python爬取北京贝壳找房网数据 |
您所在的位置:网站首页 › 房产数据分析的Python程序 › python爬取北京贝壳找房网数据 |
python爬取北京贝壳找房网数据
|
python爬取北京贝壳找房网数据 一,选题背景 贝壳找房业务涉及二手房,新房,租房,商业办公等。平台拥有全面真实的房源信息,为需要找房的人提高安全可靠的购房体验。对北京贝壳找房网进行数据爬取 要达到的数据分析的预期目标是: 1,对爬取的房源信息进行可视化处理。 2,预期目标归类二手房源进行可视化处理。
二,爬虫设计方案 1,爬虫名称: 爬取北京贝壳找房网数据可视化处理。 2,爬虫爬取的内容与数据特征分析: 目标网站是北京贝壳找房网,其原理主要是通过Requests获取Json请求,从而得到北京市房源数据 3. 方案概述 分析网站页面结构,找到爬取数据的位置,根据不同的数据制定不同的爬取方法,将爬取的数据保存成csv文件,然后再将csv文件里的数据进行可视化处理。 第一步 分析网站 第二步 发送请求并获取Json数据 第三步 获取北京市房源数据数据 第四步 绘制柱状图等
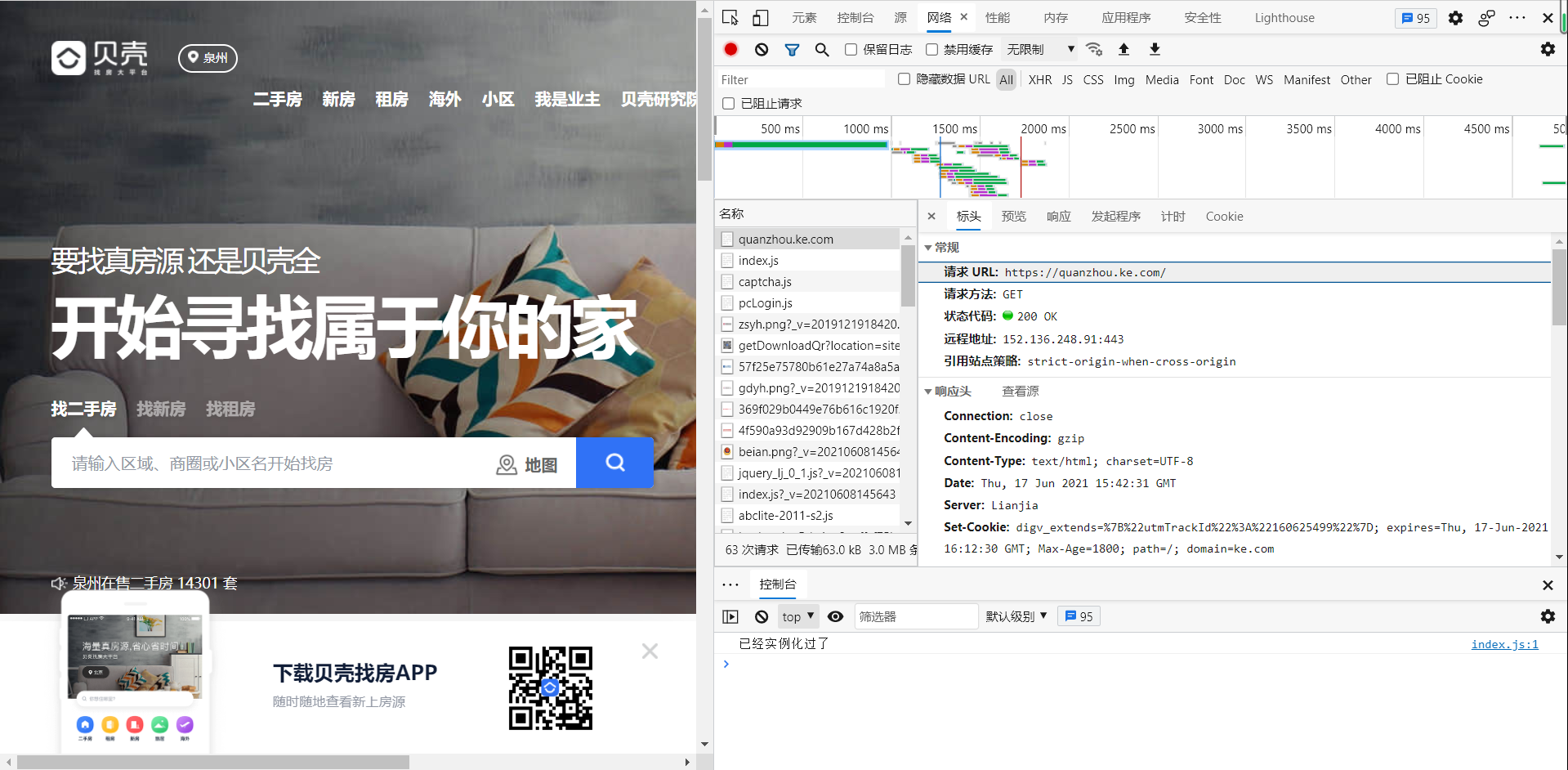
三,主题页面的结构特征分析 1,主题页面的结构与特性分析 通过浏览器“审查元素”查看源代码及“网络”反馈的消息(按f12可以获取),如下图所示:
网站html页面结构分析
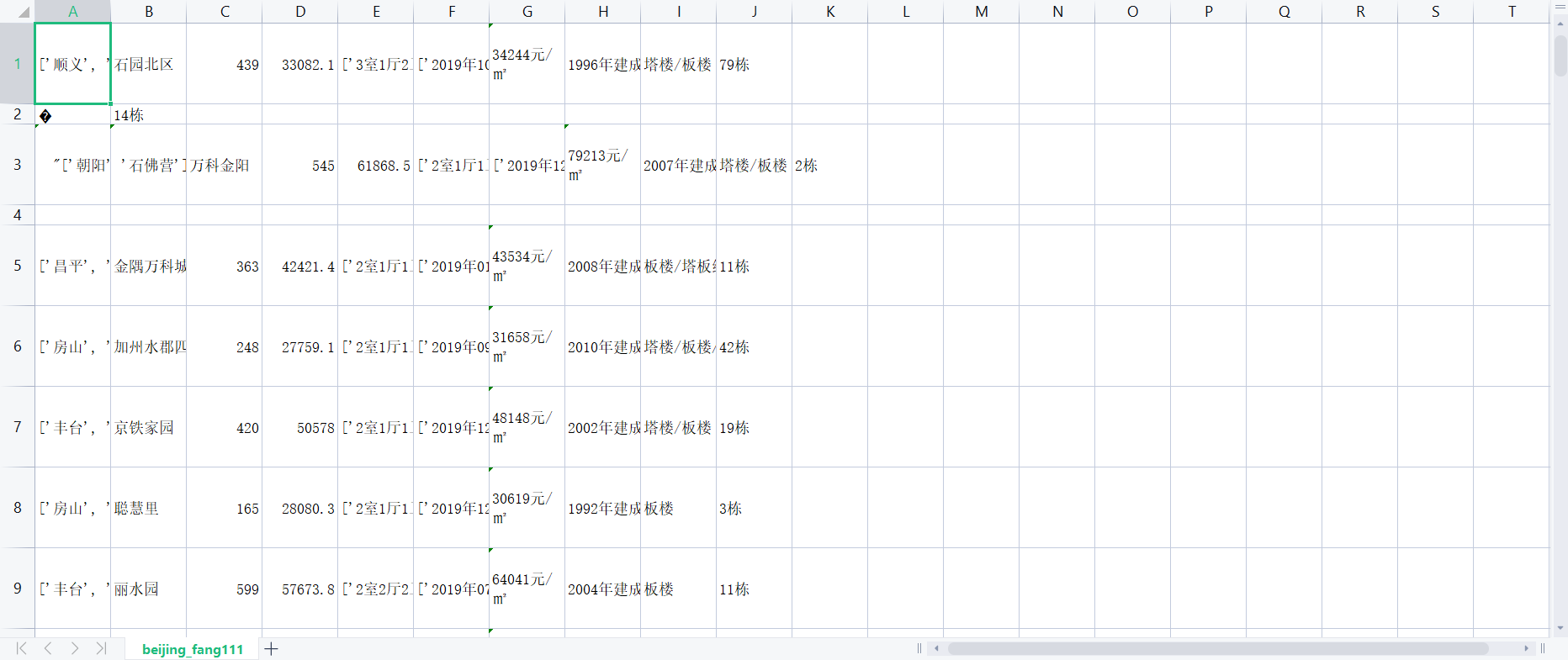
四,爬虫程序设计 1. 数据的爬取 (1)北京市房源数据的爬取 import requests import time from multiprocessing import Pool from lxml import etree import pandas as pd import os import random # 获取房源的基本url # 参数page def get_home_url(page): url = 'http://bj.ke.com/ershoufang/pg{}/'.format(page) headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36', 'Cookie': 'lianjia_uuid=e6a91b7a-b6a4-40b5-88c6-ff67759cbc8a; crosSdkDT2019DeviceId=-51npj6--xbmlw5-f22i5qg8bh36ouv-yttqkmwdf; _ga=GA1.2.121082359.1579583230; ke_uuid=6de1afa21a5799c0874702af39248907; __xsptplus788=788.1.1579583230.1579583347.4%234%7C%7C%7C%7C%7C%23%23Q6jl-k46IlXjCORdTOp6O3JyzHokoUrb%23; select_city=110000; digv_extends=%7B%22utmTrackId%22%3A%2280418605%22%7D; lianjia_ssid=a4ab1bc0-cb04-492f-960c-342c66065da0; Hm_lvt_9152f8221cb6243a53c83b956842be8a=1583897013,1583932737; User-Realip=111.196.247.121; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%2216fc67f100b140-06f07f8f707639-33365a06-1049088-16fc67f100c603%22%2C%22%24device_id%22%3A%2216fc67f100b140-06f07f8f707639-33365a06-1049088-16fc67f100c603%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_referrer%22%3A%22%22%2C%22%24latest_referrer_host%22%3A%22%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%2C%22%24latest_utm_source%22%3A%22baidu%22%2C%22%24latest_utm_medium%22%3A%22pinzhuan%22%2C%22%24latest_utm_campaign%22%3A%22wybeijing%22%2C%22%24latest_utm_content%22%3A%22biaotimiaoshu%22%2C%22%24latest_utm_term%22%3A%22biaoti%22%7D%7D; Hm_lpvt_9152f8221cb6243a53c83b956842be8a=1583933576; srcid=eyJ0Ijoie1wiZGF0YVwiOlwiMjAxZjBjNWU1ZWE1ZGVmYjQxZDFlYTE4MGVkNWI1OGRjYzk5Mzc2MjEwNTcyMWI3ODhiNTQyNTExOGQ1NTVlZDNkMTY2MWE2YWI5YWRlMGY0NDA3NjkwNWEyMzRlNTdhZWExNDViNGFiNWVmMmMyZWJlZGY1ZjM2Y2M0NWIxMWZlMWFiOWI2MDJiMzFmOTJmYzgxNzNiZTIwMzE1ZGJjNTUyMWE2ZjcxYzZmMTFhOWIyOWU2NzJkZTkyZjc3ZDk1MzhiNjhhMTQyZDQ2YmEyNjJhYzJmNjdjNmFjM2I5YzU0MzdjMDkwYWUwMzZmZjVjYWZkZTY5YjllYzY0NzEwMWY2OTc1NmU1Y2ExNzNhOWRmZTdiNGY4M2E1Zjc2NDZmY2JkMGM2N2JiMjdmZTJjNjI2MzNkMjdlNDY4ODljZGRjMjc3MTQ0NDUxMDllZThlZDVmZmMwMjViNjc2ZjFlY1wiLFwia2V5X2lkXCI6XCIxXCIsXCJzaWduXCI6XCJkMDI2MDk0N1wifSIsInIiOiJodHRwczovL2JqLmtlLmNvbS9lcnNob3VmYW5nLzE5MTExMzE5NTEwMTAwMTcxNzU5Lmh0bWwiLCJvcyI6IndlYiIsInYiOiIwLjEifQ==' } text = requests.get(url,headers=headers).text html = etree.HTML(text) detail_url = html.xpath('//ul[@class="sellListContent"]//li[@class="clear"]/a/@href') return detail_url # 获取房源详细数据信息 def get_home_detail_infos(detail_url): headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36', 'Cookie': 'lianjia_uuid=e6a91b7a-b6a4-40b5-88c6-ff67759cbc8a; crosSdkDT2019DeviceId=-51npj6--xbmlw5-f22i5qg8bh36ouv-yttqkmwdf; _ga=GA1.2.121082359.1579583230; ke_uuid=6de1afa21a5799c0874702af39248907; __xsptplus788=788.1.1579583230.1579583347.4%234%7C%7C%7C%7C%7C%23%23Q6jl-k46IlXjCORdTOp6O3JyzHokoUrb%23; select_city=110000; digv_extends=%7B%22utmTrackId%22%3A%2280418605%22%7D; lianjia_ssid=a4ab1bc0-cb04-492f-960c-342c66065da0; Hm_lvt_9152f8221cb6243a53c83b956842be8a=1583897013,1583932737; User-Realip=111.196.247.121; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%2216fc67f100b140-06f07f8f707639-33365a06-1049088-16fc67f100c603%22%2C%22%24device_id%22%3A%2216fc67f100b140-06f07f8f707639-33365a06-1049088-16fc67f100c603%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_referrer%22%3A%22%22%2C%22%24latest_referrer_host%22%3A%22%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%2C%22%24latest_utm_source%22%3A%22baidu%22%2C%22%24latest_utm_medium%22%3A%22pinzhuan%22%2C%22%24latest_utm_campaign%22%3A%22wybeijing%22%2C%22%24latest_utm_content%22%3A%22biaotimiaoshu%22%2C%22%24latest_utm_term%22%3A%22biaoti%22%7D%7D; Hm_lpvt_9152f8221cb6243a53c83b956842be8a=1583933576; srcid=eyJ0Ijoie1wiZGF0YVwiOlwiMjAxZjBjNWU1ZWE1ZGVmYjQxZDFlYTE4MGVkNWI1OGRjYzk5Mzc2MjEwNTcyMWI3ODhiNTQyNTExOGQ1NTVlZDNkMTY2MWE2YWI5YWRlMGY0NDA3NjkwNWEyMzRlNTdhZWExNDViNGFiNWVmMmMyZWJlZGY1ZjM2Y2M0NWIxMWZlMWFiOWI2MDJiMzFmOTJmYzgxNzNiZTIwMzE1ZGJjNTUyMWE2ZjcxYzZmMTFhOWIyOWU2NzJkZTkyZjc3ZDk1MzhiNjhhMTQyZDQ2YmEyNjJhYzJmNjdjNmFjM2I5YzU0MzdjMDkwYWUwMzZmZjVjYWZkZTY5YjllYzY0NzEwMWY2OTc1NmU1Y2ExNzNhOWRmZTdiNGY4M2E1Zjc2NDZmY2JkMGM2N2JiMjdmZTJjNjI2MzNkMjdlNDY4ODljZGRjMjc3MTQ0NDUxMDllZThlZDVmZmMwMjViNjc2ZjFlY1wiLFwia2V5X2lkXCI6XCIxXCIsXCJzaWduXCI6XCJkMDI2MDk0N1wifSIsInIiOiJodHRwczovL2JqLmtlLmNvbS9lcnNob3VmYW5nLzE5MTExMzE5NTEwMTAwMTcxNzU5Lmh0bWwiLCJvcyI6IndlYiIsInYiOiIwLjEifQ==' } detail_text = requests.get(detail_url,headers=headers).text html = etree.HTML(detail_text) all_data = [] # 解析获取相关数据 # 所在地址 home_location = html.xpath('//div[@data-component="overviewIntro"]//div[@class="content"]//div[@class="areaName"]/span[@class="info"]/a/text()') all_data.append(home_location) # 小区名称 local_name = html.xpath('//div[@data-component="overviewIntro"]//div[@class="content"]//div[@class="communityName"]/a/text()')[0] all_data.append(local_name) # 总价格 total_price = html.xpath('//div[@data-component="overviewIntro"]//div[@class="content"]//div[@class="price "]/span[@class="total"]/text()')[0] all_data.append(total_price) # 单价 unit_price = html.xpath('//div[@data-component="overviewIntro"]//div[@class="content"]//div[@class="price "]//div[@class="unitPrice"]/span/text()')[0] all_data.append(unit_price) # 房屋基本信息 home_style = html.xpath('//div[@class="introContent"]//div[@class="base"]//div[@class="content"]/ul/li/text()') all_data.append(home_style) # 房屋交易属性信息 transaction_info = html.xpath('//div[@class="introContent"]//div[@class="transaction"]//div[@class="content"]/ul/li/text()') all_data.append(transaction_info) # 小区均价 xiaoqu_price = html.xpath('//div[@class="xiaoquCard"]//div[@class="xiaoqu_main fl"]//span[@class="xiaoqu_main_info price_red"]/text()')[0].replace(' ','') all_data.append(xiaoqu_price) # 小区建造时间 xiaoqu_built_time = html.xpath('//div[@class="xiaoquCard"]//div[@class="xiaoqu_main fl"]//span[@class="xiaoqu_main_info"]/text()')[0].replace(' ','').replace('\n','') all_data.append(xiaoqu_built_time) # 小区建筑类型 xiaoqu_built_style = html.xpath('//div[@class="xiaoquCard"]//div[@class="xiaoqu_main fl"]//span[@class="xiaoqu_main_info"]/text()')[1].replace(' ','').replace('\n','') all_data.append(xiaoqu_built_style) # 小区楼层总数 xiaoqu_total_ceng = html.xpath('//div[@class="xiaoquCard"]//div[@class="xiaoqu_main fl"]//span[@class="xiaoqu_main_info"]/text()')[2].replace(' ','').replace('\n','') all_data.append(xiaoqu_total_ceng) return all_data # 数据保存至csv文件里(使用pandas中的to_csv保存) def save_data(data): data_frame = pd.DataFrame(data,columns=['小区位置','小区名称','房屋总价','房屋单价','房屋基本信息','房屋交易信息','小区均价','小区建造时间','小区房屋类型','小区层数']) print(data_frame) data_frame.to_csv('beijing_fang111.csv',header=False,index=False,mode='a',encoding='utf_8_sig') def main(page): print('开始爬取第{}页的数据!'.format(page)) # choice_time = random.choice(range(0,5)) # print(choice_time) urls = get_home_url(page) for url in urls: print('开始爬去详细网页为{}的房屋详细信息资料!'.format(url)) all_data = get_home_detail_infos(detail_url=url) data = [] data.append(all_data) save_data(data) if __name__ == "__main__": page = range(0,100) print('爬虫开始') pool = Pool(processes=4) pool.map(main,page) # proxies = proxy.get_proxy_random() # pool.apply_async(main,args=(page,proxies,)) pool.close() pool.join()#结构截图
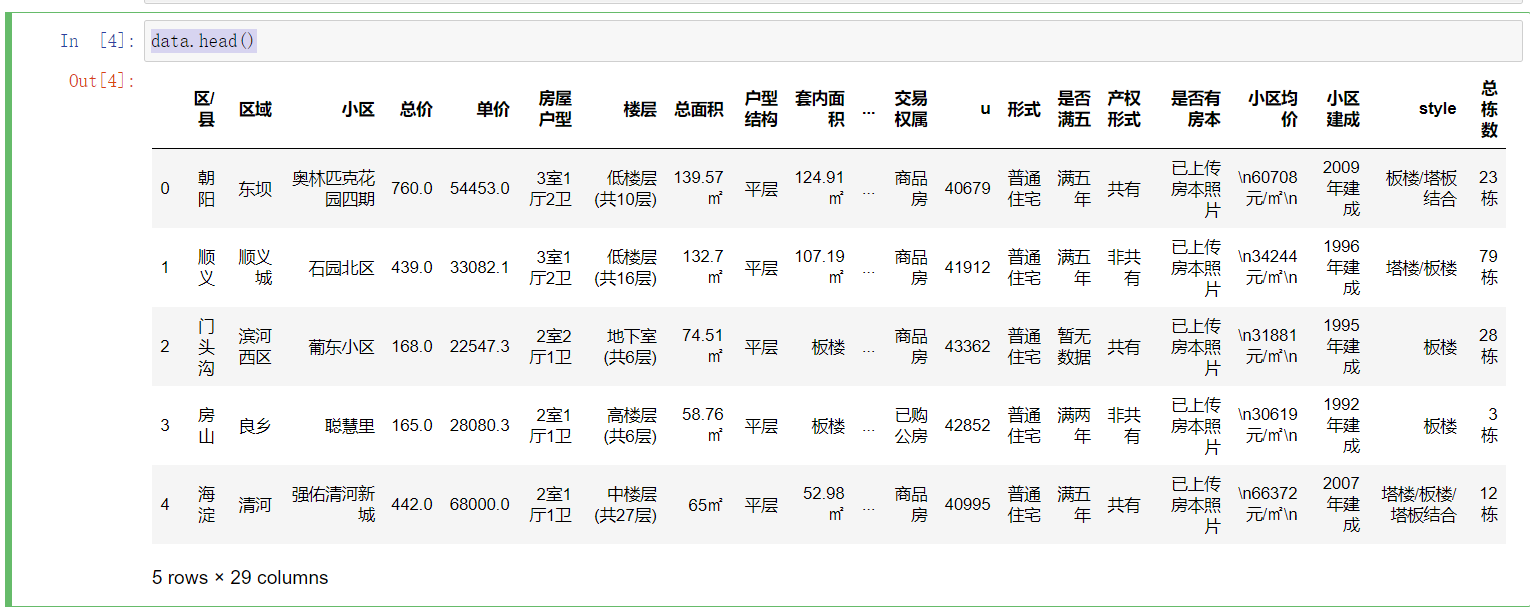
#对数据进行处理 import pandas as pd import numpy as np from matplotlib import pyplot as plt import csv data = pd.read_excel(r"F:\0_个人学习\beike_find_house.xlsx", header=None) data.columns = ['区/县','区域','小区','总价','单价','房屋户型','楼层','总面积','户型结构','套内面积','建筑类型','朝向','建筑结构','装修情况','梯户比例','供暖方式','配备电梯','产权年限','s','交易权属','u','形式','是否满五','产权形式','是否有房本','小区均价','小区建成','style','总栋数'] data.head()#结果截图
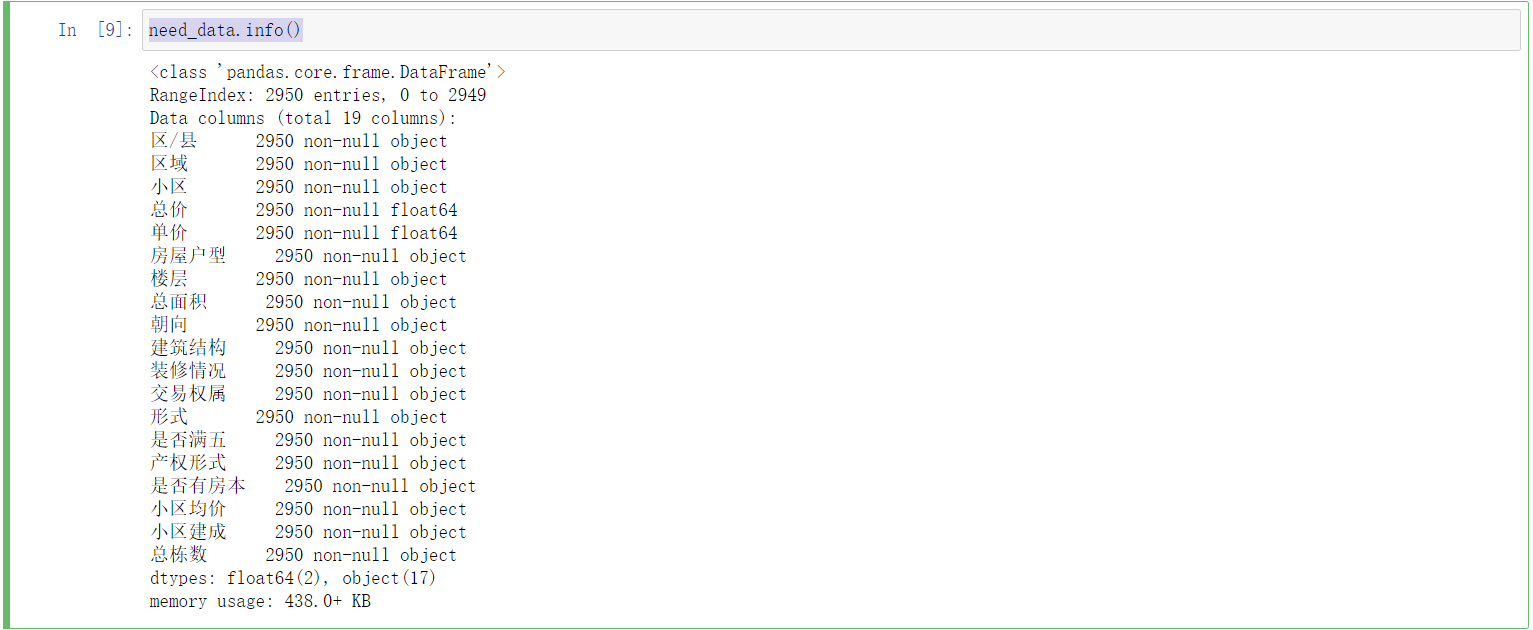
#数据清洗 data['装修情况'] = data.apply(lambda x:x['建筑类型'] if ('南北' in str(x['户型结构'])) else x['装修情况'],axis=1) data['建筑结构'] = data.apply(lambda x:x['套内面积'] if ('南北' in str(x['户型结构'])) else x['建筑结构'],axis=1) data['朝向'] = data.apply(lambda x:x['户型结构'] if ('南北' in str(x['户型结构'])) else x['朝向'],axis=1) data['套内面积'] = data.apply(lambda x:'㎡' if ('南北' in str(x['户型结构'])) else x['套内面积'],axis=1) data['装修情况'] = data.apply(lambda x:x['朝向'] if ('㎡' in str(x['户型结构'])) else x['装修情况'],axis=1) data['建筑结构'] = data.apply(lambda x:x['建筑类型'] if ('㎡' in str(x['户型结构'])) else x['建筑结构'],axis=1) data['朝向'] = data.apply(lambda x:x['套内面积'] if ('㎡' in str(x['户型结构'])) else x['朝向'],axis=1) data['套内面积'] = data.apply(lambda x:'㎡' if ('㎡' in str(x['户型结构'])) else x['套内面积'],axis=1) data['套内面积'] = data.apply(lambda x:'㎡' if ('暂无数据' in str(x['套内面积'])) else x['套内面积'],axis=1) data['装修情况'] = data.apply(lambda x:x['装修情况'] if ('㎡' in str(x['套内面积'])) else x['建筑结构'],axis=1) data['建筑结构'] = data.apply(lambda x:x['建筑结构'] if ('㎡' in str(x['套内面积'])) else x['朝向'],axis=1) data['朝向'] = data.apply(lambda x:x['朝向'] if ('㎡' in str(x['套内面积'])) else x['建筑类型'],axis=1) data['建筑类型'] = data.apply(lambda x:x['建筑类型'] if ('㎡' in str(x['套内面积'])) else x['套内面积'],axis=1) data['套内面积'] = data.apply(lambda x:x['套内面积'] if ('㎡' in str(x['套内面积'])) else '无信息',axis=1) data['装修情况'] = data.apply(lambda x:x['建筑结构'] if (('户') in str(x['装修情况'])) else x['装修情况'],axis=1) data['建筑结构'] = data.apply(lambda x:x['朝向'] if (('户') in str(x['装修情况'])) else x['建筑结构'],axis=1) data['朝向'] = data.apply(lambda x:x['建筑类型'] if (('户') in str(x['装修情况'])) else x['朝向'],axis=1) data['建筑结构'] = data.apply(lambda x:x['朝向'] if ('结构' in str(x['朝向'])) else x['建筑结构'],axis=1) data['朝向'] = data.apply(lambda x:x['建筑类型'] if ('结构' in str(x['朝向'])) else x['朝向'],axis=1) data['总楼层'] = data.apply(lambda x:str(x[6])[3:].strip('(共').strip('层)'),axis=1) data['楼层'] = data.apply(lambda x:str(x[6])[:3],axis=1) data['总面积'] = data.apply(lambda x:str(x[7]).strip('㎡'),axis=1) data['小区均价'] = data.apply(lambda x:str(x[-5]).strip('元/㎡\n').strip('\n'),axis=1) data['小区建成'] = data.apply(lambda x:str(x[-4])[:4],axis=1) data['总栋数'] = data.apply(lambda x:str(x[-2])[:-1],axis=1) data.to_csv('after_deal_data.csv',encoding='utf_8_sig') need_data = data[['区/县','区域','小区','总价','单价','房屋户型','楼层','总面积','朝向','建筑结构','装修情况','交易权属','形式','是否满五','产权形式','是否有房本','小区均价','小区建成','总栋数']] need_data.head()#结果截图
need_data.info()
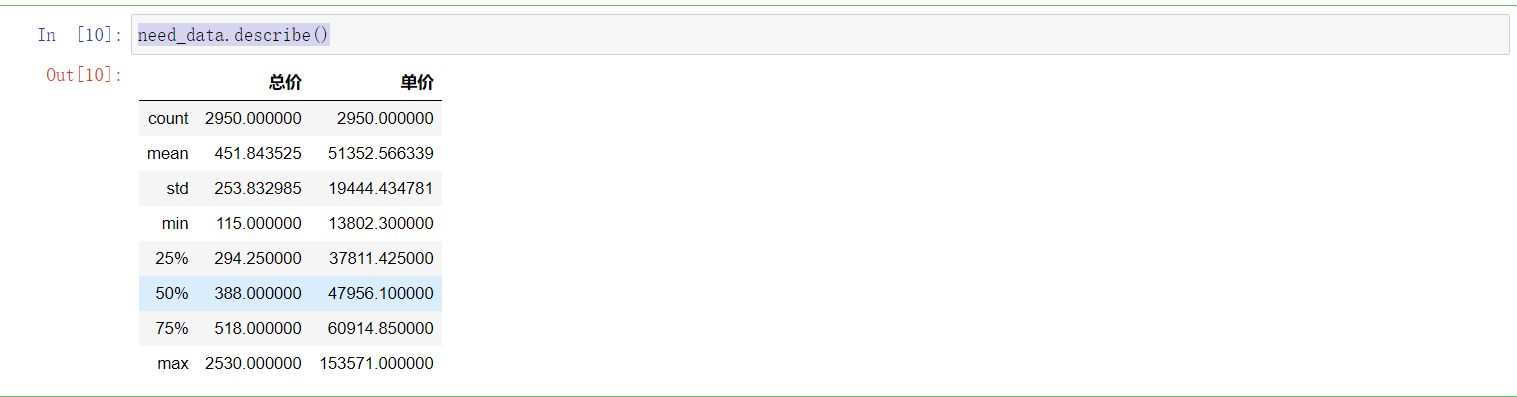
need_data.describe()
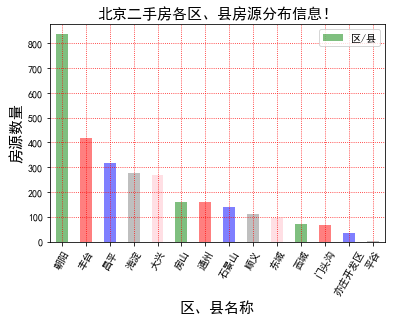
plt.rcParams['font.sans-serif'] = ['SimHei'] # 步骤一(替换sans-serif字体) plt.rcParams['axes.unicode_minus'] = False # 步骤二(解决坐标轴负数的负号显示问题) fig, ax=plt.subplots() ''' 各区县房源分布情况!!! ''' need_data['区/县'].value_counts().plot(kind='bar',color=['green','red','blue','grey','pink'],alpha=0.5) plt.title('北京二手房各区、县房源分布信息!',fontsize=15) plt.xlabel('区、县名称',fontsize=15) plt.ylabel('房源数量',fontsize=15) plt.grid(linestyle=":", color="r") plt.xticks(rotation=60) plt.legend() plt.show() #结果截图
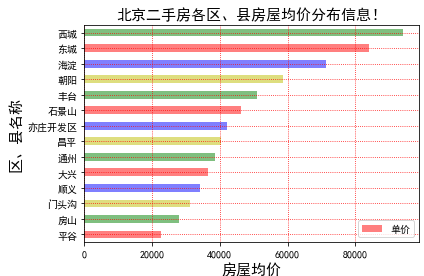
''' 各区县房源均价分布情况!!! ''' need_data.groupby('区/县').mean()['单价'].sort_values(ascending=True).plot(kind='barh',color=['r','g','y','b'],alpha=0.5) plt.title('北京二手房各区、县房屋均价分布信息!',fontsize=15) plt.xlabel('房屋均价',fontsize=15) plt.ylabel('区、县名称',fontsize=15) plt.grid(linestyle=":", color="r") plt.legend() plt.show() #结果截图
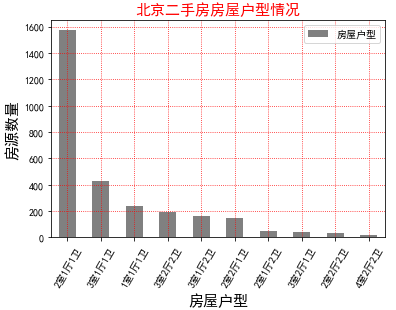
''' 房屋户型情况 ''' room_style = need_data['房屋户型'].value_counts() print(room_style) need_data['房屋户型'].value_counts()[:10].plot(kind='bar',color='grey') plt.title('北京二手房房屋户型情况',fontsize=15,color='red') plt.xlabel('房屋户型',fontsize=15) plt.ylabel('房源数量',fontsize=15) plt.grid(linestyle=":", color="r") plt.legend() plt.xticks(rotation=60) # ax.spines['top'].set_visible(False) # ax.spines['right'].set_visible(False) plt.show()
need_data[need_data.房屋户型 == '1室0厅2卫']
# 北京二手房总价最大、最小值及其房源信息 total_price_min = need_data['总价'].min() total_price_min_room_info = need_data[need_data.总价==total_price_min] print('二手房总价最低价位为:\n{}'.format(total_price_min)) print('二手房总价最低的房源信息为:\n{}'.format(total_price_min_room_info)) total_price_max = need_data['总价'].max() total_price_max_room_info = need_data[need_data.总价==total_price_max] print('二手房总价最高价位为:\n{}'.format(total_price_max)) print('二手房总价最低的房源信息为:\n{}'.format(total_price_max_room_info))
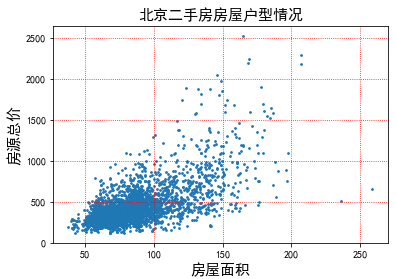
# 绘制总面积和总价的散点关系图 home_area = need_data['总面积'].apply(lambda x:float(x)) # print(home_area.head()) total_price = need_data['总价'] # print(total_price.head()) plt.scatter(home_area,total_price,s=3) plt.title('北京二手房房屋户型情况',fontsize=15) plt.xlabel('房屋面积',fontsize=15) plt.ylabel('房源总价',fontsize=15) plt.grid(linestyle=":", color="r") plt.show()
# 分析两个面积大但是价格较低的房源 area_max = home_area.max() area_max_room_info = need_data[home_area==area_max] print('二手房面积最大的房源信息为:\n{}'.format(area_max_room_info))
''' 装修情况的房源分布情况!!! ''' need_data['装修情况'].value_counts().plot(kind='bar',color=['g','r','y','b'],alpha=0.5) plt.title('北京二手房装修情况的房源分布信息!',fontsize=15) plt.xlabel('装修类型',fontsize=15) plt.ylabel('房屋均价',fontsize=15) plt.grid(linestyle=":", color="r") plt.legend() plt.xticks(rotation=0) plt.show() ''' 装修情况的均价分布情况!!! ''' need_data.groupby('装修情况').mean()['单价'].plot(kind='bar',color=['g','r','y','b'],alpha=0.5) plt.title('北京二手房装修与房屋均价分布信息!',fontsize=15) plt.xlabel('装修类型',fontsize=15) plt.ylabel('房屋均价',fontsize=15) plt.grid(linestyle=":", color="r") plt.legend() plt.xticks(rotation=0) plt.show()
# 小区均价数据的清洗处理 # 由于小区均价中存在暂无数据的情况,本次使用单价的形式代替房屋均价 need_data = need_data.copy() need_data['小区均价'] = need_data.apply(lambda x: x['单价'] if ('暂无数据' in str(x['小区均价'])) else x['小区均价'],axis=1) avg_price = need_data['小区均价'].astype('float') print('小区均价最高的价格是:{}'.format(avg_price.max())) print('小区均价最低的价格是:{}'.format(avg_price.min()))
# 小区均价最低的房源信息 need_data[need_data['小区均价'].astype('float')==avg_price.min()]
# 小区均价最高的房源信息 need_data[need_data['小区均价'].astype('float')==avg_price.max()]
# 将未有小区建成时间的数据字段直接剔除(2个) need_data[need_data.小区建成=='暂无数据']
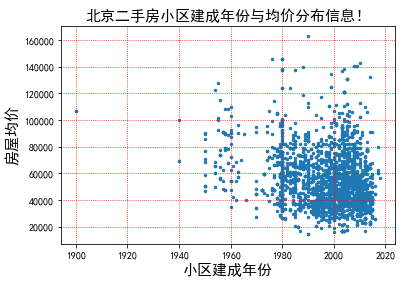
# 剔除小区建成时间为暂无数据的两条数据 try: need_data = need_data.drop([1931,2527]) except: print('数据已经剔除!!!') need_data[need_data.小区建成=='暂无数据'] # 将小区建成时间转成日期并仅提取其中的年份 built_year = pd.to_datetime(need_data.小区建成).dt.year # 绘制小区建成年限与小区均价的散点分布图 plt.scatter(built_year,need_data['小区均价'].astype(float),s=6) plt.title('北京二手房小区建成年份与均价分布信息!',fontsize=15) plt.xlabel('小区建成年份',fontsize=15) plt.ylabel('房屋均价',fontsize=15) plt.grid(linestyle=":", color="r") plt.xticks(rotation=0) plt.show()
# 分析房屋的产权形式(得出结论有两种) need_data['产权形式'].value_counts()
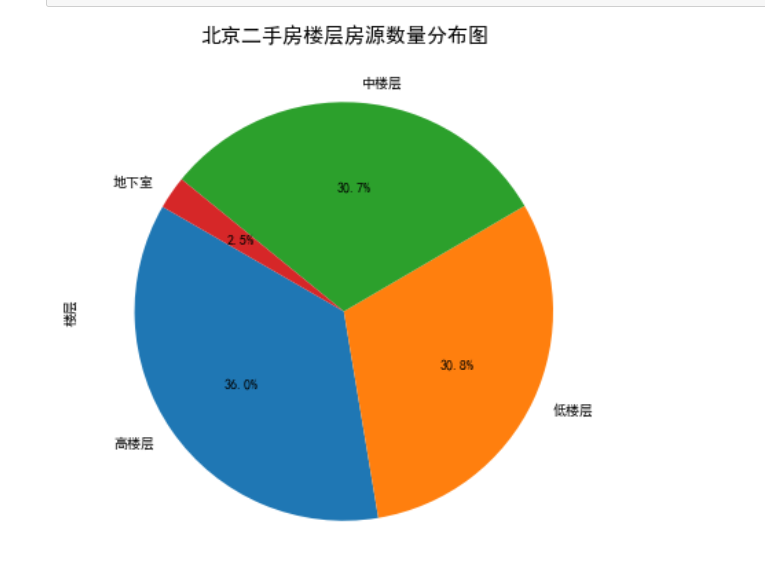
need_data['楼层'].value_counts() need_data[need_data['楼层']=='未知('] try: need_louceng_data = need_data.drop(1340) except: print('楼层未知的已删除!') need_louceng_data[need_louceng_data['楼层']=='未知('] plt.figure(figsize=(7,7)) need_louceng_data['楼层'].value_counts().plot(kind='pie',autopct='%1.1f%%',shadow=False,startangle=150) plt.title('北京二手房楼层房源数量分布图',fontsize=15) plt.xticks(rotation=30) plt.grid(linestyle=":", color="g") plt.show()
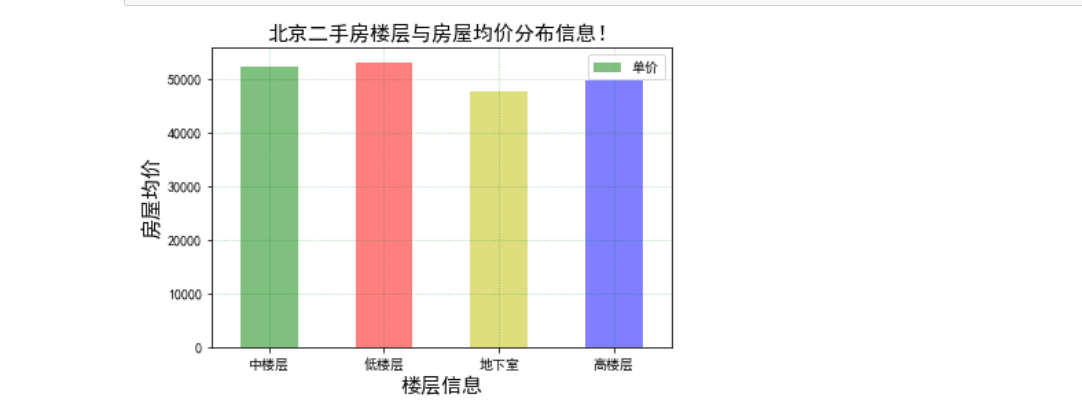
avg_price_louceng = need_louceng_data.groupby('楼层').mean()['单价'] avg_price_louceng.plot(kind='bar',color=['g','r','y','b'],alpha=0.5) plt.title('北京二手房楼层与房屋均价分布信息!',fontsize=15) plt.xlabel('楼层信息',fontsize=15) plt.ylabel('房屋均价',fontsize=15) plt.grid(linestyle=":", color="g",alpha=0.4) plt.legend() plt.xticks(rotation=0) plt.show()
五,总结 这次的主题爬虫爬的是北京贝壳找房网的网站,相对来说进行的还是比较不顺利的,该网站设置了反爬限制。在数据的可视化上,大部分都还好,想要的也达到了我的预期效果。现在很多网站是用JSON存储数据或者用JS动态加载数据的,因此之后会多学习这些方面的知识。
|













【本文地址】
今日新闻 |
推荐新闻 |