致性模型的基础上保证了高容错性。因而被大规模部署在分布式系统中,应用十分广泛。 实验目的 1) 理解HDFS在Hadoop体系结构中的角色; 2) 熟悉HDFS操作常用的Java API。 第1关:HDFS Java API编程 ——文件读写任务描述 利用HDFS文件系统开放的API对HDFS系统进行文件的创建和读写 相关知识 HDFS文件系统 HDFS设计成能可靠地在集群中大量机器之间存储大量的文件,它以块序列的形式存储文件。文件中除了最后一个块,其他块都有相同的大小(一般64M)。属于文件的块为了故障容错而被复制到不同节点备份(备份数量有复制因子决定)。块的大小和读写是以文件为单位进行配置的。HDFS中的文件是一次写的,并且任何时候都只有一个写操作,但是可以允许多次读。 2、通过FSDataOutputStream进行写入; FSDataOutputStream outStream = fs.create(file); //获取输出流 outStream.writeUTF("XXX");//可以写入任意字符 outStream.close();//记得关闭输出流3、通过FSDataInputStream将文件内容输出。 FSDataInputStream inStream = fs.open(file); //获取输入流 String data = inStream.readUTF(); //读取文件
测试说明 本关的评测预设文件时/user/hadoop/myfile所以创建文档的路径必须设置为/user/hadoop/myfile才能评测,否则会评测失败。 注:由于启动服务、编译等耗时,以及hdfs文件操作过程资源消耗较大且时间较长,因而评测时间较长,在40s左右. 实训使用软件环境为:JavaJDK1.8,hadoop2.7.4。 开始你的任务吧,gook luck! 代码如下: import java.io.*; import java.sql.Date; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FSDataInputStream; import org.apache.hadoop.fs.FSDataOutputStream; import org.apache.hadoop.fs.FileStatus; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; public class hdfs { public static void main(String[] args) throws IOException { Configuration conf = new Configuration();//configuration类实现hadoop各模块之间值的传递 FileSystem fs = FileSystem.get(conf); //获取文件系统 Path file = new Path("/user/hadoop/myfile"); //创建文件 FSDataOutputStream outStream = fs.create(file); //获取输出流 outStream.writeUTF("https://www.educoder.net");//可以写入任意字符 outStream.close();//记得关闭输出流 FSDataInputStream inStream = fs.open(file); //获取输入流 String data = inStream.readUTF(); //读取文件 } } 第2关:HDFS Java API编程——文件上传任务描述 本关任务:向HDFS中上传任意文本文件。 相关知识 判断HDFS中文件是否存在 1. FileSystem fs = FileSystem.get(conf);//获取对象 2. fs.exists(new Path(path); //判断该路径的文件是否存在,是则返回true文件拷贝 关键代码如下: 1. /* fs.copyFromLocalFile 第一个参数表示是否删除源文件,第二个参数表示是否覆盖 */ 2. fs.copyFromLocalFile(false, true, localPath, remotePath);向HDFS文件追加数据 向HDFS文件中追加信息,关键代码如下: FileSystem fs = FileSystem.get(conf); Path remotePath = new Path(remoteFilePath); /* 创建一个文件读入流 */ FileInputStream in = new FileInputStream(localFilePath); /* 创建一个文件输出流,输出的内容将追加到文件末尾 */ FSDataOutputStream out = fs.append(remotePath); /* 读写文件内容 */ byte[] data = new byte[1024]; int read = -1; while ( (read = in.read(data)) > 0 ) { out.write(data, 0, read); }编程要求 请在右侧start…end处填充代码实现相关功能,完成向HDFS中上传文本文件,如果指定的文件在HDFS中已经存在,由用户指定是追加到原有文件末尾还是覆盖原有的文件。 测试说明 文中要上传的文件路径和目标文件路径已经设置好,请不要修改,否则无法评测,因为Hadoop环境非常消耗资源,所以评测时间较长,需要40秒左右。 开始你的任务吧,good luck! 代码如下: import java.io.*; import java.sql.Date; import java.util.Scanner; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FSDataInputStream; import org.apache.hadoop.fs.FSDataOutputStream; import org.apache.hadoop.fs.FileStatus; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; public class hdfs { /** * 判断路径是否存在 */ public static boolean test(Configuration conf, String path) throws IOException { /*****start*****/ //请在此处编写判断文件是否存在的代码 try(FileSystem fs = FileSystem.get(conf)){ return fs.exists(new Path(path)); } catch (IOException e){ e.printStackTrace(); return false; } /*****end*****/ } /** * 复制文件到指定路径 * 若路径已存在,则进行覆盖 */ public static void copyFromLocalFile(Configuration conf, String localFilePath, String remoteFilePath) throws IOException { /*****start*****/ //请在此处编写复制文件到指定路径的代码 Path localPath = new Path(localFilePath); Path remotePath = new Path(remoteFilePath); try (FileSystem fs = FileSystem.get(conf)) { fs.copyFromLocalFile(false, true, localPath, remotePath); } catch (IOException e) { e.printStackTrace(); } /*****end*****/ } /** * 追加文件内容 */ public static void appendToFile(Configuration conf, String localFilePath, String remoteFilePath) throws IOException { /*****start*****/ //请在此处编写追加文件内容的代码 Path remotePath = new Path(remoteFilePath); try (FileSystem fs = FileSystem.get(conf); FileInputStream in = new FileInputStream(localFilePath);) { FSDataOutputStream out = fs.append(remotePath); byte[] data = new byte[1024]; int read = -1; while ((read = in.read(data)) > 0) { out.write(data, 0, read); } out.close(); } catch (IOException e) { e.printStackTrace(); } /*****end*****/ } /** * 主函数 */ public static void main(String[] args)throws IOException { Configuration conf = new Configuration(); createHDFSFile(conf); String localFilePath = "./file/text.txt"; // 本地路径 String remoteFilePath = "/user/hadoop/text.txt"; // HDFS路径 String choice = ""; try { /* 判断文件是否存在 */ Boolean fileExists = false; if (hdfs.test(conf, remoteFilePath)) { fileExists = true; System.out.println(remoteFilePath + " 已存在."); choice = "append"; //若文件存在则追加到文件末尾 } else { System.out.println(remoteFilePath + " 不存在."); choice = "overwrite"; //覆盖 } /*****start*****/ //请在此处编写文件不存在则上传 文件choice等于overwrite则覆盖 choice 等于append 则追加的逻辑 if (!fileExists) { // 文件不存在,则上传 hdfs.copyFromLocalFile(conf, localFilePath, remoteFilePath); System.out.println(localFilePath + " 已上传至 " + remoteFilePath); } else if (choice.equals("overwrite")) { // 选择覆盖 hdfs.copyFromLocalFile(conf, localFilePath, remoteFilePath); System.out.println(localFilePath + " 已覆盖 " + remoteFilePath); } else if (choice.equals("append")) { // 选择追加 hdfs.appendToFile(conf, localFilePath, remoteFilePath); System.out.println(localFilePath + " 已追加至 " + remoteFilePath); } /*****end*****/ } catch (Exception e) { e.printStackTrace(); } } //创建HDFS文件 public static void createHDFSFile(Configuration conf)throws IOException{ FileSystem fs = FileSystem.get(conf); //获取文件系统 Path file = new Path("/user/hadoop/text.txt"); //创建文件 FSDataOutputStream outStream = fs.create(file); //获取输出流 outStream.writeUTF("hello"); outStream.close(); fs.close(); } } 第3关:HDFS Java API编程 ——文件下载任务描述 从HDFS中下载指定文件。 相关知识 将文件从HDFS拷贝至本地 将文件拷贝至本地只需要调用FileSystem中的一个方法即可,如下: FileSystem fs = FileSystem.get(conf); Path localPath = new Path(localFilePath); fs.copyToLocalFile(remotePath, localPath);编程要求 填充右侧代码片段,完成从HDFS中下载文件的功能。 测试说明 文中要上传的文件路径和目标文件路径已经设置好,请不要修改,否则无法评测,因为Hadoop环境非常消耗资源,所以评测时间较长,需要40秒左右。 开始你的任务吧,祝你成功! 代码如下: import java.io.*; import java.sql.Date; import java.util.Scanner; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FSDataInputStream; import org.apache.hadoop.fs.FSDataOutputStream; import org.apache.hadoop.fs.FileStatus; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; public class hdfs { /** * 下载文件到本地 * 判断本地路径是否已存在,若已存在,则自动进行重命名 */ public static void copyToLocal(Configuration conf, String remoteFilePath, String localFilePath) throws IOException { FileSystem fs = FileSystem.get(conf); Path remotePath = new Path(remoteFilePath); File f = new File(localFilePath); /*****start*****/ /*在此添加判断文件是否存在的代码,如果文件名存在,自动重命名(在文件名后面加上 _0, _1 ...) */ if (f.exists()) { System.out.println(localFilePath + " 已存在."); Integer i = 0; while ( true) { f = new File( localFilePath + "_" + i.toString() ); if (!f.exists() ) { localFilePath = localFilePath + "_" + i.toString() ; break; } } System.out.println("将重新命名为: " + localFilePath); } /*****end*****/ /*****start*****/ // 在此添加将文件下载到本地的代码 Path localPath = new Path(localFilePath); fs.copyToLocalFile(remotePath, localPath); /*****end*****/ fs.close(); } /** * 主函数 */ public static void main(String[] args)throws IOException { Configuration conf = new Configuration(); createHDFSFile(conf); String localFilePath = "/tmp/output/text.txt"; // 本地路径 String remoteFilePath = "/user/hadoop/text.txt"; // HDFS路径 try { //调用方法下载文件至本地 hdfs.copyToLocal(conf, remoteFilePath, localFilePath); System.out.println("下载完成"); } catch (Exception e) { e.printStackTrace(); } } //创建HDFS文件 public static void createHDFSFile(Configuration conf)throws IOException{ FileSystem fs = FileSystem.get(conf); //获取文件系统 Path file = new Path("/user/hadoop/text.txt"); //创建文件 FSDataOutputStream outStream = fs.create(file); //获取输出流 outStream.writeUTF("hello hadoop HDFS www.educoder.net"); outStream.close(); fs.close(); } } 第4关:HDFS Java API编程 ——使用字符流读取数据任务描述 本关任务:使用字符流读取HDFS文件数据并输出到终端。 相关知识 使用字符流读取数据 使用字符流读取数据简单来说分为三个步骤: 通过Configuration对象获取FileSystem对象;通过fs获取FSDataInputStream对象;通过字符流循环读取文件中数据并输出。关键代码: Configuration conf = new Configuration(); FileSystem fs = FileSystem.get(conf); Path remotePath = new Path(remoteFilePath); FSDataInputStream in = fs.open(remotePath); BufferedReader d = new BufferedReader(new InputStreamReader(in)); StringBuffer buffer = new StringBuffer(); String line = null; while ( (line = d.readLine()) != null ) { buffer.append(line); }编程要求 填充右侧代码片段,完成将HDFS中指定文件输出到指定文件中。 测试说明 文中要上传的文件路径和目标文件路径已经设置好,请不要修改,否则无法评测,因为Hadoop环境非常消耗资源,所以评测时间较长,需要40秒左右。 开始你的任务吧! 代码如下: import java.io.*; import java.sql.Date; import java.util.Scanner; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FSDataInputStream; import org.apache.hadoop.fs.FSDataOutputStream; import org.apache.hadoop.fs.FileStatus; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; public class hdfs { /** * 读取文件内容 */ public static void cat(Configuration conf, String remoteFilePath) throws IOException { /*****start*****/ //1.读取文件中的数据 Path remotePath = new Path(remoteFilePath); FileSystem fs = FileSystem.get(conf); FSDataInputStream in = fs.open(remotePath); BufferedReader d = new BufferedReader(new InputStreamReader(in)); String line = null; StringBuffer buffer = new StringBuffer(); while ((line = d.readLine()) != null) { buffer.append(line); } String res = buffer.toString(); //2.将读取到的数据输出到 /tmp/output/text.txt 文件中 提示:可以使用FileWriter FileWriter f1=new FileWriter("/tmp/output/text.txt"); f1.write(res); f1.close(); /*****end*****/ } /** * 主函数 */ public static void main(String[] args)throws IOException { Configuration conf = new Configuration(); createHDFSFile(conf); String remoteFilePath = "/user/hadoop/text.txt"; // HDFS路径 try { System.out.println("读取文件: " + remoteFilePath); hdfs.cat(conf, remoteFilePath); System.out.println("\n读取完成"); } catch (Exception e) { e.printStackTrace(); } } //创建HDFS文件 public static void createHDFSFile(Configuration conf)throws IOException{ FileSystem fs = FileSystem.get(conf); //获取文件系统 Path file = new Path("/user/hadoop/text.txt"); //创建文件 FSDataOutputStream outStream = fs.create(file); //获取输出流 outStream.writeUTF("hello hadoop HDFS step4 www.educoder.net"); outStream.close(); fs.close(); } } 第5关:HDFS Java API编程 ——删除文件任务描述 删除HDFS中指定的文件。 相关知识 删除HDSF中的文件和目录 删除HDFS中指定文件需要使用HDFS Java API中FileSystem的delete()方法。 如下: FileSystem fs = FileSystem.get(conf); Path remotePath = new Path(remoteFilePath); boolean result = fs.delete(remotePath, false);public boolean delete(Path f, Boolean recursive)永久性删除指定的文件或目录,如果f是一个空目录或者文件,那么recursive的值就会被忽略。只有recursive=true时,一个非空目录及其内容才会被删除(即递归删除所有文件)。 编程要求 请在右侧代码区填充代码,删除HDFS中/user/hadoop/text.txt文件。 测试说明 因为Hadoop环境非常消耗资源,所以评测时间较长,需要40秒左右。 验货啦,验货啦,开始你的任务吧! 代码如下: import java.io.*; import java.sql.Date; import java.util.Scanner; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FSDataInputStream; import org.apache.hadoop.fs.FSDataOutputStream; import org.apache.hadoop.fs.FileStatus; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; public class hdfs { /** * 删除文件 */ public static boolean rm(Configuration conf, String remoteFilePath) throws IOException { /*****start*****/ //请在此添加删除文件的代码 FileSystem fs = FileSystem.get(conf); Path remotePath = new Path(remoteFilePath); boolean result = fs.delete(remotePath,false); return true ; /*****end*****/ } /** * 主函数 */ public static void main(String[] args) { Configuration conf = new Configuration(); String remoteFilePath = "/user/hadoop/text.txt"; // HDFS文件 try { if (rm(conf, remoteFilePath) ) { System.out.println("文件删除: " + remoteFilePath); } else { System.out.println("操作失败(文件不存在或删除失败)"); } } catch (Exception e) { e.printStackTrace(); } } } 第6关:HDFS Java API编程 ——删除文件夹任务描述 删除HDFS中指定的目录。 相关知识 验证目录下是否存在文件 使用到的方法public RemoteIterator listFiles(Path f, Boolean recursive) 该方法的作用是:列出给定路径中文件的状态和块位置。如果f是一个目录,recursive是false,则返回目录中的文件;如果recursive是true,则在根目录中返回文件。如果路径是文件,则返回文件的状态和块位置。 例如: FileSystem fs = FileSystem.get(conf); Path dirPath = new Path(remoteDir); RemoteIterator remoteIterator = fs.listFiles(dirPath, true); //remoteIterator.hasNext() 会返回一个布尔类型的值,true即代表文件夹为空,false即代表非空。删除HDSF中的文件和目录 删除HDFS中指定文件需要使用HDFS Java API中FileSystem的delete()方法。 如下: FileSystem fs = FileSystem.get(conf); Path remotePath = new Path(remoteFilePath); boolean result = fs.delete(remotePath, false);public boolean delete(Path f, Boolean recursive)永久性删除指定的文件或目录,如果f是一个空目录或者文件,那么recursive的值就会被忽略。只有recursive=true时,一个非空目录及其内容才会被删除(即递归删除所有文件)。 编程要求 请在右侧代码区填充代码,删除HDFS中/user/hadoop/tmp目录和/user/hadoop/dir目录,删除前,需要判断两个目录是否为空,若不为空则不删除,否则删除。 测试说明 因为Hadoop环境非常消耗资源,所以评测时间较长,需要40秒左右。 验货啦,验货啦,开始你的任务吧! 代码如下: import java.io.*; import java.sql.Date; import java.util.Scanner; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.*; public class hdfs { /** * 判断目录是否为空 * true: 空,false: 非空 */ public static boolean isDirEmpty(Configuration conf, String remoteDir) throws IOException { FileSystem fs = FileSystem.get(conf); Path dirPath = new Path(remoteDir); RemoteIterator remoteIterator = fs.listFiles(dirPath, true); return !remoteIterator.hasNext(); } /** * 删除目录 */ public static boolean rmDir(Configuration conf, String remoteDir, boolean recursive) throws IOException { FileSystem fs = FileSystem.get(conf); Path dirPath = new Path(remoteDir); /* 第二个参数表示是否递归删除所有文件 */ boolean result = fs.delete(dirPath, recursive); fs.close(); return result; } /** * 主函数 */ public static void main(String[] args) { Configuration conf = new Configuration(); String remoteDir = "/user/hadoop/dir/"; // HDFS目录 String remoteDir1 = "/user/hadoop/tmp/"; // HDFS目录 Boolean forceDelete = false; // 是否强制删除 try { if ( !isDirEmpty(conf, remoteDir) && !forceDelete ) { System.out.println("目录不为空,不删除"); } else { if ( rmDir(conf, remoteDir, forceDelete) ) { System.out.println("目录已删除: " + remoteDir); } else { System.out.println("操作失败"); } } if ( !isDirEmpty(conf, remoteDir1) && !forceDelete ) { System.out.println("目录不为空,不删除"); } else { if ( rmDir(conf, remoteDir1, forceDelete) ) { System.out.println("目录已删除: " + remoteDir1); } else { System.out.println("操作失败"); } } } catch (Exception e) { e.printStackTrace(); } } } 第7关:HDFS Java API编程 ——自定义数据输入流任务描述 本关任务:实现一个自定义的数据输入流。 相关知识 BufferedReader相关方法 public int read(char[] cbuf,int off,int len)throws IOException此方法实现 Reader类相应 read 方法的常规协定。另一个便捷之处在于,它将通过重复地调用底层流的 read 方法,尝试读取尽可能多的字符。这种迭代的 read 会一直继续下去,直到满足以下条件之一: 已经读取了指定的字符数, 底层流的 read 方法返回 -1,指示文件末尾(end-of-file),或者 底层流的 ready 方法返回 false,指示将阻塞后续的输入请求。 如果第一次对底层流调用 read 返回 -1(指示文件末尾),则此方法返回 -1,否则此方法返回实际读取的字符数。 编程要求 在右侧编辑器中填充代码,实现按行读取HDFS中指定文件的方法readLine(),如果读到文件末尾,则返回空,否则返回文件一行的文本,即实现和BufferedReader类的readLine()方法类似的效果。 测试说明 因为Hadoop环境非常消耗资源,所以评测时间较长,需要40秒左右。 开始你的任务吧! import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FSDataInputStream; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import java.io.*; public class MyFSDataInputStream extends FSDataInputStream { public MyFSDataInputStream(InputStream in) { super(in); } /** * 实现按行读取 * 每次读入一个字符,遇到"\n"结束,返回一行内容 */ public static String readline(BufferedReader br) throws IOException { char[] data = new char[1024]; int read = -1; int off = 0; // 循环执行时,br 每次会从上一次读取结束的位置继续读取,因此该函数里,off 每次都从0开始 while ( (read = br.read(data, off, 1)) != -1 ) { if (String.valueOf(data[off]).equals("\n") ) { off += 1; return String.valueOf(data, 0, read); } off += 1; return String.valueOf(data, 0, read); } return null; } /** * 读取文件内容 */ public static void cat(Configuration conf, String remoteFilePath) throws IOException { FileSystem fs = FileSystem.get(conf); Path remotePath = new Path(remoteFilePath); FSDataInputStream in = fs.open(remotePath); BufferedReader br = new BufferedReader(new InputStreamReader(in)); FileWriter f = new FileWriter("/tmp/output/text.txt"); String line = null; while ( (line = MyFSDataInputStream.readline(br)) != null ) { f.write(line); } f.close(); br.close(); in.close(); fs.close(); } /** * 主函数 */ public static void main(String[] args) { Configuration conf = new Configuration(); String remoteFilePath = "/user/hadoop/text.txt"; // HDFS路径 try { MyFSDataInputStream.cat(conf, remoteFilePath); } catch (Exception e) { e.printStackTrace(); } } } |
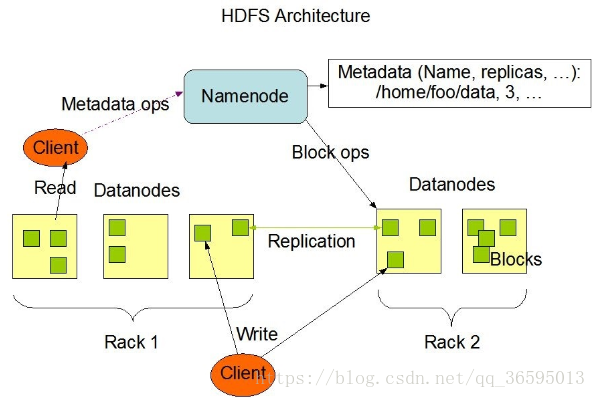 HDFS文件创建和读写 HDFS文件创建和操作可分为三个步骤: 1、获取FileSystem对象;
HDFS文件创建和读写 HDFS文件创建和操作可分为三个步骤: 1、获取FileSystem对象;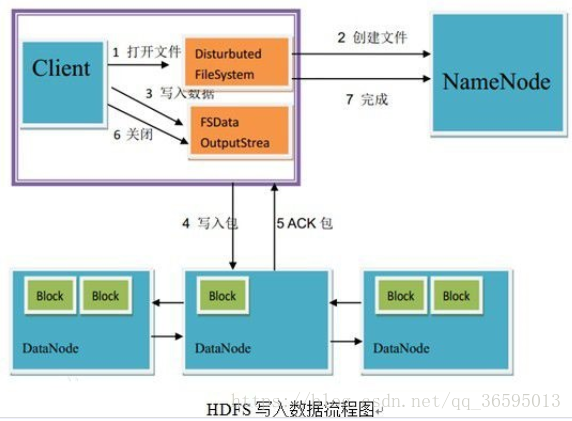 编程要求 在右侧编辑器中补全代码,完成本关任务,具体要求如下:
编程要求 在右侧编辑器中补全代码,完成本关任务,具体要求如下:【本文地址】
今日新闻 |
推荐新闻 |