【机器学习报告】我用链家的数据做了一个超过链家模型的二手房房价预测模型 |
您所在的位置:网站首页 › 房产数据分析报告 › 【机器学习报告】我用链家的数据做了一个超过链家模型的二手房房价预测模型 |
【机器学习报告】我用链家的数据做了一个超过链家模型的二手房房价预测模型
|
我用链家的数据做的二手房房价预测模型,打败了链家自己的模型
前言数据准备爬虫准备特征展示变量统计性描述数据处理数据清洗与异常值过滤数据截断数据集划分:
特征处理模型与分析第一轮迭代第二轮迭代
模型融合K折验证
PK链家模型链家估价模型测试集准备模型PK
代码开源
前言
在二手房交易市场中,普遍存在挂盘价与成交价偏差大的问题,如何精准预测二手房成交价成为一大难题。本模型的目标是训练出一个根据二手房相关特征来数据预测二手房成交价的模型,保证预测准确度要优于网站的预测模型,并给二手房出售标价提供参考价值。 (好吧这其实是我这学期数据挖掘课的大作业) 数据准备 爬虫准备 数据来源: 数据来自链家的官方交易网站https://bj.lianjia.com/chengjiao/,为了保证数据量足够大,我们的任务瞄准了北京的二手房成交信息。数据获取: 使用python编写异步爬虫脚本,该多线程脚本大大减少了爬虫所需的时间,使用了aiohttp、asyncio、lxml等相关库获取分布合理的数据集: 考虑到网站上只列出了100页具有相同约束的交易记录,总计达3000条记录,这对于训练数据集来说太小了。因此,我们选择使用几个属性的组合来扩展网站提供的记录。用价格和面积相结合,可以得到56*100页的数据量,同时也保证了数据分布的流畅性。 特征展示 决策变量: 特征变量: 特征变量:   变量统计性描述
决策变量 total_price 成交价:对0-1500万的房屋绘制直方图和密度图,我们可以发现数据是比较均匀的,绝大部分处于100-500万。
变量统计性描述
决策变量 total_price 成交价:对0-1500万的房屋绘制直方图和密度图,我们可以发现数据是比较均匀的,绝大部分处于100-500万。 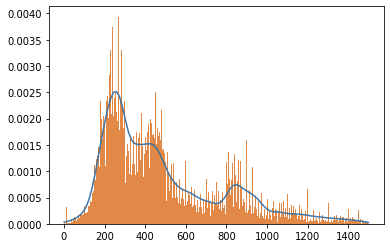 average_price 小区交易成交均价:对小区交易成交均价绘制直方图和密度图,均价集中在1-7万。 average_price 小区交易成交均价:对小区交易成交均价绘制直方图和密度图,均价集中在1-7万。 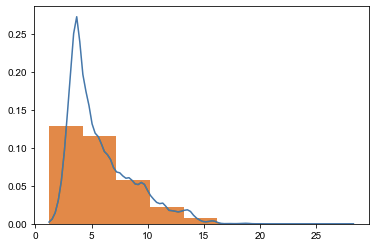 district 所在行政区:对所在行政区绘制柱状图,可以看出我们的数据分布在北京各个行政区,较为平衡。其中,在昌平区和朝阳区的交易二手房较多。 district 所在行政区:对所在行政区绘制柱状图,可以看出我们的数据分布在北京各个行政区,较为平衡。其中,在昌平区和朝阳区的交易二手房较多。 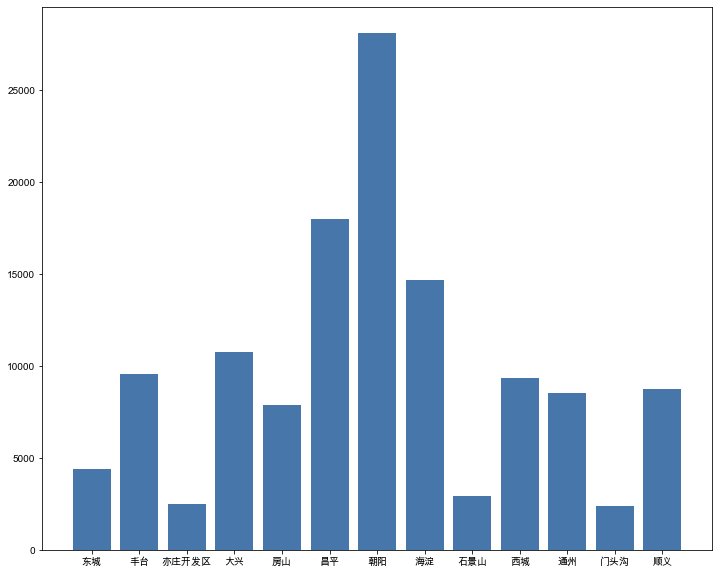 date_of_deal 成交日期:通过成交日期的柱状图,我们可以看出大部分数据是分布在2019、2020年,其他年份的数据是较少的。 date_of_deal 成交日期:通过成交日期的柱状图,我们可以看出大部分数据是分布在2019、2020年,其他年份的数据是较少的。 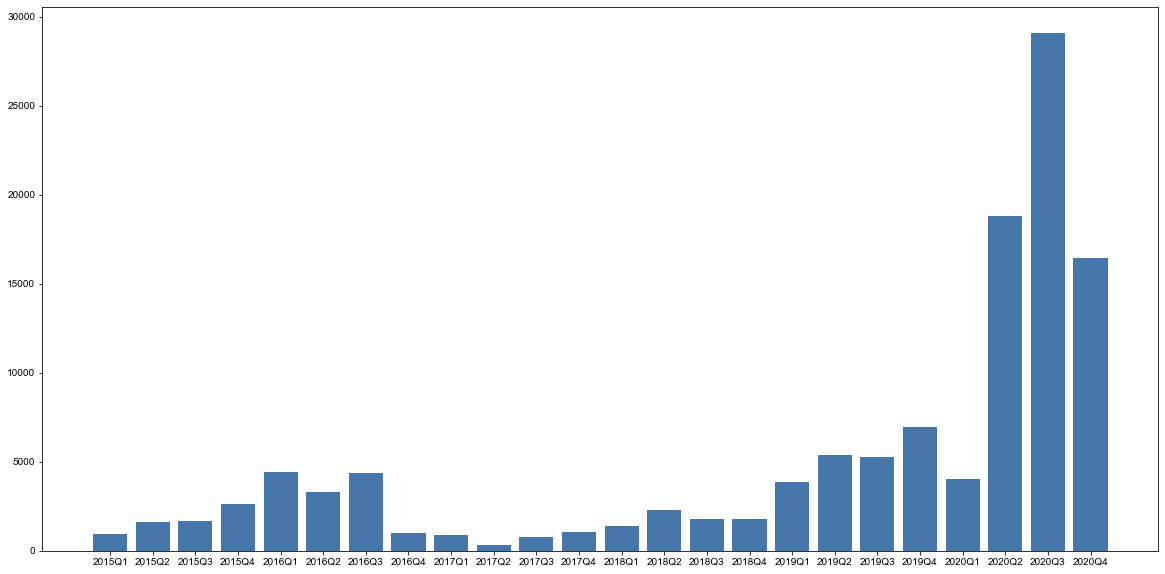 completion_year 建成年限:通过柱状图可以看出,房屋的建成年限集中分布在1990年到2014年。 completion_year 建成年限:通过柱状图可以看出,房屋的建成年限集中分布在1990年到2014年。 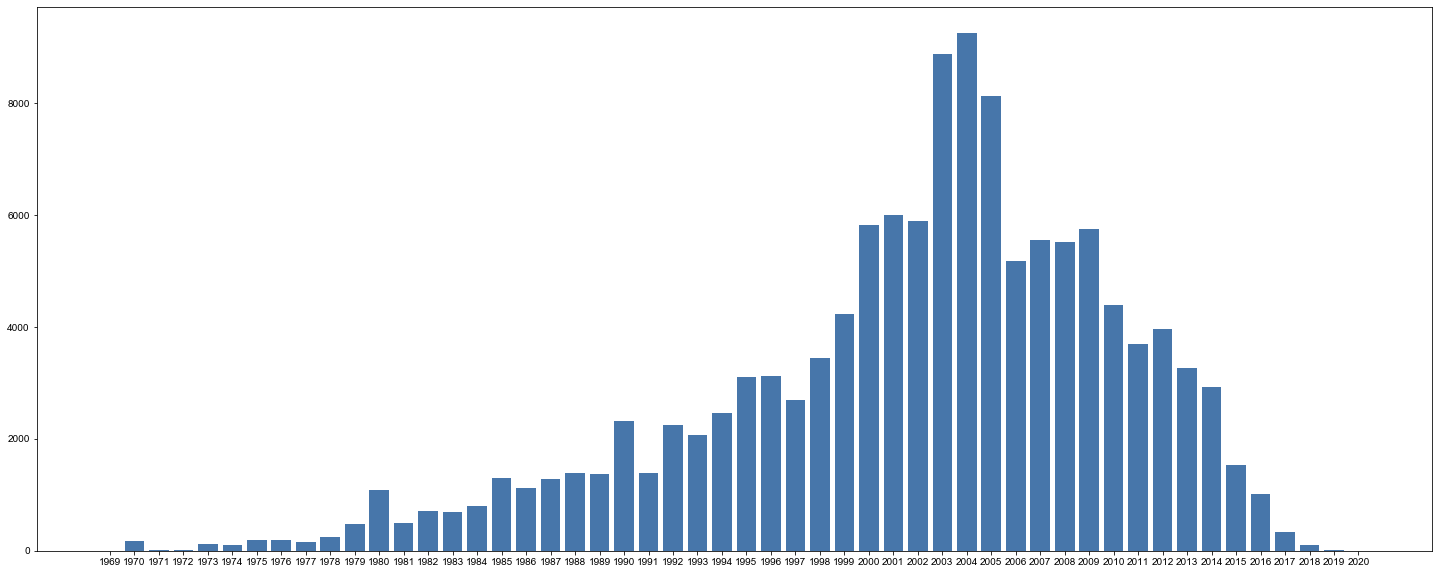 成交价与建筑面积的相关性分析:通过散点图,我们可以看出成交价与建筑面积呈现明显的正相关趋势,这暗示建筑面积是个强相关变量。 成交价与建筑面积的相关性分析:通过散点图,我们可以看出成交价与建筑面积呈现明显的正相关趋势,这暗示建筑面积是个强相关变量。 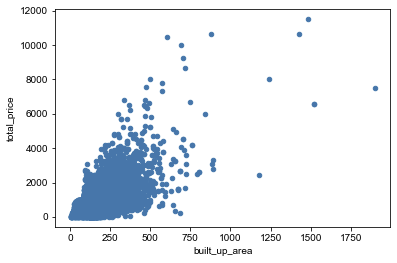 数据处理
数据清洗与异常值过滤
去除数据中house_type为车位的数据去除total_price、average_price、built_up_area为空数据去除built_up_area > 10000 and built_up_area < 5的数据去除total_price > 10亿的数据
数据截断
数据处理
数据清洗与异常值过滤
去除数据中house_type为车位的数据去除total_price、average_price、built_up_area为空数据去除built_up_area > 10000 and built_up_area < 5的数据去除total_price > 10亿的数据
数据截断
对于回归问题,考虑到数据的分布以及模型训练的有效性,我们将目标锁定为: 售价小于2000万的样本包含成交10个及以上的小区样本成交年份在2019至2020年的样本最终我们得到共77766条有效样本 数据集划分: 考虑到数据和模型的时效性,我们将成交于2020年的样本随机划分为7比3的份额,将2019年数据与70%的2020年数据作为训练集,30%的2020年数据作为验证集。最终我们得到65897个训练样本,11869个验证样本。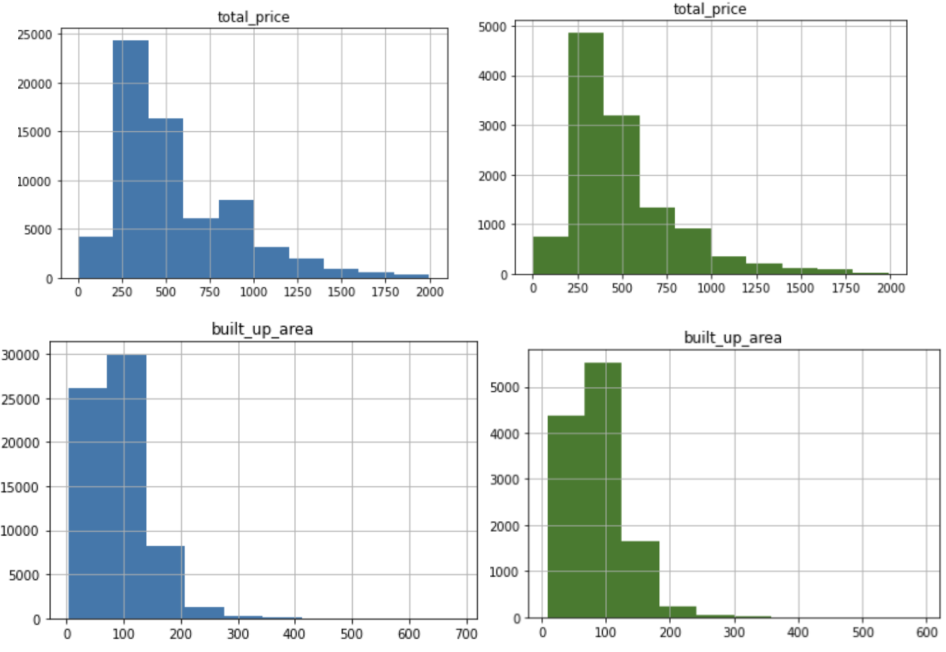 训练集与验证集total_price、build_up_area数据分布(蓝色为训练集,绿色为验证集),两个数据集分布相似,符合划分预期,可以用来训练模型。
特征处理
对于小区特征:考虑到小区数量繁多,特征较为离散,我们将小区名称前两个字符与开发商名称合并作为新的小区名称后,进行离散处理。PS:由于处理后特征仍然非常稀疏,小区数量多,前期我们并未在模型中加入该特征。在后期通过神经网络将该特征处理成8维的embedding加入到模型中去。对于地区特征:离散处理 PS: 在后期通过神经网络将该特征处理成4维的embedding加入到模型中去。除house_type、built_up_area、average_price、property_cost等连续特征,其余特征一律离散化后作为类别特征处理。
模型与分析
第一轮迭代
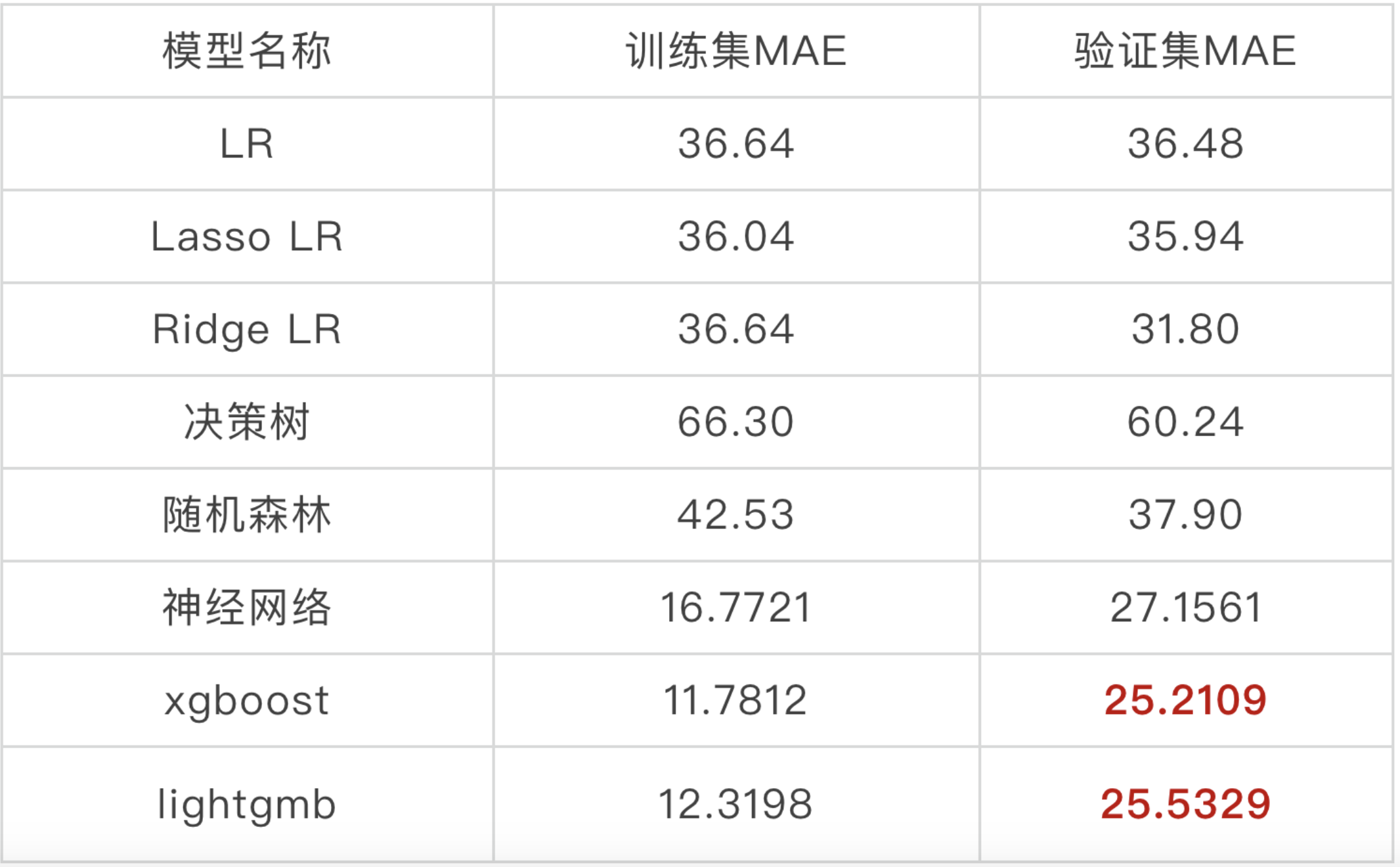
我们尝试了多种模型,并经过了大量的调参工作,最终各个模型的表现如下: 训练集与验证集total_price、build_up_area数据分布(蓝色为训练集,绿色为验证集),两个数据集分布相似,符合划分预期,可以用来训练模型。
特征处理
对于小区特征:考虑到小区数量繁多,特征较为离散,我们将小区名称前两个字符与开发商名称合并作为新的小区名称后,进行离散处理。PS:由于处理后特征仍然非常稀疏,小区数量多,前期我们并未在模型中加入该特征。在后期通过神经网络将该特征处理成8维的embedding加入到模型中去。对于地区特征:离散处理 PS: 在后期通过神经网络将该特征处理成4维的embedding加入到模型中去。除house_type、built_up_area、average_price、property_cost等连续特征,其余特征一律离散化后作为类别特征处理。
模型与分析
第一轮迭代
我们尝试了多种模型,并经过了大量的调参工作,最终各个模型的表现如下:
 其中神经网络结构如下
其中神经网络结构如下
 Xgboost最优参数如下:
xgb.XGBRegressor(objective ='reg:linear',
colsample_bytree = 0.8,
subsample = 0.8,
learning_rate = 0.01,
max_depth = 8,
reg_alpha = 0.5,
reg_lambda = 0.5,
n_estimators = 10000)
Lightbgm最优参数如下:
lgb_params = {
'boosting_type': 'gbdt',
'objective': 'regression',
'metric': 'mae',
'num_leaves': 80,
'max_depth':-1,
'min_data_in_leaf':150,
'learning_rate': 0.01,
'feature_fraction': 0.8,
'bagging_fraction': 0.8,
'bagging_freq': 3,
'lambda_l1': 0.5, 'lambda_l2': 0.5, }
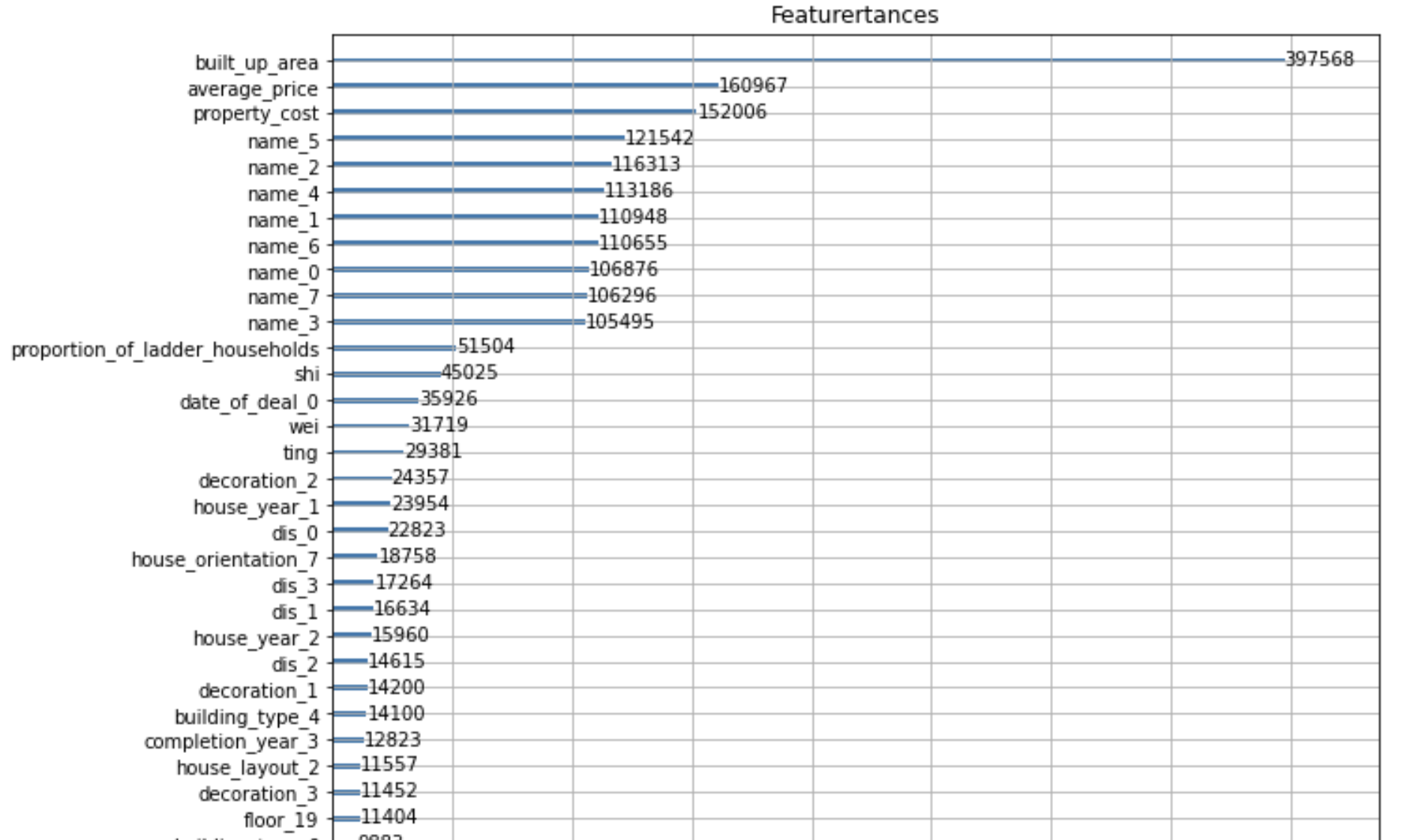
由于计算机与模型性能原因,我们没有尝试使用GDBT。根据上述结果发现,三种回归的表现结果相近,决策树、随机森林等基础树模型的表现与梯度提升树模型的Xgboost、lightgmb而言其拟合能力较差,而神经网络使用MAE作为loss时网络受离群值影响较大,使用MSE作loss时模型又不能很好的收敛。因此我们选择了性能表现最好的xgboost、lightgmb作为我们的baseline模型。以lightgbm为例,我们列出了各个特征的在最优模型中的重要程度,Feature importance越大表示该特征作用越大,其中0 1 3 分别为特征室、厅、卫。
Xgboost最优参数如下:
xgb.XGBRegressor(objective ='reg:linear',
colsample_bytree = 0.8,
subsample = 0.8,
learning_rate = 0.01,
max_depth = 8,
reg_alpha = 0.5,
reg_lambda = 0.5,
n_estimators = 10000)
Lightbgm最优参数如下:
lgb_params = {
'boosting_type': 'gbdt',
'objective': 'regression',
'metric': 'mae',
'num_leaves': 80,
'max_depth':-1,
'min_data_in_leaf':150,
'learning_rate': 0.01,
'feature_fraction': 0.8,
'bagging_fraction': 0.8,
'bagging_freq': 3,
'lambda_l1': 0.5, 'lambda_l2': 0.5, }
由于计算机与模型性能原因,我们没有尝试使用GDBT。根据上述结果发现,三种回归的表现结果相近,决策树、随机森林等基础树模型的表现与梯度提升树模型的Xgboost、lightgmb而言其拟合能力较差,而神经网络使用MAE作为loss时网络受离群值影响较大,使用MSE作loss时模型又不能很好的收敛。因此我们选择了性能表现最好的xgboost、lightgmb作为我们的baseline模型。以lightgbm为例,我们列出了各个特征的在最优模型中的重要程度,Feature importance越大表示该特征作用越大,其中0 1 3 分别为特征室、厅、卫。
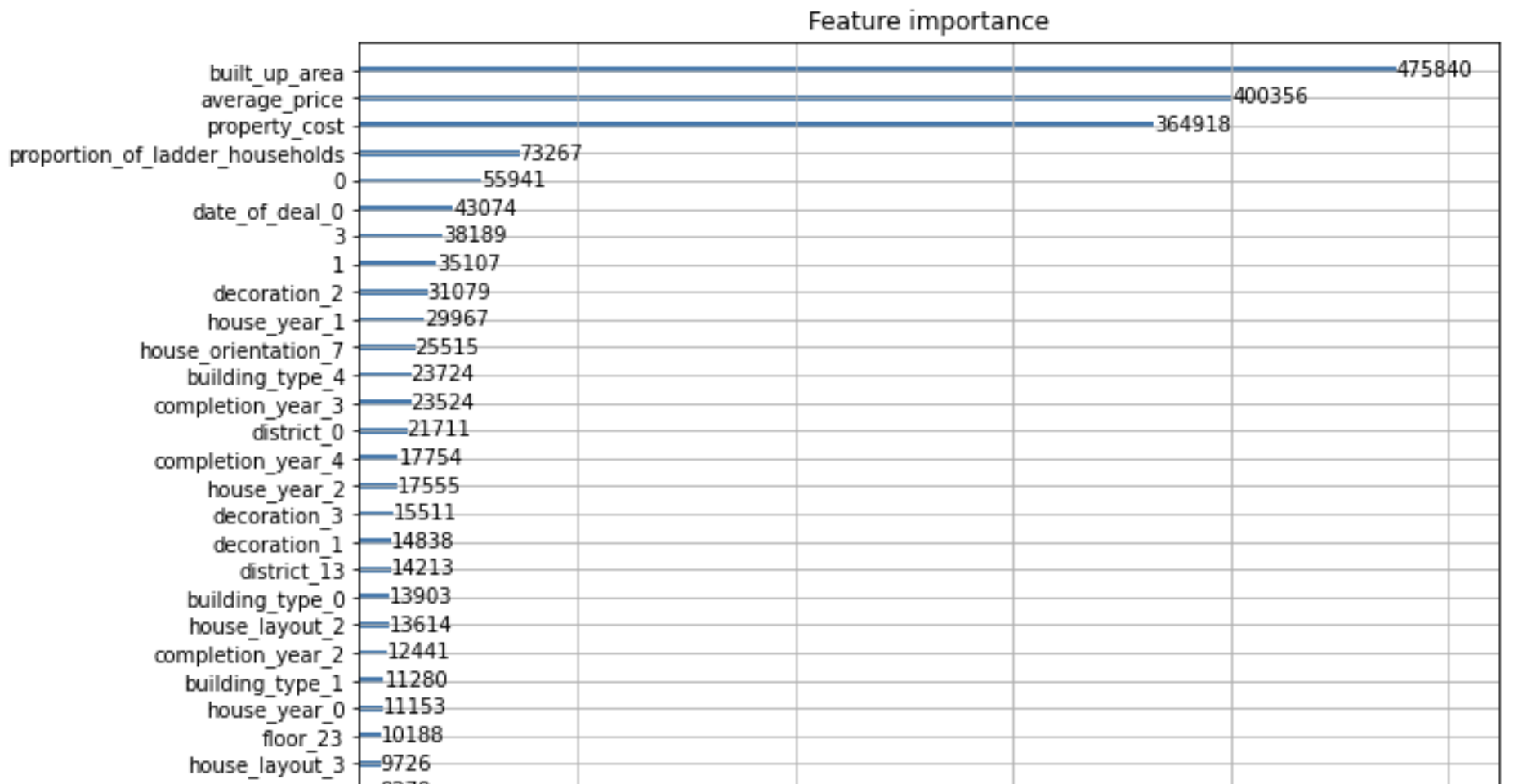 通过特征重要图发现,average_price、built_up_area、property_cost等连续特征的重要性明显高于其他离散特征,对模型对房价的预测起着决定性作用。这与我们之前的数据分析与推测相符,更大的面积、小区均价意味着更高的房价,更高的物业费用往往意味着更高档的小区。成交日期的重要性也比较靠前,说明2019年与2020年的北京房价整体上存在差异。
第二轮迭代
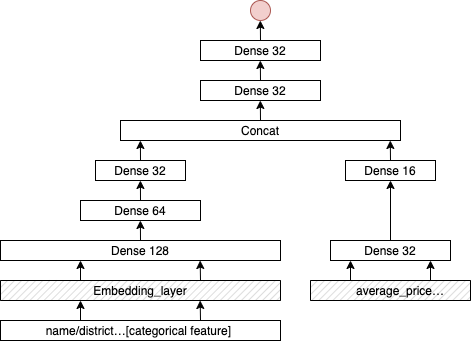
至此我们已经将所有处理的特征进行了使用,并对特征的重要性进行了合理性分析,验证了模型的有效性,那么如何进一步提高模型的性能,或者说加入更多的重要特征呢。注意到,我们的数据集中含有房屋所在小区的特征,这一特征意义重要,在中国,一个小区包含着其学区信息、交通信息以及小区开发商信息等多元信息,买家在考虑房屋面积等决定性因素的情况,极大程度也受小区的多维属性的影响。但由于小区这一离散特征类别太多(2127个),如果直接处理成01特征feed给模型显然是不合理的。那么如果给特征降维成了是否能合理使用该特征关键。将小区特征转变为embedding向量:我们利用神经网络去训练各个小区的embedding特征,与上述神经网络改变如下:
为了突出小区特征的重要性,我们将小区特征的embedding设置为8维,地区特征的embedding设置为4维,其余均减少至两维。将连续特征中与小区相关的特征全部剔除,如average_price、property_cost等。具体模型示意图如下:
通过特征重要图发现,average_price、built_up_area、property_cost等连续特征的重要性明显高于其他离散特征,对模型对房价的预测起着决定性作用。这与我们之前的数据分析与推测相符,更大的面积、小区均价意味着更高的房价,更高的物业费用往往意味着更高档的小区。成交日期的重要性也比较靠前,说明2019年与2020年的北京房价整体上存在差异。
第二轮迭代
至此我们已经将所有处理的特征进行了使用,并对特征的重要性进行了合理性分析,验证了模型的有效性,那么如何进一步提高模型的性能,或者说加入更多的重要特征呢。注意到,我们的数据集中含有房屋所在小区的特征,这一特征意义重要,在中国,一个小区包含着其学区信息、交通信息以及小区开发商信息等多元信息,买家在考虑房屋面积等决定性因素的情况,极大程度也受小区的多维属性的影响。但由于小区这一离散特征类别太多(2127个),如果直接处理成01特征feed给模型显然是不合理的。那么如果给特征降维成了是否能合理使用该特征关键。将小区特征转变为embedding向量:我们利用神经网络去训练各个小区的embedding特征,与上述神经网络改变如下:
为了突出小区特征的重要性,我们将小区特征的embedding设置为8维,地区特征的embedding设置为4维,其余均减少至两维。将连续特征中与小区相关的特征全部剔除,如average_price、property_cost等。具体模型示意图如下:
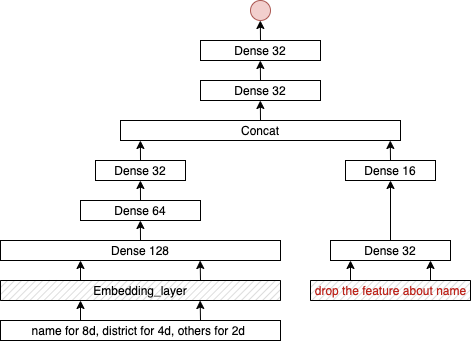 将模型训练至收敛,直到验证集上MAE不再下降即停止。将模型中的小区embedding参数取出([2127,8]),至此我们将所有小区都转换成了一个8维的特征,我们将该特征应用于原来的最优模型上,观察模型的性能变化。效果分析:
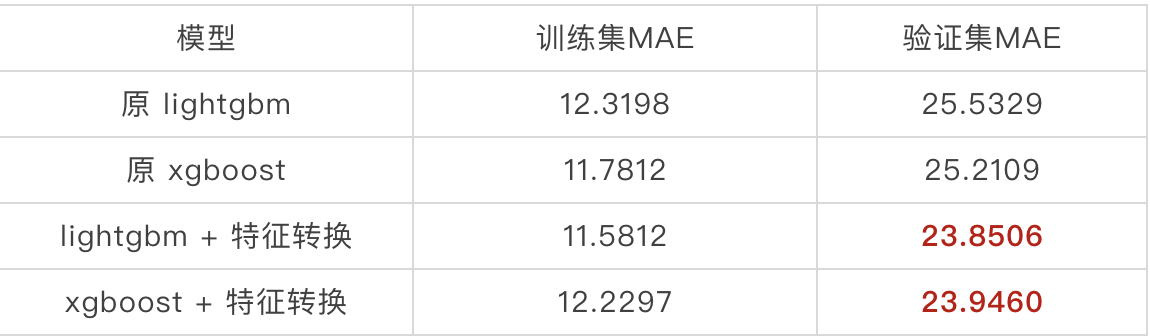
该神经网络最后在验证集上的MAE达到28.3748,仅略低于之前全特征训练的27.1561,说明即使去掉average_price、property_cost等重要的离散特征,模型仍然能通过小区特征学到这些属性。该embedding方法很有可能是有效的。我们将小区的8维特征加入原有的特征集合后,使用相同的参数,lightgbm模型在验证集上的MAE从原来的25.5下降至24.3,误差减少了1.2。显然该性能的提升不仅证明了小区特征的作用,同样也证明了通过这种方式训练的小区特征具有一定的有效性,这让我们非常喜悦,接着我们同样将训练好的4维的小区特征替换掉原有的小区01特征后,MAE又从24.3下降至23.98,误差减少了0.3。但当我们尝试将其他离散特征替换成embedding时,模型的性能没有再发生变化。经过参数调优后最终模型效果如下:
将模型训练至收敛,直到验证集上MAE不再下降即停止。将模型中的小区embedding参数取出([2127,8]),至此我们将所有小区都转换成了一个8维的特征,我们将该特征应用于原来的最优模型上,观察模型的性能变化。效果分析:
该神经网络最后在验证集上的MAE达到28.3748,仅略低于之前全特征训练的27.1561,说明即使去掉average_price、property_cost等重要的离散特征,模型仍然能通过小区特征学到这些属性。该embedding方法很有可能是有效的。我们将小区的8维特征加入原有的特征集合后,使用相同的参数,lightgbm模型在验证集上的MAE从原来的25.5下降至24.3,误差减少了1.2。显然该性能的提升不仅证明了小区特征的作用,同样也证明了通过这种方式训练的小区特征具有一定的有效性,这让我们非常喜悦,接着我们同样将训练好的4维的小区特征替换掉原有的小区01特征后,MAE又从24.3下降至23.98,误差减少了0.3。但当我们尝试将其他离散特征替换成embedding时,模型的性能没有再发生变化。经过参数调优后最终模型效果如下:
我们再一次查看各个特征的重要程度如下: 注意name_x表示小区的第x维度特征,地区特征同理。可以发现built_up_area仍然是最重要的特征,而average_price、property_cost被小区特征稀释,但小区特征的重要性仅次于这两者而超过了所有的其他离散特征,可以推断emedding后的小区特征与原本的average_price、property_cost等刻画小区属性的特征存在互补作用。而原本不重要的地区特征,也浮现在中上游。这证明了该特征降维方式的有效性。 Embedding到底学到了什么?为了探究这两组embedding特征到底学到了什么,我们对其做了可解释性的分析: 小区embedding特征:我们将2127个小区的特征进行了K-means聚类,将他们聚成20个子类,并观察每个子类的房价分布: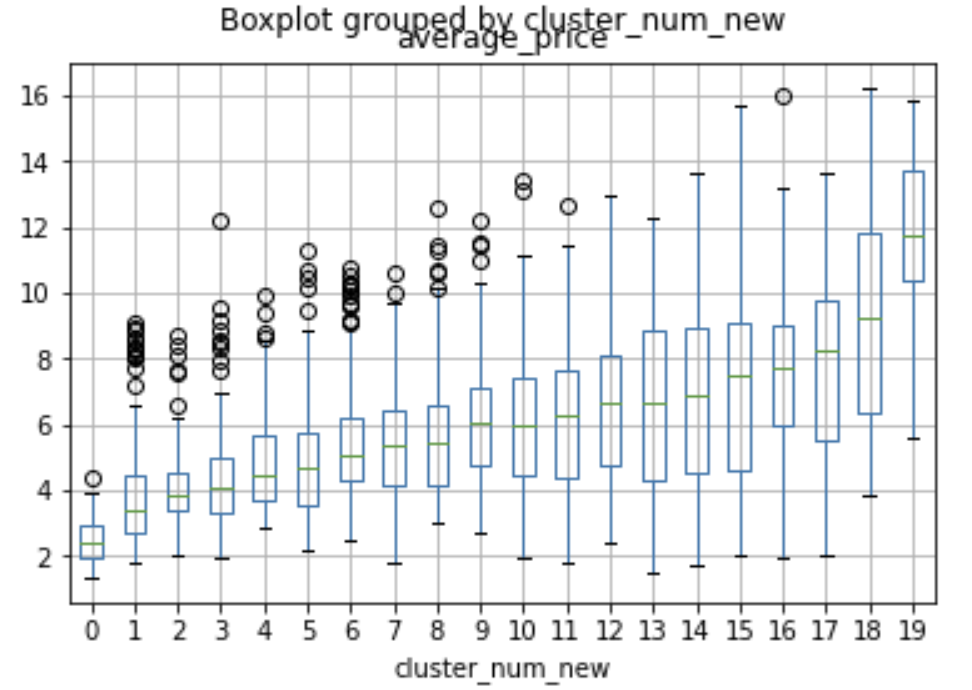 通过作出箱线图并按房屋售价中位数进行排列,我们可以发现,在这个20个聚类中,各个聚类的房价分布均不相同,但从低到高覆盖了形成了整一个数据集的房价区间分布,因此可以判断,小区embedding特征中包含了影响小区房价的重要信息,进一步证明了该特征的有效性。地区特征:我们将14个北京地区的4维特征用PCA降维至2维,并展示在2维坐标系中,结果如下: 通过作出箱线图并按房屋售价中位数进行排列,我们可以发现,在这个20个聚类中,各个聚类的房价分布均不相同,但从低到高覆盖了形成了整一个数据集的房价区间分布,因此可以判断,小区embedding特征中包含了影响小区房价的重要信息,进一步证明了该特征的有效性。地区特征:我们将14个北京地区的4维特征用PCA降维至2维,并展示在2维坐标系中,结果如下: 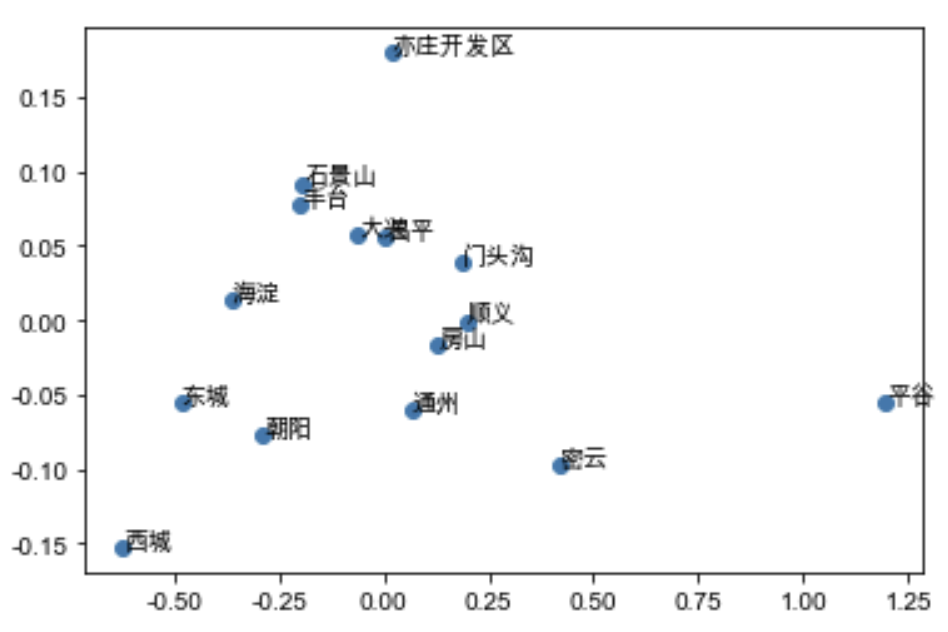 仅通过该图我们可能无法得到结论,但如果我们对比北京的地区分布以及房价图: 仅通过该图我们可能无法得到结论,但如果我们对比北京的地区分布以及房价图: 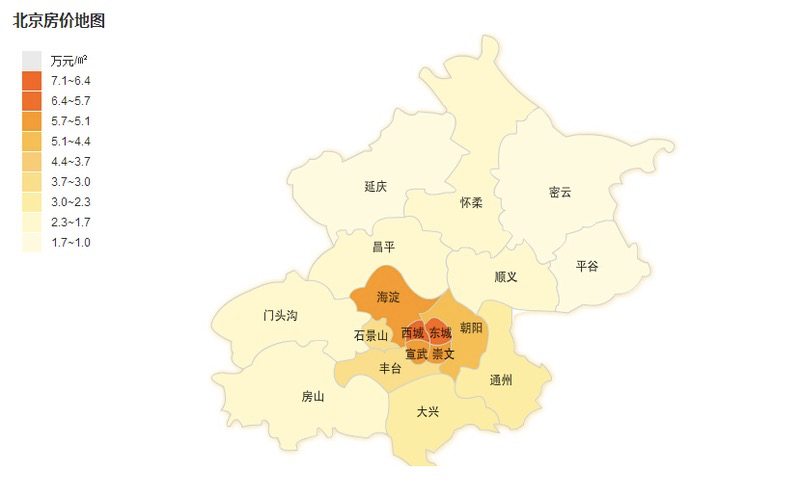 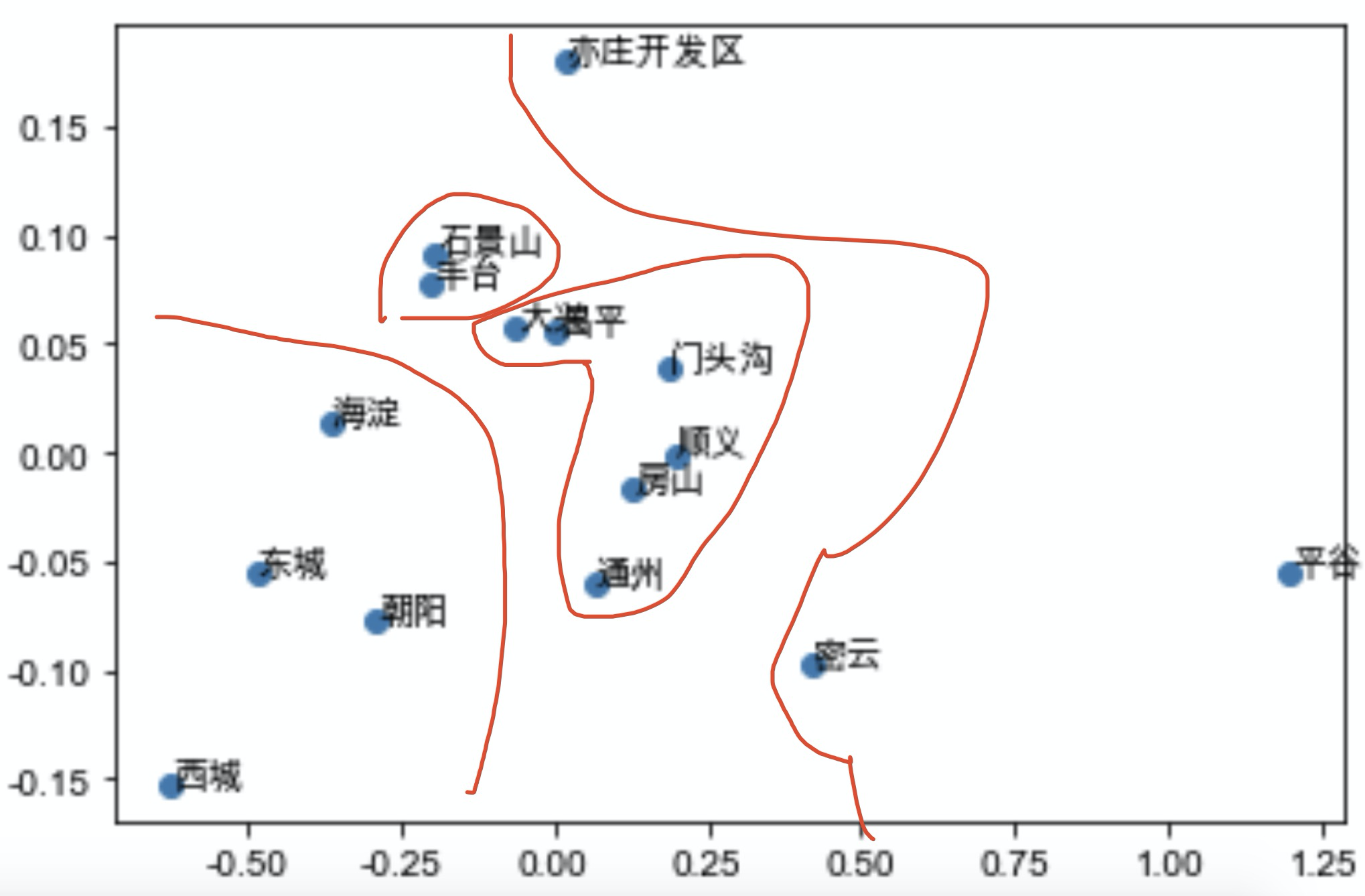 我们可以发现:西城、东城、海淀、朝阳这四个北京中心地区,其房价价格在北京地区中最高且相互差距较大,共同分布散落在原点周围。而对于石景山、丰台这两地区,两者相互比邻,且房价段位趋同,在坐标系同样分布紧密。对于大兴、昌平、门头沟、顺义、房山、通州这几个外围地区,地理位置相似(环绕主城区),共同分布在坐标轴中心位置,而对于亦庄、平谷、密云等边缘地区,房价较低,因此在坐标系上的分布较为离群,更加偏离原点。因此这个由地区embedding特征降维得到的2维坐标系,集合了各个地区地理位置、房价的信息,分布与真实的地区房价和地理位置相近,具有较强的有效性。
模型融合 我们可以发现:西城、东城、海淀、朝阳这四个北京中心地区,其房价价格在北京地区中最高且相互差距较大,共同分布散落在原点周围。而对于石景山、丰台这两地区,两者相互比邻,且房价段位趋同,在坐标系同样分布紧密。对于大兴、昌平、门头沟、顺义、房山、通州这几个外围地区,地理位置相似(环绕主城区),共同分布在坐标轴中心位置,而对于亦庄、平谷、密云等边缘地区,房价较低,因此在坐标系上的分布较为离群,更加偏离原点。因此这个由地区embedding特征降维得到的2维坐标系,集合了各个地区地理位置、房价的信息,分布与真实的地区房价和地理位置相近,具有较强的有效性。
模型融合
至此我们得到了最终的特征集合和模型,因此我们考虑使用模型融合来进一步提高我们的模型泛化能力,具体做法如下: K折验证 2020年成交的数据随机分成5份,每次训练用2019年的数据加上4份2020年的数据作为训练集,以另一份2020年的数据作为验证集,同时训练lightgbm、xgboost模型,当200轮内验证集上的MAE不再下降则停止并保存最优模型。以下仅展示lightgbm的训练结果: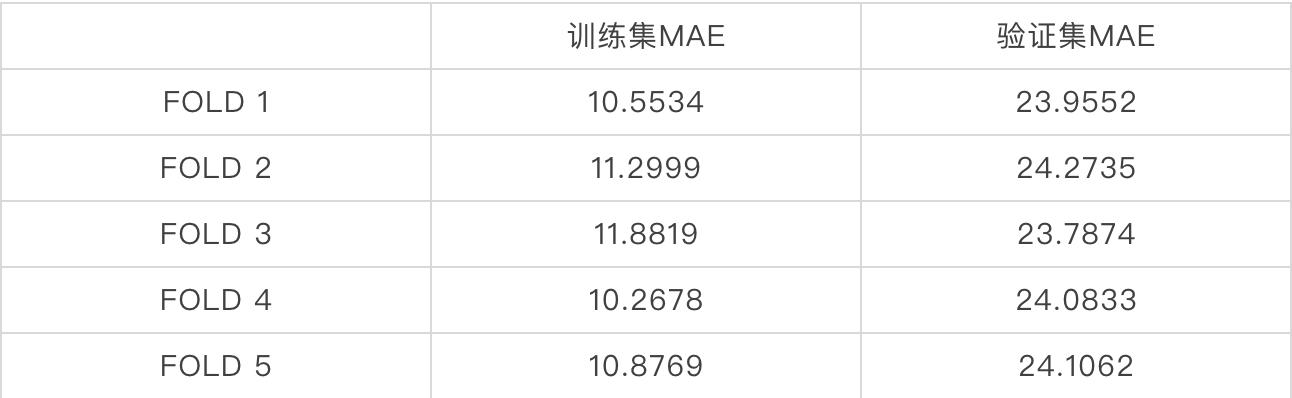 至此我们得到了10个模型,5个lightgbm和5个xgboost模型,当我们需要对房价预测时,我们仅需将10个模型的结果平均即可。
PK链家模型
至此我们得到了10个模型,5个lightgbm和5个xgboost模型,当我们需要对房价预测时,我们仅需将10个模型的结果平均即可。
PK链家模型
为了证明我们模型的先进性与应用性,我们希望能让我们的模型与链家网站的房价预测模型来一场竞赛。 链家估价模型 用户给出房屋的小区、建成年代、面积、户型、朝向、楼层以及一些标签特征后,模型会给用户提供一个合理的参考价格。这是链家官方的模型接口,由于链家官方拥有大量的充分的历史数据,因此具有一定的数据优势,挑战链家的官方模型具有一定的挑战性。我们将比较两个模型在最新的房屋成交数据(保证我们的模型和链家的模型都没有见过,防止答案泄漏)上的预测表现,来比较两个模型的性能。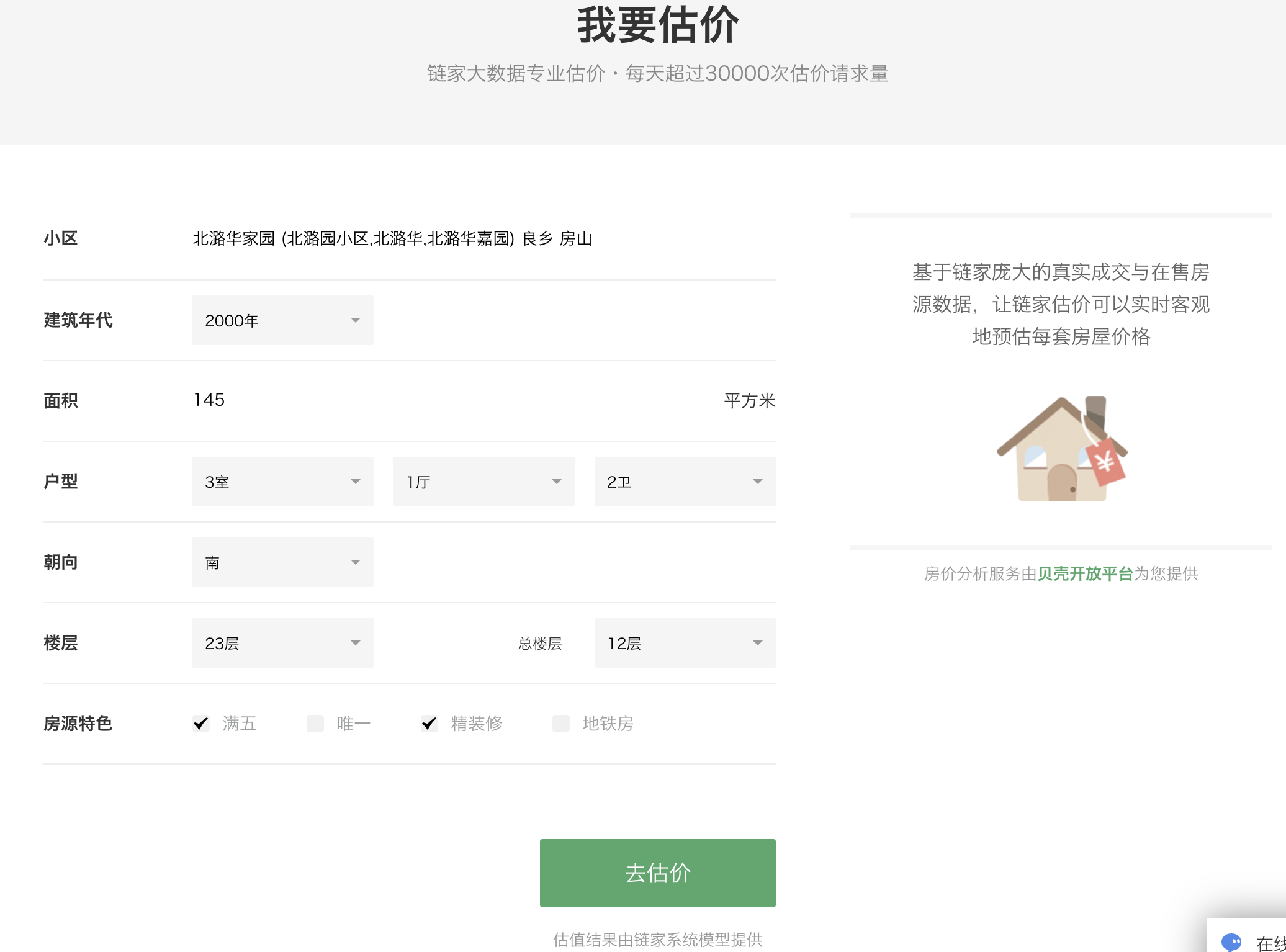 测试集准备
我们通过爬虫,重新抓取了链家网站上北京12月份最新的二手房成交记录,共2430条有效有效数据,测试集的total_price分布如下:
测试集准备
我们通过爬虫,重新抓取了链家网站上北京12月份最新的二手房成交记录,共2430条有效有效数据,测试集的total_price分布如下: 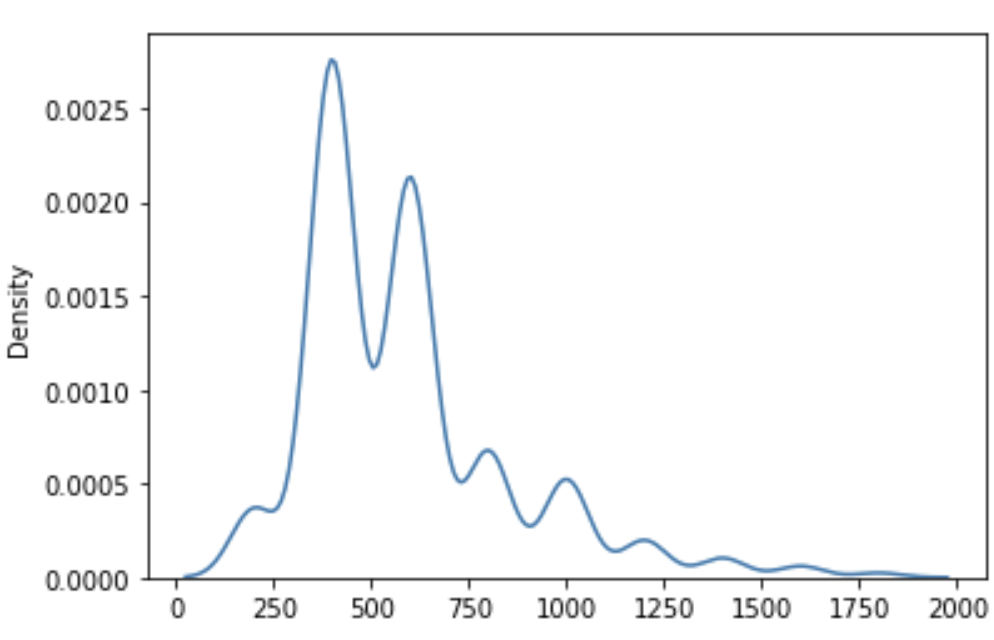 模型PK
同样通过爬虫技术,我们将测试集的成交房屋的特征信息通过爬虫的方式上传至链家的二手房估价网站,并抓取其预测结果并保存。我们的模型预测结果获取:通过相同的特征处理,将测试集的数据转化成我们模型熟悉的特征形式,利用预先训练好的10个模型,各自预测后作平均作为最后的预测结果,以此进行模型融合。计算并评价模型的性能:最终我们得到两个模型在测试集上的预测结果并计算其平均误差MAE:
模型PK
同样通过爬虫技术,我们将测试集的成交房屋的特征信息通过爬虫的方式上传至链家的二手房估价网站,并抓取其预测结果并保存。我们的模型预测结果获取:通过相同的特征处理,将测试集的数据转化成我们模型熟悉的特征形式,利用预先训练好的10个模型,各自预测后作平均作为最后的预测结果,以此进行模型融合。计算并评价模型的性能:最终我们得到两个模型在测试集上的预测结果并计算其平均误差MAE:
 结果现实链家的模型在测试集上的MAE为35.3764,而我们的模型在测试集上的MAE为22.4501,比链家模型的误差低了13万,这是一个巨大的差距,特别是对于房价来说。为了证明我们的模型全方位超过链家的模型,我们将展示两个模型在每一个二手房价位的预测误差,结果如下:
结果现实链家的模型在测试集上的MAE为35.3764,而我们的模型在测试集上的MAE为22.4501,比链家模型的误差低了13万,这是一个巨大的差距,特别是对于房价来说。为了证明我们的模型全方位超过链家的模型,我们将展示两个模型在每一个二手房价位的预测误差,结果如下:
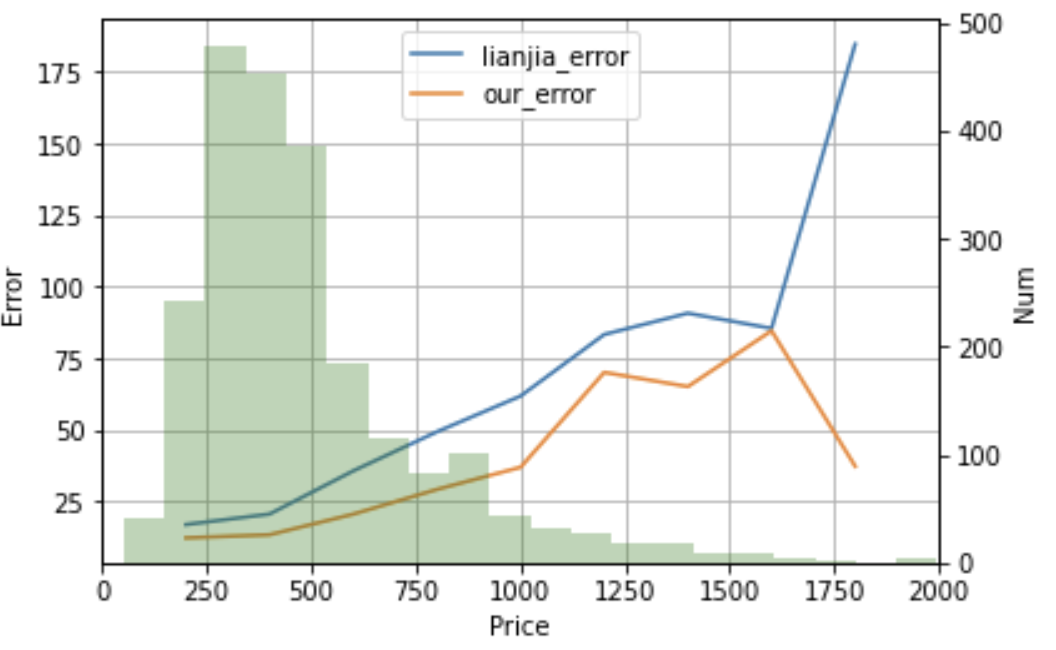 测试集的分布由绿色柱状图表示:测试集在250至700万分布较多,这也是北京主要的二手房交易价格区间。通过该图我们可以发现,在0-2000万的二手房价格区间,我们模型的误差全部低于链家模型。如果计算偏差率,对于低价位的房屋我们模型的预测偏差率远低于链家模型,并且对于高价位的二手房,我们的误差仍然保持着大幅度的领先,这说明,我们的模型的有足够的泛化能力,可以较为准确预测较大房价区间的二手房。事实证明,我们的模型相较于链家模型具有一定的先进性,在给二手房买卖双方提供参考售价参考时,我们的模型具有更强的准确性与应用性。
代码开源
测试集的分布由绿色柱状图表示:测试集在250至700万分布较多,这也是北京主要的二手房交易价格区间。通过该图我们可以发现,在0-2000万的二手房价格区间,我们模型的误差全部低于链家模型。如果计算偏差率,对于低价位的房屋我们模型的预测偏差率远低于链家模型,并且对于高价位的二手房,我们的误差仍然保持着大幅度的领先,这说明,我们的模型的有足够的泛化能力,可以较为准确预测较大房价区间的二手房。事实证明,我们的模型相较于链家模型具有一定的先进性,在给二手房买卖双方提供参考售价参考时,我们的模型具有更强的准确性与应用性。
代码开源
爬虫代码和其他代码将在展示后开源在个人github |
【本文地址】
今日新闻 |
推荐新闻 |