评价篇:确定权重(主观法,客观法,主客综合法) |
您所在的位置:网站首页 › 情绪是主观还是客观的 › 评价篇:确定权重(主观法,客观法,主客综合法) |
评价篇:确定权重(主观法,客观法,主客综合法)
|
层次分析法(主观法)
AHP层次分析法是一种解决多目标复杂问题的定性和定量相结合进行计算决策权重的研究方法。该方法将定量分析与定性分析结合起来,用决策者的经验判断各衡量目标之间能否实现的标准之间的相对重要程度,并合理地给出每个决策方案的每个标准的权数,利用权数求出各方案的优劣次序,比较有效地应用于那些难以用定量方法解决的课题。 比如现在想选择一个最佳旅游景点,当前有三个选择标准(分别是景色,门票和交通),并且对应有三种选择方案。现通过旅游专家打分,希望结合三个选择标准,选出最佳方案(即最终决定去哪个景区旅游)。诸如此类问题即专家打分进行权重计算等,均可通过AHP层次分析法得到解决。 实现步骤: 建立层次结构模型构造成对比较矩阵层次单排序及其一次性检验层次多排序及其一次性检验 1.建立层次结构模型层次结构模型一般分为三个部分: 目标层:也就是我们最终需要寻找出来的最佳结果,通常为一个。 准测层:结果优劣的判断因素。 方案层:我们的选择对象。 2.构造成对比较矩阵这里需要我们通过查阅资料来搜集相关判断因素之间的重要关系。 通常我们判断因素1对于因素2的重要程度用数字1-9来表示,1是无关紧要的,9是极其重要的。 一致阵: 对于比较矩阵来说,如果矩阵的所有元素都满足: (1)我们首先对准则层构造成对比较矩阵,计算出比较矩阵的最大特征值 (2)引入随机一致性指标RI,随机构造出500个随机成对比较矩阵,
(3)当一致性比率: (1)我们对于每一个准则层里面的元素,向下一层方案层进行构造成对比较矩阵。 (2)我们计算出每一次比较矩阵最大特征值所对应的特征向量及其 (3)最后,我们将所有的特征向量合并成为一个矩阵X,我们用X*W就可以得出每一个方案层的得分了,最后在进行拍序。 P.S:在计算成对比较矩阵的特征向量的时候,如果成对比较矩阵的一致性较好,那么比较矩阵就会和一致阵比较相似,在计算特征向量我们可以先将每一列进行归一化,再进行平均求特征向量,这样子的特征向量相差不大。 熵权法(客观法)熵权法相对于层次分析法最大的优点是,熵权法客观地为每一个指标确定了权值。 某个指标给数据差异量越大,说明这个指标提供的信息量越大,在客观评价中起到的作用就越大,我们认为这个指标应该权重越大。 实现步骤1.首先对数据进行归一化处理。 2.算出每个样本在指标下的比重p 3.算出这个指标的信息熵: 4.根据指标在信息熵中占比的比重来确定权重。 5.最后根据之前归一化的数据乘以每一个指标的权重得到最终得分,进行排序。 独立性权系数法(客观法)独立性权系教法是根据各指标与其他指标之间的共线性强弱未确定指标权重的。 设有指标项 取R的倒数作为得分,再经归一化处理得到权重系教。 CRITIC权重法(客观法) CRITIC法是一种比熵权法更好的客观赋权法。 它是基于评价指标的对比强度和指标之间的冲突性来综合衡量指标的客观权重。考虑指标变异性大小的同时兼顾指标之间的相关性,并非数字越大就说明越重要,完全利用数据自身的客观属性进行科学评价。 对比强度是指同一个指标各个评价方案之间取值差距的大小,以标准差的形式来表现。标准差越大,说明波动越大,即各方案之间的取值差距越大,权重会越高; 指标之间的冲突性,用相关系数进行表示,若两个指标之间具有较强的正相关,说明其冲突性越小,权重会越低。 对于CRITIC法而言,在标准差一定时,指标间冲突性越小,权重也越小;冲突性越大,权重也越大;另外,当两个指标间的正相关程度越大时,(相关系数越接近1),冲突性越小,这表明这两个指标在评价方案的优劣上反映的信息有较大的相似性。 实现步骤1.无量纲化处理 为消除因量纲不同对评价结果的影响,需要对各指标进行无量纲化处理处理。 CRITIC权重法一般使用正向化或逆向化处理,不建议使用标准化处理,原因是如果使用标准化处理,标准差全部都变成数字1,即所有指标的标准差完全一致,这就导致波动性指标没有意义。
2.指标变异性
在CRITIC法中使用标准差来表示各指标的内取值的差异波动情况,标准差越大表示该指标的数值差异越大,越能放映出更多的信息,该指标本身的评价强度也就越强,应该给该指标分配更多的权重。 3.指标冲突性
使用相关系数来表示指标间的相关性,与其他指标的相关性越强,则该指标就与其他指标的冲突性越小,反映出相同的信息越多,所能体现的评价内容就越有重复之处,一定程度上也就削弱了该指标的评价强度,应该减少对该指标分配的权重。 4.信息量
5.客观权重
以上所述的所有确定权重的方法其实都可以在SPSSPRO中直接实现,相当方便。 主客综合法接下来就是大家最关心的如何结合权重的问题了。组合赋权有很多种算法,其中博弈论是我在比赛中经常会用到的组合权重的方法: 现在说一下常见的博弈论求均衡解的方法,其实也是线性规划的问题。原文太多了,我就不详细解释了,有兴趣的可以直接去参考链接中找原文看看,没兴趣的可以直接参考我接下来的代码了: def general_weight(w1,w2): import numpy as np a = [email protected] b = [email protected] c = [email protected] A = np.array([[a,c],[c,b]]) B = np.array([a,b]) x = np.linalg.solve(A, B).reshape(1,2) result = [email protected]([w1,w2]) return result # 其中w1表示一种权重,w2表示一种权重施主都看到这里,还请施主点一个免费的小心心。 参考链接: 客观赋权法——CRITIC权重法_critic法_卖山楂啦prss的博客-CSDN博客 【综合评价方法 独立性权系数法】指标权重确定方法之独立性权系数法_东华果汁哥的博客-CSDN博客 (77 封私信 / 80 条消息) 组合赋权如何确定主客观权重分配? - 知乎 (zhihu.com) |

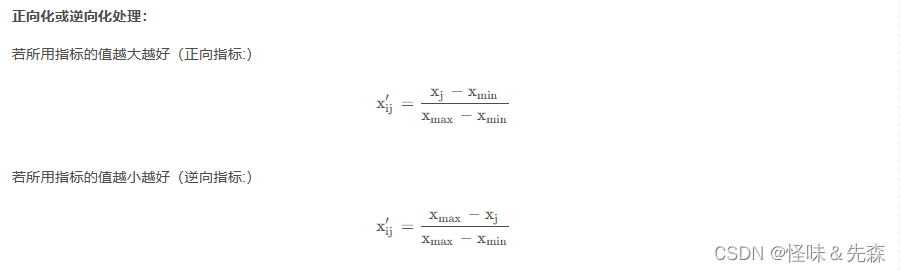
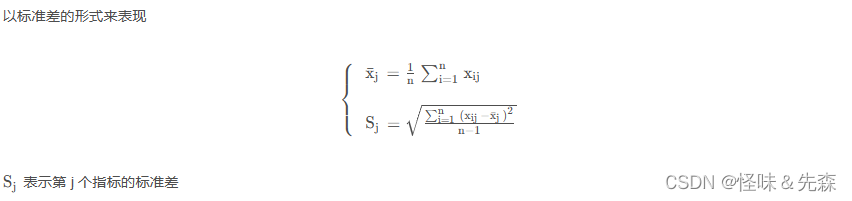
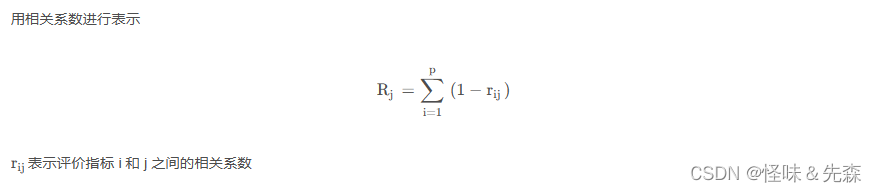

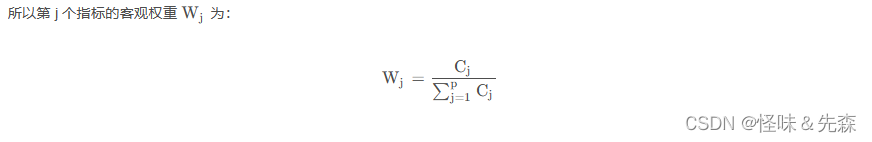
【本文地址】
今日新闻 |
推荐新闻 |