今日头条爬虫实战 |
您所在的位置:网站首页 › 打开“今日头条”阅读全文热门推荐 › 今日头条爬虫实战 |
今日头条爬虫实战
|
今日头条爬虫实战
文章目录
今日头条爬虫实战前言一、怎么获取request url二、爬虫测试三、不间断爬虫
前言
本博客主要记录如何使用python爬虫抓取今日头条上面的新闻链接,然后按照新闻链接抓取新闻的文本信息,以及新闻的热度信息,即评论转发点赞的数量。 一、怎么获取request url首先打开今日头条网站,https://www.toutiao.com/ch/news_hot/,注意要选择左边的热点选项,而不是推荐选项,即最后网址的后缀应该是news_hot 这时候其实我们已经可以爬取了,今日头条的json文件是不断更新的,我们先尝试用最简单的request来爬取data里面的文件。 我们先获取User-agent 和 cookies 从刚才打开的XHR文件中的headers中可以找到: 如下图所示 输出是我们刚才看到的data文件里面的新闻的json文件: 这样就可以获得一个时间段头条热点里面的12条新闻的一些参数,我们可以建立一些列表来将其保存下来 至于如何不间断爬取更多的新闻我们需要解析request url是怎么生成的,参考下表,表是去年的,现在的url组成可能发生了变化,但是只要我们能找到request url的组成方式,即可以不断的爬取头条网站加载的json文件,挖掘出新闻信息,因为我也很久没弄这个了,先把去年的经验写下来给大家参考,然后具体的细节以及今年头条更改了反爬虫机制,所以需要大家在这一块稍微付出一点努力,然后就可以实现了,爬虫其实很简单,上面那个简单的request便是,大家可以先简单尝试,然后在继续进展后面的部分。 对比参数解释: 继续上文参数,python获取as和cp值: 至于这两个值,在去年爬虫的时候是需要的,而且可以在csdn中搜到相关的博客找到怎么得到as和cp值,至于selenium跟splash的方法今年开始都失效了,头条升级了反爬措施,针对性的ban掉了大部分的webdriver,常用的几个都不行了,现在正面硬缸sig参数似乎也不行。但是既然我们可以用request方法访问到json内部的数据,(上述简单测试于20201210),所以应该是可以刚出url的,相信自己奥利给!具体细节可以参考博文破解头条url参数 去年我们是随便找的一个代码: def get_as_cp(): # 该函数主要是为了获取as和cp参数,程序参考今日头条中的加密js文件:home_4abea46.js zz = {} now = round(time.time()) print(now) # 获取当前计算机时间 e = hex(int(now)).upper()[2:] #hex()转换一个整数对象为16进制的字符串表示 print('e:', e) a = hashlib.md5() #hashlib.md5().hexdigest()创建hash对象并返回16进制结果 print('a:', a) a.update(str(int(now)).encode('utf-8')) i = a.hexdigest().upper() print('i:', i) if len(e)!=8: zz = {'as':'479BB4B7254C150', 'cp':'7E0AC8874BB0985'} return zz n = i[:5] a = i[-5:] r = '' s = '' for i in range(5): s= s+n[i]+e[i] for j in range(5): r = r+e[j+3]+a[j] zz ={ 'as':'A1'+s+e[-3:], 'cp':e[0:3]+r+'E1' } print('zz:', zz) return zz这样完整的链接就构成了,另外提一点就是:_signature参数去掉也是可以获取到json数据的,因此这样请求的链接就完成了;下面附上完整代码: 这份代码其实是具备参考价值的,只要可以找到今年头条url的相关参数,就可以继续进展下去 其中只要能摸索出目前今日头条的url组成,基本任务就成功了,加油! import requests import json from openpyxl import Workbook import time import hashlib import os import datetime #可能不一样 start_url = 'https://www.toutiao.com/api/pc/feed/?min_behot_time=0&category=news_hot&utm_source=toutiao&widen=1&max_behot_time=' url = 'https://www.toutiao.com' headers={ 'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36' } cookies = {''} # 此处cookies可从浏览器中查找,为了避免被头条禁止爬虫 max_behot_time = '0' # 链接参数 title = [] # 存储新闻标题 source_url = [] # 存储新闻的链接 s_url = [] # 存储新闻的完整链接 source = [] # 存储发布新闻的公众号 media_url = {} # 存储公众号的完整链接 def get_as_cp(): # 该函数主要是为了获取as和cp参数,程序参考今日头条中的加密js文件:home_4abea46.js zz = {} now = round(time.time()) print(now) # 获取当前计算机时间 e = hex(int(now)).upper()[2:] #hex()转换一个整数对象为16进制的字符串表示 print('e:', e) a = hashlib.md5() #hashlib.md5().hexdigest()创建hash对象并返回16进制结果 print('a:', a) a.update(str(int(now)).encode('utf-8')) i = a.hexdigest().upper() print('i:', i) if len(e)!=8: zz = {'as':'479BB4B7254C150', 'cp':'7E0AC8874BB0985'} return zz n = i[:5] a = i[-5:] r = '' s = '' for i in range(5): s= s+n[i]+e[i] for j in range(5): r = r+e[j+3]+a[j] zz ={ 'as':'A1'+s+e[-3:], 'cp':e[0:3]+r+'E1' } print('zz:', zz) return zz def getdata(url, headers, cookies): # 解析网页函数 r = requests.get(url, headers=headers, cookies=cookies) print(url) data = json.loads(r.text) return data def savedata(title, s_url, source, media_url): # 存储数据到文件 # 存储数据到xlxs文件 wb = Workbook() if not os.path.isdir(os.getcwd()+'/result'): # 判断文件夹是否存在 os.makedirs(os.getcwd()+'/result') # 新建存储文件夹 filename = os.getcwd()+'/result/result-'+datetime.datetime.now().strftime('%Y-%m-%d-%H-%m')+'.xlsx' # 新建存储结果的excel文件 ws = wb.active ws.title = 'data' # 更改工作表的标题 ws['A1'] = '标题' # 对表格加入标题 ws['B1'] = '新闻链接' ws['C1'] = '头条号' ws['D1'] = '头条号链接' for row in range(2, len(title)+2): # 将数据写入表格 _= ws.cell(column=1, row=row, value=title[row-2]) _= ws.cell(column=2, row=row, value=s_url[row-2]) _= ws.cell(column=3, row=row, value=source[row-2]) _= ws.cell(column=4, row=row, value=media_url[source[row-2]]) wb.save(filename=filename) # 保存文件 def main(max_behot_time, title, source_url, s_url, source, media_url): # 主函数 for i in range(3): # 此处的数字类似于你刷新新闻的次数,正常情况下刷新一次会出现10条新闻,但夜存在少于10条的情况;所以最后的结果并不一定是10的倍数 ##-------------------------------------------- #这一部分就是url的组成部分肯定和今年不一样了,然后获取到的json文件的处理后面基本不难,就是分离出相应的参数 ascp = get_as_cp() # 获取as和cp参数的函数 demo = getdata(start_url+max_behot_time+'&max_behot_time_tmp='+max_behot_time+'&tadrequire=true&as='+ascp['as']+'&cp='+ascp['cp'], headers, cookies) ##------------------------------------------ print(demo) # time.sleep(1) for j in range(len(demo['data'])): # print(demo['data'][j]['title']) if demo['data'][j]['title'] not in title: title.append(demo['data'][j]['title']) # 获取新闻标题 source_url.append(demo['data'][j]['source_url']) # 获取新闻链接 source.append(demo['data'][j]['source']) # 获取发布新闻的公众号 if demo['data'][j]['source'] not in media_url: media_url[demo['data'][j]['source']] = url+demo['data'][j]['media_url'] # 获取公众号链接 print(max_behot_time) max_behot_time = str(demo['next']['max_behot_time']) # 获取下一个链接的max_behot_time参数的值 for index in range(len(title)): print('标题:', title[index]) if 'https' not in source_url[index]: s_url.append(url+source_url[index]) print('新闻链接:', url+source_url[index]) else: print('新闻链接:', source_url[index]) s_url.append(source_url[index]) # print('源链接:', url+source_url[index]) print('头条号:', source[index]) print(len(title)) # 获取的新闻数量 if __name__ == '__main__': main(max_behot_time, title, source_url, s_url, source, media_url) savedata(title, s_url, source, media_url) |
 然后在当前页面按下ctrl+shift+i,进入浏览器开发者模式,在右上角选择network,如下:
然后在当前页面按下ctrl+shift+i,进入浏览器开发者模式,在右上角选择network,如下:  找到以下XHR文件,即中间含有category=news_hot,并且在URL中前缀是https://www.toutiao.com/api/pc/feed/的XHR文件。
找到以下XHR文件,即中间含有category=news_hot,并且在URL中前缀是https://www.toutiao.com/api/pc/feed/的XHR文件。 验证,点开preview可以看到所有新闻存储的data是以json形式存储,如下:
验证,点开preview可以看到所有新闻存储的data是以json形式存储,如下:  查看每一个新闻的内容:
查看每一个新闻的内容:  这里面有很多参数,有media以及image的具体参数,新闻的title以及abstract,还有新闻源的url等等,因此我们可以得到新闻的各个参数,方便以后爬取更多的东西。
这里面有很多参数,有media以及image的具体参数,新闻的title以及abstract,还有新闻源的url等等,因此我们可以得到新闻的各个参数,方便以后爬取更多的东西。 获取完毕后使用最简单的requests来爬: 测试时间是2020年12月10号
获取完毕后使用最简单的requests来爬: 测试时间是2020年12月10号
 其中max_behot_time在获取的json数据中获得,具体数据见如下截图:
其中max_behot_time在获取的json数据中获得,具体数据见如下截图: 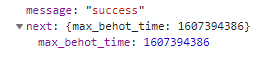 至此我们只是获得了爬虫的start url,在后续爬虫的时候需要按照上述参数表来获得新闻的url,从而爬取到新闻。
至此我们只是获得了爬虫的start url,在后续爬虫的时候需要按照上述参数表来获得新闻的url,从而爬取到新闻。【本文地址】
今日新闻 |
推荐新闻 |