为什么你的显卡利用率总是0%? |
您所在的位置:网站首页 › 手机gpu为什么一直为0 › 为什么你的显卡利用率总是0%? |
为什么你的显卡利用率总是0%?
|
作者 | 派派星 编辑 | CVHub 点击下方卡片,关注“自动驾驶之心”公众号 ADAS巨卷干货,即可获取 点击进入→自动驾驶之心【全栈算法】技术交流群 为啥GPU利用率总是这么低上回说到,如何榨干GPU的显存,使得我们的模型成功跑起来了。但是,又一个问题来了,GPU的利用率总是一会99%,一会10%,就不能一直99%榨干算力?导致算力不能够完全利用的原因是数据处理的速度没有跟上网络的训练速度。因此,我们抓手在于提高数据的读取、预处理速度。 定位问题首先,我们得先判断到底是不是数据读取、预处理阶段是整个pipeline的瓶颈,不然岂不是优化了个寂寞。 pycharm run/profile 分析瓶颈通过pycharm的run/profile xxx,我们可以看到程序执行的调用图,并且可以显示每个步骤的耗时以及其占比。通过这个工具,我们可以分析在整套训练代码中时间的瓶颈,因此也能够更加准确的定位程序运行慢的症结所在。下图为profile收集一个epoch结果之后所产生的调用图。 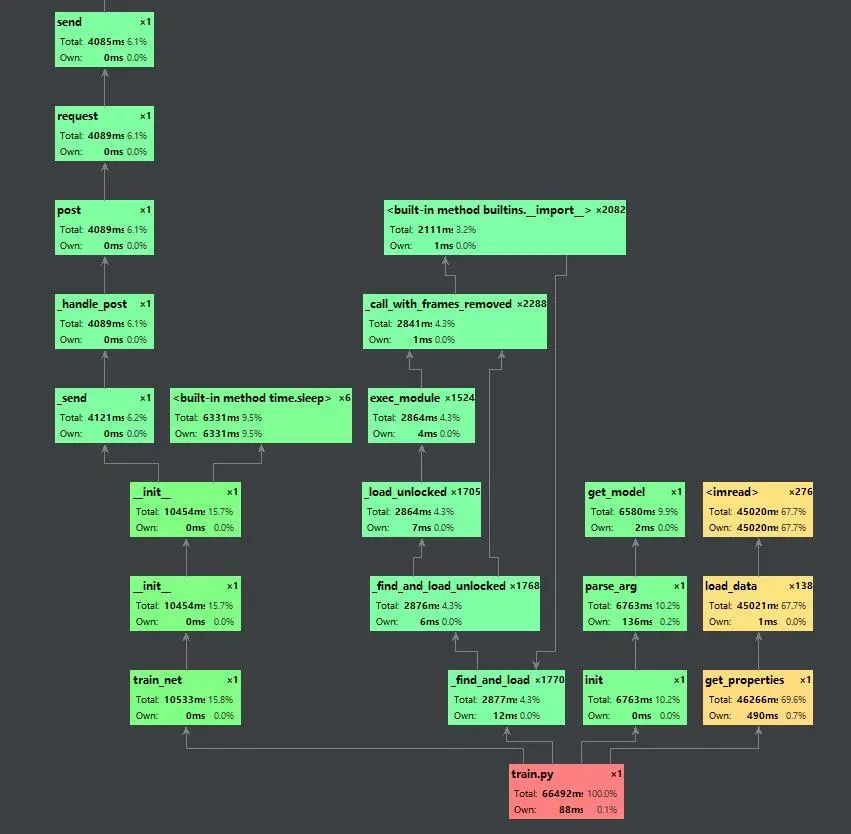 profile生成的程序调用链
profile生成的程序调用链
我们可以看到,读取数据的这部分为黄色,说明数据读取部分是整个训练pipeline的瓶颈,因此我们便可以针对性的优化。 提高数据读取速度数据读取速度慢主要是两个方面的问题:1.数据在机械硬盘中不是连续存储的,因此多个小文件的读取会浪费很多时间在寻道上;2.机械硬盘的物理特性决定其读取速度的上限。 打包数据https://github.com/Lyken17/Efficient-PyTorch#data-loader 假如我们训练的图片都是比较小,但是数量比较多的情况下,我们可以采取将数据打包成一个大的文件,比如hdf5/pth等格式。这种方式主要是降低了机械硬盘的寻道时间还有OS开启/关闭文件描述符的时间。实现的方法可以参考上述repo。 把数据放到内存上相比于机械硬盘来说,内存的速度可是快了几个量级,基本上可以说读取无延迟。因此,如果内存够大的话,的确可以先把数据全部都挂载在内存上,然后训练的时候直接从内存读取。 sudo mount tmpfs /path/to/your/data -t tmpfs -o size=30Gmount用于挂载Linux系统外的文件,tmpfs即temporary file system。许多软件为了提高一些常用的数据的读取速度,会把这些数据长期驻留在内存中以保持一个较快读写速度。后面的路径则是指明需要挂载对数据的路径,-o则是tmpfs动态大小的上限。需要注意的是,由于虚拟内存的存在(在linux为swap空间),数据并不一定都会放在物理内存中。因此我们挂载的数据也可能会因为太久没有使用而被置换到机械硬盘中。并且,由于再逻辑上这些数据是存储在内存中,因此断电之后这些数据都会会清空。 加钱都2021年了,现在SATA接口的SSD价格早已跌破0.5元1G了,建议可以换个大容量的SSD,提高工作效率。手头比较宽松的小伙伴/实验室也可以考虑一下NVMe协议的固态,速度直接起飞。 提高数据读取/预处理速度 选择opencv而不是PIL读取数据https://www.kaggle.com/yukia18/opencv-vs-pil-speed-comparisons-for-pytorch-user 上面链接的作者在20579张图片中对opencv和PIL的图片读取、Resize、ToTensor等方法进行了对比。结论是:大部分情况下,opencv的速度都要优于PIL。下面展示不同项目的结果对比。 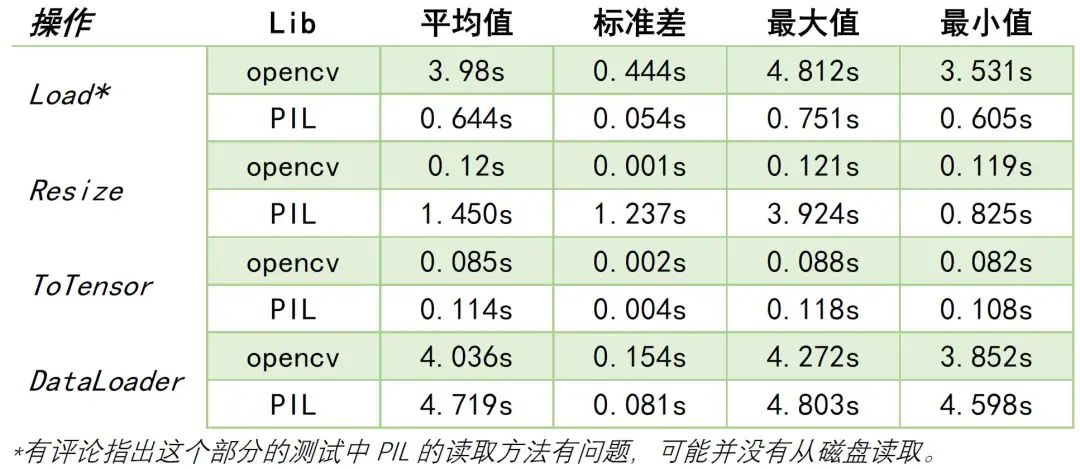 两个库在不同方法的速度对比
prefetch
两个库在不同方法的速度对比
prefetch
预读就是在GPU还在训练一个batch的同时,CPU也没有闲着,赶紧把数据读到内存中并进行数据预处理。在Pytorch1.7以前,一般使用Nvidia的apex库来进行prefetch。但是有个问题就是可能会存在内存泄漏的问题,具体原因可以参考https://github.com/NVIDIA/apex/issues/439。而在Pytorch1.7版本之后,torch.utils.data里面的DataLoader中就能够通过prefetch_factor属性来决定每个每个 worker提前加载的sample数量。 DALI出奇迹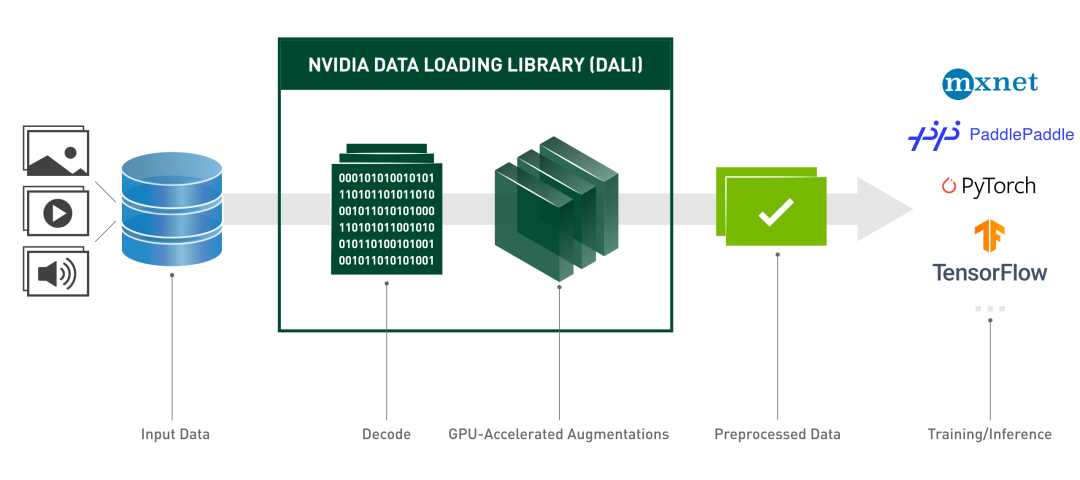 DALI框架工作Pipeline
DALI框架工作Pipeline
为了解决数据读取和预处理速度的问题,Nvidia推出了Data Loading Library[1],包含了诸如数据加载、解码、裁剪、resize还有许多数据增强功能。并且还能够将数据预处理阶段放到显卡上运行,进一步提高了数据增强的效率,目前已经可以轻松地被部署到TensorFlow,PyTorch,MXNet和PaddlePaddle框架。实测在使用Pytorch+DALI能够比原来的速度提高将近四倍![2] References[1] https://docs.nvidia.com/deeplearning/dali/user-guide/docs/ [2]https://zhuanlan.zhihu.com/p/105056158 国内首个自动驾驶学习社区 近1000人的交流社区,和20+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(分类、检测、分割、关键点、车道线、3D目标检测、多传感器融合、目标跟踪、光流估计、轨迹预测)、自动驾驶定位建图(SLAM、高精地图)、自动驾驶规划控制、领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频,期待交流!
【自动驾驶之心】全栈技术交流群 自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多传感器融合、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、硬件配置、AI求职交流等方向;
添加汽车人助理微信邀请入群 备注:学校/公司+方向+昵称 |


【本文地址】